
في آذار (مارس) 2018 ، نشر David Ha و Jürgen Schmidhuber ورقتهما نموذج العالم “World Models“. وأوضحت الورقة كيف يمكن تدريب نموذج يمكنه تعلم كيفية أداء مهمة معينة من خلال التجريب داخل هلوسة أحلامه التوليدية ، بدلاً من داخل البيئة نفسها. هذا مثال ممتاز لكيفية استخدام النمذجة التوليدية لحل المشكلات العملية ، عند تطبيقها جنبًا إلى جنب مع تقنيات التعلم الآلي الأخرى مثل التعلم المعزز.
أحد المكونات الرئيسية لهذه المعمارية هو نموذج توليدي يمكنه إنشاء توزيع احتمالي للحالة المحتملة التالية ، بالنظر إلى الحالة الحالية والإجراء. بعد تكوين فهم للفيزياء الأساسية للبيئة من خلال الحركات العشوائية ، يصبح النموذج قادرًا بعد ذلك على تدريب نفسه من نقطة الصفر في مهمة جديدة ، تمامًا ضمن تمثيله الداخلي للبيئة. أدى هذا النهج إلى الحصول على أفضل الدرجات في العالم لكلتا المهمتين التي تم اختباره من خلالها.
في هذا المقال ، سوف نستكشف النموذج بالتفصيل ونوضح كيف يمكن إنشاء نسختك الخاصة من هذه التكنولوجيا المتطورة المذهلة.
استنادًا إلى الورقة الأصلية ، سنقوم ببناء خوارزمية التعلم المعزز التي تتعلم كيفية قيادة السيارة حول مضمار السباق بأسرع ما يمكن. بينما سنستخدم محاكاة الكمبيوتر ثنائية الأبعاد كبيئتنا ، يمكن أيضًا تطبيق نفس التقنية على سيناريوهات العالم الحقيقي حيث تكون استراتيجيات الاختبار في البيئة الحية باهظة الثمن أو غير قابلة للتنفيذ.
قبل أن نبدأ في بناء النموذج ، نحتاج إلى إلقاء نظرة فاحصة على مفهوم التعلم المعزز ومنصة OpenAI Gym.
التعلم المعزز
يمكن تعريف التعلم المعزز على النحو التالي:
التعلم المعزز (Reinforcement learning) هو مجال من مجالات تعلم الألة الذي يهدف إلى تدريب الوكيل (agent) على الأداء الأمثل في بيئة معينة ، فيما يتعلق بهدف معين.
بينما تهدف كل من النمذجة التمييزية (discriminative modeling) والنمذجة التوليدية (generative modeling) إلى تقليل دالة الخسارة على مجموعة بيانات من الملاحظات ، يهدف التعلم المعزز إلى تعظيم المكافأة طويلة الأجل للعامل في بيئة معينة. غالبًا ما يوصف بأنه أحد الفروع الرئيسية الثلاثة لتعلم الألة ، جنبًا إلى جنب مع التعلم الخاضع للإشراف (التنبؤ باستخدام البيانات المصنفة) والتعلم غير الخاضع للإشراف ( التعلم من البيانات غير المصنفة).
دعونا أولاً نقدم بعض المصطلحات الرئيسية المتعلقة بالتعلم المعزز:
بيئة (Environment)
العالم الذي يعمل فيه الوكيل. تحدد مجموعة القواعد التي تحكم عملية تحديث حالة اللعبة وتخصيص المكافآت ، بالنظر إلى الإجراء السابق للوكيل وحالة اللعبة الحالية. على سبيل المثال ، إذا كنا نقوم بتدريس خوارزمية التعلم المعزز للعب الشطرنج ، فإن البيئة ستتكون من القواعد التي تحكم كيفية تأثير إجراء معين (على سبيل المثال ، الحركة e4) على حالة اللعبة التالية (المواضع الجديدة للقطع على اللوحة ) وسيحدد أيضًا كيفية تقييم ما إذا كان مركز معين هو كش ملك وتخصيص مكافأة للاعب الفائز بقيمة 1 بعد النقلة الفائزة.
وكيل (Agent)
الكيان الذي يتخذ الإجراءات في البيئة.
حالة اللعبة (Game state)
البيانات التي تمثل موقفًا معينًا قد يواجهه الوكيل (يُطلق عليه أيضًا حالة) ، على سبيل المثال ، تكوين رقعة شطرنج معين مع معلومات اللعبة المصاحبة مثل اللاعب الذي سيقوم بالخطوة التالية.
فعل (Action)
خطوة فعالة يمكن أن يقوم بها الوكيل.
مكافأة (Reward)
القيمة التي تعيدها البيئة للوكيل بعد اتخاذ الإجراء. يهدف الوكيل إلى تعظيم مجموع مكافآته على المدى الطويل. على سبيل المثال ، في لعبة الشطرنج ، يكون التحقق من ملك الخصم بمكافأة 1 وكل حركة أخرى لها مكافأة قدرها 0. تحصل الألعاب الأخرى على مكافآت تُمنح باستمرار طوال الحلقة (على سبيل المثال ، النقاط في لعبة Space Invaders).
حلقة (Episode)
دورة واحده للوكيل في البيئة ؛ وهذا ما يسمى أيضًا بالطرح (rollout).
خطوة زمنية (Timestep)
بالنسبة لبيئة أحداثها منفصلة ، تقوم جميع الحالات و الأفعال والمكافآت بإظهار قيمتها في الوقت t.
تظهر العلاقة بين هذه التعريفات أدناه
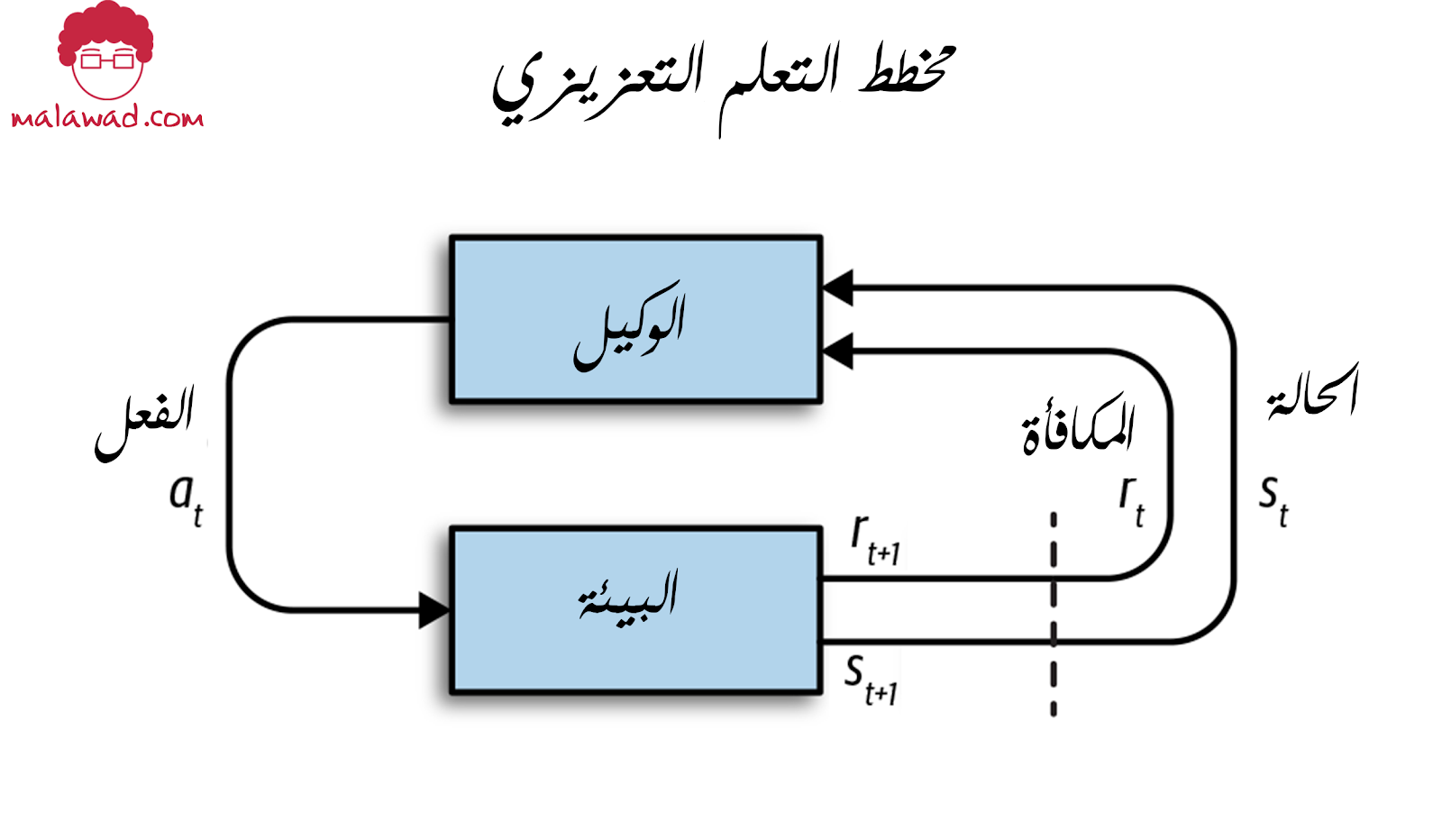
يتم تهيئة البيئة أولاً باستخدام حالة اللعبة الحالية ، s0. في الخطوة الزمنية t ، يتلقى الوكيل حالة اللعبة الحالية ويستخدم هذا لتحديد الإجراء التالي الأفضل عنده ، والذي يؤديه بعد ذلك. بالنظر إلى هذا الإجراء ، تحسب البيئة بعد ذلك الحالة التالية st + 1 ومكافأة rt + 1 وتمررها مرة أخرى إلى الوكيل ، حتى تبدأ الدورة مرة أخرى. تستمر الدورة حتى يتم استيفاء المعيار النهائي للحلقة (على سبيل المثال ، ينقضي عدد معين من الخطوات الزمنية أو يفوز / يخسر الوكيل).
كيف يمكننا تصميم وكيل لتعظيم مجموع المكافآت في بيئة معينة؟ يمكننا بناء وكيل يحتوي على مجموعة من القواعد لكيفية الاستجابة لأي حالة لعبة معينة. ومع ذلك ، سرعان ما يصبح هذا غير ممكن حيث تصبح البيئة أكثر تعقيدًا ولا تسمح لنا أبدًا ببناء وكيل يتمتع بقدرة خارقة في مهمة معينة ، لأننا نقوم ببرمجة القواعد يدوياً . يتضمن التعلم المعزز إنشاء وكيل يمكنه تعلم الاستراتيجيات المثلى بنفسه في بيئات معقدة من خلال اللعب المتكرر .
سأقدم الآن OpenAI Gym ، موطن بيئة سباق السيارات التي سنستخدمها لمحاكاة قيادة سيارة حول مضمار.
OpenAI Gym
OpenAI Gym عبارة عن مجموعة أدوات لتطوير خوارزميات التعلم التعزيزي المتوفرة كمكتبة Python.
تحتوي المكتبة على العديد من بيئات التعلم المعززة الكلاسيكية ، مثل CartPole و Pong ، بالإضافة إلى البيئات التي تقدم تحديات أكثر تعقيدًا ، مثل تدريب وكيل على المشي على أرض غير مستوية أو الفوز بلعبة أتاري. توفر جميع البيئات طريقة خطوة يمكنك من خلالها إرسال إجراء معين ؛ ستعيد البيئة الحالة التالية والمكافأة. من خلال استدعاء طريقة الخطوة بشكل متكرر بالإجراءات التي اختارها الوكيل ، يمكنك تشغيل حلقة في البيئة.
بالإضافة إلى الميكانيكا المجردة لكل بيئة ، يوفر OpenAI Gym أيضًا رسومات تسمح لك بمشاهدة أداء وكيلك في بيئة معينة. هذا مفيد لتصحيح الأخطاء والعثور على المجالات التي يمكن لوكيلك تحسينها.
