
يتم استخدام عملية ماركوف (MP) و عمليات قرار ماركوف ( MDPs) على نطاق واسع في علوم الكمبيوتر والمجالات الهندسية الأخرى. لذا ، فإن قراءة هذا المقال ستكون مفيدة لك ليس فقط لسياقات التعلم المعزز ، ولكن أيضًا لمجموعة واسعة من الموضوعات.
سنغطي عمليات قرار ماركوف (Markov decision processes) أو (MDPs) ، والتي يتم وصفها على أنها دمية ماتريوشكا روسية: سنبدأ من أبسط حالة وهي عملية ماركوف (Markov process) أو (MP) ، ثم نوسعها بالمكافآت ، والتي ستحولها إلى عملية مكافأة ماركوف (Markov reward process). بعد ذلك ، سنضع هذه الفكرة في مظروف إضافي عن طريق إضافة إجراءات ، والتي ستقودنا إلى عملية قرار ماركوف MDP .
عملية ماركوف (Markov process)
لنبدأ بأبسط طفل في عائلة ماركوف: MP، المعروف أيضًا باسم سلسلة ماركوف (Markov chain). تخيل أن لديك نظامًا ما أمامك يمكنك فقط مراقبته. ما تلاحظه يسمى حالات ، ويمكن للنظام التبديل بين الحالات وفقًا لبعض قوانين الديناميكيات. مرة أخرى ، لا يمكنك التأثير على النظام ، ولكن يمكنك فقط مشاهدة الحالات المتغيرة.
تشكل جميع الحالات الممكنة لنظام ما مجموعة تسمى فضاء الحالة (state space.) . بالنسبة لعملية ماركوف ، نطلب أن تكون هذه المجموعة من الحالات محدودة (ولكن يمكن أن تكون كبيرة للغاية لتعويض هذا القيد).
تشكل ملاحظاتك سلسلة من الحالات أو سلسلة (chain) (لهذا يُطلق على عملية ماركوف أيضًا اسم سلاسل ماركوف). على سبيل المثال ، بالنظر إلى أبسط نموذج للطقس في بعض المدن ، يمكننا أن نلاحظ اليوم الحالي على أنه مشمس أو ممطر ، وهو فضاء الحالة . تشكل سلسلة من الملاحظات بمرور الوقت سلسلة من الحالات ، مثل [مشمس ، مشمس ، ممطر ، مشمس ، …] وهذا يسمى التاريخ.
لتسمية مثل هذا النظام بـ MP ، يجب أن تفي بخاصية ماركوف، مما يعني أن ديناميكيات النظام المستقبلية من أي حالة يجب أن تعتمد على هذه الحالة فقط.
تتمثل النقطة الرئيسية لخاصية ماركوف في جعل كل حالة يمكن ملاحظتها قائمة بذاتها لوصف مستقبل النظام. بمعنى آخر ، تتطلب خاصية ماركوف أن تكون حالات النظام مميزة عن بعضها البعض وفريدة من نوعها. في هذه الحالة ، هناك حاجة إلى حالة واحدة فقط لنمذجة الديناميكيات المستقبلية للنظام وليس التاريخ بأكمله أو ، على سبيل المثال ، حالات N الأخيرة.
في حالة الطقس لدينا ، فإن خاصية ماركوف تحد نموذجنا لتمثيل الحالات التي يمكن أن يتبع فيها يوم مشمس يوم ممطر بنفس الاحتمال ، بغض النظر عن مقدار الأيام المشمسة التي رأيناها في الماضي .
إنه ليس نموذجًا واقعيًا للغاية ، فمن المنطقي أننا نعلم أن فرصة هطول الأمطار غدًا لا تعتمد فقط على الظروف الحالية ولكن على عدد كبير من العوامل الأخرى ، مثل الموسم وخط العرض ووجود الجبال والبحر مجاور. لقد ثبت مؤخرًا أنه حتى النشاط الشمسي له تأثير كبير على الطقس. لذا ، مثالنا ساذج حقًا ، لكن من المهم فهم القيود واتخاذ قرارات واعية بشأنها.
