
نمذجة الموضوع (topic modeling) هي واحدة من أكثر التطبيقات شيوعاً في معالجة اللغة الطبيعية في حالات الاستخدام الصناعي. لتحليل الأشكال المختلفة للنص من المقالات الإخبارية إلى التغريدات ، من تصور سحابات الكلمات إلى إنشاء الرسوم البيانية للموضوعات والمستندات المتصلة ، فإن نماذج الموضوعات مفيدة لمجموعة من حالات الاستخدام. تُستخدم نماذج الموضوعات على نطاق واسع لتجميع المستندات وتنظيم مجموعات كبيرة من البيانات النصية. كما أنها مفيدة لتصنيف النص.
ما هي نمذجة الموضوع ؟
لنفترض أننا حصلنا على مجموعة كبيرة من المستندات ، وطُلب منا أن “نفهم” منها. ماذا سنفعل؟ من الواضح أن المهمة ليست محددة بشكل جيد. نظرًا للكم الكبير من المستندات ، فإن تصفح كل منها يدويًا ليس خيارًا. تتمثل إحدى طرق التعامل معها في إخراج بعض الكلمات التي تصف المجموعة بشكل أفضل ، مثل أكثر الكلمات شيوعًا في المجموعة.
هذا يسمى سحابة الكلمات. مفتاح سحابة الكلمات الجيدة هو إزالة كلمات التوقف. إذا أخذنا أي مجموعة نصية باللغة الإنجليزية وقمنا بسرد الكلمات k الأكثر شيوعًا ، فلن نحصل على أي إحصاءات ذات مغزى ، حيث ستكون الكلمات الأكثر شيوعًا هي كلمات التوقف (the ، is ، are ، am ، إلخ). بعد إجراء المعالجة المسبقة المناسبة ، قد تقدم سحابة الكلمات بعض الأفكار المفيدة اعتمادًا على مجموعة المستندات.
هناك طريقة أخرى تتمثل في تقسيم المستندات إلى كلمات وعبارات ، ثم تجميع هذه الكلمات والعبارات معًا بناءً على بعض فكرة التشابه بينها. يمكن بعد ذلك استخدام مجموعات الكلمات والعبارات الناتجة لبناء بعض الفهم لما يدور حوله الكتاب. بشكل بديهي ، إذا اخترنا كلمة واحدة من كل مجموعة ، فإن مجموعة الكلمات المختارة تمثل (بالمعنى الدلالي) ما تدور حوله المجموعة. الاحتمال الآخر هو استخدام TF-IDF سبق و تحدثنا عنه هنا و هنا.
ضع في اعتبارك مجموعة من الوثائق حيث توجد بعض الوثائق حول الزراعة. بعد ذلك ، يجب أن تشكل مصطلحات مثل “مزرعة” و “محاصيل” و “قمح” و “زراعة” “الموضوعات” في الوثائق المتعلقة بالزراعة. ما أسهل طريقة للعثور على هذه المصطلحات التي تتكرر كثيرًا في المستند ولكنها لا تظهر كثيرًا في المستندات الأخرى في المجموعة؟
نمذجة الموضوع (topic modeling) تعمل على تفعيل هذا الحدس. يحاول تحديد الكلمات “الرئيسية” (تسمى “الموضوعات”) الموجودة في مجموعة نصية دون معرفة مسبقة عنها ، على عكس مناهج التنقيب عن النص المستندة إلى القواعد التي تستخدم التعبيرات العادية أو تقنيات البحث عن الكلمات الرئيسية المستندة إلى القاموس. يوضح الشكل أدناه تصورًا لنتائج تصور نمذجة الموضوع لمجموعة من العلوم الإنسانية.
