
في المقالة الثالثة من سلسة شبكات الخصومة التوليدية سنتحدث عن مقدمة في شبكات الترميز التلقائي (Autoencoders) و لكن أولا قصة
معرض الصور الثنائية :
شقيقان ، مشفر و مفكك ، يديران معرضًا فنيًا. في نهاية كل أسبوع ، يستضيفون معرضًا يركز على دراسات أحادية اللون للأرقام المكونة من رقم واحد. المعرض غريب بشكل خاص لأنه يحتوي على جدار واحد فقط ولا يوجد عمل أي عمل فني فيه. عندما تصل لوحة جديدة للعرض ، يختار السيد مشفر ببساطة نقطة على الحائط لتمثيل اللوحة ، ويضع علامة في ذلك المكان ، ثم يرمي العمل الفني الأصلي بعيدًا. عندما يطلب أحد العملاء رؤية اللوحة ، يحاول السيد مشفر إعادة إنشاء العمل الفني باستخدام إحداثيات العلامة الموجوده على الحائط.
يظهر جدار المعرض في الصورة أسفله ، حيث تمثل كل نقطة سوداء علامة وضعها السيد مشفر لتمثيل لوحة. نعرض أيضًا إحدى اللوحات التي تم وضع علامة عليها على الحائط عند النقطة [–3.5 ، –0.5] من قبل السيد مشفر ثم أعيد بناؤها باستخدام هذين الرقمين فقط من قبل السيد مفكك.
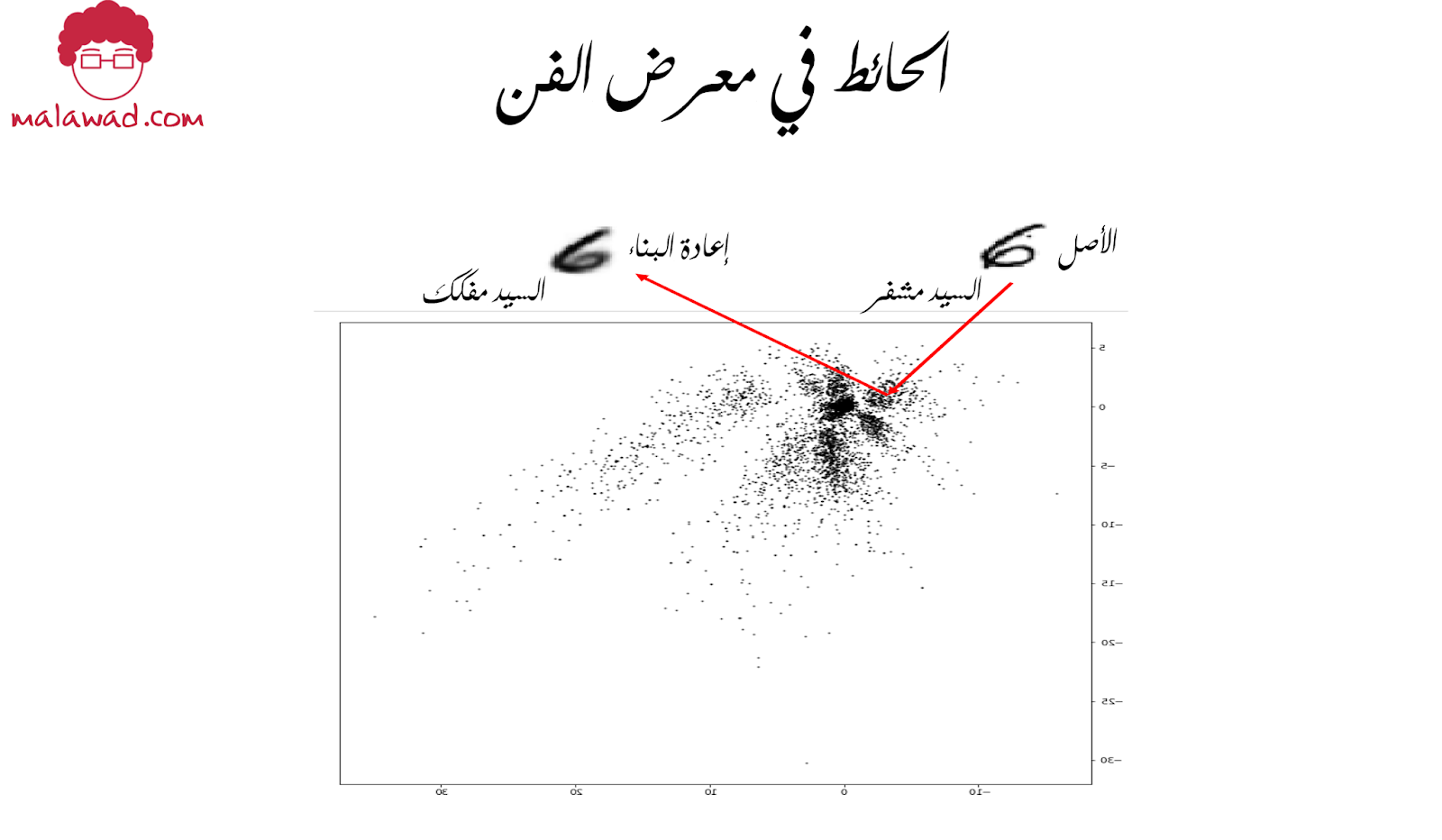
في الصورة الأتيه يمكننا رؤية أمثلة على اللوحات الأصلية الأخرى (الصف العلوي) ، وإحداثيات النقطة على الحائط التي قدمها السيد مشفر ، واللوحات المعاد إنشاؤها التي أنتجها السيد مفكك (الصف السفلي).

إذا كيف يقرر السيد مشفر مكان وضع العلامات؟ يتطور النظام بشكل طبيعي من خلال سنوات من التدريب والعمل معًا ،و التحسن مرة تلو الأخرى . يراقب الإخوة بعناية خسارة الإيرادات في مكتب التذاكر بسبب طلب العملاء استرداد الأموال وذلك لأن اللوحات أعيد بناؤها بشكل سيئ ، ويحاولون باستمرار إيجاد نظام يقلل من هذه الخسارة في الأرباح.
