
في المقالة الأولى من سلسة شبكات الخصومة التوليدية أخذنا نظرة عامة عن النماذج التوليدية ، و في هذه المقالة سنتحدث عن النماذج التوليدية الإحتمالية
النماذج التوليدية الاحتمالية
كخطوة أولى ، سنحدد أربعة مصطلحات رئيسية: فضاء العينة (sample space) ، دالة الكثافة (density function) ، النمذجة المعييارية (parametric modeling)، وتقدير الاحتمالية الأقصى (maximum likelihood estimation).
فضاء العينة (sample space)
فضاء العينة هي المجموعة الكاملة لجميع القيم التي يمكن أن تأخذها الملاحظة x.
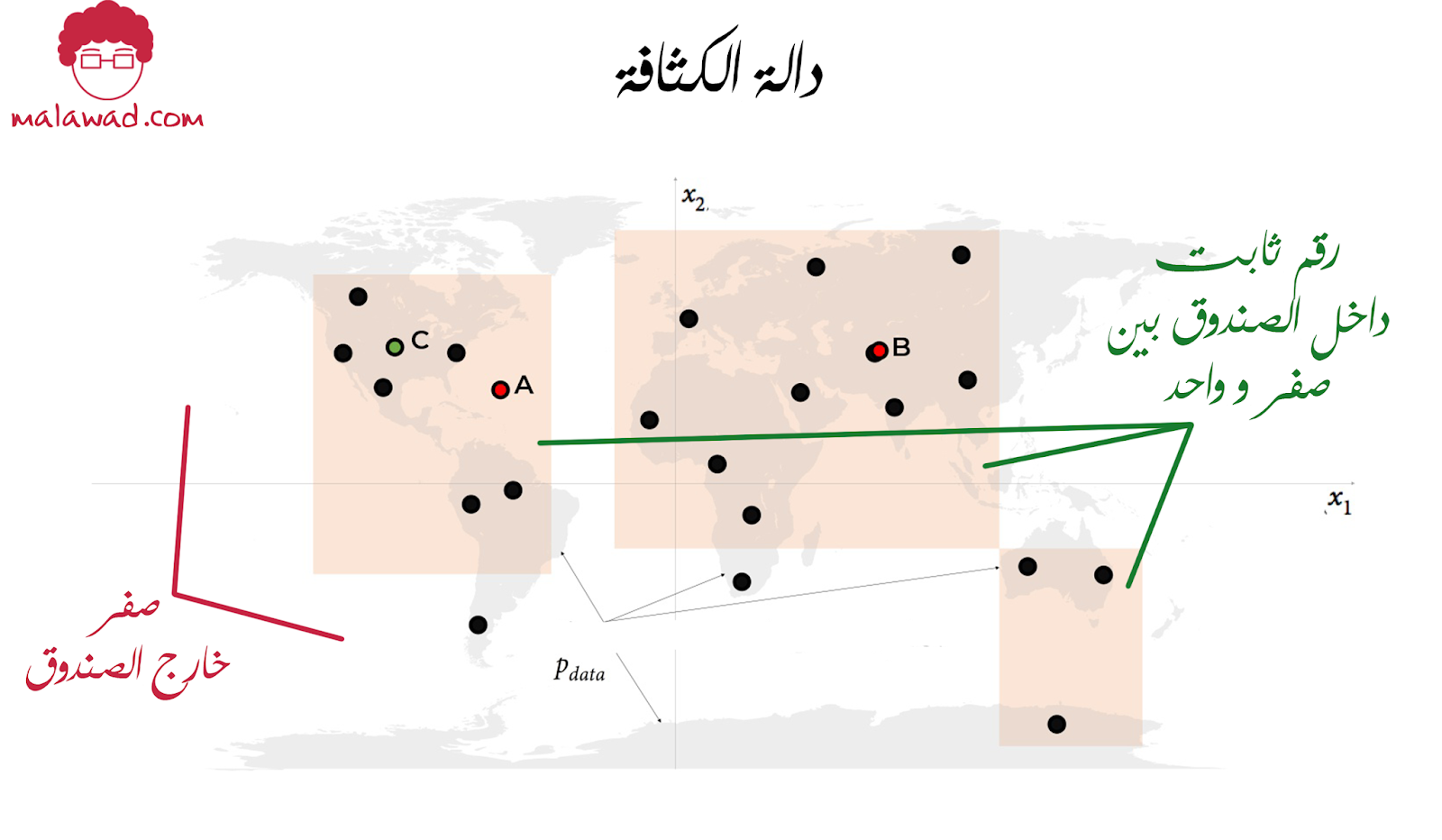
في الصورة التالية ، يتكون فضاء العينة من جميع نقاط خطوط الطول والعرض x=(x1,x2 على خريطة العالم.
على سبيل المثال ، x = (42.5117 ، 18.2465) هي نقطة في فضاء العينة تمثل مدينه في العالم.