بالطبع ، إذا أردنا أن نجعل نموذجنا أكثر تعقيدًا ، فيمكننا دائمًا القيام بذلك من خلال توسيع فضاء الحالة لدينا ، مما سيسمح لنا بالتقاط المزيد من التبعيات في النموذج على حساب فضاء حالة أكبر. على سبيل المثال ، إذا كنت تريد أن تحدد بشكل منفصل احتمال الأيام الممطرة خلال الصيف والشتاء ، فيمكنك عندئذٍ تضمين الموسم في حالتك.
في هذه الحالة ، سيكون فضاء الحالة [مشمس + صيف ، مشمس + شتاء ، ممطر + صيف ، ممطر + شتاء] وهكذا.
نظرًا لأن نموذج النظام الخاص بك يتوافق مع خاصية ماركوف ، يمكنك التقاط احتمالات الانتقال باستخدام مصفوفة انتقالية ، وهي عبارة عن مصفوفة مربعة بالحجم N × N ، حيث يمثل N عدد الحالات في نموذجنا. تحتوي كل خلية في صف ، i وعمود ، j ، في المصفوفة على احتمال انتقال النظام من الحالة i إلى الحالة j.
على سبيل المثال ، في مثالنا المشمس / الممطر ، يمكن أن تكون مصفوفة الانتقال على النحو التالي:
| مشمس | ممطر | |
| مشمس | 0.8 | 0.2 |
| ممطر | 0.1 | 0.9 |
في هذه الحالة ، إذا كان لدينا يوم مشمس ، فهناك احتمال بنسبة 80٪ أن يكون اليوم التالي مشمسًا و 20٪ أن يكون اليوم التالي ممطرًا. إذا لاحظنا يومًا ممطرًا ، فهناك احتمال بنسبة 10٪ أن يصبح الطقس أفضل واحتمال 90٪ أن يكون الجو ممطرًا في اليوم التالي.
هذا كل شيء. التعريف الرسمي لعملية ماركوف هي كما يلي:
- مجموعة من الحالات (S) التي يمكن أن يكون فيها النظام
- مصفوفة الانتقال (T) ، مع احتمالات الانتقال ، والتي تحدد ديناميكيات النظام
التمثيل المرئي المفيد لـ MP هو رسم بياني يحتوي على عُقد تتوافق مع حالات وحواف النظام ، معنونة بتمثيل إحتمالي يمثل الإنتقال المحتمل من حالة إلى حالة. إذا كان احتمال الانتقال 0 ، فإننا لا نرسم حد (لا توجد طريقة للانتقال من حالة إلى أخرى). يستخدم هذا النوع من التمثيل أيضًا على نطاق واسع في تمثيل آلة الحالة المحدودة (finite state machine representation,) ، والتي تتم دراستها في نظرية الأوتوماتا.

مرة أخرى ، نحن نتحدث عن الملاحظة فقط. لا توجد وسيلة لنا للتأثير على الطقس ، لذلك نحن فقط نراقبه ونسجل ملاحظاتنا.
لإعطائك مثالًا أكثر تعقيدًا ، دعنا نفكر في نموذج آخر يسمى عامل المكتب تحتوي فضاء الحالة في مثالنا على الحالات التالية:
المنزل: إنه ليس في المكتب
الكمبيوتر: إنه يعمل على جهاز الكمبيوتر الخاص به في المكتب
القهوة: يشرب القهوة في المكتب
الدردشة: إنه يناقش شيئًا ما مع زملائه في المكتب
يبدو رسم انتقال الحالة كما يلي:

نحن نفترض أن يوم العمل في مكتبنا يبدأ عادة من حالة المنزل وأنه يبدأ يومه مع القهوة دون استثناء (لا يوجد مسار المنزل ← الكمبيوتر أو المنزل ← الدردشة). يوضح الرسم التخطيطي السابق أيضًا أن أيام العمل تنتهي دائمًا بالانتقال إلى حالة المنزل من حالة الكمبيوتر.
