
توليد الموسيقى ، لكي تؤلف الآلة الموسيقى التي ترضي آذاننا ، يجب أن تتقن العديد من التحديات التقنية نفسها التي رأيناها في المقالين السابقين سلسة شبكات الخصومة التوليدية (هنا و هنا ) فيما يتعلق بالنص.
على وجه الخصوص ، يجب أن يكون نموذجنا قادرًا على التعلم من الهيكل التسلسلي للموسيقى وإعادة إنشائه ، كما يجب أن يكون قادرًا على الاختيار من بين مجموعة منفصلة من الاحتمالات للملاحظات اللاحقة.
ومع ذلك ، فإن توليد الموسيقي يمثل تحديات إضافية غير مطلوبة لتوليد النص ، وهي النغمة والإيقاع. غالبًا ما تكون الموسيقى متعددة الأصوات – أي أن هناك عدة تدفقات من النوتات يتم عزفها في وقت واحد على آلات مختلفة ، والتي تتحد لتكوين تناغمات إما متنافرة (متضاربة) أو إنسيابية (متناغمة). يتطلب إنشاء النص منا فقط التعامل مع تدفق واحد من النص ، بدلاً من التدفقات المتوازية للأوتار الموجودة في الموسيقى.
الأساسيات
يجب أن يكون لدى أي شخص يتولى مهمة توليد الموسيقى أولاً فهم أساسي للنظرية الموسيقية. في هذا القسم سنتناول التدوينات الأساسي المطلوب لقراءة الموسيقى وكيف يمكننا تمثيل ذلك رقميًا ، من أجل تحويل الموسيقى إلى بيانات الإدخال المطلوبة لتدريب نموذج توليدي.
أحد المصارد الرائعة لتعلم توليد الموسيقى هي هذه المدونه
مجموعة البيانات الأولية التي سنستخدمها هي مجموعة من ملفات MIDI. يمكنك استخدام أي مجموعة بيانات ترغب فيها . (في النوته في طريقة التحميل )
لعرض الموسيقى التي تم إنشاؤها بواسطة النموذج والاستماع إليها ، ستحتاج إلى بعض البرامج التي يمكنها إنتاج تدوينات موسيقية. MuseScore هي أداة رائعة لهذا الغرض ويمكن تنزيلها مجانًا.
تدوين الموسيقى
سنستخدم مكتبة Python Library music21 لتحميل ملفات MIDI في Python للمعالجة.
from music21 import converter
dataset_name = 'cello'
filename = 'cs1-2all'
file = "./data/{}/{}.mid".format(dataset_name, filename)
original_score = converter.parse(file).chordify()

نحن نستخدم طريقة chordify َلضغط جميع النغمات التي يتم عزفها في وقت واحد إلى أوتار داخل جزء واحد ، بدلاً من تقسيمها بين عدة أجزاء. نظرًا لأن هذه القطعة يتم عزفها بواسطة آلة واحدة (آلة التشيلو) ، فإننا مبررون للقيام بذلك ، على الرغم من أننا قد نرغب أحيانًا في فصل الأجزاء لتوليد موسيقى ذات طبيعة متعددة الألحان.
لبرمجة هذا سنقوم بإنشاء حلقة تمر من خلال كل المعزوفة و تستخرج النغمة والمدة لكل نوته و تضعها في قائمتين . يتم فصل النغمات الفردية في الأوتار بنقطة ، بحيث يمكن تخزين الوتر بأكمله كسلسلة واحدة. يشير الرقم الموجود بعد كل اسم ملاحظة إلى الجواب الموسيقي (octave) الذي توجد به الملاحظة — بما أن أسماء الملاحظات (من A إلى G) تتكرر ، فهذا ضروري لتحديد نغمة كل نوته بشكل فريد.
notes = []
durations = []
for element in original_score.flat:
if isinstance(element, chord.Chord):
notes.append('.'.join(n.nameWithOctave for n in element.pitches))
durations.append(element.duration.quarterLength)
if isinstance(element, note.Note):
if element.isRest:
notes.append(str(element.name))
durations.append(element.duration.quarterLength)
else:
notes.append(str(element.nameWithOctave))
durations.append(element.duration.quarterLength)
الجدول التالي يوضح مخرج هذه العملية

تبدو مجموعة البيانات الناتجة الآن أشبه كثيرًا بالبيانات النصية التي تعاملنا معها في المقالات السابقة. الكلمات هي النغمات ، ويجب أن نحاول بناء نموذج يتنبأ بالنغمة التالية ، مع الأخذ في الاعتبار سلسلة من النغمات السابقة. يمكن أيضًا تطبيق الفكرة نفسها على قائمة المدة . يمنحنا Keras المرونة لنكون قادرين على بناء نموذج يمكنه التعامل مع توقع النغمة والمدة في وقت واحد.