كما ترى من الصورة أعلاه ، فعمل الأخوين مبهر – العملاء الذين يأتون لمشاهدة العمل الفني نادرًا ما يشكون من أن لوحات السيد مفكك المعاد إنشاؤها تختلف اختلافًا كبيرًا عن القطع الأصلية التي جاءوا لرؤيتها.
ذات يوم ، راود السيد مشفر فكرة. ماذا لو وضع علامات بشكل عشوائي على أجزاء من الجدار لا تحتوي حاليًا على علامة؟ و يمكن للسيد مفكك بعد ذلك بإعادة إنشاء العمل الفني المقابل لهذه النقاط ، وفي غضون أيام قليلة سيكون لديهم معرض خاص بهم للوحات أصلية تمامًا.
بدأ الإخوة خطتهم وفتحوا معرضهم الجديد للجمهور. وتم عرض بعض المعروضات كما في الصورة أدناه

كما ترون ، لم تحقق الخطة نجاحًا كبيرًا. التنوع العام ضعيف وبعض القطع الفنية لا تشبه أرقام أصلاً.
إذن ، ما الخطأ الذي حدث وكيف يمكن للأخوة تحسين مخططهم؟
الترميز التلقائي
القصة السابقة هي تشبيه للترميز التلقائي (Autoencoders) ، وهي شبكة عصبية تتكون من جزأين:
• شبكة تشفير (encoder network) تضغط البيانات المدخله عالية الأبعاد في متجه التمثيل (Representation Vector) منخفضة الأبعاد
• شبكة فكك التشفير (decoder network) تقوم بفك تشفير متجه التمثيل إلى المجال الأصلي

يتم تدريب الشبكة للعثور على أوزان لكل من المشفر (encoder) و المفكك (decoder) لتقليل الخسارة (loss) بين المدخلات الأصلية وإعادة بناء المدخلات بعد مرورها من خلال شبكة التشفير و شبكة فك الشفرة.