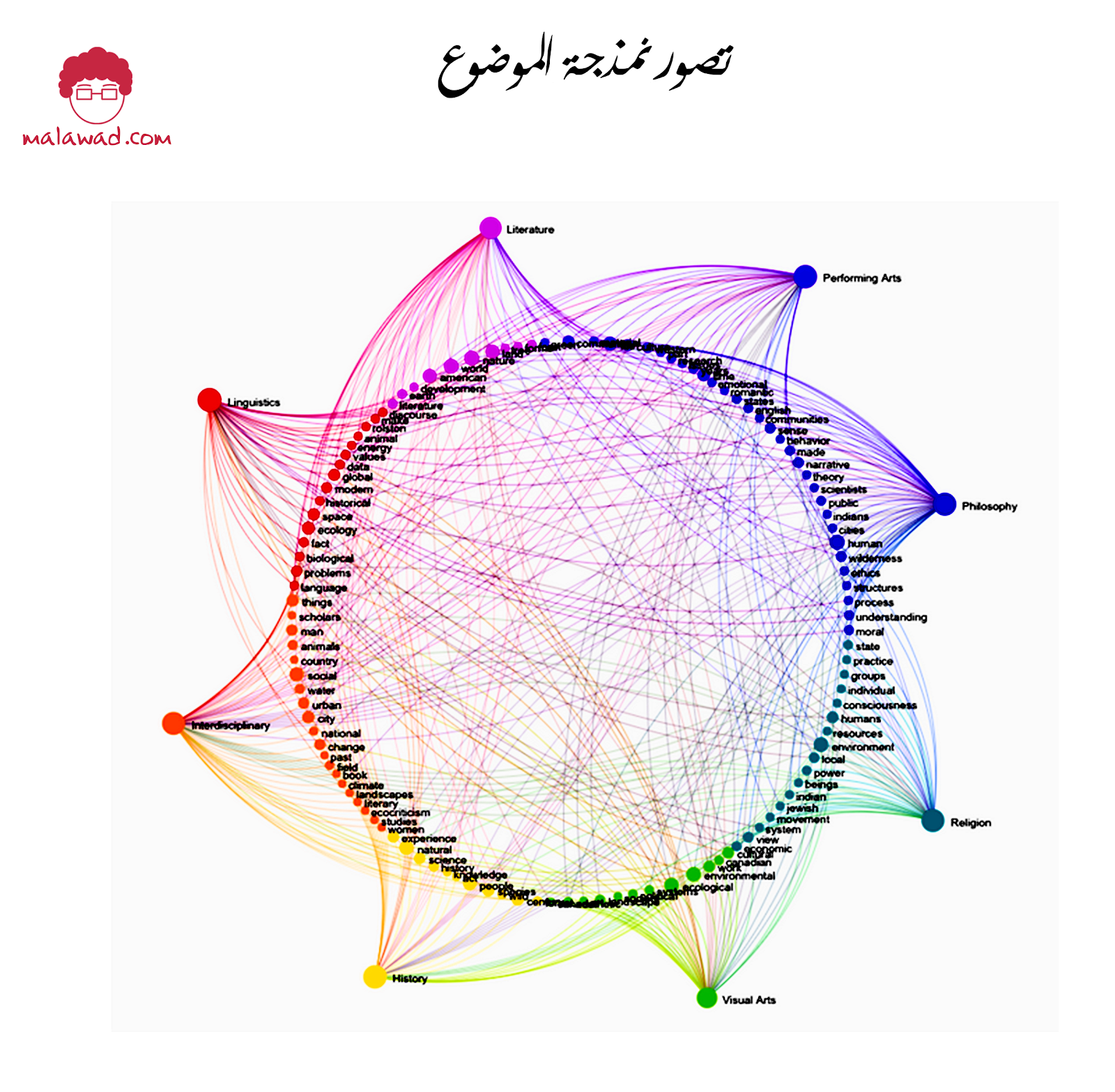
في هذا الشكل ، نرى مجموعة من الكلمات الرئيسية للتخصصات الإنسانية الفردية – وكذلك كيفية تداخل بعض الكلمات الرئيسية بين التخصصات – تم الحصول عليها من خلال تصور نمذجة الموضوع . هذا مثال على كيفية استخدام نمذجة الموضوع لاكتشاف الموضوعات في مجموعة كبيرة من النص. يجب ملاحظة أنه لا يوجد م نمذجة الموضوع واحد.
تشير نمذجة الموضوع عمومًا إلى مجموعة من طرق التعلم الإحصائي غير الخاضعة للإشراف لاكتشاف الموضوعات الكامنة في مجموعة كبيرة من المستندات النصية. بعض خوارزميات نمذجة الموضوعات الشائعة هي latent Dirichlet allocation (LDA) ، والتحليل الدلالي الكامن (LSA) ، والتحليل الدلالي الكامن الاحتمالي (PLSA). من الناحية العملية ، التقنية الأكثر استخدامًا هي تقنية LDA.
نمذجة الموضوع بواسطة خوارزمية LDA
ماذا تفعل LDA؟ لنبدأ بمجموعة بيانات صغيرة. لنفترض أن لدينا مجموعة من المستندات ، من D1 إلى D5 ، وأن كل مستند يتكون من جملة واحدة:
D1: أحب أكل البروكلي والموز.
D2: أكلت موزة وسلطة على الإفطار.
D3: الجراء والقطط لطيفة.
D4: تبنت أختي قطة أمس.
D5: انظر إلى هذا الهامستر اللطيف يمضغ قطعة من البروكلي.