توليد الموسيقى بإستخدام الشبكات العصبية المتكررة
لإنشاء مجموعة البيانات التي ستقوم بتدريب النموذج ، نحتاج أولاً إلى إعطاء قيمة عدد صحيح لكل نغمة ومدتها ، تمامًا كما فعلنا سابقًا لكل كلمة في مجموعة نصية. لا يهم ماهية هذه القيم حيث سنستخدم طبقة التضمين لتحويل قيم البحث عن الأعداد الصحيحة إلى متجهات.

نقوم بعد ذلك بإنشاء مجموعة التدريب عن طريق تقسيم البيانات إلى أجزاء صغيرة من 32 ملاحظة ، مع متغير استجابة للملاحظة التالية في التسلسل تم تحويله إلى خط الترميز الأحادي (one-hot encoded) ، لكل من النغمة والمدة.

النموذج الذي سنقوم ببنائه هو شبكة LSTM مكدسة مع آلية انتباه. في المقال السابق ، رأينا كيف يمكننا تكديس طبقات LSTM عن طريق تمرير الحالات المخفية للطبقة السابقة كمدخلات إلى طبقة LSTM التالية. يمنح تكديس الطبقات بهذه الطريقة حرية النموذج في تعلم المزيد من السمات المعقدة من البيانات. في الجزئية القادمة سنتحدث عن آلية الانتباه (attention mechanism) التي تشكل الآن جزءًا لا يتجزأ من أكثر النماذج التوليدية التسلسلية تطوراً. و التي أدى تطورها لظهور المتحول (the transformer) ، وهو نوع من النماذج يعتمد كليًا على الانتباه الذي لا يتطلب حتى طبقات متكررة أو تلافيفية.
في الوقت الحالي ، دعنا نركز على دمج الانتباه في شبكة LSTM المكدسة لمحاولة التنبؤ بالملاحظة التالية ، في ضوء سلسلة من الملاحظات السابقة.
انتباه (Attention)
تم تطبيق آلية الانتباه في الأصل على مشاكل ترجمة النص – وعلى وجه الخصوص ، ترجمة الجمل الإنجليزية إلى الفرنسية.
رأينا كيف يمكن لشبكات الترميز – فك الترميز أن تحل هذا النوع من المشاكل ، عن طريق تمرير تسلسل المدخلات أولاً من خلال شبكة المشفر لإنشاء متجه سياق (context vector) ، ثم تمرير هذا المتجه عبر شبكة مفكك لإخراج النص المترجم. إحدى المشكلات التي لوحظت في هذا النهج هي أن متجه السياق يمكن أن تصيبها مشكلة عنق الزجاجة (bottleneck) .
بحيث يمكن أن تصبح المعلومات في بداية جملة المصدر مخففة بحلول الوقت الذي تصل فيه إلى متجه السياق ، خاصة للجمل الطويلة. لذلك ، تعاني هذه الأنواع من شبكات الترميز – فك الترميز أحيانًا للاحتفاظ بجميع المعلومات التي يطلبها المفكك لترجمة المصدر بدقة.
كمثال ، لنفترض أننا نريد من النموذج أن يترجم الجملة التالية إلى الألمانية: لقد سجلت ركلة جزاء في مباراة كرة القدم ضد إنجلترا (I scored a penalty in the football match against England.) .
من الواضح أن معنى الجملة بأكملها سوف يتغير عن طريق استبدال الكلمة سُجلت بكلمة أضعت.
ومع ذلك ، قد لا تتمكن الحالة المخفية النهائية للمشفر من الاحتفاظ بهذه المعلومات بشكل كافٍ ، حيث تظهر الكلمة “سجلت ” في وقت مبكر من الجملة.
الترجمة الصحيحة للجملة هي: Ich habe im Fußballspiel gegen England einen Elfmeter erzielt.
إذا نظرنا إلى الترجمة الألمانية الصحيحة ، يمكننا أن نرى أن كلمة (erzielt) تظهر بالفعل في نهاية الجملة! لذلك لن يضطر النموذج بأن يحتفظ فقط بحقيقة أن ركلة الجزاء قد تم تسجيلها بدلاً من إضاعتها خلال مرور الجملة في المشفر ، ولكن أيضًا خلال مرورها في المفكك.