دالة الكثافة الاحتمالية (Probability Density Function)
دالة الكثافة الاحتمالية (أو ببساطة دالة الكثافة) p(x) ، هي وظيفة تعيين النقطة x في فضاء العينة إلى رقم بين 0 و 1. يجب أن يكون مجموع دالة الكثافة على جميع النقاط في فضاء العينة يساوي 1 ، بحيث يكون توزيع احتمالي واضح المعالم
في مثال خريطة العالم ، تكون دالة الكثافة لنموذجنا هي 0 خارج المربع البرتقالي ورقم ثابت داخل الصندوق.
النمذجة المعاييرية (Parametric Modeling)
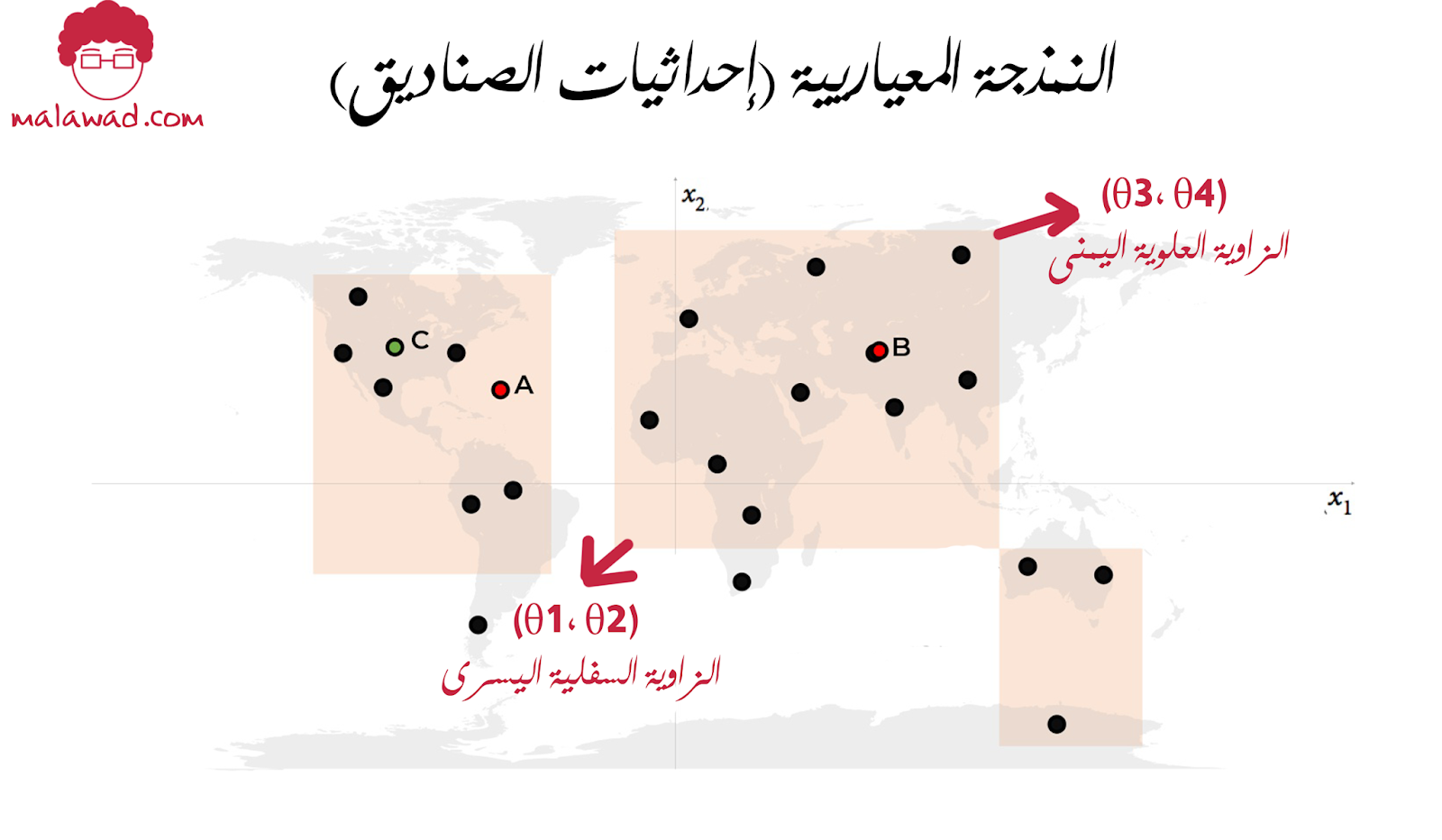
النموذج المعيياري ، pθ (x) ، هو مجموعة من دوال الكثافة التي يمكن وصفها باستخدام عدد محدود من المعايير θ.
تعد عائلة جميع المربعات الممكنة التي يمكنك رسمها في صورة خريطة العالم مثالًا على نموذج معيياري. في هذه الحالة ، هناك أربع معايير: إحداثيات الزوايا السفلية اليسرى (θ1 ، θ2) والزاوية العلوية اليمنى (θ3 ، θ4) للمربع.
وبالتالي ، يمكن تمثيل كل دالة كثافة pθ (x) في هذا النموذج المعيياري (أي كل مربع) بشكل فريد بأربعة أرقام ،
θ=(θ1,θ2,θ3,θ4)
الأرجحية (Likelihood)
الأرجحية L (θ∣x) لمجموعة المعايير θ هو دالة تقيس مدى معقولية θ ، بالنظر إلى بعض نقاط الملاحظات x. يتم تعريفه على النحو التالي:

