
يصف النموذج التوليدي (generative model) كيفية توليد مجموعة بيانات عن طريق الإستعانة بالنماذج الإحتماليه (probabilistic model). فمن خلال أخذ عينات من هذا النموذج ، يمكننا إنشاء بيانات جديدة.
مثال:
لنفترض أن لدينا مجموعة بيانات تحتوي على صور للخيول. قد نرغب في بناء نموذج يمكن أن يولد صورة جديدة لحصان لم يكن موجودًا من قبل ولكن لا يزال يبدو حقيقيًا لأن النموذج قد تعلم القواعد العامة التي تحكم مظهر الحصان. هذا هو نوع المشكلة التي يمكن حلها باستخدام النمذجة التوليدية (generative modeling).
للقيام بهذا ، نحصل على مجموعة بيانات تتكون من أمثلة عديدة للكيان الذي نحاول توليده و إنشائه. يُعرف هذا باسم بيانات التدريب (training data) ، وتسمى كل قيمة هذه البيانات بالملاحظة (observation)

تحتوي كل ملاحظة على العديد من السمات (features) – بالنسبة لمسأئل توليد الصور ، تكون السمات عادة هي قيم النقاط الضوئية (pixel) الفردية.
هدفنا هو بناء نموذج يمكنه إنشاء مجموعات جديدة من السمات التي تبدو كما لو تم إنشاؤها باستخدام نفس القواعد التي نشأت منها البيانات الأصلية. من الناحية النظرية ، توليد الصور هي مهمة صعبة للغاية.
فيجب أن يكون النموذج التوليدي احتماليًا (probabilistic) وليس حتميًا (deterministic). إذا كان نموذجنا مجرد عملية حسابية ثابتة ، مثل أخذ متوسط قيمة كل نقطة ضوئية في مجموعة البيانات ، فإنه ليس مولِّدًا لأن النموذج ينتج نفس المخرجات في كل مرة. لذلك يجب أن يشتمل النموذج على عنصر عشوائي (stochastic) يؤثر على العينات الفردية الناتجة عن النموذج.
النمذجة التوليدية (Modeling Generative) مقابل النمذجة التمييزية (Discriminative Modeling)
بطبيعتها معظم المشكلات في تعلُم الآلة (Machine learning) تمييزية (discriminative). و لفهم الفرق ، دعنا نلقي نظرة على مثال.