- متجه التمثيل (representation vector) : هي عبارة عن ضغط للصورة الأصلية في الفضاء الكامن (latent space) ذو أبعاد أقل
الفكرة هي أنه باختيار أي نقطة في الفضاء الكامن ، يجب أن نكون قادرين على إنشاء صور جديدة بتمرير هذه النقطة من خلال شبكة فك الترميز ، حيث تعلم المفكك كيفية تحويل النقاط في الفضاء الكامن إلى صور صالحة.
في قصتنا ، يستخدم السيد مشفر والسيد مفكك متجهات التمثيل داخل فضاء كامن ثنائي الأبعاد (الجدار) لتشفير كل صورة. هذا يساعدنا على تصور الفضاء الكامن ، حيث يمكننا بسهولة رسم النقاط في بعدين. من الناحية العملية ، عادةً ما يكون لشبكات الترميز التلقائي أكثر من بعدين من أجل الحصول على مزيد من الحرية لالتقاط فارق أكبر في الصور.
شبكة الترميز التلقائي
شبكة تشفير (encoder network)
في شبكة الترميز التلقائي (Autoencoders) ، تتمثل مهمة التشفير في أخذ صورة مدخلة وتعيينها إلى نقطة في الفضاء الكامن. و هنا معمارية شبكة التشفير التي سنقوم ببنائها

لتحقيق ذلك ، نقوم أولاً بإنشاء طبقة إدخال للصورة وتمريرها عبر أربع طبقات لف رياضي بالتسلسل ،. نستخدم مقدار خطوة يساوي 2 على بعض الطبقات لتقليل حجم المخرج. ثم يتم تسطيح طبقة اللف الرياضية الأخيرة وتوصيلها بطبقة كثيفة أو كاملة إتصال حجمها يساوي 2 ، والتي تمثل الفضاء الكامن ثنائية الأبعاد.
### شبكة التشفير
encoder_input = Input(shape=self.input_dim, name='encoder_input') #1
x = encoder_input
for i in range(self.n_layers_encoder):
conv_layer = Conv2D(
filters = self.encoder_conv_filters[i]
, kernel_size = self.encoder_conv_kernel_size[i]
, strides = self.encoder_conv_strides[i]
, padding = 'same'
, name = 'encoder_conv_' + str(i)
)
x = conv_layer(x) #2
x = LeakyReLU()(x)
shape_before_flattening = K.int_shape(x)[1:]
x = Flatten()(x) #3
encoder_output= Dense(self.z_dim, name='encoder_output')(x) #4
self.encoder = Model(encoder_input, encoder_output) #5
- تحديد الإدخال إلى التشفير (الصورة).
- تكديس الطبقات اللف الرياضي بالتسلسل فوق بعضها البعض.
- تسطيح طبقة اللف الرياضي الأخيرة إلى مٌتجه.
- طبقة كثيفة تربط هذا المتجه بالفضاء الكامن ثنائية الأبعاد.
- نموذج Keras الذي يحدد المشفر – نموذج يأخذ صورة إدخال ويشفّرها في الفضاء الكامن ثنائي الأبعاد.
شبكة فكك التشفير (decoder network)
المفكك هو صورة طبق الأصل من المشفر ، باستثناء طبقات اللف الرياضي ، عوضا عنها سنستخدم طبقات لف رياضية تناقليه (convolutional transpose layers) ، كما هو موضح في معمارية شبكة فك الشفرة

لاحظ أنه لا يجب أن يكون المفكك صورة معكوسة من المشفر. يمكن أن يكون أي شيء نريده ، طالما أن المخرج من الطبقة الأخيرة من المفكك له نفس حجم المدخل في المشفر (لأن وظيفة الخسارة لدينا هي مقارنة هذين الإثنين).