نفس المبدأ صحيح في الموسيقى. لفهم ما هي النوتة الموسيقية أو تسلسل النوتات التي من المحتمل أن تتبع من فقرة معينة من الموسيقى ، قد يكون من الضروري استخدام المعلومات من بداية التسلسل ، وليس فقط أحدث المعلومات. على سبيل المثال ، خذ المقطع الافتتاحي منPrelude to Bach’s Cello Suite No. 1

ما النوته التي تعتقد أنها تأتي بعد ذلك؟ حتى لو لم يكن لديك معرفة بالموسيقى ، فقد تظل قادرًا على التخمين. إذا قلت G (نفس الملاحظة الأولى في القطعة) ، فأنت على صواب. كيف عرفت هذا؟ لأن نفس النوتتين تتكررا بشكل دوري.
نريد أن يكون نموذجنا قادرًا على أداء نفس الحيلة – على وجه الخصوص ، لا نريده أن يهتم فقط بالحالة المخفية للشبكة في الوقت الراهن ، ولكن أيضًا أن يولي اهتمامًا خاصًا للحالة المخفية للشبكة قبل ثماني نوتات .
تم اقتراح آلية الانتباه لحل هذه المشكلة. بدلاً من استخدام الحالة المخفية النهائية لـ RNN للتشفير فقط كمتجه للسياق (context vector) ، تسمح آلية الانتباه للنموذج بإنشاء متجه السياق كمجموع مرجح للحالات المخفية للمشفر RNN في كل خطوة زمنية سابقة. آلية الانتباه هي مجرد مجموعة من الطبقات التي تحول الحالات المخفية السابقة للمشفر والحالة المخفية الحالية للمفكك إلى أوزان مجموعة التي تولد متجه السياق.
إذا كان هذا يبدو محيرا ، فلا تقلق! سنبدأ برؤية كيفية تطبيق آلية الانتباه بعد طبقة متكررة بسيطة ، و من ثم سننتقل إلى تطبيقها على شبكات الترميز- فك الترميز حيث نريد التنبؤ بسلسلة كاملة من النغمات اللاحقة ، بدلاً من واحدة فقط.
