
يساعد نمط تصميم السمة المتقاطعة (Feature Cross) النماذج على تعلم العلاقات بين المدخلات بشكل أسرع عن طريق جعل كل مجموعة من قيم الإدخال سمة منفصلة بشكل صريح.
المشكلة
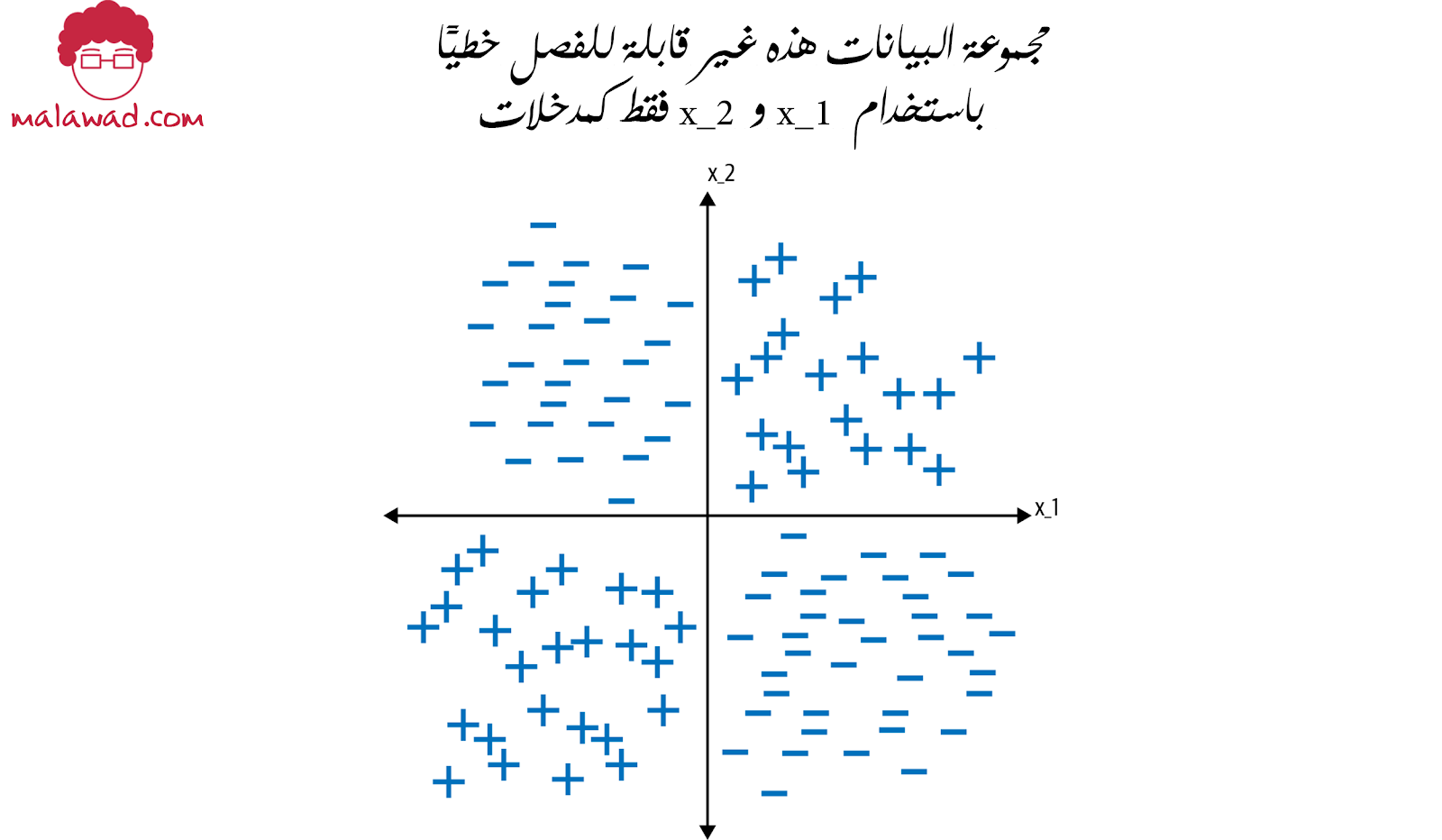
ضع في اعتبارك مجموعة البيانات التالية ومهمة إنشاء مصنف ثنائي يفصل بين التسميتين + و-.