لنفترض أن لدينا مجموعة بيانات من اللوحات ، بعضها رسمها فان جوخ والبعض الآخر لفنانين آخرين. مع وجود بيانات كافية ، يمكننا تدريب نموذج تمييزي للتنبؤ بما إذا كانت لوحة معينة قد رسمها فان جوخ. و في هذه الحالة سيتعلم نموذجنا أن بعض الألوان والأشكال والقوام من المرجح أن تشير إلى أن اللوحة هي من قبل الرسام الهولندي ، وبالنسبة للوحات بهذه السمات (features) ، فإن النموذج سيزيد من توقعه وفقًا لذلك.
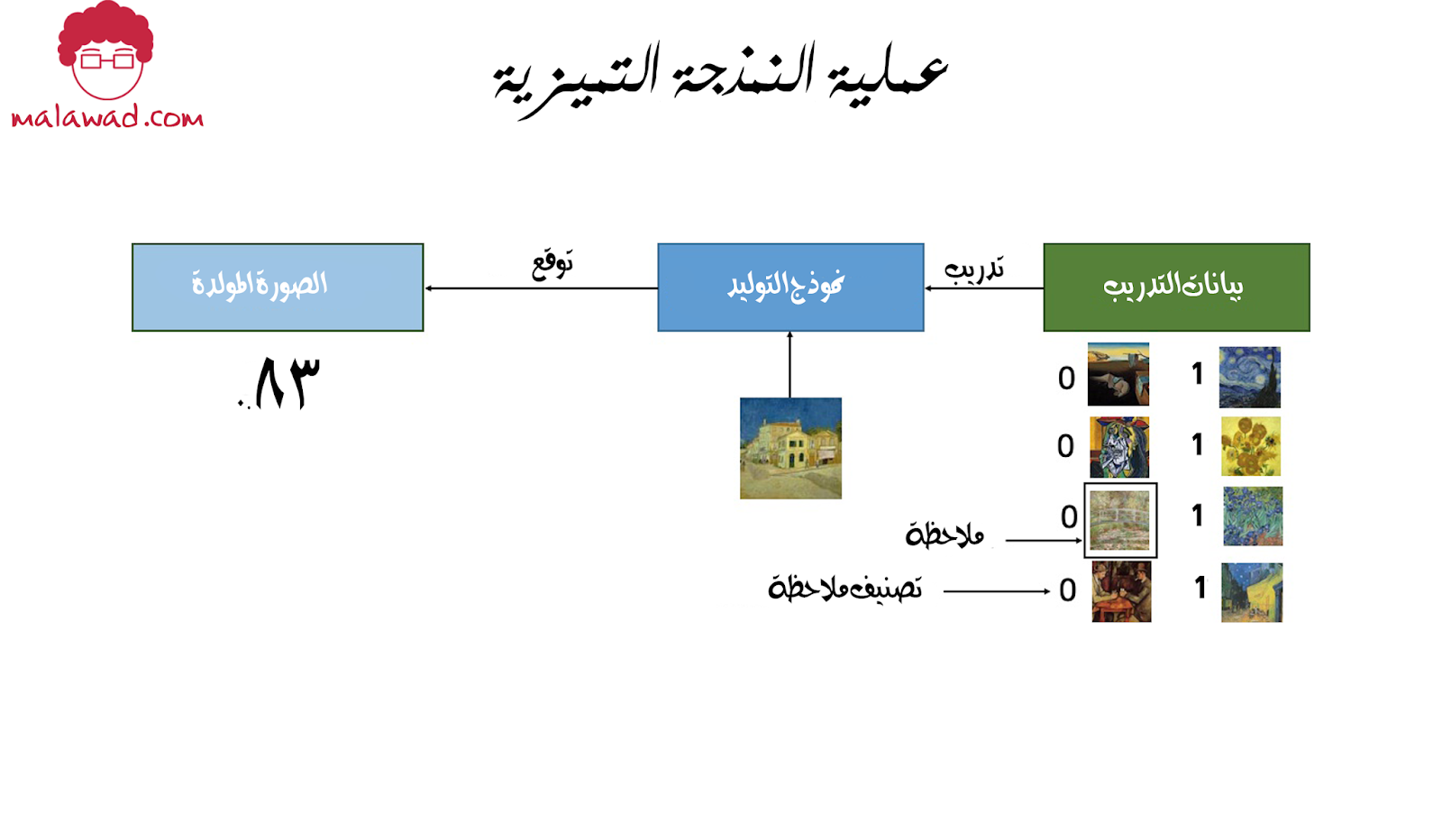
أحد الاختلافات الرئيسية هو أنه عند أداء النمذجة التمييزية ، كل ملاحظة في بيانات التدريب (observation) لها تسمية أو تصنيف (label).
بالنسبة لمسائل التصنيف الثنائي (binary classification) مثل تمييز الفنان لدينا ، سيتم تصنيف لوحات فان جوخ بـ 1 واللوحات الفنانين الأخرى ستصنف بـ 0. ثم يتعلم نموذجنا كيفية التمييز بين هاتين المجموعتين ويخرج احتمالية أن تكون الملاحظة الجديدة تحمل التصنيف 1 . أي أنه رسمها فان جوخ.
لهذا السبب ، فإن النمذجة التمييزية (discriminative modeling ) هي مرادف لما يعرف ب التعلم تحت الإشراف (supervised learning) ،
عادةً ما يتم تنفيذ النمذجة التوليدية (Generative modeling) باستخدام مجموعة بيانات غير مصنفة ( أو ما يعرف بالتعلم من دون إشراف) على الرغم من أنه يمكن أيضًا تطبيقها على مجموعة بيانات مصنفة لتعلم كيفية إنشاء ملاحظات عن كل تصنيف معين
- بالنسية للنمذجة التمييزية نحن نهتم بالأتي (P(x|y)) – أي احتمالية التصنيف y بالنظر إلى الملاحظة x.
- أما النمذجة التوليدية فنهتم (P(x)) – أي احتمالية مراقبة الملاحظة x. إذا تم تصنيف مجموعة البيانات ، فيمكننا أيضًا إنشاء نموذج مولّد يقدّر توزيع (P(x|y)).
النمذجة التمييزية تقوم بمحاولة تقدير احتمال أن الملاحظة x تنتمي إلى الفئة y.