مصفوفة الانتقال للرسم البياني السابق هي كما يلي:
| المنزل | القهوة | الدردشة | الكمبيوتر | |
| المنزل | 60% | 40% | 0% | 0% |
| القهوة | 0% | 10% | 70% | 20% |
| الدردشة | 0% | 20% | 50% | 30% |
| الكمبيوتر | 20% | 20% | 10% | 50% |
يمكن وضع احتمالات الانتقال مباشرة على الرسم البياني الانتقالي للحالة ، كما هو موضح هنا:

من الناحية العملية ، نادرًا ما نمتلك رفاهية معرفة مصفوفة الانتقال الدقيقة. هناك موقف أكثر واقعية عندما يكون لدينا فقط ملاحظات لحالات نظامنا ، والتي تسمى أيضًا الحلقات (episodes):
- المنزل← القهوة ← القهوة ← الدردشة ← الدردشة ← القهوة ← الكمبيوتر ← الكمبيوتر ← المنزل
- الكمبيوتر ← الكمبيوتر ← الدردشة ← الدردشة ← القهوة ← الكمبيوتر ← الكمبيوتر ← المنزل
- المنزل ← المنزل ← القهوة ← الدردشة ← الكمبيوتر ← القهوة ← القهوة
ليس من المعقد تقدير مصفوفة الانتقال من ملاحظاتنا – فنحن فقط نحسب جميع التحولات من كل حالة ونقوم بتسويتها مجموعها إلى 1. وكلما زادت بيانات الملاحظة لدينا ، كلما اقترب تقديرنا من النموذج الأساسي الحقيقي.
تجدر الإشارة أيضًا إلى أن خاصية ماركوف تعني الثبات (أي أن توزيع الانتقال الأساسي لأي حالة لا يتغير بمرور الوقت). عدم الإستقرار يعني أن هناك بعض العوامل الخفية التي تؤثر على ديناميكيات نظامنا ، وهذا العامل غير مدرج في الملاحظات. ومع ذلك ، فإن هذا يتعارض مع خاصية ماركوف ، والتي تتطلب أن يكون توزيع الاحتمالات الأساسي هو نفسه لنفس الحالة بغض النظر عن تاريخ الانتقال.
من المهم فهم الفرق بين التحولات الفعلية التي لوحظت في إحدى الحلقات والتوزيع الأساسي الوارد في مصفوفة الانتقال. يتم أخذ عينات عشوائية من الحلقات الملموسة التي نلاحظها من توزيع النموذج ، بحيث يمكن أن تختلف من حلقة إلى أخرى. ومع ذلك ، فإن احتمال الانتقال الملموس لأخذ العينات يظل كما هو. إذا لم يكن الأمر كذلك ، تصبح شكليات سلسلة ماركوف غير قابلة للتطبيق.
الآن يمكننا المضي قدمًا وتوسيع نموذج عملية ماركوف لجعله أقرب إلى مشاكل التعلم المعزز. دعنا نضيف مكافآت للصورة!
عمليات مكافأة ماركوف
لتقديم المكافأة ، نحتاج إلى تمديد نموذج عملية ماركوف الخاص بنا قليلاً. أولاً ، نحتاج إلى إضافة قيمة لانتقالنا من حالة إلى حالة. لدينا بالفعل احتمال ، ولكن يتم استخدام الاحتمال لالتقاط ديناميكيات النظام ، لذلك لدينا الآن رقم قياسي إضافي دون عبء إضافي.
يمكن تمثيل المكافأة في أشكال مختلفة. الطريقة الأكثر شيوعًا هي الحصول على مصفوفة مربعة أخرى ، مماثلة لمصفوفة الانتقال ، مع مكافأة تُمنح للانتقال من الحالة i إلى الحالة j ، الموجودة في الصف الأول والعمود j.