أي أن احتمالية θ بالنظر إلى بعض النقاط المرصودة x تُعرَّف بأنها قيمة دالة الكثافة المحددة بواسطة θ عند النقطة x.
إذا كانت لدينا مجموعة بيانات X من الملاحظات المستقلة ، فيمكننا كتابة:

نظرًا لأن هذا المنتج قد يكون من الصعب جدًا التعامل معه من الناحية الحسابية ، فإننا غالبًا ما نستخدم لوغاريتم الأرجحية ℓ بدلاً من ذلك

هناك أسباب إحصائية لسبب تعريف الأرجحية بهذه الطريقة ، ولكن يكفي لنا أن نفهم لماذا هذا الأمر منطقي ، فمنطقيًا.نحن ببساطة نحدد أرجحية أن مجموعة من المعايير θ ستكون مساوية لاحتمال رؤية البيانات تحت النموذج المعيياري المحدد بواسطة θ.
في مثال خريطة العالم ، لو كان لدينا مربع برتقالي يغطي النصف الأعلة فقط من سيكون لديه أرجحية تساوي صفر، و ذلك لأنه من المستحيل أن يكون قد قام بتوليد النقاط الموجوده في النصف الأسفل من الخريطة … المربعات البرتقاليه في نموذجنا لها أرجحية إيجابية حيث أن دالة الكثافة موجبة لجميع نقاط البيانات تحت هذا النموذج.
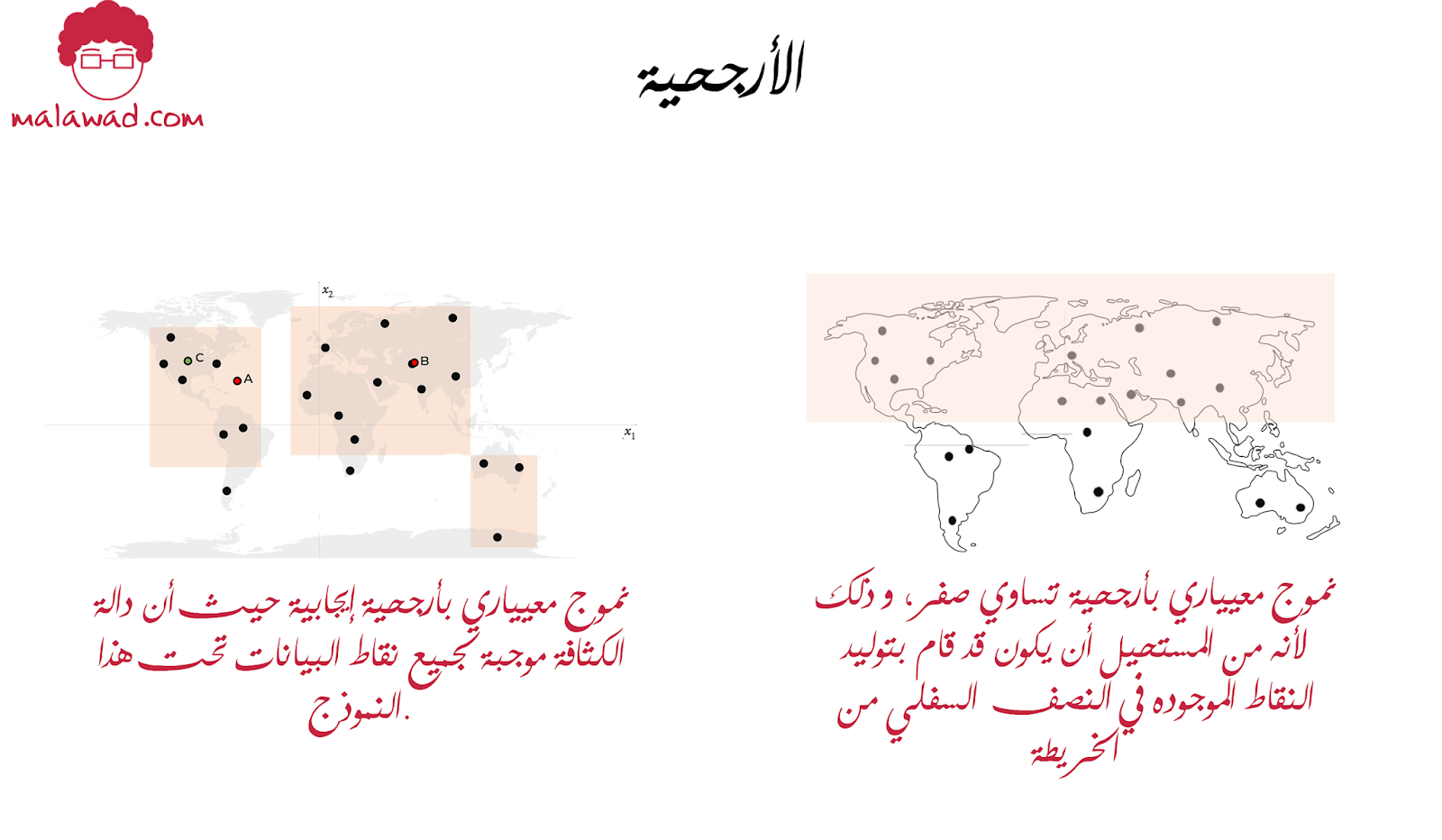
لذلك من المنطقي أن يكون تركيز النمذجة المعييارية هو العثور على القيمة المثلى θ^ لمجموعة المعايير التي تزيد من أرجحية مراقبة مجموعة البيانات X. وتسمى هذه التقنية تقدير الأرجحية العظمى (maximum likelihood estimation).
تقدير الأرجحية العظمى (maximum likelihood estimation).
هي التقنية التي تسمح لنا بتقدير θ^ (مجموعة المعايير θ لدالة الكثافة pθ (x) ) ، التي من المرجح أن تفسر بعض البيانات المرصودة X.
و بطريقة رسمية أكثر

