
في المقالة الأولى من سلسة التعامل مع مسائل تعلم الألة نتعرف علىالتعلم الخاضع للإشراف و التعلم غير الخاضع للإشراف
التعلم الخاضع للإشراف مقابل التعلم غير الخاضع للإشراف
عند التعامل مع مشكلات التعلم الآلي ، هناك نوعان من البيانات (ونماذج التعلم الآلي):
• البيانات الخاضعة للإشراف: لها دائمًا هدف واحد أو عدة أهداف مرتبطة بها.
• البيانات غير الخاضعة للإشراف: ليس لها أي هدف محدد مسبقاً.
التعلم الخاضع للإشراف
إن معالجة المشكلة الخاضعة للإشراف أسهل بكثير من معالجة المشكلة غير الخاضعة للإشراف. تُعرف المشكلة التي يُطلب منا فيها توقع قيمة بالمشكلة الخاضعة للإشراف (supervised problem) .
على سبيل المثال ، إذا كانت المشكلة تتعلق بالتنبؤ بأسعار المنازل نظرًا لتاريخ أسعار المنازل ، مع وجود سمات مثل وجود مستشفى أو مدرسة أو سوبر ماركت ، أقرب مسافة لوسيلة نقل عام ، وما إلى ذلك ، تعتبر مشكلة خاضعة للإشراف.
وبالمثل ، عندما يتم تزويدنا بصور القطط والكلاب ، ونعرف مسبقًا أي القطط هي القطط وأيها الكلاب ، وإذا كانت المهمة هي إنشاء نموذج يتنبأ بما إذا كانت الصورة المقدمة هي قطة أم كلب ، تعتبر المشكلة خاضعة للإشراف.

كما نرى في الصورة أعلاه ، يرتبط كل صف من البيانات بهدف أو تسمية. الأعمدة عبارة عن سمات مختلفة وتمثل الصفوف نقاط بيانات مختلفة تسمى عادةً الملاحظات (أو العينات). يوضح المثال عشر ملاحظات تحتوي على عشر سمات ومتغير مستهدف يمكن أن يكون إما رقمًا أو فئة.
إذا كان الهدف صنف، تصبح المشكلة مشكلة تصنيف. وإذا كان الهدف رقم حقيقي ، تصبح المشكلة مشكلة إنحدار (regression problem) .
وبالتالي ، يمكن تقسيم المشاكل الخاضعة للإشراف إلى فئتين فرعيتين:
• التصنيف: التنبؤ بفئة ، على سبيل المثال. كلب أو قطة.
• الانحدار: التنبؤ بقيمة ، على سبيل المثال أسعار المنزل.
وتجدر الإشارة إلى أنه في بعض الأحيان قد نستخدم الانحدار (regression) في مشاكل التصنيف اعتمادًا على المقياس المستخدم للتقييم. لكننا سنتحدث عن ذلك لاحقًا.
التعلم غير الخاضع للإشراف
نوع آخر من مشاكل التعلم الآلي هو النوع غير الخاضع للإشراف. لا تحتوي مجموعات البيانات غير الخاضعة للإشراف على هدف مرتبط بها وبشكل عام ، يكون التعامل معها أكثر صعوبة عند مقارنتها بالمشكلات الخاضعة للإشراف.
لنفترض أنك تعمل في شركة مالية تتعامل مع معاملات بطاقات الائتمان. هناك الكثير من البيانات التي تأتي في كل ثانية. المشكلة الوحيدة هي أنه من الصعب العثور على بشر يضعون علامة على كل معاملة سواء على أنها معاملة صحيحة أو حقيقية أو عملية احتيال.
عندما لا تتوفر لدينا أي معلومات حول معاملة احتيالية أو حقيقية، تصبح المشكلة مشكلة غير خاضعة للإشراف. لمعالجة هذه الأنواع من المشاكل ، علينا التفكير في عدد المجموعات التي يمكن تقسيم البيانات إليها.
التجميع(Clustering) هو أحد الأساليب التي يمكنك استخدامها لمشاكل مثل هذه ، ولكن يجب ملاحظة أن هناك العديد من الأساليب الأخرى المتاحة التي يمكن تطبيقها على المشكلات غير الخاضعة للإشراف.