كما ذكرنا ، يمكن أن تكون المكافأة إيجابية أو سلبية ، كبيرة أو صغيرة. في بعض الحالات ، يكون هذا التمثيل زائدًا عن الحاجة ويمكن تبسيطه. على سبيل المثال ، إذا تم منح مكافأة للوصول إلى الحالة بغض النظر عن الحالة السابقة ، فيمكننا الاحتفاظ بالأزواج فقط ، وهي تمثيل أكثر إحكاما. ومع ذلك ، لا ينطبق هذا إلا إذا كانت قيمة المكافأة تعتمد فقط على الحالة المستهدفة ، وهذا ليس هو الحال دائمًا.
الشيء الثاني الذي نضيفه إلى النموذج هو عامل الخصم (جاما) ، وهو رقم واحد من 0 إلى 1 .
كما ذكرنا ، نلاحظ سلسلة من انتقالات الحالة في عملية ماركوف. لا يزال هذا هو الحال بالنسبة لعملية مكافأة ماركوف ، ولكن لكل انتقال ، لدينا الكمية الإضافية – المكافأة. و بالتالي ، كل ملاحظاتنا لها قيمة مكافأة مرتبطة بكل انتقال للنظام.
لكل حلقة ، نحدد العائد في ذلك الوقت ، t ، على أنها هذه الكمية:

دعنا نحاول فهم ما يعنيه هذا. لكل نقطة زمنية ، نحسب العائد كمجموع للمكافآت اللاحقة ، ولكن يتم ضرب المكافآت الأكثر بعدًا في عامل الخصم المرفوع إلى قوة عدد الخطوات التي نبتعد بها عن نقطة البداية عند t.
يشير عامل الخصم إلى بعد نظر الوكيل (Agent). إذا كانت قيمة جاما تساوي 1 ، فعندئذٍ تكون العائد Gt تساوي مجموع جميع المكافآت اللاحقة وتتوافق مع الوكيل الذي يتمتع برؤية مثالية لأي مكافآت لاحقة. إذا كانت قيمة جاما تساوي 0 ، فستكون Gt مجرد مكافأة فورية دون أي حالة لاحقة وستتوافق مع قصر النظر المطلق.
هذه القيم القصوى مفيدة فقط في حالات الزاوية ، وفي معظم الأوقات ، يتم تعيين جاما على شيء ما بينهما ، مثل 0.9 أو 0.99. في هذه الحالة ، سننظر في المكافآت المستقبلية ، لكن ليس بعيدًا جدًا. قد تكون قيمة قابلة للتطبيق في حالات الحلقات القصيرة المحدودة.
تعتبر معييار جاما هذه مهمة في التعلم المعزز ، وسنلتقي بها كثيرًا خلال سلسلة مقالاتنا عن التعلم المعزز. في الوقت الحالي ، فكر في الأمر كمقياس للمدى الذي نتطلع إليه في المستقبل لتقدير العائد المستقبلي. كلما اقتربنا من 1 ،كلما زادت الخطوات التي سنأخذها في عين الاعتبار.
كمية العائد هذه ليست مفيدة جدًا في الممارسة ، حيث تم تعريفها لكل سلسلة محددة لاحظناها من عملية مكافأة ماركوف ، و بالتالي يمكن أن تختلف بشكل كبير ، حتى بالنسبة لنفس الحالة. ومع ذلك ، إذا ذهبنا إلى أقصى الحدود وحسبنا التوقع الرياضي للعائد لأي حالة (عن طريق حساب متوسط عدد كبير من السلاسل) ، فسنحصل على كمية أكثر فائدة بكثير ، تسمى قيمة الحالة:

هنا التفسير بسيط – لكل حالة ، القيمة ، (V (s ، هي متوسط (أو متوقع) العائد الذي نحصل عليه باتباع عملية مكافأة ماركوف.
لإظهار هذه الأشياء النظرية في الممارسة العملية ، دعنا نوسع عملية عامل مكتبنا بالمكافأة ونحولها إلى عملية مكافأة عامل المكتب. ستكون قيم المكافآت لدينا على النحو التالي:
- المنزل← المنزل : 1 (من الجيد أن تكون في المنزل).