بناء آلية الانتباه في كيراس
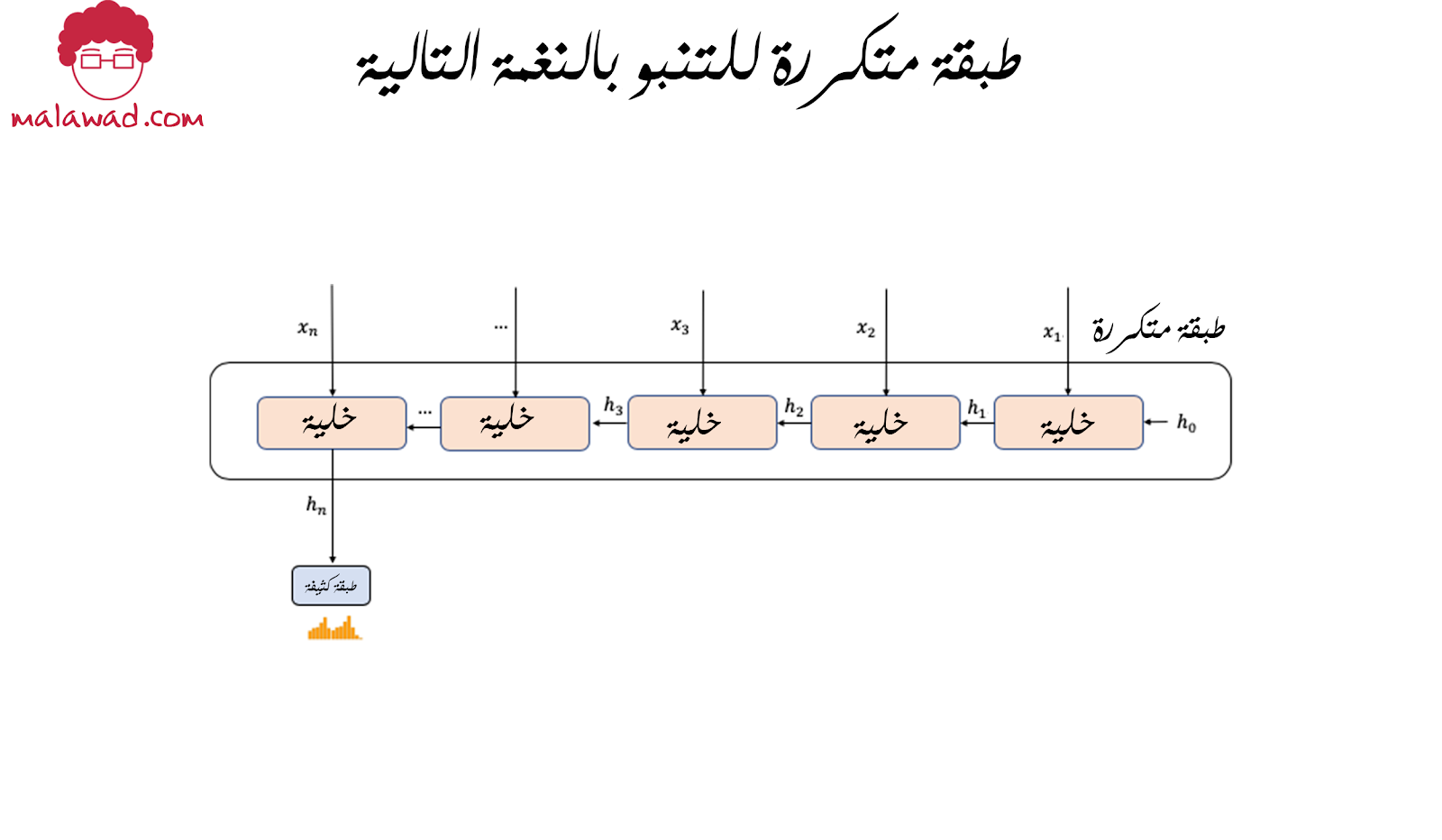
أولاً ، دعنا نذكر أنفسنا بكيفية استخدام طبقة متكررة (recurrent layer) قياسية للتنبؤ بالنغمة التالية لو تم إدخال سلسلة من النغمات عليها .توضح الصورة كيفية تغذية تسلسل المدخلات (x1 ، … ، xn) إلى الطبقة خطوة واحدة في كل مرة ، مع تحديث الحالة المخفية للطبقة باستمرار.
يمكن أن يكون تسلسل الإدخال هو تضمينات النغمة (note embeddings) ، أو تسلسل الحالة المخفية من طبقة متكررة سابقة. الناتج من الطبقة المتكررة هو الحالة المخفية النهائية ، متجه بنفس طول عدد الوحدات. يمكن بعد ذلك تغذية طبقة كثيفة بإخراج سوفت ماكس (softmax) للتنبؤ بتوزيع النغمة التالية في التسلسل.
و الأن نفس الطبقة مع ألية الإنتباه مطبقة على الحالات الخفية للطبقة المكررة (recurrent layer)
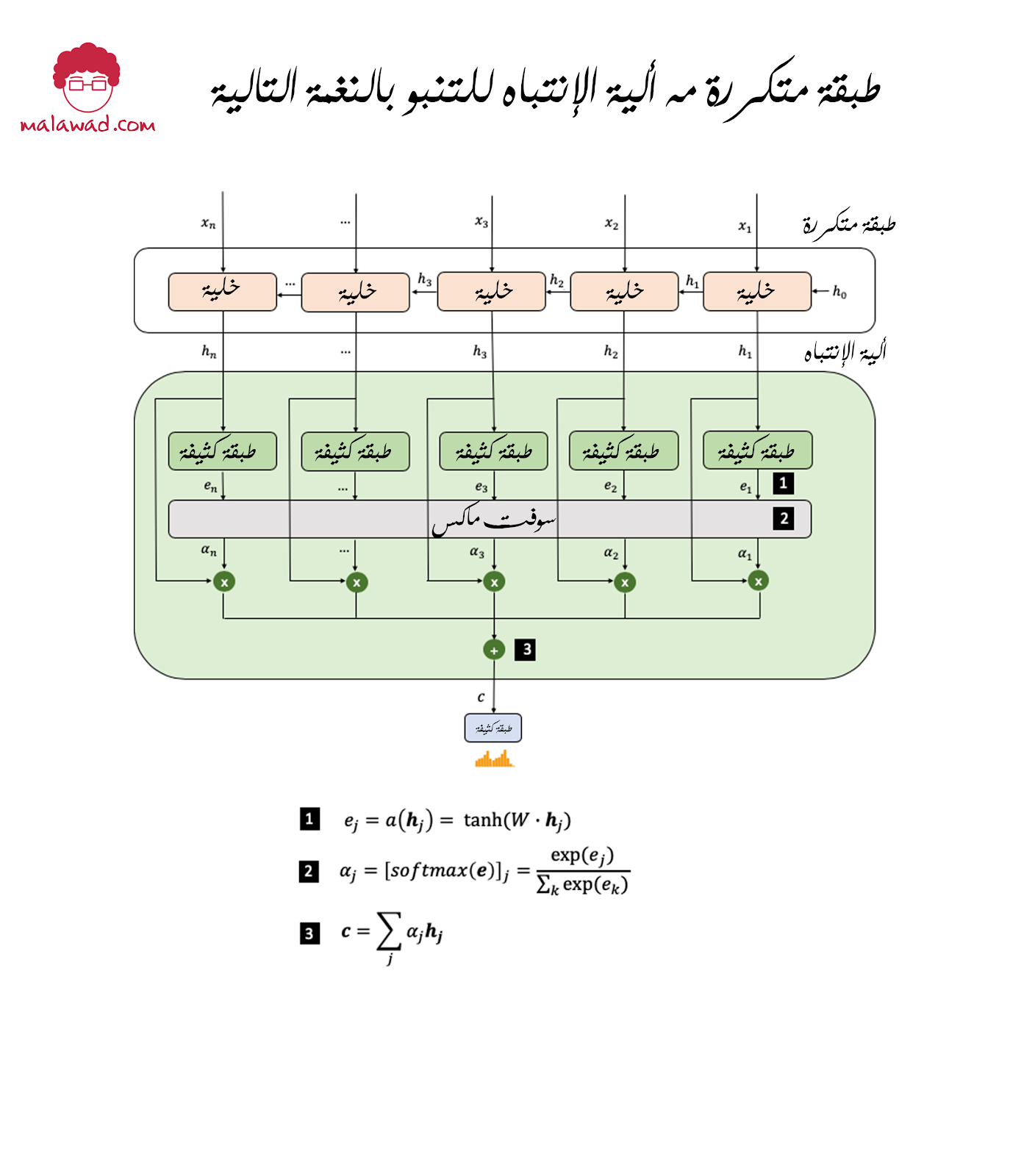
دعنا نتحرى هذه العملية خطوة بخطوة:
- أولاً ، يتم تمرير كل حالة مخفية hj (متجه طولها يساوي عدد الوحدات في الطبقة المتكررة) من خلال دالة المحاذاة (alignment function) يرمز لها a لإنشاء عدد قياسي (scalar) يرمز له ej . في هذا المثال ، هذه الدالة هي ببساطة طبقة متصلة بكثافة مع وحدة إخراج واحدة ووظيفة تنشيط ظل الجيب tanh .
- ثانياً ، يتم تطبيق دالة softmax على المتجه e1،…، en لإنتاج متجه الأوزان α1،…، αn.
- أخيرًا ، يتم ضرب كل متجه حالة مخفية hj بوزنه الخاص αj ، ثم يتم جمع النتائج لإعطاء متجه السياق c (وبالتالي يكون c له نفس طول متجه الحالة المخفية).
