
على الرغم من أن شبكات الخصومة التوليدية شكلت نقلة نوعية في مجال النمذجة التوليدية ، فمن المعروف أيضًا أنها صعبة التدريب. لذلك في المقال السادس من سلسلة شبكات الخصومة التوليدية سوف نتعرف على بعض المشكلات الأكثر شيوعًا و التي نواجهها عند تدريها
تذبذب الخسارة (Oscillating Loss)
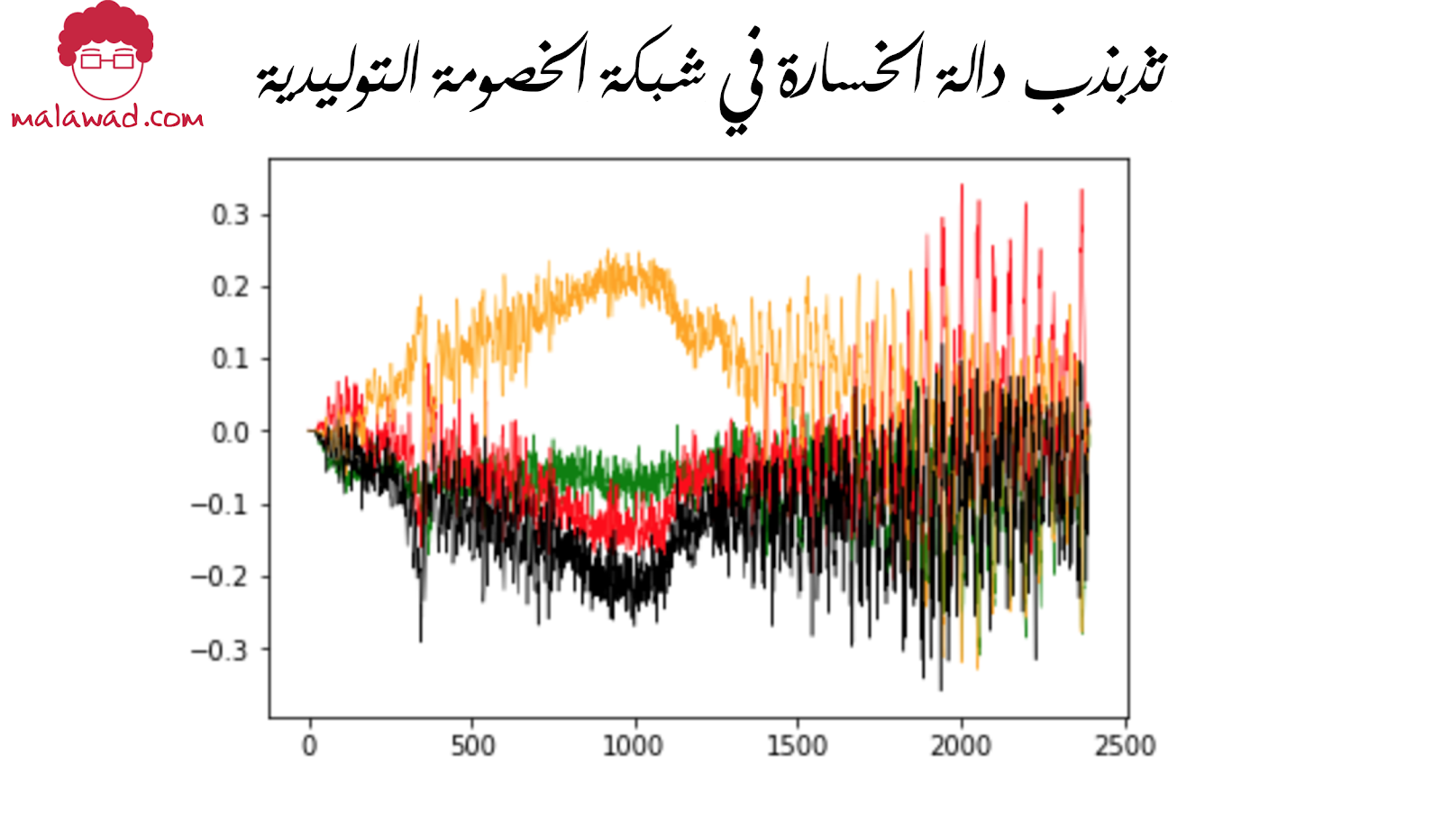
قد تبدأ خسارة المميز (Discriminator) والمولد (Generator) في التذبذب بشكل كبير ، بدلاً من الاستقرار على المدى الطويل أثناء التدريب. ففي العادةً ما يكون هناك بعض التذبذب الصغير للخسارة بين الحزم (batches)، ولكن على المدى الطويل ، يجب على الخسارة أن تستقر أو تزيد أو تنقص تدريجيًا كما شاهدنا في المقال السابق بدلاً من التقلب غير المنتظم ، لضمان تقارب (converges) شبكة الخصومة التوليدية و تحسنها مع الوقت .