النمذجة التوليدية لا تهتم بتمييز الملاحظات. بدلاً من ذلك ، تحاول تقدير احتمالية رؤية الملاحظة على الإطلاق.
النقطة الأساسية :هي أنه حتى لو تمكنا من بناء نموذج تمييزي مثالي لتحديد لوحات فان جوخ ، فلن يكون لديها أي فكرة عن كيفية إنشاء لوحة تبدو مثل فان جوخ.
يمكن لنموذجنا فقط إخراج الاحتمالات مقابل الصور الموجودة ، لأن هذا هو ما تم تدريبه على القيام به. وبدلاً من ذلك ، نحتاج إلى تدريب نموذج مولّد ، يمكنه إنتاج مجموعات من وحدات النقاط الضوئية التي لديها فرصة كبيرة للانتماء إلى مجموعة بيانات التدريب الأصلية.
نهضة النمذجة التوليدية
على الرغم من أن النمذجة التمييزية قد وفرت حتى الآن الجزء الأكبر من الزخم وراء التقدم في التعلم الآلي ، إلا أن العديد من التطورات الأكثر إثارة للاهتمام في هذا المجال في السنوات الثلاث إلى الخمس الماضية قد أتت من خلال تطبيقات جديدة للتعلم العميق لمهام النمذجة التوليدية.
على وجه الخصوص ، كان هناك اهتمام إعلامي متزايد بمشاريع النمذجة التوليدية مثل StyleGAN من NVIDIA ، القادر على إنشاء صور واقعية للغاية للوجوه البشرية ، ونموذج اللغة GPT-2 من OpenAI ، القادر على توليد نصوص كاملة من خلال إعطائة فقرة تمهيدية قصيرة
توضح الصورة التالية التقدم المذهل الذي تم إحرازه بالفعل في توليد صور الوجه منذ 2014. هناك تطبيقات إيجابية واضحة هنا لصناعات مثل تصميم الألعاب والتصوير السينمائي ، ومن المؤكد أن التطورات في توليد الموسيقى الأوتوماتيكية سيكون لها صدى واسع في هذه المجالات. يبقى أن نرى ما إذا كنا سنقرأ يومًا ما المقالات الإخبارية أو الروايات التي كتابتها عن طريق نموذج توليد ، في حين أنها مثيرة ، إلا أن هذا يثير أيضًا أسئلة أخلاقية حول انتشار المحتوى المزيف على الإنترنت ويعني أنه قد يصبح من الصعب أبدًا الوثوق بما نراه وقراءة من خلال قنوات الاتصال العامة.

بالإضافة إلى الاستخدامات العملية للنمذجة التوليدية (والعديد منها لم يتم اكتشافه بعد) ، هناك ثلاثة أسباب مهمة تجعل النمذجة التوليدية هي المفتاح لفتح أشكال أكثر تعقيدًا للذكاء الاصطناعي ، والذي يتجاوز قدرات ما يمكن لأي نموذج تمييزي وحده أن يحققه.
أولاً ، من وجهة نظر نظرية بحتة ، لا ينبغي لنا أن نكتفي بالقدرة فقط على التفوق في تصنيف البيانات ولكن يجب علينا أيضًا البحث عن فهم أكثر اكتمالًا لكيفية إنشاء البيانات في المقام الأول.
ثانيًا ، من المحتمل جدًا أن تكون النمذجة التوليدية أساسية لدفع التطورات المستقبلية في مجالات أخرى لتعلم الآلة ، مثل التعلم المعزز (و الذي يهتم بتعليم عميل في بيئة إفتراضية للقيام بمهمة ما عن طريق التجربة و الخطاً). على سبيل المثال ، يمكننا استخدام التعلم المعزز لتدريب الروبوت على المشي عبر تضاريس معينة. و النهج العام للقيام بذلك هو في بناء محاكاة كمبيوتر للتضاريس ثم إجراء العديد من التجارب حيث يحاول العميل في كل مرة إستخدام استراتيجيات مختلفة. بمرور الوقت ، سيتعرف العميل على الاستراتيجيات الأكثر نجاحًا من غيرها وبالتالي يتحسن تدريجيًا.