قد يؤدي تعلم نموذج موضوع في هذه المجموعة باستخدام LDA إلى إنتاج مثل هذا:
الموضوع أ: 30٪ بروكلي ، 15٪ موز ، 10٪ فطور ، 10٪ مضغ
الموضوع ب: 20٪ كلاب ، 20٪ قطط ، 20٪ لطيف ، 15٪ هامستر
المستند 1 و 2: 100٪ الموضوع أ
المستند 3 و 4: 100٪ الموضوع ب
المستند 5: 60٪ الموضوع أ ، 40٪ الموضوع ب
وبالتالي ، فإن الموضوعات ليست سوى مزيج من الكلمات الرئيسية مع توزيع احتمالي ، وتتكون المستندات من مزيج من الموضوعات ، مرة أخرى مع توزيع احتمالي. تعطي نمذجة الموضوع مجموعة من الكلمات الأساسية لكل موضوع فقط. ما يمثله الموضوع بالضبط وما يجب تسميته يُترك عادةً للتفسير البشري في نموذج LDA. هنا ، قد ننظر إلى الموضوع “أ” ونقول ، “إنه يتعلق بالطعام”. وبالمثل ، بالنسبة للموضوع ب ، قد نقول ، “يتعلق الأمر بالحيوانات الأليفة”.
طريقة عمل الخوارزمية
تفترض LDA أن الوثائق قيد النظر قد تم إنتاجها من مزيج من الموضوعات. وتفترض كذلك أن العملية التالية تولد هذه المستندات:
في البداية ، لدينا قائمة بالموضوعات ذات التوزيع الاحتمالي. لكل موضوع ، توجد قائمة مرتبطة بالكلمات مع توزيع احتمالي. ناخذ عينة k مواضيع من توزيع الموضوع. لكل موضوع من مواضيع k المحددة ، نقوم بأخذ عينات من الكلمات من التوزيع المقابل. هذه هي الطريقة التي يتم بها إنشاء كل مستند في المجموعة.
الآن ، بالنظر لمجموعة من المستندات ، يقوم LDA بعمل إقتفاء رجعي للعملية التوليد ومعرفة الموضوعات التي ستنشئ هذه المستندات. تسمى الموضوعات “كامنة” لأنها مخفية ويجب اكتشافها.
كيف تفعل LDA هذا الإقتفاء ؟ يقوم بذلك عن طريق تحليل مصفوفة مصطلح المستند (M) التي تحافظ على عدد الكلمات في جميع المستندات .
يحتوي على جميع m مستندات D1 ، D2 ، D3 … Dm مرتبة على طول الصفوف وكل n الكلمات W1 ، W2 ، .. ، Wn في مفردات المجموعة مرتبة كأعمدة. M [i، j] هو عدد مرات تكرار الكلمة Wj في المستند Di. يوضح الشكل أدناه إحدى هذه المصفوفات لمجموعة افتراضية تتكون من خمس وثائق ، مع مفردات من ست كلمات.

لاحظ أنه إذا كانت كل كلمة في المفردات تمثل بُعدًا فريدًا وكان إجمالي المفردات بحجم n ، فإن الصف i من هذه المصفوفة هو متجه يمثل المستند i في هذا الفضاء ذي الأبعاد n. يقوم LDA بتحويل M إلى قسمين فرعيين: M1 و M2.
M1 عبارة عن مصفوفة موضوعات المستند و M2 عبارة عن مصفوفة موضوع – مصطلحات ، بأبعاد (M ، K) و (K ، N) ، على التوالي. مع أربعة مواضيع (K1 – K4) ، قد تبدو المخططات الفرعية لـ M مثل تلك الموضحة في الشكل أدناه. هنا ، k هو عدد الموضوعات التي نهتم بالعثور عليها.

k عدد المواضيع هو مُدخل ضبط (hyperparameter). يتم العثور على القيمة المثلى لـ k عن طريق التجربة والخطأ.
يمكن بعد ذلك استخدام هذه المخططات الفرعية لفهم بنية موضوع المستند والكلمات الأساسية التي يتكون منها الموضوع. الآن بعد أن أصبح لدينا فكرة عما يحدث خلف الكواليس عندما نقوم بتدريب نمذجة موضوع ، دعنا نلقي نظرة على كيفية بناء نموذج.