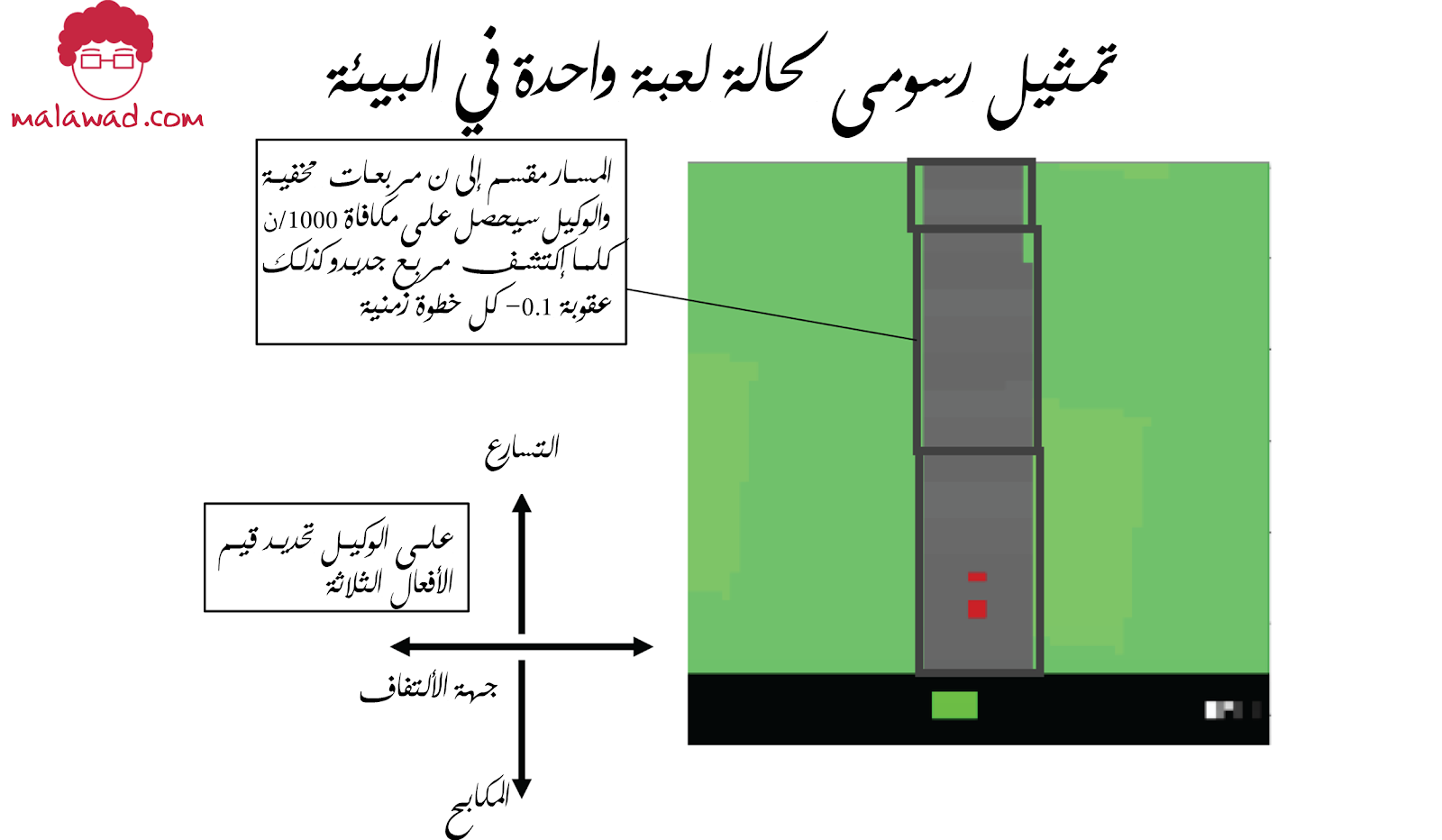
سوف نستفيد من بيئة CarRacing داخل OpenAI Gym. دعونا نرى كيف يتم تحديد حالة اللعبة ، والحركة ، والمكافأة ، والحلقة لهذه البيئة:
حالة اللعبة
صورة RGB 64 × 64 بكسل تصور عرضًا علويًا للمسار والسيارة.
فعل
مجموعة من ثلاث قيم: اتجاه التوجيه (–1 إلى 1) ، والتسارع (0 إلى 1) ، و المكابح (من 0 إلى 1). يجب على الوكيل تعيين جميع القيم الثلاث في كل خطوة زمنية.
مكافأة
عقوبة سلبية قدرها -0.1 لكل خطوة زمنية يتم أخذها ومكافأة موجبة قدرها 1000 / N إذا تمت زيارة مربع مسار جديد ، حيث N هو إجمالي عدد المربعات التي يتكون منها المسار.
حلقة
تنتهي الحلقة عندما تكمل السيارة المسار ، أو تخرج عن حافة البيئة ، أو تنقضي 3000 خطوة زمنية.
يتم عرض هذه المفاهيم في تمثيل رسومي لحالة اللعبة في الصورة التالية لاحظ أن السيارة لا ترى المسار من وجهة نظرها ، ولكن بدلاً من ذلك ، يجب أن نتخيل وكيلاً يطفو فوق المسار يتحكم في السيارة من منظور علوي.
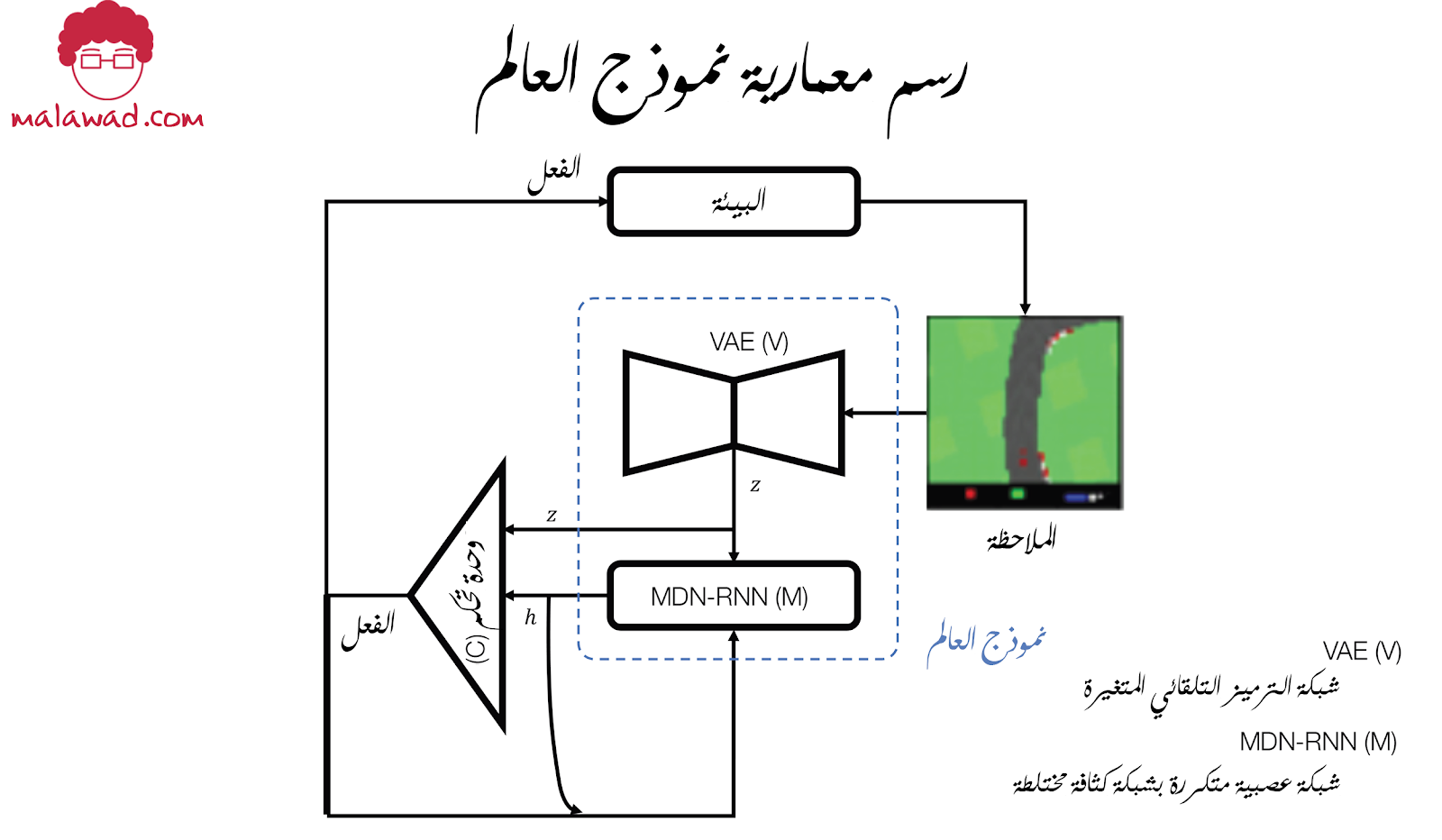
معمارية نموذج العالم
سنغطي الآن نظرة عامة عالية المستوى على المعمارية بأكملها الذي سنستخدمها لبناء الوكيل الذي يتعلم من خلال التعلم المعزز ، قبل أن نستكشف الخطوات التفصيلية المطلوبة لبناء كل مكون.
يتكون الحل من ثلاثة أجزاء متميزة ، كما هو موضح في الصورة أدناه ، يتم تدريبها بشكل منفصل:
- V
شبكة الترميز التلقائي المتغيرة (VAE)
- M
شبكة عصبية متكررة مع شبكة كثافة مختلطة (recurrent neural network with a mixture density network) أو بإختصار (MDN-RNN).
- C
وحدة تحكم.
شبكة الترميز التلقائية المتغيرة
عندما تتخذ قرارات أثناء القيادة ، فأنت لا تقوم بتحليل كل بكسل تراه – بدلاً من ذلك ، تقوم بتكثيف المعلومات المرئية في أقل عدد ممكن من الكيانات الكامنة ، مثل استقامة الطريق ، والانحناءات القادمة ، والموضع النسبي إلى الطريق ، لتساعدك في قراراتك.
.
لقد رأينا في المقالة الرابعة من شبكة الخصومة التوليدية كيف يمكن لـ VAE التقاط صورة إدخال عالية الأبعاد وتكثيفها في متغير عشوائي كامن يتبع تقريبًا التوزيع الطبيعي القياسي متعدد المتغيرات ، من خلال تقليل خطأ إعادة البناء وتباعد KL. هذا يضمن أن الفضاء الكامن مستمر وأننا قادرون على أخذ عينات منه بسهولة لتوليد ملاحظات جديدة ذات مغزى.
في مثال سباق السيارات ، يكثف VAE صورة الإدخال 64 × 64 × 3 (RGB) في متغير عشوائي مكون من 32 بعدًا موزعًا بشكل طبيعي ، يتم تحديد المعايير بواسطة متغيرين ، mu و log_var. هنا ، log_var هو لوغاريتم تباين التوزيع.
يمكننا أخذ عينة من هذا التوزيع لإنتاج متجه كامن z يمثل الحالة الحالية. يتم تمرير هذا إلى الجزء التالي من الشبكة ، MDN-RN.
شبكة عصبية متكررة بشبكة كثافة مختلطة (MDN-RNN)
أثناء القيادة ، لا تشكل كل ملاحظة لاحقة مفاجأة كاملة لك. إذا كانت الملاحظة الحالية تقترح انعطافًا يسارًا في الطريق أمامك وقمت بإدارة العجلة جهة اليسار ، فإنك تتوقع أن تظهر الملاحظة التالية أنك ما زلت على نفس الخط مع الطريق.
إذا لم تكن لديك هذه القدرة ، فمن المحتمل أن تنطلق قيادتك في جميع أنحاء الطريق لأنك لن تكون قادرًا على رؤية أن الانحراف الطفيف عن المركز سيكون أسوأ في الخطوة الزمنية التالية ما لم تفعل شيئًا حيال ذلك الآن.
هذا التفكير المتقدم هو وظيفة MDN-RNN ، وهي شبكة تحاول التنبؤ بتوزيع الحالة الكامنة التالية بناءً على الحالة الكامنة السابقة والإجراء السابق.
على وجه التحديد ، تعد MDN-RNN طبقة LSTM بها 256 وحدة مخفية متبوعة بطبقة إخراج شبكة كثافة مختلطة (MDN) تسمح بحقيقة أن الحالة الكامنة التالية يمكن استخلاصها فعليًا من أي واحد من التوزيعات العادية المتعددة.
تم تطبيق نفس الأسلوب بواسطة أحد مؤلفي ورقة “نموذج العالم” ، ديفيد ها ، على مهمة إنشاء خط اليد ، كما هو موضح في الصورة أدناه ، لوصف حقيقة أن نقطة القلم التالية يمكن أن تهبط في أي من المناطق الحمراء المميزة.