تتمثل المشكلة في هذا النهج في أن فيزياء البيئة غالبًا ما تكون معقدة للغاية وسيتعين حسابها في كل خطوة زمنية من أجل تغذية المعلومات مرة أخرى إلى العميل ليقرر الخطوة التالية. ومع ذلك ، إذا كان الوكيل قادرًا على محاكاة بيئته من خلال النموذج التوليدي ، فلن يحتاج إلى اختبار الاستراتيجية في محاكاة الكمبيوتر أو في العالم الحقيقي ، ولكن بدلاً من ذلك يمكنه التعلم في بيئته الخيالية الخاصة.
أخيرًا ، إذا أردنا أن نقول حقًا أننا بنينا آلة اكتسبت شكلًا من الذكاء يمكن مقارنته بالإنسان ، فلا بد أن تكون النمذجة التوليدية جزءًا من الحل.
إطار النمذجة التوليدي (Generative Modeling Framwork)
دعنا نبدأ بلعبة عن النمذجة التوليدية و لكن في بُعدين فقط. لقد اخترتنا قاعدة تم استخدامها لإنشاء توزيع مجموعة النقاط X في هذه الصورة. دعنا نسمي هذه القاعدة pdata. التحدي هنا هو اختيار نقطة مختلفة x=(x1,x2) في المساحة التي يبدو أنها تم إنشاؤها بواسطة نفس القاعدة.

أين اخترت؟ من المحتمل أنك استخدمت معرفتك بنقاط البيانات الموجودة لإنشاء نموذج عقلي عن مكان وجود الذي من المرجح أن يتم العثورعلى النقطة فيه. في هذا الصدد ،النموذج الذي أنشئناه pmodel هو تقدير للقاعدة pdata.
ربما قررت أن شكل النموذج pmodel يجب أن يبدو كمربع مستطيل بداخله يمكن العثور على نقاط ، أما خارجه فلا توجد فرصة للعثور على أي نقاط. لإنشاء ملاحظة جديدة ، يمكنك ببساطة اختيار نقطة عشوائية داخل الصندوق ، أو بشكل رسمي أكثر ، عينة من نموذج التوزيع. …..تهانينا ، ابتكرنا للتو نموذجنا التوليدي الأول!

على الرغم من أن هذا ليس المثال الأكثر تعقيدًا ، إلا أنه يمكننا استخدامه لفهم ما تحاول النمذجة التوليدية تحقيقه. يحدد الإطار (Framework) التالي دوافعنا.
إطار النمذجة التوليدي
1- لدينا مجموعة بيانات من الملاحظات X.
2- نفترض أن الملاحظات تم إنشاؤها وفقًا لتوزيع غير المعروف (unknown distribution) pdata.
3- يحاول نموذج التوليدي pmodel محاكاة البيانات. إذا حققنا هذا الهدف ، فيمكننا أخذ عينة من pmodel لإنشاء ملاحظات يبدو أنها مستمدة من pdata.
4- نقول بأن النموذج pmodel قام بعمل جيد إذا ما :
القاعدة 1: تمكن من إنشاء أمثلة يبدو أنها مستمدة من توزيع البيانات pdata.
القاعدة 2: تمكن من توليد أمثلة مختلفة عن الملاحظات في X. وبعبارة أخرى ، لا ينبغي للنموذج ببساطة إعادة إنتاج الأشياء التي شاهدها بالفعل.
دعنا الآن نكشف عن التوزيع الحقيقي لإنشاء البيانات ، ونرى كيف ينطبق الإطار على هذا المثال.
كما نرى من الشكل فإن قاعدة توليد البيانات هي ببساطة توزيع النقاط على كتلة اليابسة في العالم ، مع عدم وجود فرصة لإيجاد نقطة في البحر.