بالنسبة لمشكلة اكتشاف الاحتيال ، يمكننا القول أنه يمكن تقسيم البيانات إلى فئتين (احتيالية أو حقيقية). عندما نعرف عدد المجموعات ، يمكننا استخدام خوارزمية التجميع للمشكلات غير الخاضعة للإشراف.
في الصورة أدناه ، يُفترض أن تحتوي البيانات على فئتين ، ويمثل اللون الداكن الاحتيال ، ويمثل اللون الفاتح معاملات حقيقية.

هذه الفئات ، مع ذلك ، ليست معروفة لنا قبل نهج التجميع. بعد تطبيق خوارزمية التجميع ، يجب أن نكون قادرين على التمييز بين الهدفين المفترضين. لفهم المشكلات غير الخاضعة للإشراف ، يمكننا أيضًا استخدام العديد من تقنيات التحلل (decomposition techniques) مثل تحليل المكونات الرئيسية (Principal Component Analysis) أو بإختصار (PCA) ، و توزيع ت العشوائي للتضمين الجواري (t-distributed Stochastic Neighbour Embedding) أو بإختصار (t-SNE) وما إلى ذلك.
يسهل التعامل مع المشكلات الخاضعة للإشراف لأنه يمكن تقييمها بسهولة. ومع ذلك ، من الصعب تقييم نتائج الخوارزميات غير الخاضعة للإشراف والكثير من التدخل البشري أو الاستدلال مطلوب.
التعامل مع مجموعة البيانات
في معظم الأوقات ، عندما يبدأ الأشخاص بعلوم البيانات أو التعلم الآلي ، فإنهم يبدأون بمجموعات بيانات معروفة جدًا ، على سبيل المثال ، مجموعة بيانات Titanic أو مجموعة بيانات Iris و هي مشاكل خاضعة للإشراف.
في مجموعة بيانات تيتانيك ، عليك أن تتوقع بقاء الأشخاص على متن تيتانيك بناءً على عوامل مثل فئة التذاكر والجنس والعمر وما إلى ذلك. و كذلك في مجموعة بيانات Iris علينا أن نتنبأ بنوع الزهرة بناءً على طول البتلة وطول السيبال وعرض البتلة.
قد تتضمن مجموعات البيانات غير الخاضعة للإشراف مجموعات بيانات لتقسيم العملاء. على سبيل المثال ، لديك بيانات للعملاء الذين يزورون موقع التجارة الإلكترونية الخاص بك أو بيانات العملاء الذين يزورون متجرًا أو مركزًا تجاريًا ، وتريد تقسيمهم أو تجميعهم في فئات مختلفة.
مثال آخر لمجموعات البيانات غير الخاضعة للإشراف قد يتضمن أشياء مثل اكتشاف الاحتيال ببطاقات الائتمان أو مجرد تجميع عدة صور.
في معظم الأوقات ، من الممكن أيضًا تحويل مجموعة بيانات خاضعة للإشراف إلى مجموعة بيانات غير خاضعة للإشراف لمعرفة كيف تبدو عند رسمها. على سبيل المثال ، دعنا نلقي نظرة على مجموعة البيانات في الصورة أدناه

توضح الصورة مجموعة بيانات MNIST وهي مجموعة بيانات شائعة جدًا من الأرقام المكتوبة بخط اليد ، وهي مشكلة خاضعة للإشراف حيث يتم إعطاؤك صور الأرقام والتسمية الصحيحة المرتبطة معهم. يجب عليك بناء نموذج يمكنه تحديد أي رقم هو عندما يتم توفيره مع الصورة فقط. يمكن تحويل مجموعة البيانات هذه بسهولة إلى مسأله غير خاضعه للإشراف من أجل تصورها .
لوقمنا بإستخدام تقنية التحلل (decomposition techniques) توزيع ت العشوائي للتضمين الجواري (t-distributed Stochastic Neighbour Embedding) أو بإختصار (t-SNE) في هذه البيانات فسنتمكن من تقسيم الصورة في هذه المجموعة إلى عشرة أقسام.