طبقات اللف الرياضية التناقليه (Convolutional Transpose Layers)
تسمح لنا الطبقات اللف الرياضي بتقليل ارتفاع وعرض حجم التنسور المدخل للنصف ، من خلال تعيين مقدار الخطوة = 2.
تستخدم طبقات اللف الرياضية التناقليه نفس مبدأ طبقات اللف الرياضي العادية (تمرير مرشح عبر الصورة) ، ولكنها مختلفة في أنه عندما نعين مقدار الخطوات = 2 يتضاعف ارتفاع وعرض حجم التنسور المدخل.
في طبقات لف رياضية تناقليه ، تحدد قيمة الخطوة الحشو الصفري الداخلي بين وحدات النقاط الضوئية في الصورة كما هو موضح في الصور أدناه.

في Keras ، تتيح لنا طبقة Conv2DTranspose إجراء عمليات اللف الرياضي التناقلية على التنسور. من خلال تكديس هذه الطبقات ، يمكننا توسيع حجم كل طبقة تدريجيًا ، باستخدام مقدار خطوة يساوي 2 ، حتى نعود إلى أبعاد الصورة الأصلية 28 × 28.
### شبكة فك التشفير
decoder_input = Input(shape=(self.z_dim,), name='decoder_input') #1
x = Dense(np.prod(shape_before_flattening))(decoder_input) #2
x = Reshape(shape_before_flattening)(x) #3
for i in range(self.n_layers_decoder):
conv_t_layer = Conv2DTranspose(
filters = self.decoder_conv_t_filters[i]
, kernel_size = self.decoder_conv_t_kernel_size[i]
, strides = self.decoder_conv_t_strides[i]
, padding = 'same'
, name = 'decoder_conv_t_' + str(i)
)
x = conv_t_layer(x) #4
if i < self.n_layers_decoder - 1:
x = LeakyReLU()(x)
else:
x = Activation('sigmoid')(x)
decoder_output = x
self.decoder = Model(decoder_input, decoder_output) #5
- مدخل شبكة فك التشفير (النقطة في الفضاء الكامن).
- قم بتوصيل المدخل بطبقة كثيفة.
- إعادة تشكيل المتجه إلى تنسور يمكن تغذيته كمدخل في أول طبقة لف رياضي تناقلي
- تكدس طبقات اللف الرياضي التناقلية فوق بعضها البعض.
- نموذج Keras الذي يحدد شبكة فك التشفير — نموذج يأخذ نقطة في الفضاء الكامن ويفك تشفيره في مجال الصورة الأصلي.
ضم شبكة التشفير وشبكة فك التشفير
لتدريب شبكتي التشفير و فك التشفير سوياً ، نحتاج إلى تحديد نموذج سيمثل تدفق صورة من خلال برنامج التشفير والعودة من خلال وحدة فك الترميز. لحسن الحظ ، يجعل Keras من السهل جدًا القيام بذلك
### شبكة الترميز التلقائي model_input = encoder_input #1 model_output = decoder(encoder_output) #2 self.model = Model(model_input, model_output) #3
- مدخل الترميز التلقائي هو نفسه مدخل شبكة التشفير
- مخرج الترميز التلقائي هو نفسه مخرج شبكة التشفير بعد تمريرها على شبكة في التشفير
- نموذج Keras الذي يحدد شبكة الترميز التلقائي بالكامل – نموذج يأخذ صورة ، ويمررها من خلال شبكة التشفير و يخرجها خلال شبكة فك التشفير لإعادة بناء للصورة الأصلية.