تدريب نموذج نمذجة موضوع : مثال
لقد رأينا المفهوم وراء LDA. كيف نبني واحدًا بأنفسنا؟ هنا ، سنستخدم تطبيق LDA من مكتبة Python Gensim ومجموعة بيانات ملخص كتاب CMU التي استخدمناها سابقًا لتوضيح كيفية إنشاء محرك بحث. يوضح مقتطف الكود التالي كيفية تدريب نموذج موضوع باستخدام LDA:
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from gensim.models import LdaModel
from gensim.corpora import Dictionary
from pprint import pprint
# المعالجة المسبفة
def preprocess(textstring):
stops = set(stopwords.words('english'))
tokens = word_tokenize(textstring)
return [token.lower() for token in tokens if token.isalpha() and token not in stops]
data_path = "Data/booksummaries.txt"
summaries = []
for line in open(data_path, encoding="utf-8"):
temp = line.split("\t")
summaries.append(preprocess(temp[6]))
# إنشاء تمثيل قاموس للمستند
dictionary = Dictionary(summaries)
# ترشيح الكلمات الغير شائعة و المتكررة بكثرة
dictionary.filter_extremes(no_below=10, no_above=0.5)
corpus = [dictionary.doc2bow(summary) for summary in summaries]
# إنشاء قاموس فهرس إلى كلمة
temp = dictionary[0]
id2word = dictionary.id2token
# تدريب نموذج نمذجة الموضوع
model = LdaModel(corpus=corpus, id2word=id2word,iterations=400, num_topics=10)
top_topics = list(model.top_topics(corpus))
pprint(top_topics)
إذا قمنا بفحص الموضوعات بصريًا ، فقد أظهر أحدها كلمات مثلs police, case, murdered, killed, death, body, وما إلى ذلك. في حين أن الموضوعات نفسها لن تحصل على أسماء في نموذج الموضوع ، عند النظر في الكلمات الرئيسية ، قد نستنتج من هذا أن الموضوع يتعلق بروايات الجريمة / الإثارة.
كيف نقيم النتائج؟ بالنظر إلى مصفوفة الموضوع – المصطلح لـ LDA ، نقوم بتصنيف كل موضوع من أوزان المصطلح الأعلى إلى الأدنى ثم نختار المصطلحات n الأولى لكل موضوع.
نقوم بعد ذلك بقياس تماسك المصطلحات في كل موضوع ، والذي يقيس بشكل أساسي مدى تشابه هذه الكلمات مع بعضها البعض. بالإضافة إلى ذلك ، في هذا المثال ، قمنا ببعض الاختيارات لمعايير النموذج ، مثل عدد التكرارات وعدد الموضوعات وما إلى ذلك ، ولم نقم بأي ضبط دقيق.
كما هو الحال مع أي مشروع في العالم الحقيقي ، نحتاج إلى تجربة معايير مختلفة ونماذج موضوعات مختلفة قبل اختيار نموذج نهائي لنشره. يوفر هذا المقال من Gensim حول LDA مزيدًا من المعلومات حول كيفية إنشاء نموذج موضوع وضبطه وتقييمه.
الآن بعد أن عرفنا كيفية بناء نموذج موضوع ، كيف يمكننا استخدامه بالضبط؟ بعض حالات الاستخدام لنماذج الموضوعات هي:
- تلخيص المستندات والتغريدات وما إلى ذلك ، في شكل كلمات رئيسية بناءً على توزيعات الموضوعات التي تم تعلمها
- الكشف عن اتجاهات وسائل التواصل الاجتماعي على مدار فترة زمنية
- تصميم أنظمة الاقتراحات للنصوص
أيضًا ، يمكن استخدام توزيع الموضوعات لمستند معين كموجه سمه لتصنيف النص.
على الرغم من أنه من الواضح أن هناك مجموعة من حالات الاستخدام لنماذج نمذجة الموضوعات في مشاريع الصناعة ، وهناك عدد قليل من التحديات المرتبطة باستخدامها. لا يزال تقييم نماذج نمذجة الموضوعات وتفسيرها يمثل تحديًا ، ولا يوجد إجماع على ذلك حتى الآن. يمكن أن يستغرق ضبط المعايير لهذه النماذج أيضًا الكثير من الوقت. في المثال أعلاه ، قدمنا عدد الموضوعات يدويًا. كما ذكرنا سابقًا ، لا يوجد إجراء مباشر لمعرفة عدد الموضوعات ؛ نستكشف بقيم متعددة بناءً على تقديراتنا حول الموضوعات الموجودة في مجموعة البيانات. شيء آخر يجب مراعاته هو أن نماذج مثل LDA تعمل عادةً فقط مع المستندات الطويلة وأداء ضعيف في المستندات القصيرة ، مثل مجموعة التغريدات.
ختاما
على الرغم من كل هذه التحديات ، تعد نماذج الموضوعات أداة مهمة في أي مجموعة أدوات لمهندس معالجة اللغة الطبيعية ، ولديها مدى وصول أوسع من حيث المكان الذي يمكن استخدامها فيه. نأمل أن نقدم لك معلومات كافية لمساعدتك في تحديد حالات الاستخدام المناسبة في مكان عملك. يمكن للقارئ المهتم البدء في [23] للتعمق في هذا الموضوع.













إضافة تعليق