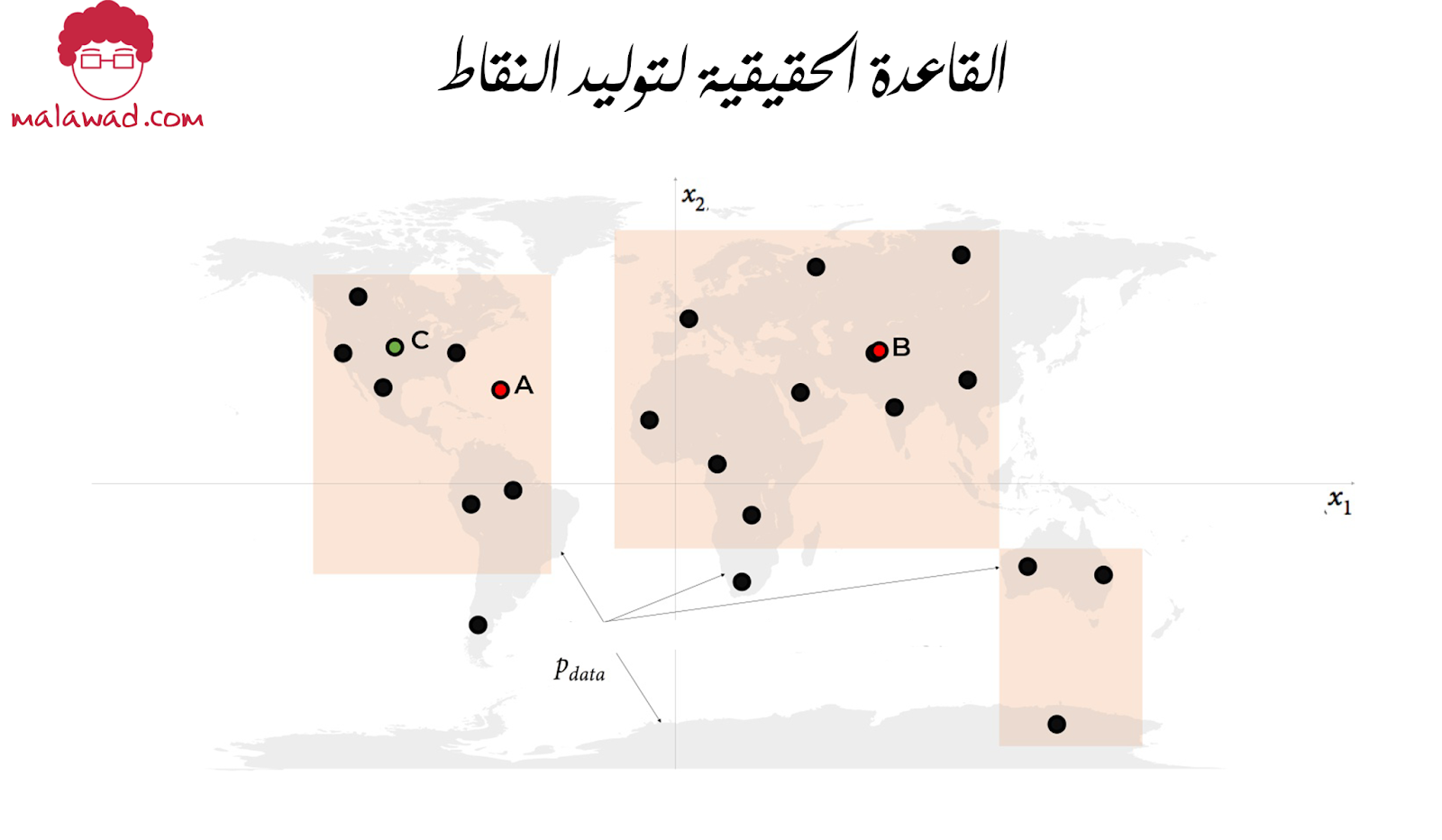
توضح النقاط A و B و C ثلاث ملاحظات تم إنشاؤها بواسطة نموذج التوليد pmodel بدرجات متفاوتة من النجاح:
• النقطة A تخرق القاعدة 1 من إطار عمل النمذجة التوليدي – لا يبدو أنها قد تم إنشاؤها بواسطة توزيع البيانات pdata لأنها في منتصف البحر.
• النقطة B قريبة جدًا من نقطة في مجموعة البيانات فلا ينبغي أن ننبهر بأن نموذجنا يمكن أن يولد مثل هذه النقطة. إذا كانت جميع الأمثلة التي تم إنشاؤها بواسطة النموذج على هذا النحو ، فسوف نخل بالقاعدة 2 من إطار عمل النمذجة التوليدي.
• يمكن اعتبار النقطة C ناجحة لأنها قد تكون ناتجة عن توزيع البيانات pdata وتختلف بشكل مناسب عن أي نقطة في مجموعة البيانات الأصلية.
مجال النمذجة التوليدية متنوع ويمكن أن يأخذ تعريف المشكلة مجموعة متنوعة من الأشكال. ومع ذلك ، في معظم السيناريوهات ، إطار عمل النمذجة التوليدي يمنحنا تصور موسع عن كيف يجب أن نفكر معالجة أي مشكلة.




إضافة تعليق