الآن بعد أن حددنا نموذجنا ، نحتاج فقط إلى تجميعه باستخدام دالة خسارة و دالة تحسين ، دالة الخسارة عادةً إما تكون خسارة متوسط الخطأ التربيعي ( root mean squared error) أو الإنتروبيا الثنائية (binary cross-entropy) بين وحدات النقاط الضوئية الفردية للصورة الأصلية و الصورة المعادة بنائها
### التجميع
optimizer = Adam(lr=learning_rate)
def r_loss(y_true, y_pred):
return K.mean(K.square(y_true - y_pred), axis = [1,2,3])
self.model.compile(optimizer=optimizer, loss = r_loss)
و لتدريب شبكة الترميز التلقائي
self.model.fit(
x = x_train
, y = x_train
, batch_size = batch_size
, shuffle = True
, epochs = 10
, callbacks = callbacks_list
)
تحليل شبكة الترميز التلقائي
الآن بعد أن تم تدريب شبكة الترميز التلقائي ، يمكننا البدء في تحليل في كيفية تمثيل الصور في الفضاء الكامن.
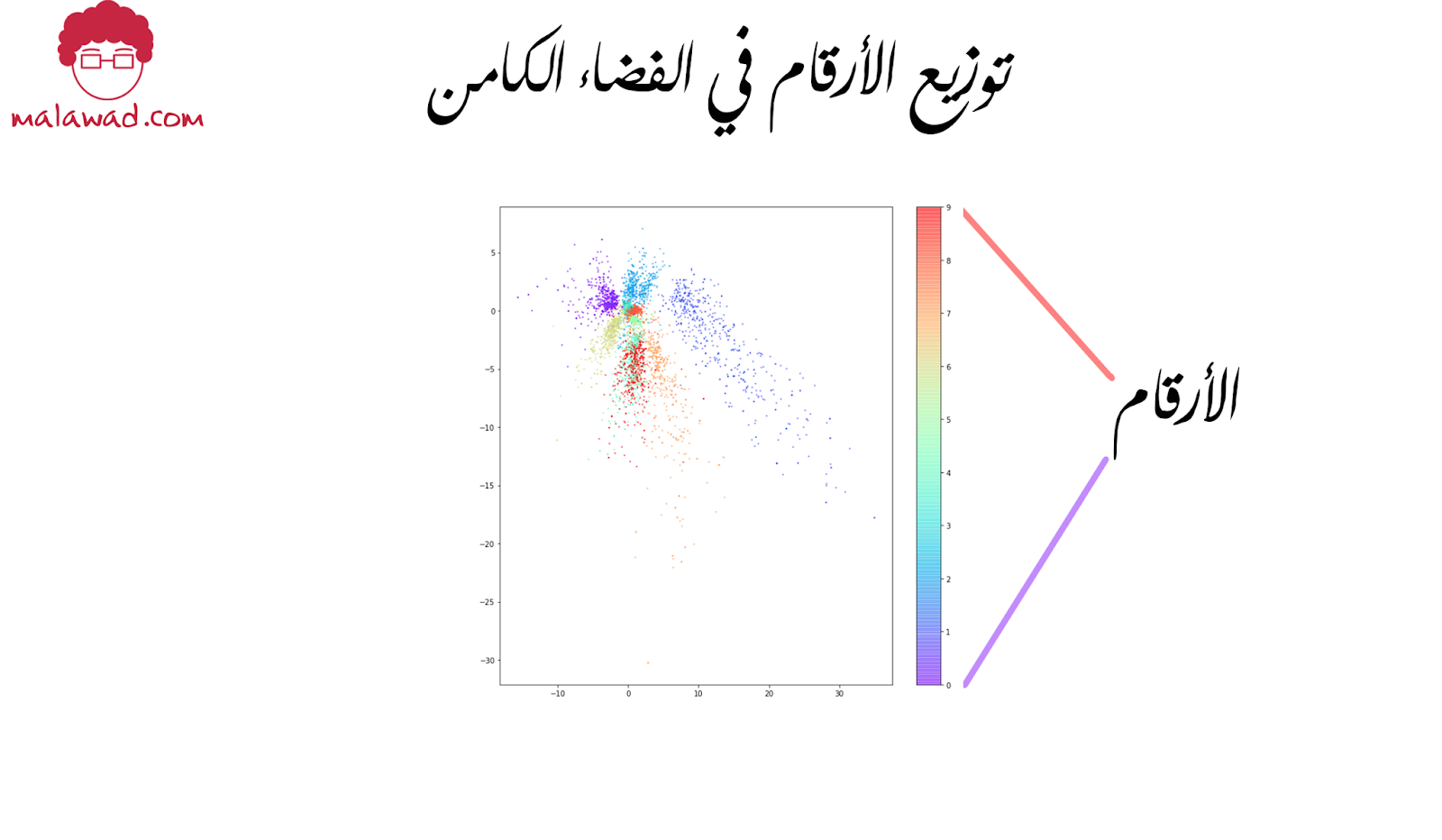
هناك بعض النقاط المثيرة للاهتمام التي يجب ملاحظتها:
1. الرسم ليس متماثل حول النقطة (0 ، 0) على سبيل المثال ، هناك نقاط أكثر بكثير في قيم محور y السلبي أكثر من الإيجابية ، بل أن بعض النقاط تتجاوز -30 .
2. يتم تمثيل بعض الأرقام على مساحة صغيرة جدًا والبعض الآخر على مساحة أكبر بكثير.
3. هناك فجوات كبيرة بين الألوان التي تحتوي على نقاط قليلة.
تذكر أن هدفنا هو أن نكون قادرين على اختيار نقطة عشوائية في الفضاء الكامن، وتمريرها من خلال شبكة فك التشفير ، والحصول على صورة لرقم يبدو حقيقيًا. نرغب أيضًا في الحصول على مزيج متساوي تقريبًا من أنواع مختلفة من الأرقام (على سبيل المثال ، لا يجب أن ينتج دائمًا نفس الرقم)