يمكن بعد ذلك تمرير متجه السياق إلى طبقة كثيفة بإخراج softmax كالمعتاد ، لإخراج توزيع النغمة التالية المحتملة.
يمكن بناء هذه الشبكة في Keras كما هو موضح في
notes_in = Input(shape = (None,)) #1
durations_in = Input(shape = (None,))
x1 = Embedding(n_notes, embed_size)(notes_in) #2
x2 = Embedding(n_durations, embed_size)(durations_in)
x = Concatenate()([x1,x2]) #3
x = LSTM(rnn_units, return_sequences=True)(x) #4
x = LSTM(rnn_units, return_sequences=True)(x)
e = Dense(1, activation='tanh')(x) #5
e = Reshape([-1])(e)
alpha = Activation('softmax')(e) #6
c = Permute([2, 1])(RepeatVector(rnn_units)(alpha)) #7
c = Multiply()([x, c])
c = Lambda(lambda xin: K.sum(xin, axis=1), output_shape=(rnn_units,))(c)
notes_out = Dense(n_notes, activation = 'softmax', name = 'pitch')(c) #8
durations_out = Dense(n_durations, activation = 'softmax', name = 'duration')(c)
model = Model([notes_in, durations_in], [notes_out, durations_out]) #9
att_model = Model([notes_in, durations_in], alpha) #10
opti = RMSprop(lr = 0.001)
model.compile(loss=['categorical_crossentropy', 'categorical_crossentropy'],
optimizer=opti) #11
1- هناك نوعان من المدخلات للشبكة: تسلسل أسماء الملاحظات السابقة وقيم المدة. لاحظ كيف لم يتم تحديد طول التسلسل – لا تتطلب آلية الانتباه مدخل بطول ثابت ، لذلك يمكننا ترك هذا كمتغير.