باستخدام إحداثيات x_1 و x_2 فقط ، لا يمكن إيجاد حد خطي يفصل بين الفئتين + و-.
هذا يعني أنه لحل هذه المشكلة ، يتعين علينا جعل النموذج أكثر تعقيدًا ، ربما عن طريق إضافة المزيد من الطبقات إلى النموذج. ومع ذلك ، يوجد حل أبسط.
الحل
في تعلم الألة ، تعد هندسة السمات عملية استخدام معرفة المجال لإنشاء سمات جديدة تساعد في عملية تعلم الألة وتزيد من القوة التنبؤية لنموذجنا. تتمثل إحدى تقنيات هندسة السمات الشائعة الاستخدام في إنشاء السمة المتقاطعة (feature cross).
السمة المتقاطعة عبارة عن سمة تركيبية تتشكل عن طريق ربط سمتين فئويتين أو أكثر من أجل التقاط التفاعل بينهما. من خلال ضم سمتين بهذه الطريقة ، من الممكن ترميز اللاخطية في النموذج ، والذي يمكن أن يسمح بقدرات تنبؤية تتجاوز ما كان بإمكان كل سمة توفيره بشكل فردي.
توفر السمات المتقاطعة طريقة لجعل نموذج تعلم الألة يتعلم العلاقات بين السمات بشكل أسرع. في حين أن النماذج الأكثر تعقيدًا مثل الشبكات العصبية والأشجار يمكن أن تتعلم السمات المتقاطعة بمفردها ، فإن استخدام السمات المتقاطعة بشكل صريح يمكن أن يسمح لنا بالإكتفاء بتدريب النموذج الخطي فقط.
وبالتالي ، يمكن أن تؤدي السمات المتقاطعة إلى تسريع تدريب النموذج (أقل تكلفة) وتقليل تعقيد النموذج (هناك حاجة إلى بيانات تدريب أقل).
لإنشاء عمود سمة لمجموعة البيانات أعلاه ، يمكننا تجميع (bucketize ) x_1 و x_2 كل منهما في حاويتين، اعتمادًا على علامتهما. هذا يحول x_1 و x_2 إلى سمات فئوية.
لنفترض أن:
- A يشير إلى حاوية حيث x_1> = 0
- B هو الحاوية حيث x_1 <0.
- C تشير إلى الحاوية حيث x_2> = 0