في مثال سباق السيارات ، نسمح باستخلاص كل عنصر من الحالة الكامنة التالية المرصودة من أي واحد من التوزيعات الخمسة العادية.
المتحكم
حتى هذه النقطة ، لم نذكر أي شيء عن اختيار الفعل . تقع هذه المسؤولية على عاتق المتحكم.
وحدة التحكم عبارة عن شبكة عصبية كثيفة متصلة ، حيث يكون الإدخال عبارة عن سلسلة من z (الحالة الكامنة الحالية المأخوذة من التوزيع المشفر بواسطة VAE) والحالة المخفية لـ RNN. تتوافق الخلايا العصبية الثلاثة الناتجة مع الإجراءات الثلاثة (الدوران ، والتسريع ، والفرامل) ويتم ضبط حجمها لتقع في النطاقات المناسبة.
سنحتاج إلى تدريب وحدة التحكم باستخدام التعلم المعزز حيث لا توجد مجموعة بيانات تدريب تخبرنا أن إجراءً معينًا جيد والآخر سيء. بدلاً من ذلك ، سيحتاج الوكيل إلى اكتشاف هذا بنفسه من خلال التجارب المتكررة.
إن جوهر ورقة “نموذج العالم” هو أنها توضح كيف يمكن أن يحدث هذا التعلم المعزز داخل النموذج التوليدي الخاص بالوكيل للبيئة ، بدلاً من بيئة OpenAI Gym.
لفهم الأدوار المختلفة للمكونات الثلاثة وكيفية عملها معًا ، يمكننا أن نتخيل حوارًا بينها:
- VAE: (بالنظر إلى أحدث ملاحظة 64 × 64 × 3): هذا يبدو كطريق مستقيم ، مع اقتراب منحنى يسار طفيف ، مع مواجهة السيارة في اتجاه الطريق (z).
- RNN: استنادًا إلى هذا الوصف (z) وحقيقة أن وحدة التحكم قد اختارت الإسراع بشدة في الخطوة الزمنية الأخيرة (الفعل) ، سأقوم بتحديث حالتي المخفية بحيث يُتوقع أن تظل الملاحظة التالية طريقًا مستقيمًا ، ولكن مع ظهور بسيط لمنعطف على اليسار .
- المتحكم: استنادًا إلى الوصف من VAE (z) والحالة المخفية الحالية من RNN (h) ، تُخرج شبكتي العصبية [0.34 ، 0.8 ، 0] كإجراء تالي.
يتم بعد ذلك تمرير الإجراء من وحدة التحكم إلى البيئة ، والتي تقوم بإرجاع ملاحظة محدثة ، وتبدأ الدورة مرة أخرى.
لمزيد من المعلومات حول النموذج ، يوجد أيضًا شرح تفاعلي ممتاز متاح عبر الإنترنت (هنا).
تجهيز النظام
نحن الآن جاهزون لبدء استكشاف كيفية بناء وتدريب هذا النموذج في Keras. إذا كان لديك جهاز كمبيوتر عالي المواصفات ، فيمكنك تشغيل الحل محليًا ، لكني أوصي باستخدام موارد السحابة مثل Google Cloud Compute Engine للوصول إلى الأجهزة القوية التي يمكنك استخدامها.
ملحوظة
تم اختبار الكود التالي على Ubuntu 16.04 ، لذلك فهو خاص بــ Linux.
قم أولاً بتثبيت المكتبات التالية:
sudo apt-get install cmake swig python3-dev \ zlib1g-dev python-opengl mpich xvfb \ xserver-xephyr vnc4server
ثم إنسخ هذه الريبو :
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
أقترح إنشاء بيئة افتراضية منفصلة للعمل فيها:
mkvirtualenv worldmodels cd WorldModels pip install -r requirements.txt
الأن نحن جاهزون
نظرة عامة على عملية التدريب
فيما يلي نظرة عامة على عملية التدريب المكونة من خمس خطوات:
أولاً : اجمع بيانات الطرح (rollout) العشوائي هنا ، لا يهتم الوكيل بالمهمة المحددة ، ولكنه بدلاً من ذلك يستكشف البيئة بشكل عشوائي. سيتم إجراء ذلك باستخدام OpenAI Gym لمحاكاة العديد من الحلقات وتخزين الحالة المرصودة والإجراء والمكافأة في كل خطوة زمنية. الفكرة هنا هي بناء مجموعة بيانات عن كيفية عمل فيزياء البيئة ، والتي يمكن أن يتعلم منها VAE بعد ذلك لالتقاط الحالات بكفاءة كمتجهات كامنة. يمكن لـ MDN-RNN بعد ذلك أن تتعلم كيف تتطور المتجهات الكامنة (latent vectors) بمرور الوقت.
ثانيا: تدريب VAE باستخدام البيانات التي تم جمعها عشوائيًا ، نقوم بتدريب VAE على صور المراقبة.
ثالثا: اجمع البيانات لتدريب MDN-RNN بمجرد أن يكون لدينا VAE مدرب ، نستخدمه لترميز كل من الملاحظات المجمعة في متجهات mu و log_var ، والتي يتم حفظها جنبًا إلى جنب مع الإجراء الحالي والمكافأة.
رابعاً : تدريب MDN-RNN نأخذ دفعات من 100 حلقة ونحمّل متغيرات mu و log_var والإجراء والمكافأة المقابلة في كل خطوة زمنية تم إنشاؤها في الخطوة 3. ثم نقوم بتجربة متجه z من متجهي mu و log_var. بالنظر إلى متجه z الحالي ، و الفعل، والمكافأة ، يتم بعد ذلك تدريب MDN-RNN على التنبؤ بالمتجه z التالي والمكافأة.
خامساً: تدريب وحدة التحكم باستخدام VAE و RNN المدربين ، يمكننا الآن تدريب وحدة التحكم على إخراج فعل بإعطائها الحالة z الحالية والحالة المخفية ، h ، من RNN. تستخدم وحدة التحكم خوارزمية تطورية (evolutionary algorithm ) تعرف بإسم استراتيجية تطور تكيف مصفوفة التغاير (Covariance Matrix Adaptation Evolution Strategy) أو بإختصار CMA-ES كمحسِّن لها. تكافئ الخوارزمية أوزان المصفوفة التي تولد إجراءات تؤدي إلى درجات عالية بشكل إجمالي في المهمة ، بحيث من المرجح أيضًا أن ترث الأجيال القادمة هذا السلوك المطلوب.
دعنا الآن نلقي نظرة فاحصة على كل خطوة من هذه الخطوات بمزيد من التفصيل.
جمع بيانات الطرح العشوائي (Collecting Random Rollout Data)
لبدء جمع البيانات ، قم بتشغيل الأمر التالي من الترمنل :
bash 01_generate_data.sh <env_name> <parallel_process> <episodes_per_process> \ <render> <action_refresh_rate>
حيث تكون المعايير كما يلي:
<env_name>
اسم البيئة التي تستخدمها دالة make_env (على سبيل المثال ، car_racing).
<parallel_process>
عدد الأنوية المراد إستخدامها (على سبيل المثال ، 8 لجهاز ثماني النواة).
<episodes_per_process>
كم عدد الحلقات التي يجب على كل نواة تشغيلها (على سبيل المثال ، 125 ، لذلك 8 أنوية ستنشئ 1000 حلقة).
<max_timesteps>
الحد الأقصى لعدد الخطوات الزمنية لكل حلقة (على سبيل المثال ، 300).
<render>
1 لعرض عملية الطرح في نافذة (وإلا 0).
<action_refresh_rate>
عدد الخطوات الزمنية لتجميد الإجراء الحالي قبل التغيير. يمنع هذا الإجراء من التغيير بسرعة كبيرة بحيث لا تتمكن السيارة من إحراز تقدم.
على سبيل المثال ، على جهاز ثماني النواة ، يمكنك تشغيل:
bash 01_generate_data.sh car_racing 8 125 300 0 5
سيؤدي ذلك إلى إستخدام 8 أنوبة تعمل بالتوازي ، كل منها تحاكي 125 حلقة ، بحد أقصى 300 خطوة زمنية لكل منها ومعدل تحديث للإجراء يبلغ 5 خطوات زمنية.
تستدعي كل عملية ملف Python 01_generate_data.py. تم تحديد الجزء الرئيسي من البرمجة أدناه :
# ...
DIR_NAME = './data/rollout/'
env = make_env(current_env_name) #1
s = 0
while s < total_episodes:
episode_id = random.randint(0, 2**31-1)
filename = DIR_NAME + str(episode_id)+".npz"
observation = env.reset()
env.render()
t = 0
obs_sequence = []
action_sequence = []
reward_sequence = []
done_sequence = []
reward = -0.1
done = False
while t < time_steps:
if t % action_refresh_rate == 0:
action = config.generate_data_action(t, env) #2
observation = config.adjust_obs(observation) #3
obs_sequence.append(observation)
action_sequence.append(action)
reward_sequence.append(reward)
done_sequence.append(done)
observation, reward, done, info = env.step(action) #4
t = t + 1
print("Episode {} finished after {} timesteps".format(s, t))
np.savez_compressed(filename
, obs=obs_sequence
, action=action_sequence
, reward = reward_sequence
, done = done_sequence) #5
s = s + 1
env.close()
1- make_env هي دالة مخصصة تنشئ بيئة OpenAI Gym المناسبة. في هذه الحالة ، نقوم بإنشاء بيئة CarRacing ، مع بعض التعديلات. يتم تخزين ملف البيئة في مجلد custom_envs.
2- create_data_action هي دالة مخصصة تخزن قواعد إنشاء أفعال عشوائية.
3- يتم قياس الملاحظات التي يتم إرجاعها بواسطة البيئة بين 0 و 255. نريد الملاحظات التي يتم قياسها بين 0 و 1 ، لذلك هذه الوظيفة هي ببساطة قسمة على 255.
4- تتضمن كل بيئة OpenAI Gym طريقة خطوة (step method) . هذه تعطي الملاحظة التالية ، والمكافأة ، وعلامة الإكتمال ، لكل فعل .
5- نقوم بحفظ كل حلقة كملف فردي داخل المجلد ./data/rollout/.
توضح الصورة التالية مقتطفًا للإطارات من 40 إلى 59 من حلقة واحدة ، يوضح اقتراب السيارة من زاوية ، بالإضافة إلى الفعل (a) والمكافأة (r) المختارين عشوائيًا. لاحظ كيف تتغير المكافأة إلى 3.22 عندما تتخطى السيارة مربع مسار جديد ولكنها بخلاف ذلك –0.1. أيضًا ، يتغير الإجراء كل خمسة إطارات حيث أن قيمة action_refresh_rate هي 5.

تدريب شبكة الترميز التلقائية المتغيرة ( VAE)
يمكننا الآن بناء نموذج توليدي (VAE) على هذه البيانات المجمعة.
تذكر أن الهدف من VAE هو السماح لنا بطوي صورة 64 × 64 × 3 إلى متغير عشوائي موزع بشكل طبيعي ، يتم تحديد معايير توزيعه بواسطة متجهين ، mu و log_var. كل من هذه المتجهات بطول 32.
لبدء تدريب VAE ،سنقوم بتشغيل الأمر التالي :
python 02_train_vae.py --new_model [--N] [--epochs]
حيث تكون المعايير كما يلي:
–new_model
سواءً كان ينبغي تدريب النموذج من الصفر أو لا علينا إضافة هذا المعييار في البداية . و إلا فسيقوم البرنامج بالبحث عن الملف ./vae/vae.json و يواصل تدريب النموذج السابق.
–N (اختياري)
عدد الحلقات التي يجب استخدامها عند تدريب VAE (على سبيل المثال ، 1000 – لا يحتاج VAE إلى استخدام جميع الحلقات لتحقيق نتائج جيدة ، لذلك لتسريع التدريب ، يمكنك استخدام عينة فقط من الحلقات).
–epochs (اختياري)
عدد حقب التدريب (على سبيل المثال ، 3).