ˆθ تسمى تقدير الأرجحية العظمى (MLE).
نموذجنا التوليدي الاحتمالي الأول :
كوكب 1 :
العام هو 2047 و تم تعيينك رئيسًا جديدًا للأزياء في أحد الكواكب في الفضاء البعيد المسمى رودز ، بصفتك المدير ، تقع على عاتقك وحدك مسؤولية إنشاء صيحات الموضة الجديدة والمثيرة لسكان الكوكب.
عند الوصول ، تم تقديم مجموعة بيانات تحتوي على 50 ملاحظة لأزياء سكان الكوكب وأُخبرت بأن لديك يوم لابتكار 10 أنماط جديدة لتقديمها إلى شرطة الموضة للفحص. يُسمح لك باللعب بتسريحات الشعر ولون الشعر والنظارات ونوع الملابس ولون الملابس لإنشاء أفضل أعمالك.

مجموعة البيانات
دعونا نلقي نظرة على مجموعة بيانات الأزياء. تحتوي على 50 ملاحظة (N=50) يمكن وصف كل ملاحظة من خلال خمس سمات (features) ، ( قصة الشعر ، لون الشعر ، نوع الملابس ، لون الملابس ، ونوع الإكسسورات) الجدول التالي يوضح أول عشرة ملاحظات من مجموعة بيانات.
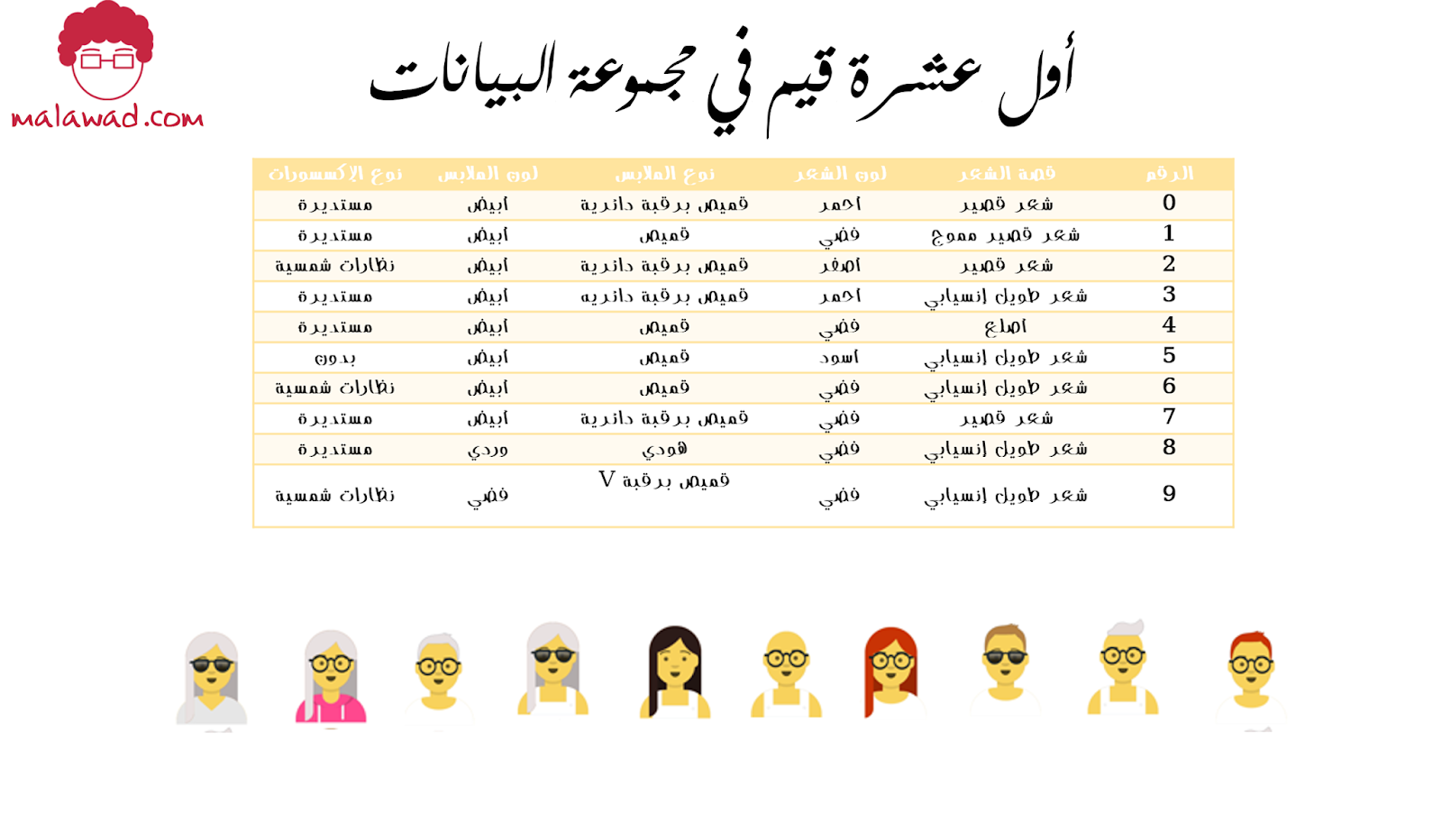
تتضمن القيم المحتملة لكل سمة ما يلي:
• 7 قصات شعر مختلفة (قصة الشعر):
أصلع ، شعر طويل ، شعر طويل مجعد ، شعر طويل إنسيابي ، شعر قصير، شعر قصير مموج ، شعر قصير إنسيابي
• 6 ألوان مختلفة للشعر (لون الشعر):
أسود ، أشقر ، بني ، باستيلبينك ، أحمر ، فضي
• 3 أنواع مختلفة من النظارات (نوع الإكسسوارت):
بدون ، مستديرة ، نظارة شمسية
• 4 أنواع مختلفة من الملابس (نوع الملابس):
هودي ، قميص عام ، قميص برقبة دائرية ، قميص برقبة V
• 8 ألوان ملابس مختلفة (لون الملابس):
أسود ، أزرق، رمادي ، أخضر، برتقالي ، وردي ، أحمر ، أبيض
هناك 7 × 6 × 3 × 4 × 8 = 4032 تركيبات مختلفة من هذه السمات ، لذلك هناك 4032 نقطة في فضاء العينة (sample space).
تكمن المشكلة في أننا لا نعرف توزيع البيانات pdata بشكل صريح — كل ما نملكه هو عينة من الملاحظات X التي تم إنشاؤها بواسطة pdata. الهدف من النمذجة التوليدية هو استخدام هذه الملاحظات لبناء نموذج يمكن أن يحاكي بدقة الملاحظات الناتجة من توزيع البيانات من pdata.
لتحقيق ذلك ، يمكننا ببساطة تعيين احتمال لكل تركيب ممكن من السمات ، بناءً على البيانات التي رأيناها سيحتوي هذا النموذج المعيياري 4031 معييار (D=4031) . معييار لكل نقطة في مساحة عينة الاحتمالات ، ناقصًا واحدًا لأنه سيتم فرض قيمة المعييار الأخير ليكون المجموع الإجمالي مساوي 1.
وبالتالي فإن نموذج المعايير الذي نحاول تقديره هو (θ1 ، … ، θ4301).
التوزيع متعدد الحدود (multinomial distribution)
يعرف هذا النوع من النماذج المعييارية بالتوزيع متعدد الحدود (multinomial distribution)، و تقدير الأرجحية العظمى ˆθ لكل معييار هو