- D هي الحاوية حيث x_2 <0 .
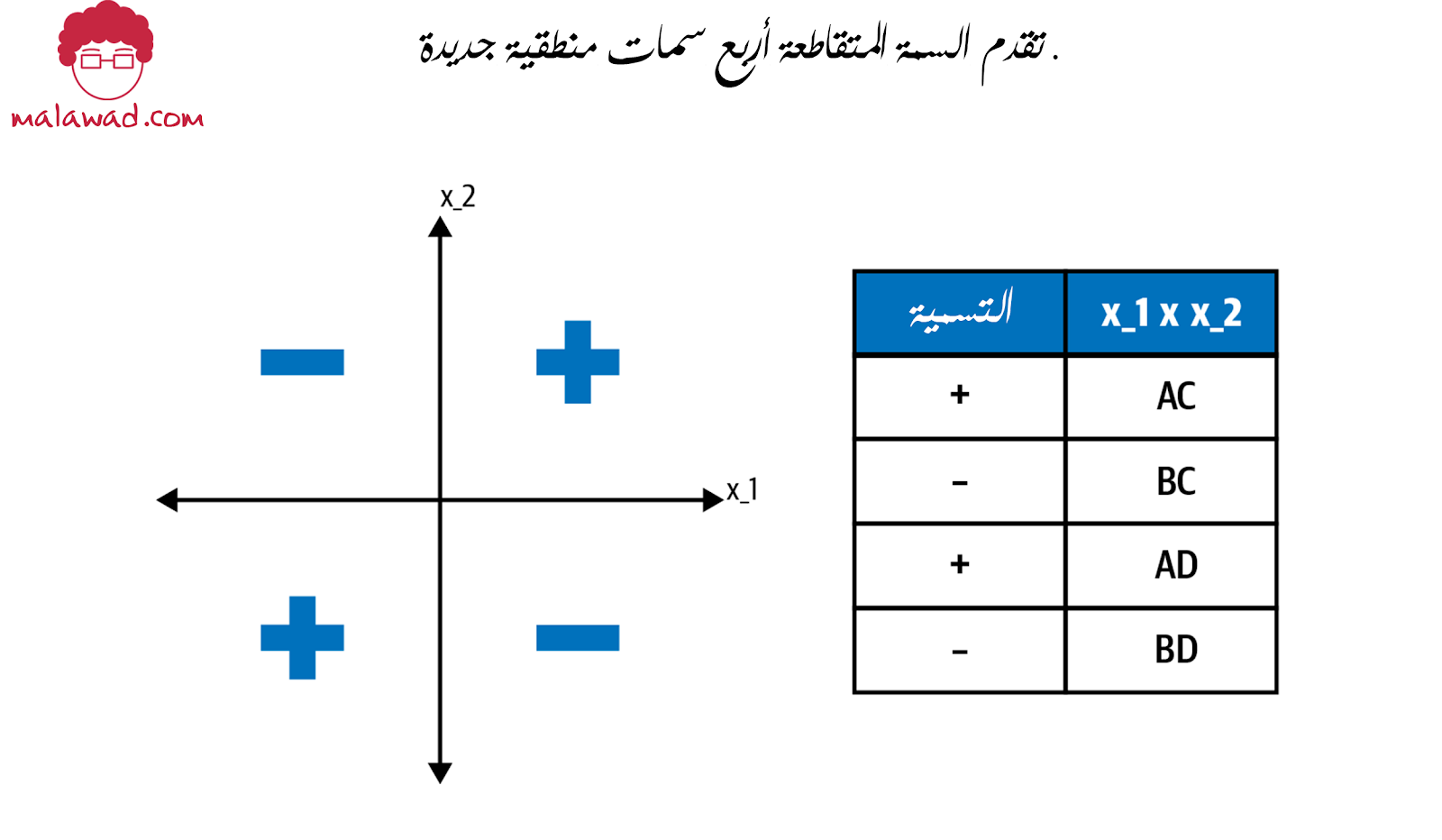
يقدم تقاطع السمات لهذه السمات المجمعة أربع سمات منطقية جديدة لطرازنا:
AC حيث x_1> = 0 و x_2> = 0
BC حيث x_1 <0 و x_2> = 0
AD حيث x_1> = 0 و x_2 <0
BD حيث x_1 <0 و x_2 <0
كل من هذه السمات المنطقية الأربعة (AC و BC و AD و BD) ستحصل على وزنها عند تدريب النموذج. هذا يعني أنه يمكننا التعامل مع كل ربع على أنه سمة خاصة به.
نظرًا لأن مجموعة البيانات الأصلية تم تقسيمها تمامًا بواسطة الحاويات التي أنشأناها ، فإن تقاطع السمات A و B قادر على فصل مجموعة البيانات خطيًا.
لكن هذا مجرد توضيح. ماذا عن بيانات العالم الحقيقي؟ ضع في اعتبارك مجموعة بيانات عامة لركوب سيارة الأجرة الصفراء في مدينة نيويورك .
| pickup_datetime | pickuplon | pickuplat | dropofflon | dropofflat | passengers | fare_amount |
| 2014-05–17 15:15:00 UTC | -73.99955 | 40.7606 | -73.99965 | 40.72522 | 1 | 31 |
| 2013–12-09 15:03:00 UTC | -73.99095 | 40.749772 | -73.870807 | 40.77407 | 1 | 34.33 |
| 2013-04–18 08:48:00 UTC | -73.973102 | 40.785075 | -74.011462 | 40.708307 | 1 | 29 |
| 2009–11-05 06:47:00 UTC | -73.980313 | 40.744282 | -74.015285 | 40.711458 | 1 | 14.9 |
| 2009-05-21 09:47:06 UTC | -73.901887 | 40.764021 | -73.901795 | 40.763612 | 1 | 12.8 |
تحتوي مجموعة البيانات هذه على معلومات حول ركوب سيارات الأجرة في مدينة نيويورك مع سمات مثل وقت الركوب ، وخطي طول وعرض موقع الركوب وكذلك خطي طول و عرض موقع التنزيل و عدد الركاب .