- المنزل ← القهوة : 1
- الكمبيوتر ← الكمبيوتر : 5 (العمل الجاد هو شيء جيد)
- الكمبيوتر ← الدردشة : -3 (ليس من الجيد أن تشتت انتباهك)
- الدردشة ← الكمبيوتر : 2
- الكمبيوتر ← القهوة : 1
- القهوة ← القهوة : 1
- القهوة ← الدردشة : 2
- الدردشة ← القهوة : 1
- الدردشة ←الدردشة : -1 (المحادثات الطويلة تصبح مملة)
يظهر رسم تخطيطي لهذا هنا:

لنعد إلى معييار جاما الخاصة بنا ونفكر في قيم الحالات ذات القيم المختلفة لجاما. سنبدأ بحالة بسيطة: جاما = 0.
كيف تحسب قيم الحالات هنا؟ للإجابة على هذا السؤال ، دعنا نثبت حالتنا إلى الدردشة. ماذا يمكن أن يكون الانتقال التالي؟
الجواب هو أن الأمر يعتمد على الصدفة. وفقًا لمصفوفة الانتقال الخاصة بنا لعامل المكتب:
- هناك احتمال بنسبة 50٪ أن تكون الحالة التالية هي الدردشة مرة أخرى.
- و 20٪ أنها ستكون قهوة .
- و 30٪ أنها ستكون كمبيوتر.
عندما تكون جاما = 0 ، فإن عائدنا يساوي فقط قيمة الحالة الفورية التالية. لذا ، إذا أردنا حساب قيمة حالة الدردشة ، فسنحتاج إلى جمع جميع قيم الانتقال وضربها في احتمالاتها:
V (الدردشة) = –1 * 0.5 + 2 * 0.3 + 1 * 0.2 = 0.3
V(قهوة) = 2 * 0.7 + 1 * 0.1 + 3 * 0.2 = 2.1
V(المنزل) = 1 * 0.6 + 1 * 0.4 = 1.0
V (كمبيوتر) = 5 * 0.5 + (–3) * 0.1 + 1 * 0.2 + 2 * 0.2 = 2.8
لذا ، فإن الكمبيوتر هو الحالة الأكثر قيمة (إذا كنا نهتم فقط بالمكافأة الفورية) ، وهذا ليس مفاجئًا لأن الكمبيوتر ← الكمبيوتر متكرر ، وله مكافأة كبيرة ، ونسبة العقوبة ليست عالية جدًا.
الآن سؤال أصعب – ما هي القيمة عندما تكون جاما = 1؟ فكر في هذا بعناية. الجواب هو أن القيمة لا نهائية لجميع الحالات.
لا يحتوي مخططنا على حالات بالوعة (حالات لا يمكن الإنتقال منها) ، وعندما يساوي جاما 1 ، فإننا نهتم بعدد لا حصر له من التحولات في المستقبل. كما رأيت في حالة جاما = 0 ، فإن جميع قيمنا موجبة على المدى القصير ، لذا فإن مجموع العدد اللامتناهي للقيم الإيجابية سيعطينا قيمة لا نهائية ، بغض النظر عن حالة البداية.
توضح لنا هذه النتيجة اللانهائية أحد أسباب إدخال جاما في عملية مكافأة ماركوف بدلاً من مجرد جمع كل المكافآت المستقبلية. في معظم الحالات ، يمكن أن تحتوي العملية على كمية لا حصر لها (أو كبيرة) من التحولات.
نظرًا لأنه ليس من العملي جدًا التعامل مع القيم اللانهائية ، فإننا نود تحديد الأفق الذي نحسب قيمًا له. توفر جاما ذات القيمة الأقل من 1 مثل هذا القيد.
من ناحية أخرى ، إذا كنت تتعامل مع بيئات ذات أفق محدود (على سبيل المثال ، لعبة tic-tac-toe ، والتي تكون محدودة بتسع خطوات على الأكثر) ، فسيكون من الجيد استخدام جاما = 1.