2- تقوم طبقات التضمين بتحويل القيم الصحيحة لأسماء الملاحظات و المدة إلى متجهات.
3- يتم ربط المتجهات لتشكيل متجه طويل واحد سيتم استخدامه كمدخل في الطبقات المتكررة.
4- يتم استخدام طبقتين LSTM مكدستين كجزء متكرر من الشبكة. لاحظ كيف قمنا بتعيين return_sequences إلى True لجعل كل طبقة تمرر التسلسل الكامل للحالات المخفية إلى الطبقة التالية ، بدلاً من مجرد الحالة المخفية النهائية.
5- دالة المحاذاة (alignment function) هي مجرد طبقة كثيفة مع وحدة إخراج واحدة و دالة تنشيط الظل الزائدي (tanh activation). يمكننا استخدام طبقة Reshape لسحق الإخراج إلى متجه واحد بطول يساوي طول تسلسل الإدخال (seq_length).
6- يتم حساب الأوزان من خلال تطبيق دالة تنشيط softmax على قيم المحاذاة.
7- للحصول على المجموع الموزون للحالات المخفية ، نحتاج إلى استخدام طبقة RepeatVector لنسخ الأوزان rnn_units مرات لتشكيل مصفوفة من الشكل [rnn_units ، seq_length] ، ثم تبديل هذه المصفوفة باستخدام طبقة Permute للحصول على مصفوفة من الشكل [ seq_length ، rnn_units]. يمكننا بعد ذلك ضرب هذه المصفوفة بشكل نقطي مع الحالات المخفية من طبقة LSTM النهائية ، والتي لها أيضًا الشكل [seq_length ، rnn_units]. أخيرًا ، نستخدم طبقة Lambda لإجراء الجمع على طول محور seq_length ، لإعطاء متجه السياق لطول rnn_units.
8- تحتوي الشبكة على إخراج مزدوج الرأس (double-headed output) ، أحدهما لاسم الملاحظة التالية والآخر لطول الملاحظة التالي.
9- يقبل النموذج النهائي أسماء الملاحظات السابقة و مدتها كمدخلات ومخرجات توزيع لاسم الملاحظة التالية ومدة الملاحظة التالية.
10- نقوم أيضًا بإنشاء نموذج يُخرج متجه طبقة ألفا ، حتى نتمكن من فهم كيفية إسناد الشبكة للأوزان إلى الحالات المخفية السابقة.
11- يتم تجميع النموذج باستخدام categorical_crossentropy لكل من اسم الملاحظة ورؤوس إخراج مدة الملاحظة ، حيث إنها مشكلة تصنيف متعددة الفئات.
يظهر الرسم تخطيطي للنموذج الكامل المدمج في Keras

تحليل نموذج RNN مع ألية الاهتمام
سنبدأ بتوليد بعض الموسيقى من البداية ، عن طريق تغذية الشبكة بتسلسل من العملة <START> فقط (على سبيل المثال ، نخبر النموذج بأن يفترض أنه يبدأ من بداية القطعة). ثم يمكننا إنشاء مقطع موسيقي باستخدام نفس التقنية التكرارية التي استخدمناها في المقالة الثانية عشر من سلسلة شبكات الخصومة التوليدية لإنشاء تسلسلات نصية ، على النحو التالي:
1- بالنظر إلى التسلسل الحالي (لأسماء الملاحظات ومدتها) ، يتوقع النموذج توزيعين ، لاسم الملاحظة التالية ومدتها.
2- نقوم بأخذ عينات من كلا التوزيعين ، باستخدام معييار الحرارة (temperature) للتحكم في مقدار التباين الذي نرغب فيه في عملية أخذ العينات.
3- يتم تخزين الملاحظة المختارة وإلحاق اسمها ومدتها بالتسلسلات المعنية.