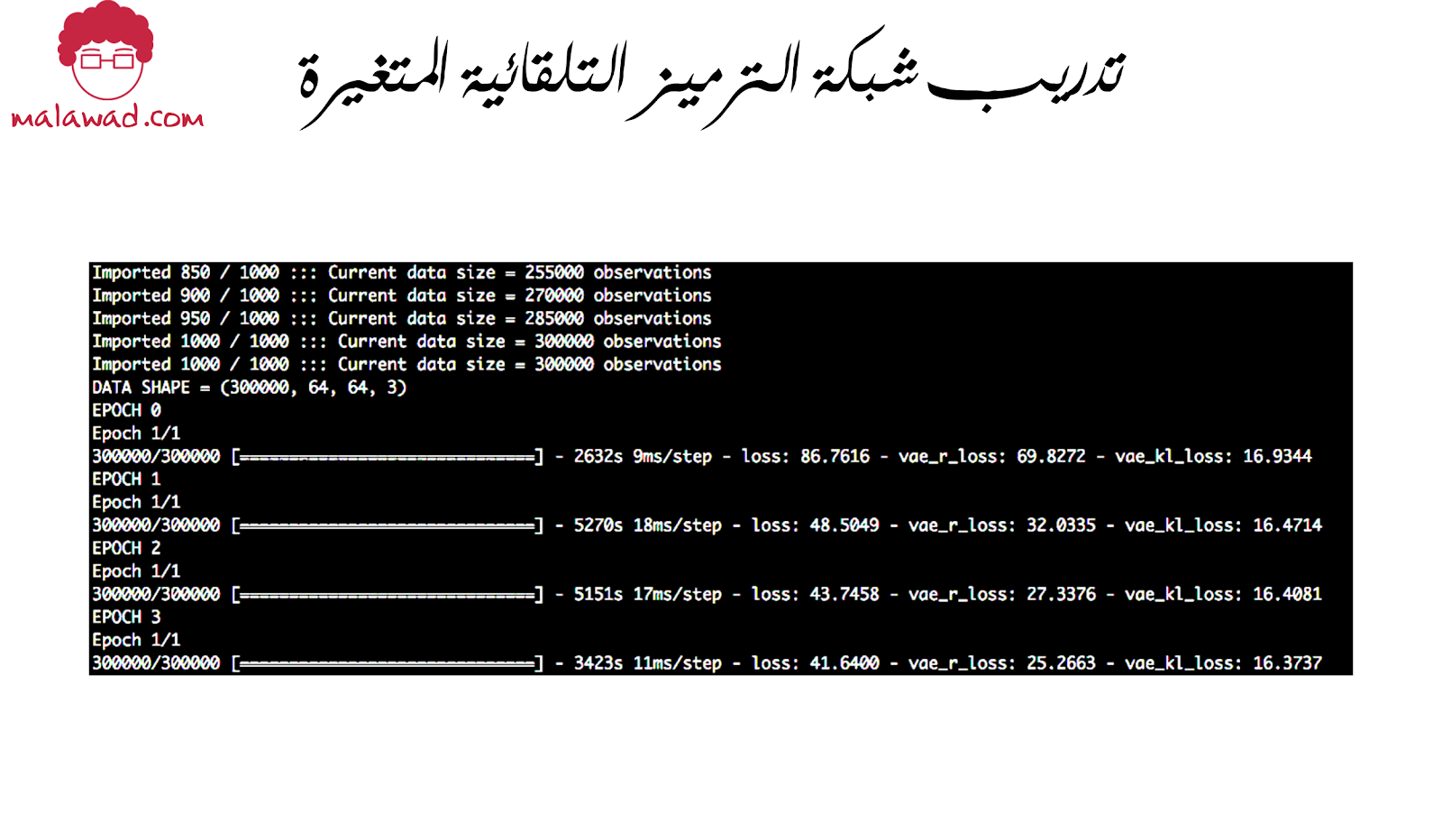
يجب أن تكون مخرجات عملية التدريب كما هي موضحه في الصورة التالية . يتم حفظ ملف يخزن أوزان الشبكة المدربة في ./vae/vae.json كل حقبة.
معمارية شبكة الترميز التلقائية المتغيرة ( VAE)
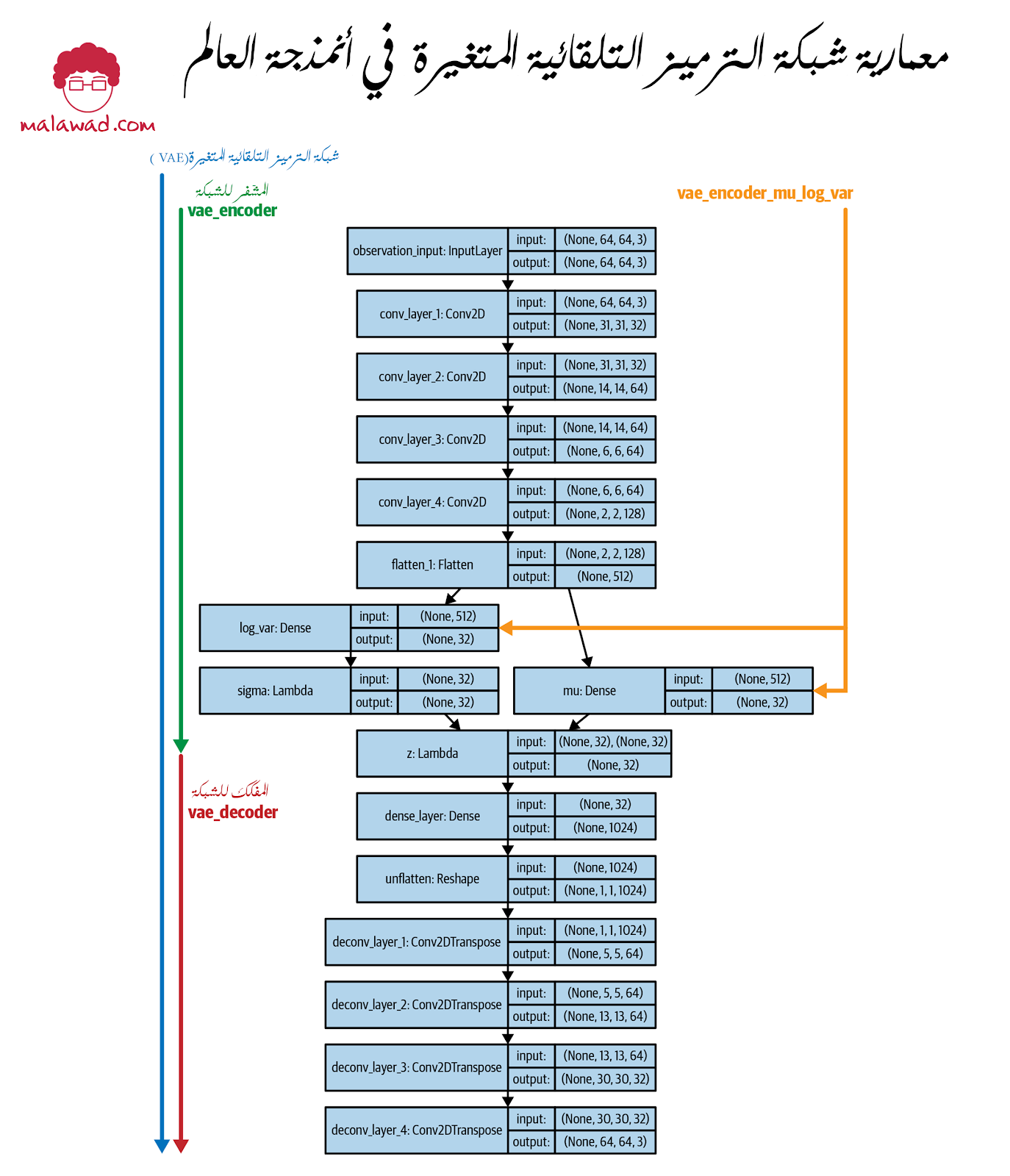
كما رأينا سابقًا ، يمنحنا Keras ليس فقط إمكانية تحديد نموذج VAE الكامل الذي سيتم تدريبه ، ولكن أيضًا النماذج الإضافية التي تشير إلى أجزاء التشفير وفك التشفير من الشبكة المدربة بشكل منفصل. ستكون هذه مفيدة عندما نريد تشفير صورة معينة ، أو فك تشفير متجه z معين ، على سبيل المثال.
في هذا المثال ، نحدد أربعة نماذج مختلفة على VAE:
full_model
هذا هو النموذج الكامل الذي يتم تدريبه.
encoder
هذا يقبل ملاحظة 64 × 64 × 3 كمدخلات و يخرج متجه z. إذا قمنا بأستخدام predict method لهذا النموذج لنفس الإدخال عدة مرات ، فستحصل على مخرجات مختلفة ، لأنه على الرغم من ثبات قيم mu و log_var ، فإن متجه z الذي تم أخذ عينات منه عشوائيًا سيكون مختلفًا في كل مرة.
encoder_mu_log_var
هذا يقبل ملاحظة 64 × 64 × 3 كمدخلات و يخرج المتجهتين mu و log_var المقابلة لهذا الإدخال. على عكس نموذج vae_encoder ، إذا قمنا بأستخدام predict method عدة مرات ، فستحصل دائمًا على نفس الإخراج: متجه mu بطول 32 ومتجه log_var بطول 32.
decoder
هذا يقبل متجه z كمدخل ويعيد الملاحظة 64 × 64 × 3 المعاد بناؤها
و الصورة التالية توضح المعمارية الكاملة للشبكة ، يمكننا تعديل VAE عن طريق تحرير ملف ./vae/arch.py.
استكشاف شبكة الترميز التلقائية المتغيرة ( VAE)
سنلقي الآن نظرة على ناتج طرق التنبؤ للنماذج المختلفة المبنية على VAE لنرى كيف تختلف ، ثم نرى كيف يمكن استخدام VAE لإنشاء ملاحظات مسار جديدة تمامًا.
النموذج الكامل
إذا قمنا بتغذية النموذج full_model بملاحظة ، فإنه قادر على إعادة بناء تمثيل دقيق للصورة ، كما هو موضح أدناه هذا مفيد للتحقق بصريًا من أن VAE يعمل بشكل صحيح.

نماذج التشفير (The encoder models)
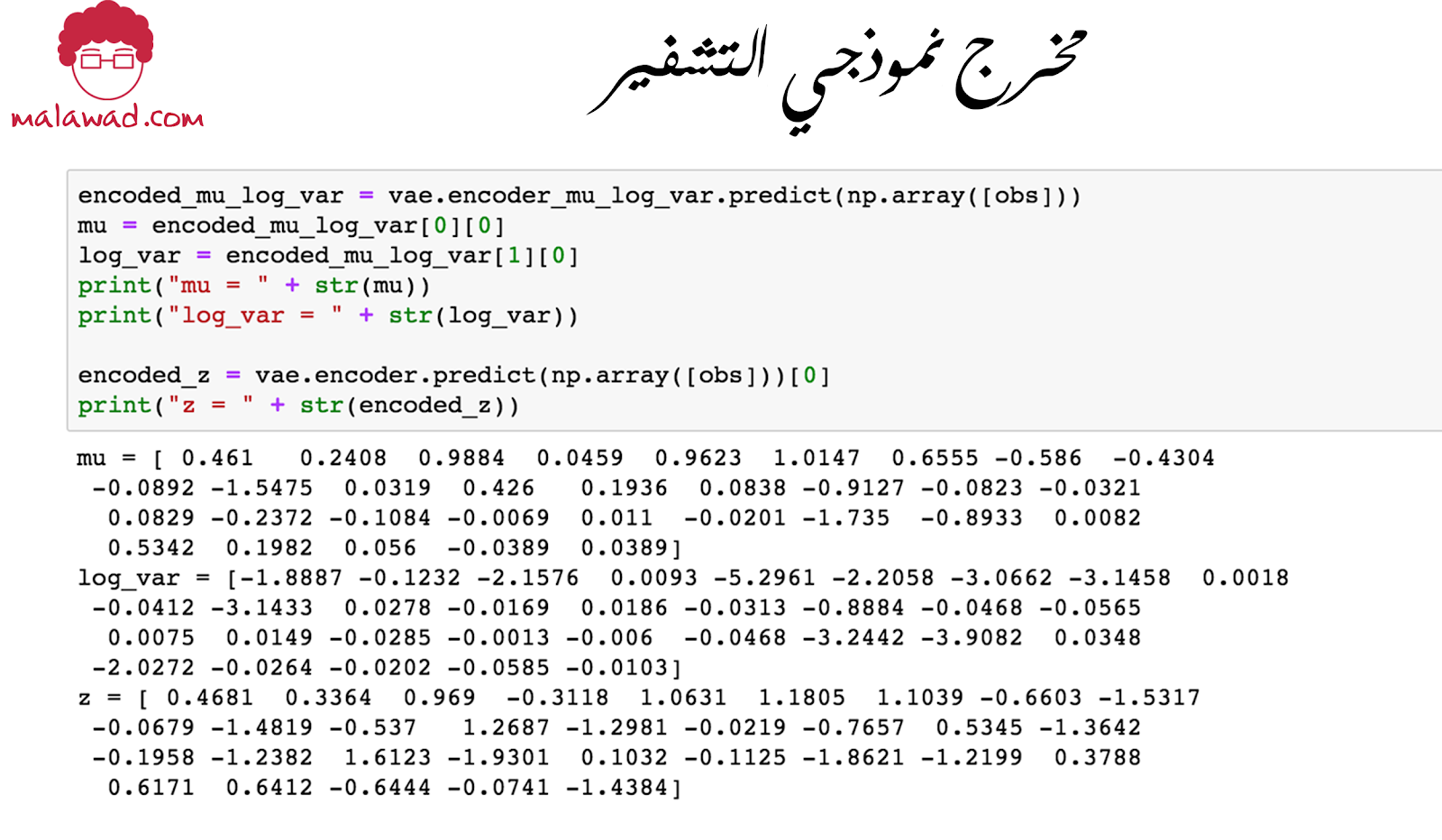
إذا قمنا بتغذية نموذج encoder_mu_log_var بملاحظة ، فإن الناتج هو المتجهتين mu و log_var التي تم إنشاؤها والتي تصف التوزيع الطبيعي متعدد المتغيرات (multivariate normal distribution) .