هناك فئة مهمة من البيئات مع خطوة واحدة فقط تسمى multi-armed bandit MDP هذا يعني أنه في كل خطوة ، تحتاج إلى تحديد إجراء بديل واحد ، والذي يمنحك بعض المكافأة وتنتهي الحلقة.
دعنا الأن نضع طبقة أخرى من التعقيد حول عمليات مكافأة ماركوف ونقدم القطعة الأخيرة المفقودة: الإجراءات.
إضافة الإجراءات
قد تكون لديك بالفعل أفكار حول كيفية توسيع عملية مكافأة ماركوف لتشمل الإجراءات. أولاً ، يجب أن نضيف مجموعة من الإجراءات (أ) ، والتي يجب أن تكون محدودة. هذه فضاء إجراء (action space) وكيلنا. ثانيًا ، نحتاج إلى تكييف مصفوفة الانتقال الخاصة بنا بالإجراءت ، وهو ما يعني أساسًا أن المصفوفة تحتاج إلى بُعد إضافي للعمل ، والذي يحولها إلى مكعب.
إذا كنت تتذكر ، في حالة عمليات ماركوف و عمليات مكافأة ماركوف ، فإن مصفوفة الانتقال لها شكل مربع ، مع حالة المصدر في الصفوف والحالة المستهدفة في الأعمدة. لذلك ، كل صف ، i، يحتوي على قائمة احتمالات للإنتقال إلى كل حالة:

الآن لم يعد الوكيل يراقب انتقالات الحالة وحسب ، ولكن يمكنه اختيار إجراء ما يتخذه في كل حالة انتقالية. لذلك ، بالنسبة لكل حالة مصدر ، ليس لدينا قائمة من الأرقام ، ولكن لدينا مصفوفة ، حيث يحتوي بُعد العمق على الإجراءات التي يمكن أن يتخذها الوكيل ، والبعد الآخر هو ما سينتقل إليه نظام الحالة المستهدفة بعد