4-إذا كان طول التسلسل الآن أكبر من طول التسلسل الذي تم تدريب النموذج عليه ، فإننا نزيل عنصرًا واحدًا من بداية التسلسل.
5-تتكرر العملية مع التسلسل الجديد ، وهكذا ، لعدد الملاحظات التي نرغب في إنشائها.
توضح الصورة التالية أمثلة على الموسيقى التي تم إنشاؤها من الصفر بواسطة النموذج في فترات مختلفة من عملية التدريب.
ستركز معظم تحليلاتنا على تنبؤات نغمة الملاحظة ، بدلاً من الإيقاعات ، كما هو الحال بالنسبة إلى موسيقى Bach’s Cello ، فإن التعقيدات التناغمية أكثر صعوبة في الالتقاط وبالتالي فهي أكثر جدارة بالتحقيق. ومع ذلك ، يمكنك أيضًا تطبيق نفس التحليل على التنبؤات الإيقاعية للنموذج ، والتي قد تكون ذات صلة بشكل خاص بأنماط الموسيقى الأخرى التي يمكنك استخدامها لتدريب هذا النموذج (مثل مسار الطبلة).

هناك عدة نقاط يجب ملاحظتها حول النغمات التي تم إنشاؤها.
أولاً ، انظر كيف أصبحت الموسيقى أكثر تعقيدًا مع تقدم التدريب. في البداية ، يقوم النموذج بتكرار نفس مجموعة النغمات والإيقاعات. بحلول الحقبة العاشرة : بدأ النموذج في إنشاء مجموعات صغيرة من النوتات الموسيقية . بحلول الحقبة 20 ، كان ينتج إيقاعات مثيرة للاهتمام وقد إختار مفتاح معين و هو (E-flat major).
ثانيًا ، يمكننا تحليل توزيع درجات النغمات بمرور الوقت عن طريق رسم التوزيع المتوقع في كل خطوة زمنية كخريطة حرارة. توضح الصورة التالية خريطة الحرارة هذه للمثال من الحقبة 20 في الصورة السابقة.
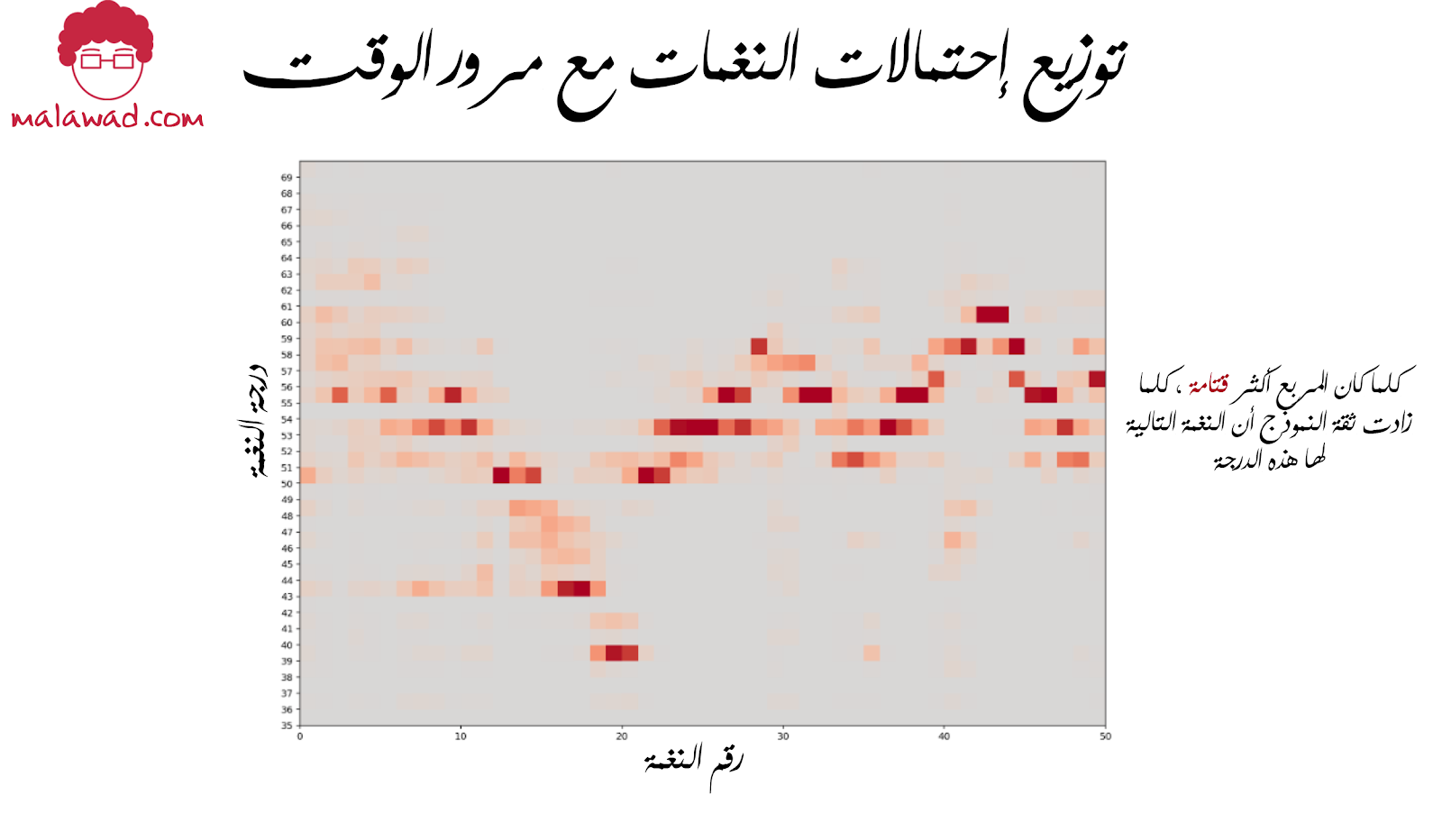
هناك نقطة مثيرة للاهتمام يجب ملاحظتها هنا وهي أن النموذج قد تعلم بوضوح أي الملاحظات تنتمي إلى مفاتيح معينة ، حيث توجد فجوات في التوزيع في الملاحظات التي لا تنتمي إلى المفتاح. على سبيل المثال ، توجد فجوة رمادية على طول صف الملاحظة 54 (المقابلة لـ #Gb/F). من غير المرجح أن تظهر هذه النوتة الموسيقية في مقطوعة موسيقية في مفتاح E-flat major.