البرمجة
دعونا نلقي نظرة على كيفية القيام بذلك. أولاً وقبل كل شيء يتم استيراد جميع ملفات المكتبات المطلوبة
import matplotlib.pyplot as plt import numpy as np import pandas as pd import seaborn as sns from sklearn import datasets from sklearn import manifold %matplotlib inline
سنستخدم matplotlib و seaborn للتصور، و numpy للتعامل مع المصفوفات العددية ، و pandas لإنشاء إطارات البيانات من المصفوفات العددية و scikit-Learn (sklearn) للحصول على البيانات وتنفيذ t-SNE.
بعد عمليات الاستيراد ، نحتاج إما إلى تنزيل البيانات وقراءتها بشكل منفصل أو استخدام وظيفة sklearn المدمجة التي تزودنا بمجموعة بيانات MNIST.
data = datasets.fetch_openml(
'mnist_784',
version = 1,
return_X_y=True)
pixel_values, targets = data
targets = targets.astype(int)
في هذا الجزء من الكود ، قمنا بإحضار البيانات باستخدام مجموعات بيانات sklearn ، ولدينا مجموعة من قيم النقاط الضوئية (بكسل) ومجموعة أخرى من الأهداف. نظرًا لأن الأهداف من نوع السلسلة (string) ، فإننا نقوم بتحويلها إلى أعداد صحيحة.
pixel_values عبارة عن مصفوفة ثنائية الأبعاد حجمها 70000×784. يوجد 70000 صورة مختلفة حجم كل منها 28×28 بكسل. تسطيح 28×28 يعطي 784 نقطة بيانات.
يمكننا تصور العينات في مجموعة البيانات هذه عن طريق إعادة تشكيلها على شكلها الأصلي ثم رسمها باستخدام matplotlib.
single_image = pixel_values[100,:].reshape(28,28) plt.imshow(single_image, cmap='gray')
سيخرج الكود الصورة الأتية :

تأتي الخطوة الأكثر أهمية بعد أن نحصل على البيانات.
tsne = manifold.TSNE(n_components=2 , random_state=42) transformed_data = tsne.fit_transform(pixel_values[:3000,:])
هذه الخطوة تخلق تحويل t-SNE للبيانات. نحن نستخدم عنصرين فقط حيث يمكننا تصورهما جيدًا في بيئة ثنائية الأبعاد.
البيانات المحولة (transformed_data) ، في هذه الحالة ، عبارة عن مصفوفة من الشكل 3000 × 2 (3000 صف وعمودين).
يمكن تحويل مثل هذه البيانات إلى إطار بيانات الباندا عن طريق استدعاء pd.DataFrame على المصفوفة.
tsne_df = pd.DataFrame(
np.column_stack((transformed_data, targets[:3000])),
columns=["x","y", "targets"])
tsne_df.loc[:,"targets"] = tsne_df.targets.astype(int)
نحن هنا بصدد إنشاء إطار بيانات الباندا من مصفوفة عددية. هناك ثلاثة أعمدة : x و y و targets.
x و y هما المكونان من تحلل t-SNE و targets هي الرقم الفعلي. هذا يعطينا إطار بيانات يشبه الإطار الموضح أدناه.