الإجراءات التي تم تنفيذها من قبل الوكيل. يوضح الرسم البياني التالي جدول الانتقال الجديد الخاص بنا ، والذي أصبح مكعبًا مع حالة المصدر كبُعد الارتفاع (مفهرسًا بـ i) ، والحالة المستهدفة على أنها العرض (j) ، والإجراء الذي يمكن أن يتخذه الوكيل باعتباره العمق (k) من الجدول الانتقالي:
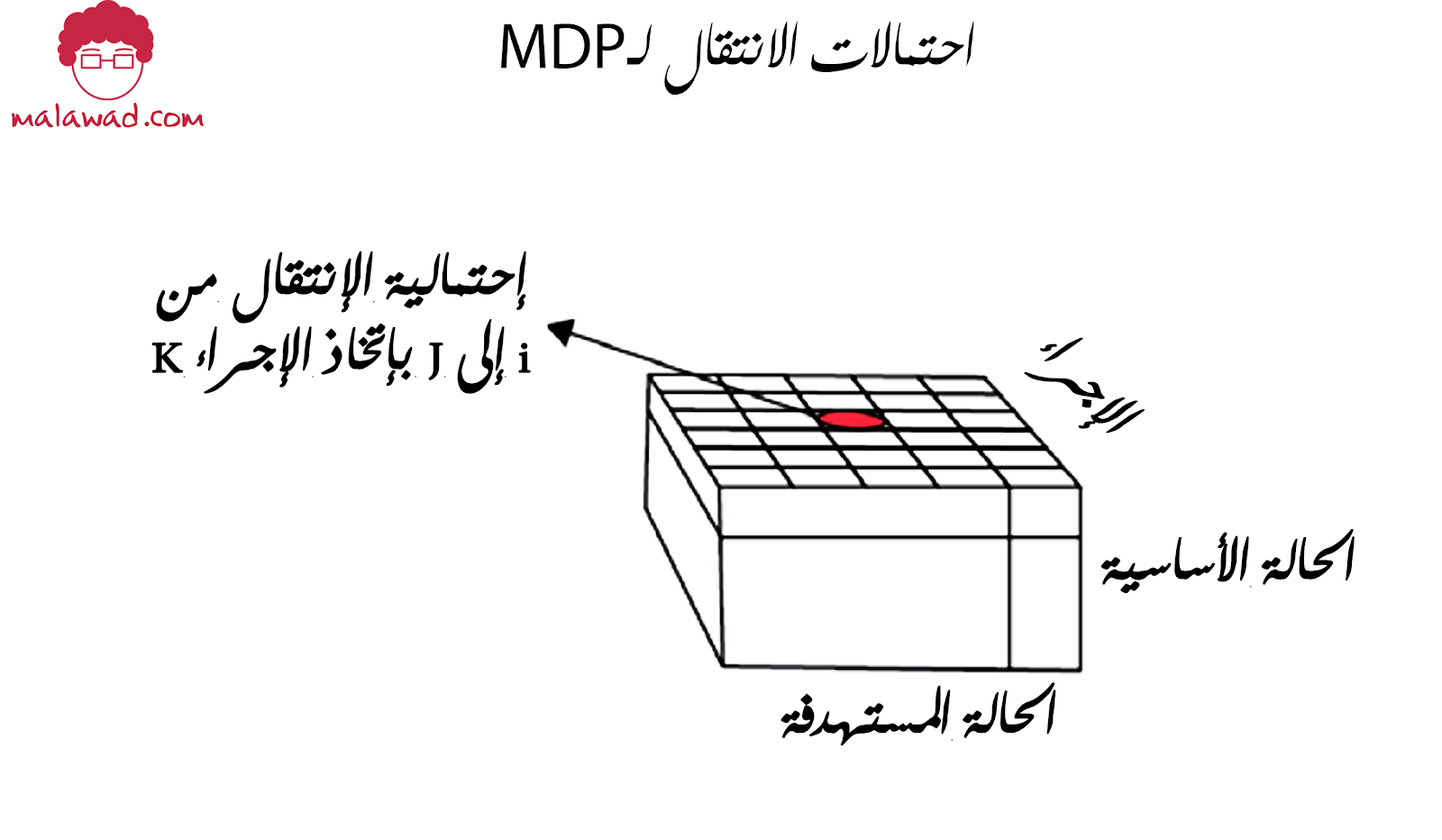
لذلك ، بشكل عام ، من خلال اختيار الإجراء ، يمكن للوكيل أن يؤثر على احتمالات الحالات المستهدفة ، وهي قدرة مفيدة.
مثال بسيط
لإعطائك فكرة عن سبب حاجتنا إلى الكثير من التعقيدات ، دعنا نتخيل روبوتًا صغيرًا يعيش في شبكة 3 × 3 ويمكنه تنفيذ الإجراءات التالية ، انعطف يسارًا ، انعطف يمينًا ، إتجه للأمام .
حالة العالم هي موضع الروبوت بالإضافة إلى اتجاهه (لأعلى ولأسفل ولليسار ولليمين) ، مما يعطينا 3 × 3 × 4 = 36 حالة (يمكن أن يكون الروبوت في أي مكان وفي أي اتجاه).
تخيل أيضًا أن الروبوت لديه محركات غير مثالية (وهو ما يحدث غالبًا في العالم الحقيقي) ، وعند تنفيذ الإجراء ، انعطف يسارًا أو انعطف يمينًا ، فهناك فرصة 90٪ لحدوث الانعطاف المرغوب ، ولكن في بعض الأحيان ، هناك إحتمال 10٪ ، أن تنزلق العجلة ويظل موضع الروبوت كما هو. يحدث الشيء نفسه مع إتجه للأمام – في 90٪ من الحالات يعمل ، ولكن بالنسبة للباقي (10٪) يبقى الروبوت في نفس الموضع.