التسمية هنا هي fare_amount ، أي تكلفة ركوب التاكسي. ما هي السمات المتقاطعة التي قد تكون ذات صلة بمجموعة البيانات هذه؟
يمكن أن يكون هناك الكثير. دعنا نفكر في pickup_datetime. من خلال هذه السمة ، يمكننا استخدام معلومات حول ساعة المشوار ويوم الأسبوع.
كل من هذه المتغيرات هي متغير فئوي، وبالتأكيد يحتوي كلاهما على القدرة التنبؤية في تحديد سعر ركوب سيارة أجرة. بالنسبة لمجموعة البيانات هذه ، من المنطقي التفكير في تقاطع سمة يوم_من_أسبوع و الساعة_من_يوم.
نظرًا لأنه من المعقول افتراض أن ركوب سيارات الأجرة في الساعة 5 مساءً يوم الاثنين يجب أن يعامل بشكل مختلف عن ركوب سيارات الأجرة في الساعة 5 مساءً يوم الجمعة.
| day_of_week | hour_of_day |
| Sunday | 00 |
| Sunday | 01 |
| …….. | ……. |
| Saturday | 23 |
ستكون السمة المتقاطعة بين هاتين السمتين هي خط ترميز أحادي أبعاده 168 بُعد (24 ساعة × 7 أيام = 168)
كمثال “الاثنين الساعة 5 مساءً” سيحتل فهرسًا واحدًا بحيث (day_of_week هو يوم الاثنين مرتبط مع hour_of_day هو 17 ).
في حين أن هاتين السمتين مهمتان بحد ذاتهما ، فإن السماح بسمة متقاطعة بين ساعة في اليوم ويوم في الأسبوع يجعل من السهل على نموذج توقع أجرة التاكسي أن يدرك أن ساعة الذروة في نهاية الأسبوع تؤثر على مدة ركوب سيارة الأجرة وبالتالي على أجرة التاكسي بطريقتها الخاصة.
السمة المتقاطعة في BigQuery ML
لإنشاء السمة المتقاطعة في BigQuery ، يمكننا استخدام الوظيفة ML.FEATURE_CROSS وتمرير STRUCT للسمات day_of_week و hour_of_day:
ML.FEATURE_CROSS(STRUCT(day_of_week,hour_of_week)) AS day_X_hour
تُنشئ عبارة STRUCT زوجًا مرتبًا من السمتين. إذا كان إطار عمل البرنامج الخاص بنا لا يدعم وظيفة السمات المتقاطعة ، فيمكننا الحصول على نفس التأثير باستخدام ربط السلسلة:
ML.FEATURE_CROSS(STRUCT(day_of_week,hour_oCONCAT(CAST(day_of_week AS STRING),
CAST(hour_of_week AS STRING)) AS day_X_hourf_week)) AS day_X_hour
فيما يلي مثال تدريبي كامل لمشكلة الولادة ، مع السمة المتقاطعة بين عامودي is_male و plurality المستخدمة كسمة :
CREATE OR REPLACE MODEL babyweight.natality_model_feat_eng
TRANSFORM(weight_pounds,
is_male,
plurality,
gestation_weeks,
mother_age,
CAST(mother_race AS string) AS mother_race,
ML.FEATURE_CROSS(
STRUCT(
is_male,
plurality)
) AS gender_X_plurality)
OPTIONS
(MODEL_TYPE='linear_reg',
INPUT_LABEL_COLS=['weight_pounds'],
DATA_SPLIT_METHOD="NO_SPLIT") AS
SELECT
*
FROM
babyweight.babyweight_data_train
عندما يكون لدينا بيانات كافية ، يتيح نمط السمة المتقاطعة (Feature Cross) للنماذج أن تصبح أبسط.
في مجموعة بيانات الولادة ، دالة الخسارة لمتوسط الخطأ التربيعي (RMSE) للنموذج خطي بنمط السمات المتقاطعة هو 1.056.