بينما يقوم نموذج encoder_z بخطوة إضافية عن طريق أخذ عينات متجه z معينه من هذا التوزيع.
يظهر مخرجي هذين النموذجين أدناه .
من المثير للاهتمام هو رسم قيم mu و log_var لكل من الأبعاد الـ 32 لملاحظة معينة.

لاحظ كيف يختلف 12 بُعدًا فقط من 32 بُعدًا اختلافًا كبيرًا عن التوزيع الطبيعي القياسي (mu = 0 ، log_var = 0). هذا لأن VAE يحاول تقليل تباعد KL ، مما يعني الاختلاف عن التوزيع الطبيعي القياسي في أقل عدد ممكن من الأبعاد. , و بالتالي قرر النموذج أن 12 بُعدًا كافية لالتقاط معلومات كافية حول الملاحظات لتحقيق إعادة بناء دقيقة.
نموذج فك التشفير (decoder model)
يقبل المفكك متجه z كمدخل ويعيد بناء الصورة الأصلية. في الصورة أدناه ، نولد خطيًا ( linearly interpolate
) اثنين من أبعاد z لإظهار كيف يبدو أن كل بُعد يشفر جانبًا معينًا من المسار – على سبيل المثال ، يتحكم z [4] في الاتجاه الأيسر / الأيمن المباشر للمسار الأقرب للسيارة و z [7] يتحكم في حدة الانعطاف لليسار المقترب.
.

يوضح هذا أن المساحة الكامنة التي تعلمها VAE مستمرة ويمكن استخدامها لإنشاء مقاطع مسار جديدة لم يلاحظها الوكيل من قبل.
جمع البيانات لتدريب ال RNN
الآن بعد أن أصبح لدينا VAE مدربًا ، يمكننا استخدام هذا لإنشاء بيانات تدريب لـ RNN الخاص بنا.
في هذه الخطوة ، نقوم بتمرير جميع بيانات النشر العشوائي (random rollout) من خلال نموذج encoder_mu_log_var وتخزين متجهات mu و log_var المقابلة لكل ملاحظة. سيتم استخدام هذه البيانات المشفرة ، جنبًا إلى جنب مع الإجراءات والمكافآت التي تم جمعها بالفعل ، لتدريب MDN-RNN.
لبدء جمع البيانات ، نستخدم الأمر التالي
python 03_generate_rnn_data.py
لدينا أدنا مقتطف من ملف 03_generate_data.py يوضح كيفية إنشاء بيانات تدريب MDN-RNN.
def encode_episode(vae, episode):
obs = episode['obs']
action = episode['action']
reward = episode['reward']
done = episode['done']
mu, log_var = vae.encoder_mu_log_var.predict(obs) #1
done = done.astype(int)
reward = np.where(reward>0, 1, 0) * np.where(done==0, 1, 0) #2
initial_mu = mu[0, :]
initial_log_var = log_var[0, :]
return (mu, log_var, action, reward, done, initial_mu, initial_log_var)
vae = VAE()
vae.set_weights('./vae/weights.h5')
for file in filelist:
rollout_data = np.load(ROLLOUT_DIR_NAME + file)
mu, log_var, action, reward, done, initial_mu
, initial_log_var = encode_episode(vae, rollout_data)
np.savez_compressed(SERIES_DIR_NAME + file, mu=mu, log_var=log_var
, action = action, reward = reward, done = done)
initial_mus.append(initial_mu)
initial_log_vars.append(initial_log_var)
np.savez_compressed(ROOT_DIR_NAME + 'initial_z.npz', initial_mu=initial_mus
, initial_log_var=initial_log_vars) #3
1- هنا ، نحن نستخدم نموذج encoder_mu_log_var من VAE للحصول على متجهات mu و log_var لملاحظة معينة.
2- يتم تحويل قيمة المكافأة لتكون إما 0 أو 1 ، بحيث يمكن استخدامها كمدخلات في MDN-RNN.
3- نقوم أيضًا بحفظ متجهي mu و log_var الأوليين في ملف منفصل — سيكون هذا مفيدًا لاحقًا ، لتهيئة بيئة الأحلام.
تدريب الشبكة العصبية المتكررة مع شبكة الكثافة المختلطة ( MDN-RNN)
يمكننا الآن تدريب MDN-RNN على التنبؤ بتوزيع متجه z التاليه والمكافأة ، بالنظر إلى قيمة z الحالية ، و الفعل الحالي ، والمكافأة السابقة.
الهدف من MDN-RNN هو التنبؤ بخطوة زمنية واحدة في المستقبل – يمكننا بعد ذلك استخدام الحالة المخفية الداخلية لـ LSTM كجزء من الإدخال في وحدة التحكم.
لبدء تدريب MDN-RNN ،سنستخدم الأمر التالي :
python 04_train_rnn.py (--new_model) (--batch_size) (--steps)
و المعايير كما يلي:
–new_model
سواءً كان ينبغي تدريب النموذج من الصفر أو لا علينا إضافة هذا المعييار في البداية . و إلا فسيقوم البرنامج بالبحث عن الملف ./rnn/rnn.json و يواصل تدريب النموذج السابق.
–batch_size
عدد الحلقات التي يتم تغذيتها إلى MDN-RNN في كل تكرار تدريب.
–steps
العدد الإجمالي لتكرارات التدريب.
يظهر ناتج عملية التدريب في أدناه . يتم حفظ ملف يخزن أوزان الشبكة المدربة في ./rnn/rnn.json كل 10 خطوات.

معمارية الشبكة العصبية المتكررة مع شبكة الكثافة المختلطة ( MDN-RNN)
تظهر المعمارية في الصورة أدناه
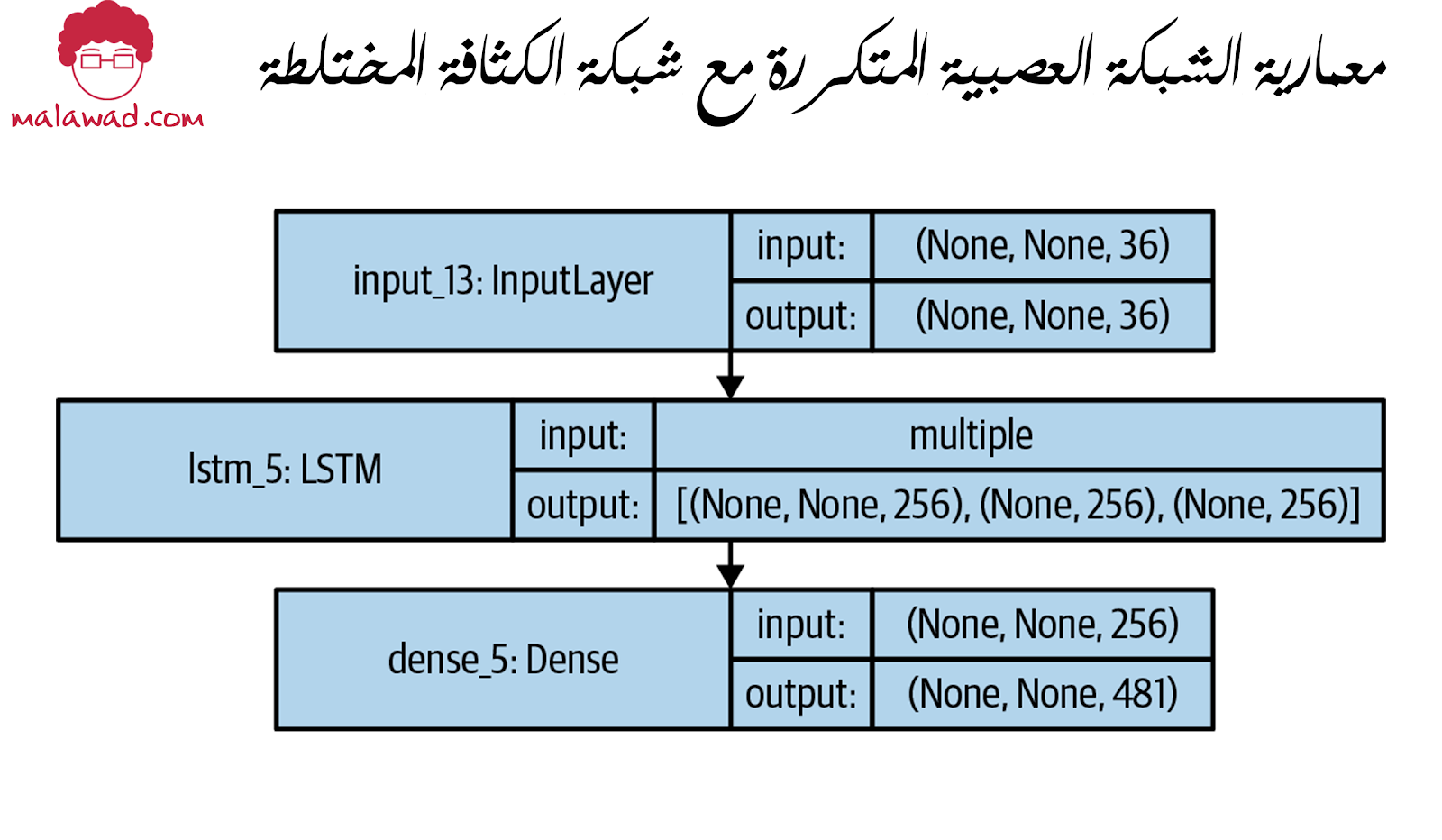
يتكون من طبقة LSTM ( وهي RNN) ، متبوعة بطبقة متصلة بكثافة (MDN) تحول الحالة المخفية لـ LSTM إلى معايير توزيع الخليط. لننتقل عبر الشبكة خطوة بخطوة.
المدخل إلى طبقة LSTM هو متجه بطول 36 – سلسلة من متجه z المشفر (الطول 32) من VAE ، الإجراء الحالي (الطول 3) ، والمكافأة السابقة (الطول 1).
الناتج من طبقة LSTM هو متجه بطول 256 – قيمة واحدة لكل خلية LSTM في الطبقة. يتم تمرير هذا إلى MDN ، وهي مجرد طبقة متصلة بكثافة تحول متجه الطول 256 إلى متجه بطول 481.
لماذا 481؟ توضح الصورة أدناه تكوين الناتج من MDN-RNN.