حيث nj هو عدد المرات التي لوحظت فيها تركيب j في مجموعة البيانات و N = 50 هو العدد الإجمالي للملاحظات.
على سبيل المثال ، يظهر التركيب التالي (دعنا نطلق عليها المجموعة 1) مرتين في مجموعة البيانات:
( شعر طويل إنسيابي ، أحمر ، قميص برقبة دائرية ، أبيض ، مستديرة )
وبالتالي:
θ1=2/50=0.04^
يمكننا حساب جميع قيم ˆθj بهذه الطريقة ، من الممكن إعتبار قائمتنا بنموذج مولد . لكن هذا النموذج يفشل بشكل ذريع في نقطة معينة وهي القاعدة الثانية من إطار النمذجة التوليدية حيث:
لا يمكن لهذا النموذج أبدًا إنشاء أي شيء لم يره من قبل ، حيث أن θj = 0^ لأي تركيبة غير موجوده في مجموعة البيانات الأصلية X.

التنعيم التجميعي (additive smoothing)
ولمعالجة ذلك ، سنقوم بإضافة 1 لكل تركيب ممكن من السمات. يُعرف هذا بالتنعيم التجميعي (additive smoothing). و في هذا النموذج ستكون قيمة MLE لكل المعايير هي

ومع ذلك ، يظل هذا نموذجاُ توليداً غير مرضي ، لأن احتمال ملاحظة نقطة ليست في مجموعة البيانات الأصلية هو مجرد رقم ثابت.
و عوضا عن ذلك نرغب في أن يقوم النموذج التوليدي بإعطاء أوزان مختلفة للمناطق في فضاء العينة و الذي قد تعلم النموذج من خلال دراسته للتوزيع البيانات الأصلي أن إحتمال إنتماء هذه المنطقة قد يكون عالي لتحقيق ذلك ، نحتاج إلى اختيار نموذج معيياري مختلف.
نايف بايز (Naive Bayes)
يستخدم النموذج المعيياري نايف بايز Naive Bayes افتراضًا بسيطًا يقلل بشكل كبير من عدد المعايير التي نحتاج إلى تقديرها.
بحيث نفترض أن كل ميزة xj مستقلة عن أي ميزة أخرى xk
و بالنسبة لمجموعة بياناتنا ، نفترض أن اختيار لون الشعر ليس له تأثير على اختيار نوع الملابس ، ونوع النظارات التي يرتديها شخص ما ليس له تأثير على تصفيفة الشعر ، بالتالي لكل السمات xj و xk:

يُعرف هذا بافتراض نايف بايز ( Naive Bayes). لتطبيق هذا الافتراض ، نستخدم أولاً قاعدة السلسلة للإحتمالات (chain rule of probability) لكتابة دالة الكثافة كمنتج للاحتمالات الشرطية (conditional probabilities)

حيث K هو إجمالي عدد السمات (أي 5 ).
نطبق الآن افتراض نايف بايز Naive Bayes لتبسيط السطر الأخير:

هذا هو نموذج نايف بايز و أصبحت المشكلة مجرد تقدير المعايير

لكل سمة على حدة وضربها للعثور على احتمالية وجود أي تركيب ممكنة.
كم عدد المعايير التي نحتاج لتقديرها؟ لكل سمه ، نحتاج إلى تقدير معييار لكل قيمة يمكن أن تأخذها السمة . لذلك ، في مثالنا ، يتم تعريف هذا النموذج فقط من خلال 7 + 6 + 3 + 4 + 8-5 = 23 معييار
بالتالي يصبح تقدير الأرجحية العظمى كالأتي :

حيث ^θkl هو عدد المرات التي تأخذ فيها الميزة k القيمة l في مجموعة البيانات و N = 50 هي إجمالي عدد الملاحظات.
تقدير الأرجحية العظمى

لحساب احتمالية أن يولد النموذج بعض الملاحظة x ، نقوم ببساطة بضرب احتمالات السمات الفردية معًا. فمثلا:
= (شعر طويل أملس ، أحمر ، مستدير ، ، قميص برقبة دائرية ، أبيض)P
P(شعر طويل أملس) x P(أحمر) x P(مستدير) x P(قميص برقبة دائرية) x P(أبيض) =
= 0.46 × 0.16 × 0.44 × 0.38 × 0.44
= 0.0054
لاحظ أن هذه المجموعة لا تظهر في مجموعة البيانات الأصلية ، لكن نموذجنا ما زال يخصص لها احتمالية غير صفرية ، لذلك لا يزال من الممكن إنشاؤها. أيضا ، لديها احتمالية أعلى لأن يتم أخذ عينات منها ، على سبيل المثال ، ( شعر طويل أملس، أحمر ، دائري ، ، قميص برقبة دائرية ، أزرق) ، لأن الملابس البيضاء تظهر في كثير من الأحيان أكثر من الملابس الزرقاء في مجموعة البيانات.
لذلك ، فإن نموذج نايف بايز Naive Bayes قادر على تعلم من البيانات واستخدامها لإنشاء أمثلة جديدة لم يتم رؤيتها في مجموعة البيانات الأصلية.

و لهذ المثال البسيط ، فإن افتراض نايف بايز أن كل ميزة مستقلة عن كل ميزة أخرى هو معقول وبالتالي ينتج نموذجًا جيدًا للتوليد.
تحديات النمذجة التوليدية
كوكب 2
العام هو 2049 بعد النجاح الهائل الذي حققناه في كوكب 1 أنتشر صيتنا في أنحاء المجرة ، وطلب كوكب 2 مساعدتنا . المشكله هي انهم وفروا لنا مجموعة بيانات لا تتكون من السمات الخمس عالية المستوى التي رأيتها في الكوكب السابق ولكن بدلاً من ذلك تحتوي فقط على قيم 32 × 32 نقطة ضوئية و التي تشكل كل صورة.

وبالتالي فإن كل ملاحظة تحتوي الآن على 32 × 32 = 1024 عنصرًا ويمكن لكل سمه أن تأخذ أي قيمة لون من 1-265 وهي قيم الألوان لدينا و هنا لدينا قيم النقاط الضوئية 458 إلى 467 في الملاحضات العشرة الأولى
| face_id | px_458 | px_459 | px_460 | px_461 | px_462 | px_463 | px_464 | px_465 | px_466 | px_467 |
| 0 | 49 | 14 | 14 | 19 | 7 | 5 | 5 | 12 | 19 | 14 |
| 1 | 43 | 10 | 10 | 17 | 9 | 3 | 3 | 18 | 17 | 10 |
| 2 | 37 | 12 | 12 | 14 | 11 | 4 | 4 | 6 | 14 | 12 |
| 3 | 54 | 9 | 9 | 14 | 10 | 4 | 4 | 16 | 14 | 9 |
| 4 | 2 | 2 | 5 | 2 | 4 | 4 | 4 | 4 | 2 | 5 |
| 5 | 44 | 15 | 15 | 21 | 14 | 3 | 3 | 4 | 21 | 15 |
| 6 | 12 | 9 | 2 | 31 | 16 | 3 | 3 | 16 | 31 | 2 |
| 7 | 36 | 9 | 9 | 13 | 11 | 4 | 4 | 12 | 13 | 9 |
| 8 | 54 | 11 | 11 | 16 | 10 | 4 | 4 | 19 | 16 | 11 |
| 9 | 49 | 17 | 17 | 19 | 12 | 6 | 6 | 22 | 19 | 17 |
قررنا تجربة نموذج نايف بايز مرة أخرى ، هذه المرة تدرب على مجموعة بيانات النقاط الضوئية.
بدلاً من إنتاج أزياء جديدة ، ينتج النموذج 10 صور متشابهة جدًا لا تحتوي على إكسسوارات مميزة أو كتل واضحة من الشعر أو لون الملابس