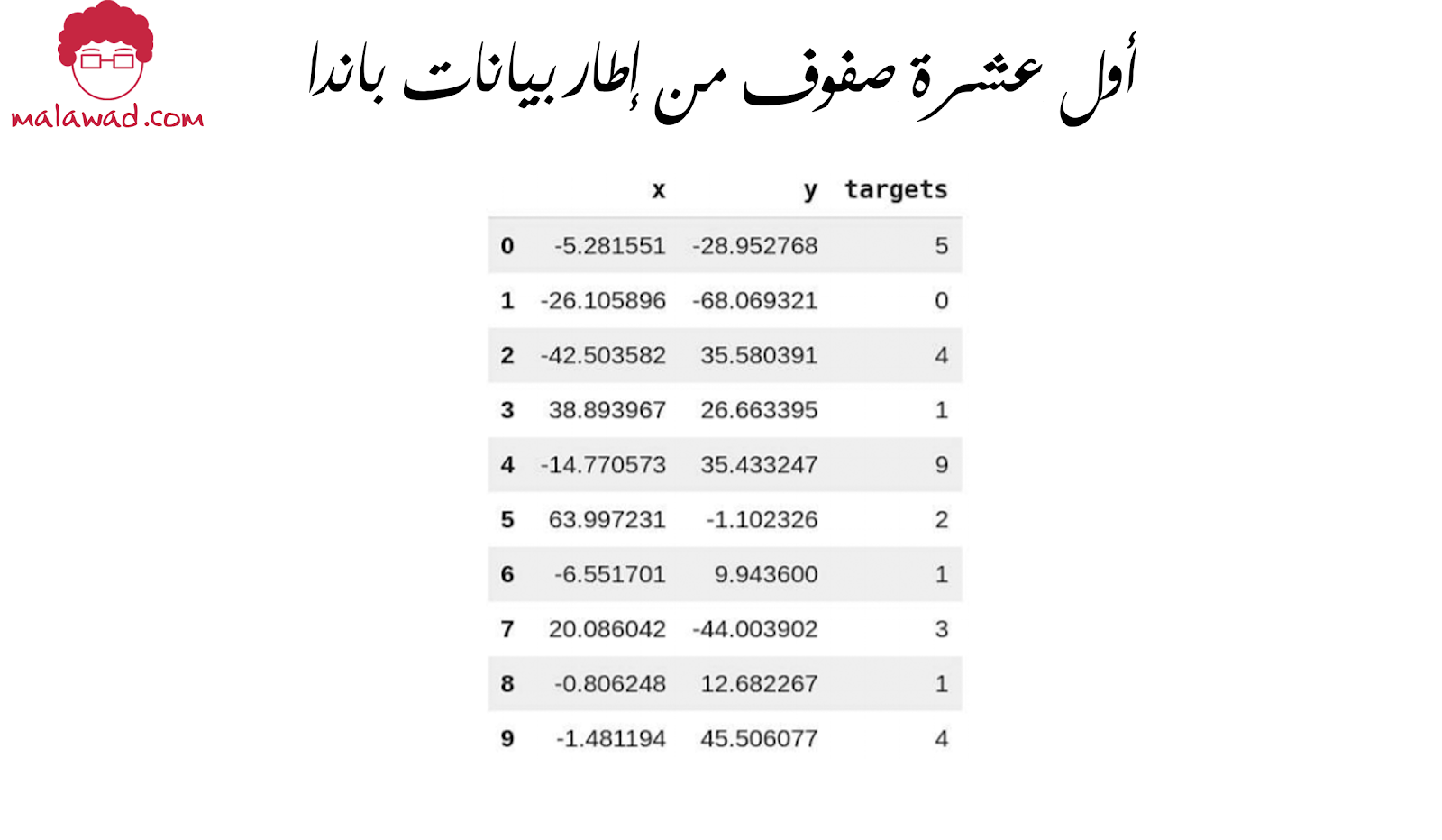
وأخيرًا ، يمكننا رسمه باستخدام seaborn و matplotlib.
grid = sns.FacetGrid(tsne_df, hue="targets", size=8) grid.map(plt.scatter, "x", "y").add_legend()
هذه طريقة واحدة لتصور مجموعات البيانات غير الخاضعة للإشراف. يمكننا أيضًا إجراء تجميع المتوسط كا (k-means clustering) على نفس مجموعة البيانات ومعرفة كيفية أدائها في بيئة غير خاضعة للإشراف. أحد الأسئلة التي تُطرح طوال الوقت هو كيفية العثور على العدد الأمثل للتجاميع (clusters) في تجميع المتوسط ك . حسنًا ، لا توجد إجابة صحيحة. عليك أن تجد الرقم عن طريق التحقق المتقاطع. تمت مناقشة التحقق المتقاطع (cross-validation) في المقال الثاني من السلسة.













إضافة تعليق