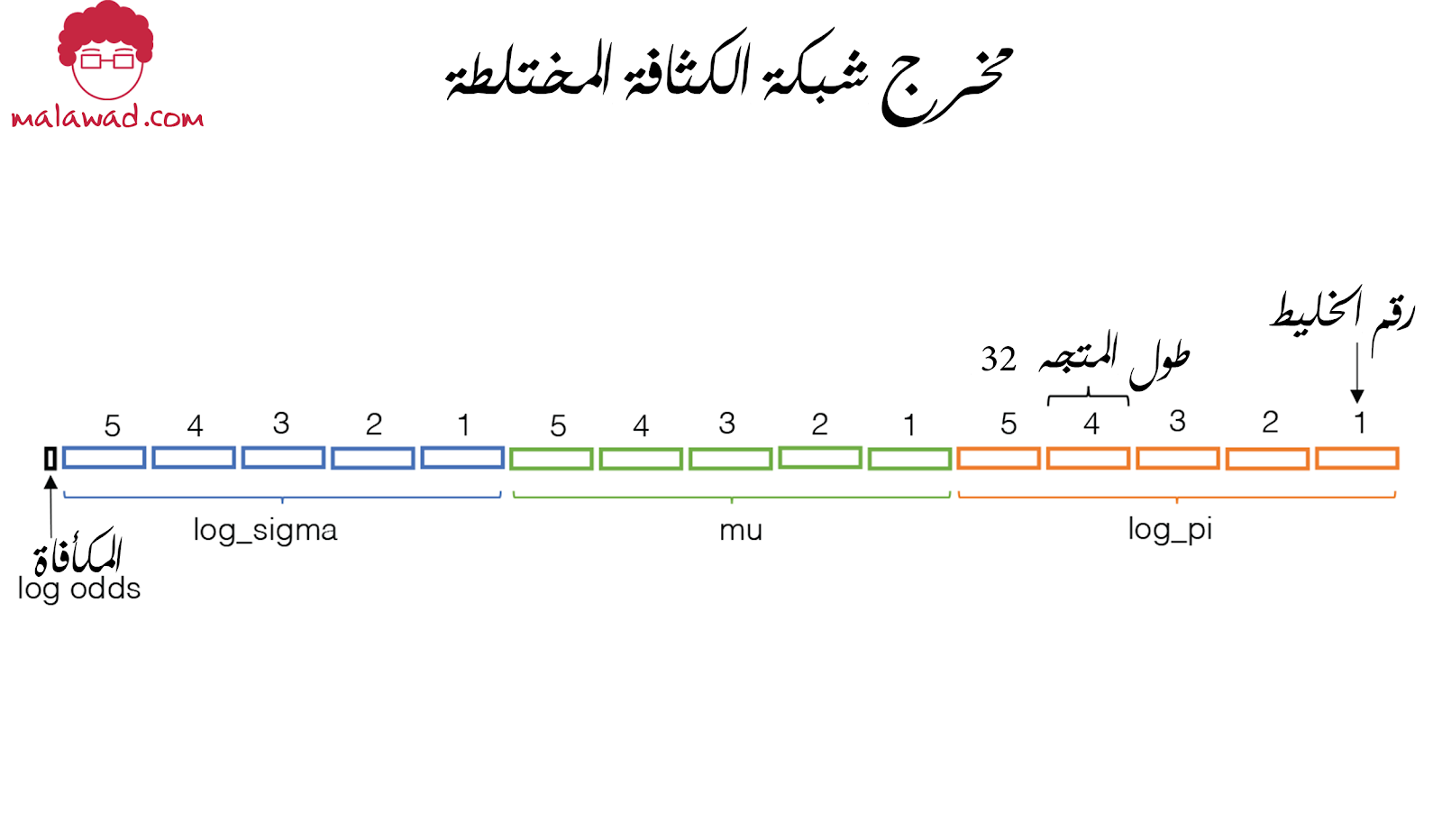
تذكر أن الهدف من شبكة الكثافة المختلطة هو نمذجة حقيقة أن z التالية يمكن استخلاصها من أحد التوزيعات العديدة الممكنة باحتمالية معينة.
في مثال سباق السيارات ، نختار خمسة توزيعات عادية. كم عدد المعايير التي نحتاجها لتحديد هذه التوزيعات؟ لكل من المخاليط الخمسة ، نحتاج إلى mu و log_sigma (لتحديد التوزيع) واحتمال اختيار هذا الخليط (log_pi) ، لكل من أبعاد z البالغ عددها 32.
هذا يجعل 5 × 3 × 32 = 480 معلمة. المعامل الإضافي الوحيد هو توقع المكافأة – وبشكل أكثر تحديدًا ، سجل احتمالات المكافأة في الخطوة الزمنية التالية.
أخذ عينات z التاليه والمكافأة من MDN-RNN
يمكننا أخذ عينة من ناتج MDN لإنشاء توقع لـ z التالية والمكافأة في الخطوة الزمنية التالية ، من خلال العملية التالية:
1- قسّم متجه الإخراج 481 بعدًا إلى 3 متغيرات (log_pi ، mu ، log_sigma) وقيمة المكافأة.
2- نغير حجم log_pi بحيث يمكن تفسيره على أنه 32 توزيع احتمالي على علامات الخليط الخمسة.
3- لكل بُعد من أبعاد z البالغ عددها 32 ، إختار عينة من التوزيعات التي تم إنشاؤها من log_pi (على سبيل المثال ، اختر أيًا من التوزيعات الخمسة يجب استخدامه لكل بُعد من أبعاد z).
4- قم بإحضار قيم mu و log_sigma المقابلة لهذا التوزيع.
5- إختار قيمة لكل بُعد من أبعاد z من معايير التوزيع الطبيعي بواسطة المعييارين المختارين لكل من mu و log_sigma لهذا البعد.
6-إذا كانت قيمة احتمالات سجل (log odds) المكافأة أكبر من 0 ، فتوقع 1 للمكافأة ؛ خلاف ذلك ، توقع 0.
دالة خسارة MDN-RNN
دالة الخسارة لـ MDN-RNN هي مجموع خسارة إعادة بناء متجه z وخسارة المكافأة.
يوضح المقتطف التالي من ملف rnn / arch.py الخاص بـ MDN-RNN كيف نقوم ببناء دالة الخسارة المخصصة في Keras.
def get_responses(self, y_true):
z_true = y_true[:,:,:Z_DIM]
rew_true = y_true[:,:,-1]
return z_true, rew_true
def get_mixture_coef(self, z_pred):
log_pi, mu, log_sigma = tf.split(z_pred, 3, 1)
log_pi = log_pi - K.log(K.sum(K.exp(log_pi), axis = 1, keepdims = True))
return log_pi, mu, log_sigma
def tf_lognormal(self, z_true, mu, log_sigma):
logSqrtTwoPI = np.log(np.sqrt(2.0 * np.pi))
return -0.5 * ((z_true - mu) / K.exp(log_sigma)) ** 2 - log_sigma - logSqrtTwoPI
def rnn_z_loss(y_true, y_pred):
z_true, rew_true = self.get_responses(y_true)
d = normal distribution_MIXTURES * Z_DIM
z_pred = y_pred[:,:,:(3*d)]
z_pred = K.reshape(z_pred, [-1, normal distribution_MIXTURES * 3])
log_pi, mu, log_sigma = self.get_mixture_coef(z_pred) #1
flat_z_true = K.reshape(z_true,[-1, 1])
z_loss = log_pi + self.tf_lognormal(flat_z_true, mu, log_sigma) #2
z_loss = -K.log(K.sum(K.exp(z_loss), 1, keepdims=True))
z_loss = K.mean(z_loss)
return z_loss
def rnn_rew_loss(y_true, y_pred):
z_true, rew_true = self.get_responses(y_true) #, done_true
d = normal distribution_MIXTURES * Z_DIM
reward_pred = y_pred[:,:,-1]
rew_loss = K.binary_crossentropy(rew_true, reward_pred, from_logits = True) #3
rew_loss = K.mean(rew_loss)
return rew_loss
def rnn_loss(y_true, y_pred):
z_loss = rnn_z_loss(y_true, y_pred)
rew_loss = rnn_rew_loss(y_true, y_pred)
return Z_FACTOR * z_loss + REWARD_FACTOR * rew_loss #4
opti = Adam(lr=LEARNING_RATE)
model.compile(loss=rnn_loss, optimizer=opti, metrics = [rnn_z_loss, rnn_rew_loss])
1- قسّم متجه الإخراج 481 بعدًا إلى 3 متغيرات (log_pi ، mu ، log_sigma) وقيمة المكافأة.
2- هذا هو حساب خسارة إعادة بناء متجه z: احتمالية السجل السلبي لمراقبة z الحقيقية ، في ظل توزيع المزيج المحدد بواسطة الناتج من MDN-RNN. نريد أن تكون هذه القيمة كبيرة قدر الإمكان ، أو بشكل مكافئ ، نسعى لتقليل احتمالية السجل السلبي.
3- بالنسبة لخسارة المكافأة ، نستخدم ببساطة الانتروبيا الثنائية بين المكافأة الحقيقية واحتمالات السجل المتوقعة من الشبكة.
4- الخسارة هي مجموع خسارة إعادة البناء z وخسارة المكافأة – قمنا بتعيين معايير الترجيح Z_FACTOR و REWARD_FACTOR على حد سواء على 1 ، على الرغم من أنه يمكن تعديلها لتحديد أولويات خسارة إعادة البناء أو خسارة المكافأة.
لاحظ أنه لتدريب MDN-RNN ، لا نحتاج إلى أخذ عينات من متجهات z محددة من إخراج MDN ، ولكن بدلاً من ذلك نحسب الخسارة مباشرةً باستخدام متجه الإخراج ذات 481 بعدًا.
تدريب وحدة التحكم
تتمثل الخطوة الأخيرة في تدريب وحدة التحكم (الشبكة التي تُخرج الفعل المختار) باستخدام خوارزمية تطورية تسمى استراتيجية تطور مصفوفة التباين المشترك (Covariance Matrix Adaptation Evolution Strategy) أو بإخنصار CMA-ES .
لبدء تدريب وحدة التحكم ، نستخدم الأمر التالي :
xvfb-run -a -s "-screen 0 1400x900x24" python 05_train_controller.py car_racing -n 16 -t 2 -e 4 --max_length 1000
حيث تكون المعايير كما يلي:
n
عدد العمال الذين سيختبرون الحلول بالتوازي (يجب ألا يكون هذا أكبر من عدد الأنوية على جهازك)
t
عدد الحلول التي سيُعطى لكل عامل لاختبارها في كل جيل
e
عدد الحلقات التي سيتم اختبار كل حل مقابلها لحساب متوسط المكافأة
max_length
أقصى عدد من الإطارات الزمنية في كل حلقة
eval_steps
عدد الأجيال بين تقييمات أفضل مجموعة معايير حالية
يستخدم الأمر أعلاه مخزن إطار افتراضي (virtual frame buffer) أو بإختصار (xvfb) لعرض الإطارات ، بحيث يمكن تشغيل الكود على جهاز Linux بدون شاشة فعلية. حجم التعداد ، pop_size = n * t.
معمارية وحدة التحكم
معمارية وحدة التحكم بسيطة للغاية. إنها شبكة عصبية متصلة بكثافة بدون طبقة مخفية ؛ يربط متجه الإدخال مباشرة إلى متجهة الفعل .
متجه الإدخال عبارة عن سلسلة من متجه z الحالي (الطول 32) والحالة المخفية الحالية لـ LSTM (الطول 256) ، مما يعطي متجهًا بطول 288. نظرًا لأننا نربط كل وحدة إدخال مباشرة بوحدات الفعل المخرجة الثلاث ، إجمالي عدد الأوزان المراد ضبطها هو 288 × 3 = 864 ، بالإضافة إلى 3 أوزان تحيز ، أي 867 في المجموع.
كيف يجب تدريب هذه الشبكة؟ لاحظ أن هذه ليست مشكلة تعلم خاضعة للإشراف – فنحن لا نحاول التنبؤ بالفعل الصحيح. لا توجد مجموعة تدريب من الأفعال الصحيحة ، لأننا لا نعرف ما هو الفعل الأمثل لحالة معينة من البيئة.
هذا ما يميز هذا على أنه مشكلة تعلم معزز. نحتاج إلى الوكيل لاكتشاف القيم المثلى للأوزان نفسها من خلال التجربة داخل البيئة وتحديث أوزانه بناءً على التعليقات الواردة.
أصبحت الاستراتيجيات التطورية خيارًا شائعًا لحل مشاكل التعلم المعزز ، نظرًا لبساطتها وكفاءتها وقابليتها للتوسع. سنستخدم إستراتيجية معينة ، تُعرف باسم CMA-ES.
استراتيجية تطور مصفوفة التباين المشترك (CMA-ES)
تلتزم الاستراتيجيات التطورية بشكل عام بالعملية التالية:
1- قم بإنشاء مجموعة من الوكلاء وقم بتهيئة المعايير بشكل عشوائي ليتم تحسينها لكل وكيل.