تحديات النمذجة التوليدية
أولاً ، نظرًا لأن نموذج نايف بايز يقوم بأخذ عينات من وحدات النقاط الضوئية بشكل مستقل ، فلا توجد طريقة لمعرفة أن اثنين من وحدات النقاط الضوئية المتجاورة ربما تكون متشابهة تمامًا في اللون ، لأنها جزء من نفس عنصر الملابس ، على سبيل المثال. يمكن للنموذج أن يولد لون الوجه والفم ، لأن كل هذه النقاط الضوئية في مجموعة التدريب هي تقريبًا نفس اللون في كل ملاحظة ؛
ثانيًا ، هناك الآن عدد كبير جدًا من إحتمالات الملاحظات في فضاء العينة (sample space). و نسبة ضئيلة فقط يمكن تميزها كوجه، و نسبة أصغر من ذلك هي تلك لأوجه تلتزم بقوانين الموضه. لذلك ، إذا كان نموذج نايف بايز الخاص بنا يعمل مباشرة مع قيم النقاط الضوئية المترابطة ، فإن فرصة العثور على تركيب مرضية من القيم أقرب للمستحيلة.
يسلط هذا المثال الضوء على التحديين الرئيسيين اللذين يجب أن يتغلب عليهما النموذج التوليدي حتى يكون ناجحًا.
تحديات النمذجة التوليدية
• كيف يتعامل النموذج مع درجة عالية من العلاقة المترابطه بين السمات؟
• كيف يجد النموذج أحد النسب الضئيلة المحتمل توليدها من الملاحظات في مساحة عينة ذات أبعاد كبيره؟
التعلم العميق (Deep learning) هو مفتاح حل هذين التحديين.
نحتاج إلى نموذج يمكنه استنتاج أوجه الصلة من البيانات ، بدلاً من إخباره بالافتراضات التي يجب إجراؤها مقدمًا. هذا هو بالضبط ما يتفوق التعلم العميق فيه وهو أحد الأسباب الرئيسية وراء للتطورات الأخيرة في النمذجة التوليدية.
التعلم التصويري (Representation Learning)
الفكرة الأساسية وراء التعلم التمثيلي هي أنه بدلاً من محاولة نمذجة فضاء العينة عالية الأبعاد مباشرة سنقوم بوصف كل ملاحظة في مجموعة التدريب باستخدام الفضاء الكامن منخفض الأبعاد (low-dimensional latent space) ثم تعلم دالة ربط (mapping function) يمكن أن تأخذ نقطة في الفضاء الكامن و وصلها بنقطة في المجال الأصلي. بمعنى آخر ، كل نقطة في الفضاء الكامن هي لبعد عالي في الصورة