في المقابل ، يؤدي تدريب شبكة عصبية عميقة في BigQuery ML على مجموعة البيانات نفسها بدون نمط السمات المتقاطعة إلى الحصول على RMSE يبلغ 1.074. هناك تحسن طفيف في أدائنا على الرغم من استخدام نموذج خطي أبسط بكثير ، كما تم تقليل وقت التدريب بشكل كبير.
السمة المتقاطعة في TensorFlow
لتنفيذ السمة المتقاطعة باستخدام السمات is_male و plurality في TensorFlow ، نستخدم tf.feature_column.crossed_column.
تأخذ الوظيفة المساعدة crossed_column وسيطتين: قائمة بمفاتيح السمات المراد تمرريرها وحجم حاوية التجزئة. ستتم تجزئة السمات المتقاطعة وفقًا لحجم hash_bucket_size لذا يجب أن تكون كبيرة بما يكفي لتقليل احتمالية حدوث تصادمات.
نظرًا لأن إدخال is_male يمكن أن يأخذ 3 قيم (صحيح ، خطأ ، غير معروف) ويمكن أن يأخذ إدخال التعددية 6 قيم (مفرد (1) ، توائم (2) ، ثلاثة توائم (3) ، رباعي (4) ، خماسيات (5) ، متعدد (2+)) ، هناك 18 زوجًا ممكنًا (is_male ، plurality).
إذا قمنا بتعيين حجم hash_bucket_size على 1000 ، فيمكننا التأكد بنسبة 85٪ من عدم وجود تصادمات.
أخيرًا ، لاستخدام عمود متقاطع في نموذج DNN ، نحتاج إلى لفه إما في عمود مؤشر (indicator_column) أو عمود تضمين(embedding_column) اعتمادًا على ما إذا كنا نريد إستخدام خط الترميز الأحادي أو تمثيله في بُعد أقل .
gender_x_plurality = fc.crossed_column(["is_male", "plurality"],
hash_bucket_size=1000)
crossed_feature = fc.embedding_column(gender_x_plurality, dimension=2)

أو
gender_x_plurality = fc.crossed_column(["is_male", "plurality"],
hash_bucket_size=1000)
crossed_feature = fc.indicator_column(gender_x_plurality)
لماذا تعمل
توفر السمات المتقاطعة وسيلة قيمة لهندسة السمات. إنها توفر مزيدًا من التعقيد والمزيد من التعبيرية وقدرة أكبر للنماذج البسيطة.
فكر مرة أخرى في السمة المتقاطعة لـ is_male و plurality في مجموعة بيانات الولادة. يسمح هذا النمط المتقاطع للنموذج بمعالجة التوائم الذكور بشكل منفصل عن التوائم الإناث وما إلى ذلك.
عندما نستخدم عمود index_column ، يكون النموذج قادرًا على التعامل مع كل من التقاطعات الناتجة كمتغير مستقل ، مضيفًا بشكل أساسي 18 سمة فئوية ثنائية إضافية إلى النموذج .
السمة المتقاطعة تتضخم بشكل جيد مع البيانات الضخمة. في حين أن إضافة طبقات إضافية إلى شبكة عصبية عميقة يمكن أن يوفر قدرًا كافيًا من اللاخطية لمعرفة كيفية تتصرف الأزواج (is_male ، plurality) ، فإن هذا يزيد بشكل كبير من وقت التدريب.
في مجموعة بيانات الولادة ، لاحظنا أن النموذج الخطيً مع سمة متقاطعة مدرب في BigQuery ML يعمل بشكل مشابه لنموذج شبكة عصبية عميقة تم تدريبه بدون السمات المتقاطعة. إلا أن النموذج الخطي يتدرب بشكل أسرع.

يقارن الجدول وقت التدريب في BigQuery ML و تقييم الخسارة لكل من النموذج الخطي مع السمة المتقاطعة (is_male ، plurality) والشبكة العصبية العميقة بدون أي سمات متقاطعة (feature cross).
| نوع النموذج | يحتوي سمات متقاطعة | وقت التدريب (دقائق) | تقييم الخسارة (RMSE) |
| خطي (Linear) | نعم | 0.42 | 1.05 |
| شبكة عصبية عميقة (DNN) | لا | 48 | 1.07 |
يحقق الانحدار الخطي البسيط خسارة مشابهًا في مجموعة التقييم ولكنه يتدرب أسرع بمائة مرة. يعد الجمع بين السمات المتقاطعة والبيانات الضخمة استراتيجية بديلة لتعلم العلاقات المعقدة في بيانات التدريب.