توضح الصورة التالية مثالاً على GAN حيث بدأت خسارة المميز والمولد في الخروج عن نطاق السيطرة ، عند حوالي 1400 حزمة. من الصعب تحديد ما إذا كان هذا قد يحدث أو متى يمكن أن يحدث ذلك لأن شبكات الخصومة التوليدية التقليدية عرضة لهذا النوع من عدم الاستقرار.
انهيار الوضع (Mode Collapse)
يحدث انهيار الوضع عندما يعثر المولد على عدد صغير من العينات التي تخدع المميز ، وبالتالي لا يكون قادرًا على إنتاج أي أمثلة بخلاف هذه المجموعة المحدودة. دعونا نفكر في كيفية حدوث ذلك. لنفترض أننا قمنا بتدريب المولد على عدة حزم دون تحديث المميز بينهما. يميل المولد للعثور على ملاحظة واحدة (تُعرف أيضًا باسم الوضع) تخدع دائمًا المميز. وتبدأ في تعيين كل نقطة في فضاء الإدخال الكامن لهذه الملاحظة. هذا يعني أن مشتقة دالة الخسارة ستنهار إلى ما يقرب من 0. حتى إذا حاولنا بعد ذلك إعادة تدريب المميّز لإيقاف خداعه بهذه النقطة ، سيجد المولد ببساطة وضعًا آخر يخدع المميّز ، لأنه أصبح لا يتأثر بالمدخل وبالتالي ليس لديه حافز لتنويع مخرجاته.

خسارة غير مفيدة (Uninformative Loss)
نظرًا لأن نموذج التعلم العميق يتم تجميعه لتقليل دالة الخسارة إلى الحد الأدنى ، فسيكون من الطبيعي التفكير في أنه كلما كانت دالة الخسارة للمولد أصغر ، كانت جودة الصور المنتجة أفضل. ومع ذلك ، نظرًا لأن المولد يتم تصنيفه فقط مقابل المُميِّز الحالي والمميز يتحسن باستمرار ، فلا يمكننا مقارنة دالة الخسارة التي تم تقييمها في نقاط مختلفة في عملية التدريب.
في الواقع ، في الصورة أدناه ، تزداد دالة خسارة المولد بمرور الوقت ، على الرغم من تحسن جودة الصور بشكل واضح. يؤدي هذا النقص في الارتباط بين دالة خسارة المولد وجودة الصورة أحيانًا إلى صعوبة مراقبة تدريب GAN.
المعايير الرئيسية (Hyperparameter)
كما رأينا ، حتى مع شبكات GAN البسيطة ، هناك عدد كبير من المعايير الرئيسية التي يجب ضبطها. بالإضافة إلى المعمارية العامة لكل من المميز والمولد ، هناك المعايير التي تحكم تسوية الحزم (batch normalization) ، و الإسقاط (dropout)، ومعدل التعلم (learning rate) ، وطبقات التنشيط (activation layers) ، والمرشحات اللف الرياضي (convolutional filter) ، وحجم النواة (kernel size) ، و مقدار الخطوة (striding) ، وحجم الحزمة (batch size) ، وحجم الفضاء الكامن (latent space) الذي يجب مراعاته. و لذلك تعتبر شبكات الخصومة التوليدية حساسة للغاية للتغييرات الطفيفة جدًا في جميع هذه المعايير ، وغالبًا ما يكون العثور على مجموعة من المعلمات التي تعمل حالة من التجارب والخطأ المتعلمين ، بدلاً من اتباع مجموعة محددة من الإرشادات.
هذا هو السبب في أنه من المهم فهم الوظائف الداخلية لشبكات الخصومة التوليدية ومعرفة كيفية تفسير دالة الخسارة – حتى تتمكن من تحديد التعديلات المعقولة للمعايير الرئيسية التي قد تحسن استقرار النموذج.













إضافة تعليق