ماذا يعني هذا ؟ لنفترض أن لدينا مجموعة تدريب تتكون من صور رمادية لعلب البسكويت
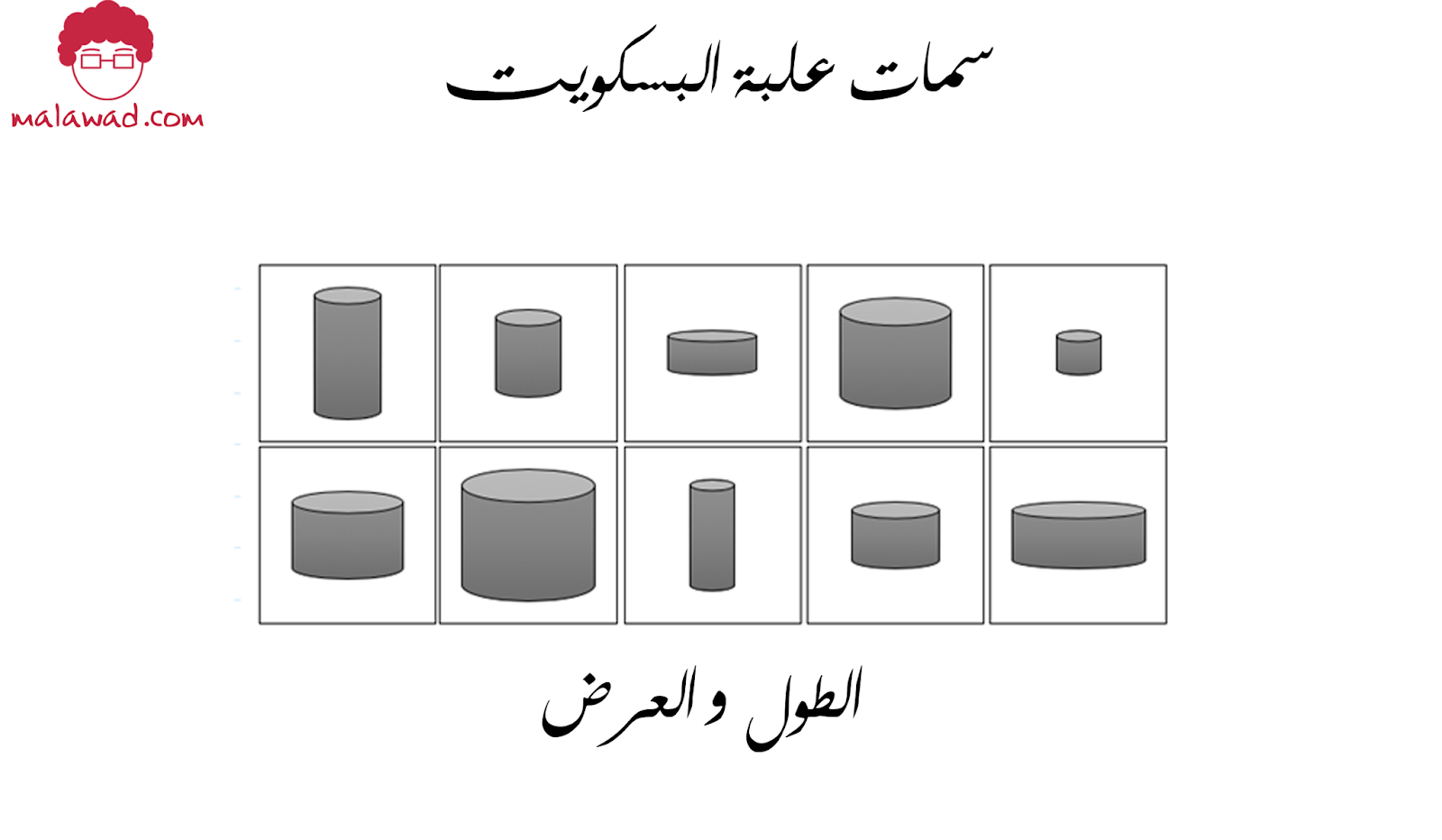
بالنسبة لنا ، من الواضح أن هناك سمتين يمكن أن تمثل كل من هذه العلب بشكل فريد: إرتفاع و عرض العلبه. بالنظر إلى الارتفاع والعرض ، يمكننا رسم أي علبه ، حتى لو لم تكن صورته في مجموعة التدريب.
ومع ذلك ، فإن هذا ليس سهلاً بالنسبة إلى الحواسيب – فقد تحتاج أولاً إلى إثبات أن الارتفاع والعرض هما بعدين في الفضاء الكامن اللذان يصفان مجموعة البيانات ، ثم تعلم دالة التعيين f ، التي يمكن أن تأخذ نقطة في هذا الفضاء و رسمها على صورة رمادية لعلبة بسكويت.
مزايا استخدام التعلم التصويري
تتمثل إحدى مزايا استخدام التعلم التصويري في أنه يمكننا إجراء عمليات ضمن الفضاء الكامن الأكثر قابلية للإدارة والذي يؤثر على الخصائص عالية المستوى للصورة. ليس من البديهي معرفة كيفية تظليل نقطة ضوئية لجعل صورة علبة البسكويت أطول. ومع ذلك ، في المساحة الكامنة ، كل ما عينا فعله هو إضافة 1 إلى البعد الكامن للارتفاع ، ثم تطبيق دالة التعيين للعودة إلى نطاق الصورة.

بالنسبة لنا كبشر التعلم التمثيلي أمر طبيعي جدًا فربما لم تتوقف لتتفكر أبدا في مدى روعته و كيف يمكننا القيام بها دون عناء. لنفترض أنك أردت وصف مظهرك لشخص كان يبحث عنك في حشد من الناس ولم يكن يعرف كيف تبدو. لن تبدأ بقول لون النقطة الضوئية 1 من شعرك ، ثم النقطة الضوئية 2 ، ثم النقطة الضوئية 3 ، وما إلى ذلك. بدلاً من ذلك ، ستفترض أن الشخص الآخر لديه فكرة عامة عن شكل الإنسان العادي ، ثم سنقوم بوصف مجموعة من النقاط الضوئية ، مثل شعري الأشقر أو ارتدي نظارات.
وفي حدود 10 أو أقل من هذه العبارات ، سيكون الشخص قادرًا تحويل هذا الوصف إلى نقاط ضوئيه و توليد صورة لك في رأسه
إن قوة التعلم التصويري هي أننا نتعلم السمات الأكثر أهمية بالنسبة لنا لوصف ملاحظات معينة وكيفية توليد هذه السمات من البيانات الأولية. من الناحية الرياضية ، تحاول العثور على الطريق غير الخطي الذي تستند إليه البيانات ثم تحدد الأبعاد المطلوبة لوصف هذه المساحة بشكل كامل..
باختصار ، يُنشئ التعلم التصويري أهم السمات عالية المستوى التي تصف كيفية عرض مجموعات وحدات النقاط الضوئية بحيث من المحتمل أن تكون أي نقطة في الفضاء الكامن هي تمثيل صورة جيدة التكوين




إضافة تعليق