في الرسم التوضيحي التالي ، يتم عرض جزء صغير من مخطط الانتقال ، يعرض التحولات المحتملة من الحالة (1 ، 1 ، لأعلى) ، عندما يكون الروبوت في وسط الشبكة. إذا حاول الروبوت التقدم للأمام ، فهناك احتمال بنسبة 90٪ أن ينتهي به الحال في الحالة (0 ، 1 ، لأعلى) ، ولكن هناك احتمال 10٪ أن العجلات سوف تنزلق ويبقى الموضع المستهدف (1 ، 1 ، أعلى).
لالتقاط كل هذه التفاصيل حول البيئة وردود الفعل المحتملة على تصرفات الوكيل بشكل صحيح ، يحتوي MDP العام على مصفوفة انتقال ثلاثية الأبعاد مع حالة مصدر الأبعاد والإجراء والحالة المستهدفة.

أخيرًا ، لتحويل عملية مكافأة ماركوف الخاصة بنا إلى MDP ، نحتاج إلى إضافة إجراءات إلى مصفوفة المكافآت الخاصة بنا بنفس الطريقة التي فعلنا بها مع مصفوفة الانتقال. ستعتمد مصفوفة المكافآت لدينا ليس فقط على الحالة ولكن أيضًا على الإجراء. بعبارة أخرى ، فإن المكافأة التي يحصل عليها الوكيل ستعتمد الآن ليس فقط على الحالة التي ينتهي بها ، ولكن أيضًا على الإجراء الذي يؤدي إلى هذه الحالة.
هذا مشابه عندما تبذل جهدًا في شيء ما – عادة ما تكتسب المهارات والمعرفة ، حتى لو لم تكن نتيجة جهودك ناجحة للغاية. لذلك ، يمكن أن تكون المكافأة أفضل إذا كنت تفعل شيئًا بدلاً من عدم القيام بشيء ما ، حتى لو كانت النتيجة النهائية هي نفسها.
الآن ، بعد أن تعرفنا على عملية قرارات ماركوف MDP ا، نحن مستعدون أخيرًا لتغطية أهم شيء لـ MDPs و التعلم المعزز: السياسة.
السياسة (POLICY)
التعريف البسيط للسياسة هو أنها مجموعة من القواعد التي تتحكم في سلوك الوكيل. حتى بالنسبة للبيئات البسيطة إلى حد ما ، يمكن أن يكون لدينا مجموعة متنوعة من السياسات. على سبيل المثال ، في المثال السابق مع الروبوت في عالم الشبكة ، يمكن أن يكون للوكيل سياسات مختلفة ، والتي ستؤدي إلى مجموعات مختلفة من الحالات التي تمت زيارتها. على سبيل المثال ، يمكن للروبوت تنفيذ الإجراءات التالية:
- المضي قدما بشكل أعمى بغض النظر عن أي شيء
- يحاول تجاوز العقبات عن طريق التحقق مما إذا كان الإجراء السابق تقدم إتجه للأمام قد فشل
- الدوران بشكل ممتع للترفيه عن مصممه
قد تتذكر أن الهدف الرئيسي للوكيل في التعلم المعزز هو جمع أكبر قدر ممكن من العائد. لذا ، مرة أخرى ، يمكن للسياسات المختلفة أن تعطينا كميات مختلفة من العائدات ، مما يجعل من المهم إيجاد سياسة جيدة. هذا هو سبب أهمية فكرة السياسة.
بشكل رسمي ، يتم تعريف السياسة على أنها توزيع الاحتمالات على الإجراءات لكل حالة ممكنة:

يتم تعريف هذا على أنه احتمال وليس كإجراء ملموس لإدخال العشوائية في سلوك الوكيل. السياسة الحتمية هي حالة خاصة من الاحتمالات مع الإجراء المطلوب الذي يكون 1 هو احتماله.
هناك فكرة أخرى مفيدة وهي أنه إذا كانت سياستنا ثابتة ولا تتغير ، فإن MDP الخاص بنا يصبح عملية مكافأة ماركوف ، حيث يمكننا تقليل الانتقال ومكافأة المصفوفات باحتمالات السياسة والتخلص من أبعاد الإجراء.













إضافة تعليق