توضح النقطة 1 سبب عدم وضوح كيفية اختيار نقطة عشوائية في الفضاء الكامن، حيث إن توزيع هذه النقاط غير محدد. فليس من المضمون حتى أن تتمحور النقاط حول (0،0). وهذا يجعل أخذ العينات من مساحتنا الكامنة أمرًا صعبًا للغاية.
توضح النقطة 2 نقص التنوع في الصور التي تم إنشاؤها. من الناحية المثالية ، نود الحصول على انتشار متساوٍ تقريبًا من الأرقام عند أخذ العينات بشكل عشوائي من مساحتنا الكامنة. ومع ذلك ، مع ترميز تلقائي هذا غير مضمون. على سبيل المثال ، مساحة 1 أكبر بكثير من مساحة 8 ،
توضح النقطة 3 سبب ضعف تكوين بعض الصور التي تم إنشاؤها. ، يمكننا رؤية ثلاث نقاط في الفضاء الكامن وصورها التي تم فك تشفيرها ، لم يتم تكوين أي منها بشكل جيد.

ويرجع ذلك جزئيًا إلى وجود مساحات كبيرة على حافة المجال حيث توجد نقاط قليلة – لا يوجد لدى الترميز التلقائي سبب لضمان أن النقاط هنا سيتم فك تشفيرها أرقام مقروءة حيث تم تشفير عدد قليل جدًا من الصور هنا.
وذلك لأن الترميز التلقائي (Autoencoders) غير مجبر على ضمان استمرارية الفضاء (space is continuous) . على سبيل المثال ، على الرغم من أن النقطة (2 ، -2) قد يتم فك شفرتها لإعطاء صورة مرضية لـ 4 ، لا توجد آلية لضمان أن النقطة (2.1 ، 2.1) تنتج أيضًا 4 مرضية.
في الختام لمعرفة المزيد عن الترميز التلقائي بوسعكم زيارة الصفحة الرسمية في مدونة كيراس













إضافة تعليق