2- قم بعمل حلقة فوق ما يلي:
أ- قم بتقييم كل وكيل في البيئة ، مع إرجاع متوسط المكافأة على عدة حلقات.
ب-قم بتوليد الوكلاء الذين لديهم أفضل الدرجات لإنشاء سكان جدد.
ج-أضف العشوائية إلى معايير السكان الجدد.
د-قم بتحديث تجمع السكان عن طريق إضافة الوكلاء حديثي الولاده وإزالة الوكلاء الذين لديهم الأداء الضعيف.
هذا مشابه للعملية التي من خلالها تتطور الحيوانات في الطبيعة – ومن هنا جاء اسم الاستراتيجيات التطورية. يعني مصطلح “التوليد” في هذا السياق ببساطة الجمع بين أفضل العوامل الحالية التي أحرزت درجات بحيث يُرجح أن ينتج الجيل التالي نتائج عالية الجودة ، على غرار والديهم. كما هو الحال مع جميع حلول التعلم المعزز ، يجب إيجاد توازن بين البحث الجشع عن الحلول المثلى محليًا واستكشاف مناطق غير معروفة من فضاء المعايير للحصول على حلول محتملة أفضل. هذا هو السبب في أنه من المهم إضافة العشوائية إلى السكان ، للتأكد من أننا لا نضيق مجال البحث الخاص بنا.
استراتيجية تطور مصفوفة التباين المشترك (CMA-ES) هي مجرد شكل واحد من أشكال الإستراتيجيات التطورية. باختصار ، فهي تعمل من خلال الحفاظ على التوزيع الطبيعي الذي يمكن من خلاله أخذ عينات من المعايير للوكلاء الجدد.
في كل جيل ، يتم بتحديث متوسط التوزيع لزيادة احتمالية أخذ عينات من الوكلاء الحاصلين على درجات عالية من الخطوة الزمنية السابقة. في الوقت نفسه ، يتم تحديث مصفوفة التغاير للتوزيع لتعظيم احتمالية أخذ عينات من العوامل ذات الدرجات العالية ، بالنظر إلى المتوسط السابق. يمكن اعتباره شكلاً من أشكال الانحدار الطبيعي الناشئ (arising gradient descen) ، ولكن مع إيجابية أنه خالٍ من المشتقات ، مما يعني أننا لسنا بحاجة إلى حساب أو تقدير المشتقات المكلفة.
يظهر جيل واحد من الخوارزمية الموضحة في مثال في الصورة أدناه نحن هنا نحاول إيجاد النقطة الدنيا لدالة غير خطية للغاية في بعدين – قيمة الدالة في المناطق الحمراء / السوداء من الصورة أكبر من قيمة الدالة في الأجزاء البيضاء / الصفراء من الصورة.
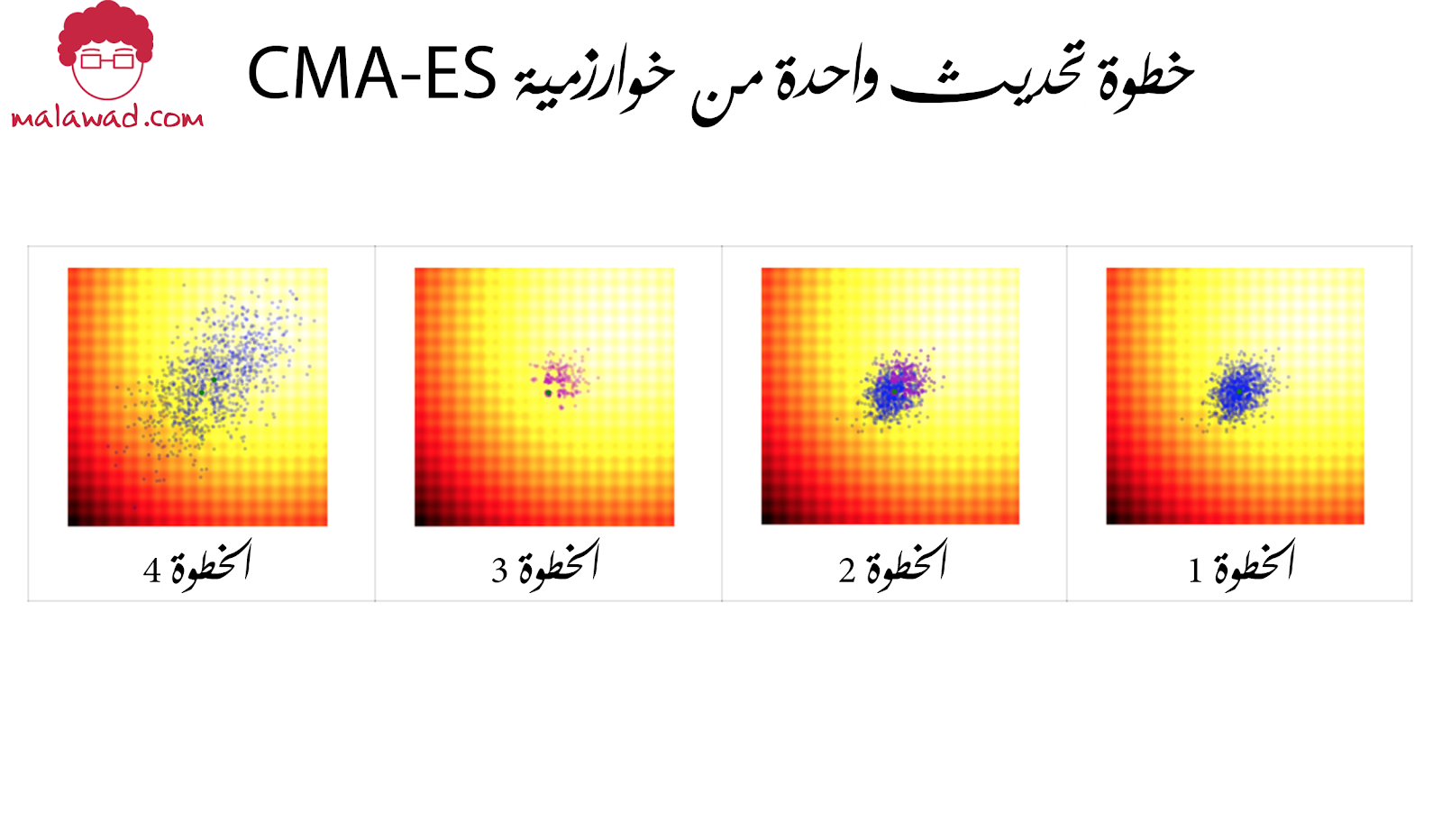
والخطوات هي كما يلي:
الخطوة الأولى : نبدأ بتوزيع طبيعي ثنائي الأبعاد تم إنشاؤه عشوائيًا ونأخذ عينة من مجموعة من المرشحين ، كما هو موضح باللون الأزرق.
الخطوة الثانية : نحسب بعد ذلك قيمة الدالة لكل مرشح ونعزل أفضل 25٪ ، كما هو موضح باللون الأرجواني – سنسمي هذه المجموعة من النقاط P.
الخطوة الثالثة : لقد حددنا متوسط التوزيع الطبيعي الجديد ليكون متوسط النقاط في P. يمكن اعتبار هذا على أنه مرحلة التكاثر (التوليد) ، حيث نستخدم فقط أفضل المرشحين لتوليد وسيلة جديدة للتوزيع. قمنا أيضًا بتعيين مصفوفة التغاير للتوزيع الطبيعي الجديد لتكون مصفوفة التغاير للنقاط في P ، لكننا نستخدم المتوسط الحالي في حساب التغاير بدلاً من المتوسط الحالي للنقاط في P. كلما زاد الفرق بين المتوسط الحالي ومتوسط النقاط في P ، كلما اتسع تباين التوزيع الطبيعي التالي. هذا له تأثير خلق الزخم بشكل طبيعي في البحث عن المعلمات المثلى.
الخطوة الرابعه: يمكننا بعد ذلك أخذ عينة جديدة من السكان المرشحين من التوزيع الطبيعي الجديد لدينا باستخدام مصفوفة متوسط متغاير محدثة.
توضح الصورة التالية عدة أجيال من العملية. شاهد كيف يتسع التباين بينما يتحرك المتوسط بخطوات كبيرة نحو الحد الأدنى ، لكنه يضيق كلما استقر المتوسط في الحد الأدنى الحقيقي.

بالنسبة لمهمة سباق السيارات ، ليس لدينا دالة محددة جيدًا لتعظيمها ، ولكن بدلاً من ذلك ، تحدد بيئة حيث يتم تحسين المعايير867 مدى نجاح الوكيل.
في البداية ، ستولد بعض مجموعات المعايير، عشوائياً ، درجات أعلى من غيرها وستقوم الخوارزمية تدريجياً بتحريك التوزيع الطبيعي في اتجاه تلك المعايير التي حصلت على أعلى درجات في البيئة.
توازي CMA-ES
تتمثل إحدى الفوائد العظيمة لـ CMA-ES في أنه يمكن موازنتها بسهولة باستخدام مكتبة Python التي أنشأها David Ha تسمى es.py. الجزء الأكثر استهلاكا للوقت من الخوارزمية هو حساب النتيجة لمجموعة معينة من المعايير ، لأنها تحتاج إلى محاكاة عامل بهذه المعايير في البيئة. ومع ذلك ، يمكن موازاة هذه العملية ، حيث لا توجد تبعيات بين عمليات المحاكاة الفردية.
في الكود الذي نستخدمه ، نستخدم إعدادات رئيسي / تابع (master/slave) ، حيث توجد عملية رئيسية ترسل مجموعات معايير ليتم اختبارها في العديد من عمليات التوابع بالتوازي.
تقوم العقد التابعة بإرجاع النتائج إلى العنصر الرئيسي ، والذي يقوم بتجميع النتائج ثم تمرير نتيجة التوليد الإجمالية إلى كائن CMA-ES. يقوم هذا الكائن بتحديث مصفوفة المتوسط والتغاير للتوزيع الطبيعي ويزود الرئيس بمجموعة جديدة للاختبار. ثم تبدأ الحلقة مرة أخرى.و توضح الصورة أدناه هذا في رسم تخطيطي.

1- يطلب الرئيس CMA-ES مجموعة من المعايير لتجربتها.
2- يقوم الرئيس بتقسيم المعايير بين عَقد التوابع المتاحة. هنا ، تحصل كل عملية من العمليات التابعة الأربع على مجموعتين من المعايير للتجربة.
3- تقوم عقدة التابع بتشغيل العامل لديها و التي بدورها تدور (loop) حول كل مجموعة من المعايير لعدة حلقات لكل منها . نقوم هنا بإستخدام ثلاث حلقات لكل مجموعة من المعلمات.
4- يتم حساب متوسط المكافآت من كل حلقة لإعطاء درجة واحدة لكل مجموعة من المعايير .
5- تقوم عقدة التابع بإرجاع قائمة النتائج إلى الرئيس .
6- يقوم الرئيس بتجميع جميع النتائج معًا وإرسال هذه القائمة إلى CMA-ES.
7- يستخدم CMA-ES قائمة المكافآت هذه لحساب التوزيع الطبيعي الجديد
مخرج تدريب وحدة التحكم
يظهر ناتج عملية التدريب في الصورة أدناه . يتم حفظ ملف يخزن أوزان الشبكة المدربة في كل جيل من خطوات Eval_steps.

يمثل كل سطر من المخرجات جيلًا من التدريب. الإحصاءات لكل جيل هي كما يلي:
1- اسم البيئة (على سبيل المثال ، car_racing)
2- رقم الجيل (على سبيل المثال ، 16)
3- الوقت المنقضي الحالي بالثواني (على سبيل المثال ، 2395)
4- متوسط مكافأة الجيل (على سبيل المثال ، 136.44)
5- الحد الأدنى لمكافأة الجيل (على سبيل المثال ، 33.28)
6- أقصى مكافأة للجيل (على سبيل المثال ، 246.12)
7- الانحراف المعياري للمكافآت (على سبيل المثال ، 62.78)
8- عامل الانحراف المعياري الحالي لعملية ES (تمت تهيئته عند 0.5 ويضمحل في كل خطوة زمنية ؛ على سبيل المثال ، 0.4604)
9- الحد الأدنى للخطوات التي تم اتخاذها قبل الإنهاء (على سبيل المثال ، 1000.0)
10 – الحد الأقصى للخطوات التي تم اتخاذها قبل الإنهاء (على سبيل المثال ، 1000)
بعد الخطوات الزمنية لـ Eval_steps ، تقوم كل عقدة تابعة بتقييم مجموعة معايير أفضل تسجيل حاليًا وإرجاع متوسط المكافآت عبر عدة حلقات (episodes) . يتم حساب متوسط هذه المكافآت مرة أخرى لإرجاع النتيجة الإجمالية لمجموعة المعلمات.