المقايضات والبدائل
بينما ناقشنا السمات المتقاطعة كطريقة للتعامل مع المتغيرات الفئوية ، يمكن تطبيقها ، مع القليل من المعالجة المسبقة ، على السمات العددية أيضًا. تتسبب السمات المتقاطعة في تناثر في النماذج وغالبًا ما تُستخدم جنبًا إلى جنب مع التقنيات التي تتصدى لهذا التناثر.
التعامل مع السمات العددية
لن نرغب أبدًا في إنشاء سمة متقاطعة (feature cross) مع إدخال مستمر. تذكر ، إذا كان أحد المدخلات يأخذ m قيمًا ممكنة ومدخلًا آخر يأخذ n من القيم الممكنة ، فإن السمات المتقاطعة بين الاثنين سينتج عنها عناصر m * n.
المدخلات العددية كثيفة ، وتتخذ سلسلة متصلة من القيم. سيكون من المستحيل تعداد جميع القيم الممكنة في تقاطع سمة لبيانات الإدخال المستمرة.
بدلاً من ذلك ، إذا كانت بياناتنا مستمرة ، فيمكننا تجميع البيانات (bucketize the data) لجعلها فئوية قبل تطبيق السمة المتقاطعة.
على سبيل المثال ، يعد خط العرض وخط الطول من المدخلات المستمرة ، ومن المنطقي إنشاء تقاطع للسمات باستخدام هذه المدخلات حيث يتم تحديد الموقع بواسطة زوج مرتب من خطوط الطول والعرض.
ومع ذلك ، بدلاً من إنشاء تقاطع للسمة باستخدام خط العرض وخط الطول الخام ، سنقوم بتخزين هذه القيم المستمرة في حاوية نسميهما binned_latitude و binned_longitude و إنشاء سمة متقاطعة بينهما :
import tensorflow.feature_column as fc
# Create a bucket feature column for latitude.
latitude_as_numeric = fc.numeric_column("latitude")
lat_bucketized = fc.bucketized_column(latitude_as_numeric,
lat_boundaries)
# Create a bucket feature column for longitude.
longitude_as_numeric = fc.numeric_column("longitude")
lon_bucketized = fc.bucketized_column(longitude_as_numeric,
lon_boundaries)
# Create a feature cross of latitude and longitude
lat_x_lon = fc.crossed_column([lat_bucketized, lon_bucketized],
hash_bucket_size=nbuckets**4)
crossed_feature = fc.indicator_column(lat_x_lon)
التعامل مع زيادة عدد عناصر النموذج .
نظرًا لأن العلاقة الأساسية للفئات الناتجة من السمة المتقاطعة تزداد بشكل مضاعف فيما يتعلق بالعناصر الأساسية لسمات الإدخال ، فإن السمات المتقاطعة تؤدي إلى التناثر في مدخلات نموذجنا. حتى مع السمة المتقاطعة day_of_week و hour_of_day ، فإن تقاطع السمات سيكون متجه متناثر أبعادة 168 .

قد يكون من المفيد تمرير السمة المتقاطعة عبر طبقة التضمين لإنشاء تمثيل منخفض الأبعاد ، كما هو موضح.

نظرًا لأن نمط تصميم التضمينات يسمح لنا بالتقاط علاقات التقارب ، فإن تمرير السمة المتقاطعة عبر طبقة التضمين يسمح للنموذج بتعميم كيفية تأثير سمة المتقاطعة معينة قادمة من أزواج من مجموعات الساعات واليوم على إخراج النموذج.
الحاجة للتنظيم
عند مقاطعة سمتين فئويتين يحتوي كل منهما على عدد كبير من العناصر ، فإننا ننتج سمة متقاطعة ذات عناصر مضاعف. وذلك لأنه كلما زاد عدد الفئات في السمة واحدة ، فمن الطبيعي أنه سيزيد عدد الفئات في السمة المتقاطعة بشكل مضاعف.
إذا وصل هذا إلى النقطة التي تحتوي فيها الحاويات الفردية على عدد قليل جدًا من العناصر ، فسيؤدي ذلك إلى إعاقة قدرة النموذج على التعميم.
فكر في مثال خطوط الطول والعرض. إذا أخذنا حاويات جيدة جدًا لخط العرض وخط الطول ، فستكون السمات المتقاطعة دقيقًة جدًا بحيث يسمح للنموذج بحفظ كل نقطة على الخريطة.
ومع ذلك ، إذا كان هذا الحفظ يعتمد على عدد قليل من الأمثلة ، فهذا الحفظ هو في الواقع فرط تخصيص (overfitting).
للتوضيح ، خذ مثالاً على التنبؤ بأجرة التاكسي في نيويورك بالنظر إلى مواقع الالتقاء والتوصيل ووقت الالتقاط:
CREATE OR REPLACE MODEL mlpatterns.taxi_l2reg
TRANSFORM(
fare_amount
, ML.FEATURE_CROSS(STRUCT(CAST(EXTRACT(DAYOFWEEK FROM pickup_datetime)
AS STRING) AS dayofweek,
CAST(EXTRACT(HOUR FROM pickup_datetime)
AS STRING) AS hourofday), 2) AS day_hr
, CONCAT(
ML.BUCKETIZE(pickuplon, GENERATE_ARRAY(-78, -70, 0.01)),
ML.BUCKETIZE(pickuplat, GENERATE_ARRAY(37, 45, 0.01)),
ML.BUCKETIZE(dropofflon, GENERATE_ARRAY(-78, -70, 0.01)),
ML.BUCKETIZE(dropofflat, GENERATE_ARRAY(37, 45, 0.01))
) AS pickup_and_dropoff
)
OPTIONS(input_label_cols=['fare_amount'],
model_type='linear_reg', l2_reg=0.1)
AS
SELECT * FROM mlpatterns.taxi_data
هناك نوعان من السمات المتقاطعة هنا: واحدة في الوقت (من يوم من الأسبوع وساعة من اليوم) والأخرى في الفضاء (لمواقع الالتقاط والتوصيل). الموقع ، على وجه الخصوص ، يتكون من عدد كبير جدًا من العناصر الأساسية ، ومن المحتمل أن تحتوي بعض الحاويات (buckets ) على عدد قليل جدًا من الأمثلة.
لهذا السبب ، يُنصح بإقران السمات المتقاطعة مع تنظيم L1 ، مما يشجع على تباين السمات ، أو تنظيم L2 ، مما يحد من فرط التخصيص. يسمح هذا لنموذجنا بتجاهل الضوضاء الخارجية الناتجة عن العديد من السمات التركيبية وا التعامل مع فرط التخصيص. في الواقع ، في مجموعة البيانات هذه ، يعمل التنظيم على تحسين RMSE قليلاً ، بنسبة 0.3٪.
كنقطة ذات صلة ، عند اختيار السمات المراد دمجها في السمة المتقاطعة ، لا نرغب في تمرير سمتين مترابطتين بشكل كبير. يمكننا التفكير في السمة المتقاطعة على أنه دمج سمتين لإنشاء زوج مرتب.
في الواقع ، يشير مصطلح “تقاطع” “لسمة المتقاطعة” إلى الضرب الديكارتي . إذا كانت هناك سمتان مترابطتان بشكل كبير ، فإن هذا لا يجلب أي معلومات جديدة إلى النموذج.
كمثال متطرف ، افترض أن لدينا سمتين، x_1 و x_2 ، حيث x_2 = 5 * x_1. سيظل تجميع قيم x_1 و x_2 بواسطة علامتهما في حاوية (Bucketing ) وإنشاء سمة متقاطعة سينتج أربع سمات منطقية جديدة.
ومع ذلك ، نظرًا لاعتماد x_1 و x_2 على بعضهما ، فإن اثنتين من هذه السمات الأربعة فارغة بالفعل ، والاثنان الآخران هما هما الحاويتان اللتان تم إنشاؤهما لـ x_1.













إضافة تعليق