بعد حوالي 200 خطوة زمنية ، تحقق عملية التدريب متوسط درجة مكافأة 840 لمهمة سباق السيارات.
التدريب داخل الحلم (In-Dream Training)
حتى الآن ، تم إجراء تدريب وحدة التحكم باستخدام بيئة OpenAI Gym CarRacing لتنفيذ طريقة الخطوة (step method ) التي تنقل المحاكاة من حالة إلى أخرى. تحسب هذه الوظيفة الحالة التالية والمكافأة ، بالنظر إلى الحالة الحالية للبيئة والإجراء المختار.
لاحظ كيف تؤدي طريقة الخطوة وظيفة مشابهة جدًا لوظيفة MDN-RNN في نموذجنا. وهي أخذ العينات من مخرجات MDN-RNN ينتج عنه توقع لـ z والمكافأة التالية ، بالنظر إلى z الحالي والإجراء المختار.
في الواقع ، يمكن اعتبار MDN-RNN بيئة في حد ذاتها ، ولكنها تعمل في فضاء-z ( z-space) بدلاً من فضاء الصورة الأصلية. و هذا يعني أنه يمكننا بالفعل استبدال البيئة الحقيقية بنسخة من MDN-RNN وتدريب وحدة التحكم بالكامل ضمن حلم مستوحى من MDN-RNN حول كيفية تصرف البيئة.
بعبارة أخرى ، تعلمت MDN-RNN ما يكفي عن الفيزياء العامة للبيئة الحقيقية من مجموعة بيانات الحركة العشوائية الأصلية بحيث يمكن استخدامها كبديل للبيئة الحقيقية عند تدريب وحدة التحكم. مما يعني أنه يمكن للوكيل تدريب نفسه على تعلم مهمة جديدة من خلال التفكير في كيفية تعظيم المكافأة في بيئة أحلامه ، دون الاضطرار إلى اختبار الاستراتيجيات في العالم الحقيقي. يمكنه بعد ذلك أداء المهمة بشكل جيد في المرة الأولى ، بعد أن لم يحاول القيام بهذه المهمة في الواقع.
هذا هو أحد أسباب أهمية ورقة “النماذج العالمية” ولماذا ستشكل النمذجة التوليدية بشكل شبه مؤكد مكونًا رئيسيًا للذكاء الاصطناعي في المستقبل.
فيما يلي مقارنة بين معارية التدريب في البيئة الحقيقية وبيئة الأحلام: تظهر معمارية العالم الحقيقي أدناه.
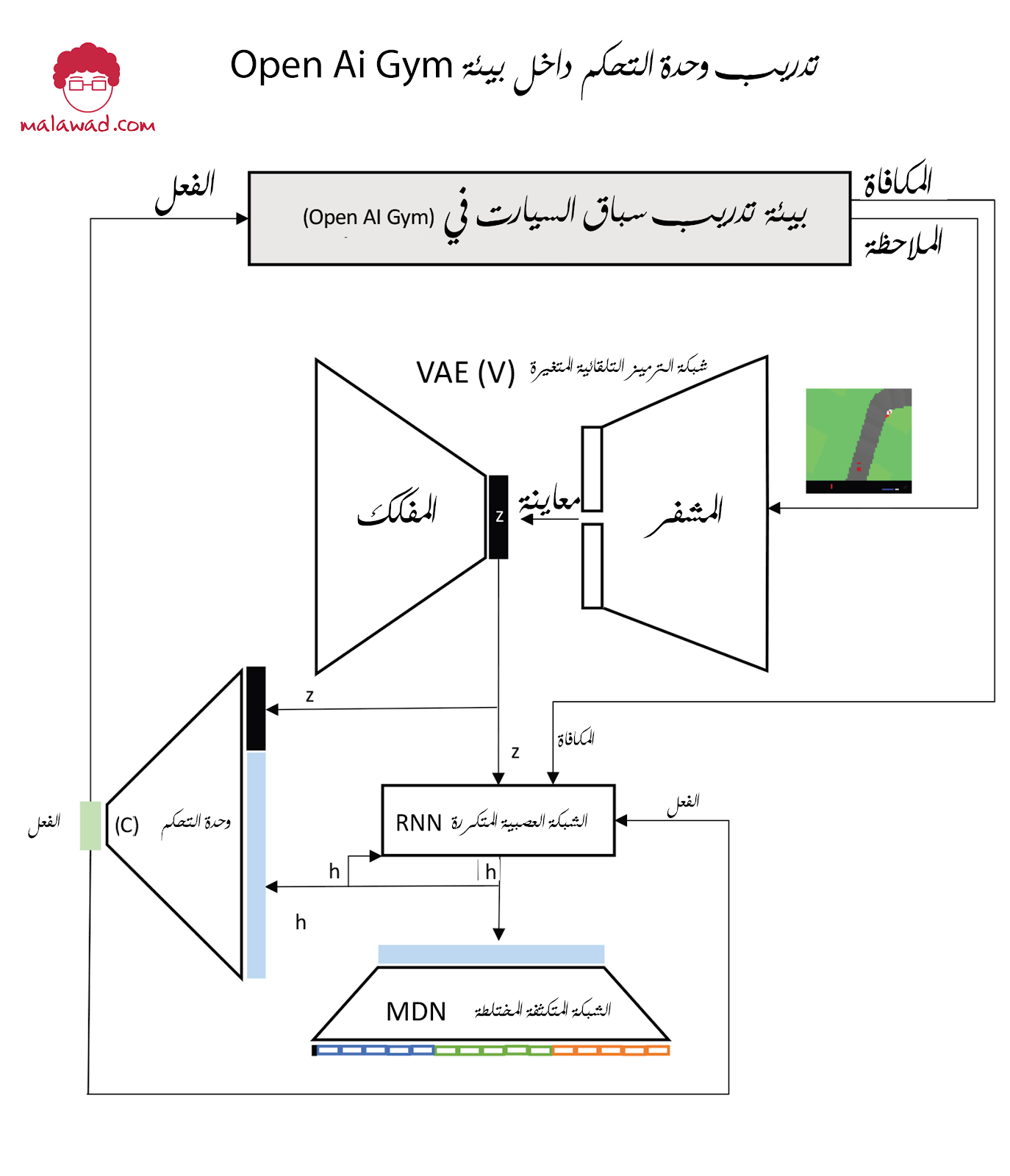
و الأن لاحظ كيف يتم تدريب وحدة التحكم في معمارية الأحلام بالكامل في z-space دون الحاجة إلى فك تشفير متجهات z إلى صور مسار يمكن التعرف عليها. يمكننا بالطبع القيام بذلك ، من أجل عرض ما يفعله الوكيل ، لكن هذا ليس مطلوبًا للتدريب.

تدريب وحدة التحكم في الحلم
لتدريب وحدة التحكم باستخدام معمارية الأحلام ، نستخدم الأمر التالي :
xvfb-run -a -s "-screen 0 1400x900x24" python 05_train_controller.py car_racing -n 16 -t 2 -e 4 --max_length 1000 --dream_mode 1
هذا هو نفس الأمر المستخدم لتدريب وحدة التحكم في البيئة الحقيقية ، ولكن بالإضافة لإستخدام – dream_mode 1.
يظهر ناتج عملية التدريب في الصورة أدناه

عند التدريب في بيئة الأحلام ، يتم إعطاء درجات كل جيل من حيث متوسط مجموع مكافآت الأحلام (أي 0 أو 1 في كل مرة). ومع ذلك ، فإن التقييم الذي يتم إجراؤه بعد كل 10 أجيال لا يزال يتم إجراؤه في البيئة الحقيقية وبالتالي يتم تسجيله بناءً على مجموع المكافآت من بيئة OpenAI Gym ، حتى نتمكن من مقارنة أساليب التدريب.
بعد 10 أجيال فقط من التدريب في بيئة الأحلام ، حقق الوكيل 586.6 نقطة في المتوسط في البيئة الحقيقية. السيارة قادرة على القيادة بدقة حول المسار ويمكنها التعامل مع معظم الزوايا ، باستثناء تلك الحادة بشكل خاص.
هذا إنجاز مذهل – تذكر ، عندما تم تقييم وحدة التحكم بعد 10 أجيال ، لم تتمكن أصلاً من القيادة بسرعة حول المسار في البيئة الحقيقية. بل كانت تدور حول البيئة بشكل عشوائي (لتدريب VAE و MDN-RNN) ثم في بيئة أحلامها الخاصة لتدريب وحدة التحكم.
على سبيل المقارنة ، بعد 10 أجيال ، أصبح الوكيل المدرَّب في البيئة الحقيقية بالكاد قادرًا على الانتقال من خط البداية. علاوة على ذلك ، فإن كل جيل من التدريب في بيئة الأحلام يكون أسرع بحوالي 3-4 مرات من التدريب في البيئة الحقيقية ، نظرًا لأن توقع z والمكافأة بواسطة MDN-RNN أسرع من حساب z والمكافأة بواسطة بيئة OpenAI Gym.
تحديات التدريب في الحلم
أحد التحديات التي يواجهها وكلاء التدريب بالكامل داخل بيئة حلم MDN-RNN هو فرط التخصيص (overfitting) . يحدث هذا عندما يجد الوكيل استراتيجية مجزية في بيئة الأحلام ، لكنها لا تعمم جيدًا على البيئة الحقيقية ، نظرًا لأن MDN-RNN لا تلتقط تمامًا كيف تتصرف البيئة الحقيقية في ظل ظروف معينة.
يمكننا أن نرى هذا يحدث بعد 20 جيلًا في الصورة أعلاه ، على الرغم من استمرار ارتفاع درجات الحلم ، لا يحرز الوكيل سوى 363.7 في البيئة الحقيقية ، وهو أسوأ من درجته بعد 10 أجيال.
يسلط مؤلفو ورقة “نماذج العالم ” الأصلية الضوء على هذا التحدي ويوضحون كيف أن تضمين معييار الحرارة للتحكم في عدم اليقين في النموذج يمكن أن يساعد في تخفيف المشكلة.
تؤدي زيادة هذا المعييار إلى تضخيم التباين عند أخذ عينات z عبر MDN-RNN ، مما يؤدي إلى عمليات نشر أكثر تقلبًا عند التدريب في بيئة الأحلام.
تتلقى وحدة التحكم مكافآت أعلى للاستراتيجيات الأكثر أمانًا التي تواجه حالات مفهومة جيدًا وبالتالي تميل إلى التعميم بشكل أفضل على البيئة الحقيقية. ومع ذلك ، يجب أن تكون درجة الحرارة المتزايدة متوازنة مع عدم جعل البيئة متقلبة لدرجة أن المتحكم لا يمكنه تعلم أي استراتيجية ، حيث لا يوجد اتساق كاف في كيفية تطور بيئة الأحلام بمرور الوقت.
في الورقة الأصلية ، أظهر المؤلفون أن هذه التقنية تم تطبيقها بنجاح على بيئة مختلفة: DoomTakeCover ، التي تدور حول لعبة الكمبيوتر Doom. توضح الصورة أدناه كيف يؤثر تغيير معييار الحرارة على كل من النتيجة الافتراضية (الحلم) والنتيجة الفعلية في البيئة الحقيقية.

الخاتمة
لقد رأينا في هذا المقال كيف يمكن استخدام النموذج التوليدي (VAE) ضمن إعداد التعلم المعزز لتمكين الوكيل من تعلم استراتيجية فعالة عن طريق اختبار السياسات ضمن أحلامه المتولدة ، بدلاً من البيئة الحقيقية.
يتم تدريب VAE على تعلم التمثيل الكامن للبيئة ، والذي يتم استخدامه بعد ذلك كمدخل لشبكة عصبية متكررة تتنبأ بالمسارات المستقبلية داخل الفضاء الكامن.
مما يمكن للوكيل بعد ذلك استخدام هذا النموذج التوليدي كبيئة زائفة لاختبار السياسات بشكل متكرر ، باستخدام منهجية تطورية ، والتي تعمم جيدًا على البيئة الحقيقية.













إضافة تعليق