في وقت مبكر من عملية التوليد (الجانب الأيسر من الرسم التخطيطي) ، لم يتم بعد إختيار المفتاح و تثبيت بشكل ثابت ، وبالتالي هناك المزيد من عدم اليقين في كيفية اختيار الملاحظة التالية. مع تقدم القطعة ، يستقر النموذج على مفتاح ويصبح من شبه المؤكد عدم ظهور بعض الملاحظات.
الأمر اللافت للنظر هو أن النموذج لم يقرر صراحة ضبط الموسيقى في مفتاح معين في البداية ، ولكنه بدلاً من ذلك يقوم باختلاقها حرفيًا أثناء التدريب، محاولًا اختيار النوتة التي تتناسب بشكل أفضل مع تلك التي اختارها مسبقًا .
ومن الجدير بالذكر أيضًا أن النموذج قد تعلم أسلوب باخ المميز في الانخفاض إلى نغمة منخفضة على التشيلو لإنهاء عبارة والارتداد مرة أخرى لبدء العبارة التالية.
انظر كيف تنتهي العبارة حول الملاحظة 20 على مستوى منخفض من E-flat – من الشائع في موسيقى Bach Cello أن تعود بعد ذلك إلى نطاق أعلى وأكثر رنانًا من الأداة لبدء العبارة التالية ، وهو بالضبط ما يتوقعه النموذج.
توجد فجوة رمادية كبيرة بين المستوى المنخفض E-flat (درجة الصوت رقم 39) والنغمة التالية ، والتي يُتوقع أن تكون حول درجة الصوت رقم 50 ، بدلاً من الاستمرار في الدمدمة حول أعماق الآلة.
أخيرًا ، يجب أن نتحقق لمعرفة ما إذا كانت آلية الانتباه لدينا تعمل كما هو متوقع. توضح الصورة التالية قيم عناصر متجه ألفا المحسوبة بواسطة الشبكة في كل نقطة في التسلسل الناتج. يُظهر المحور الأفقي تسلسل الملاحظات الناتج ؛ يُظهر المحور العامودي المكان الذي تم توجيه انتباه الشبكة إليه عند توقع كل ملاحظة على طول المحور الأفقي (أي متجه ألفا). كلما كان المربع أكثر قتامة ، زاد الاهتمام بالحالة المخفية المقابلة لهذه النقطة في التسلسل.
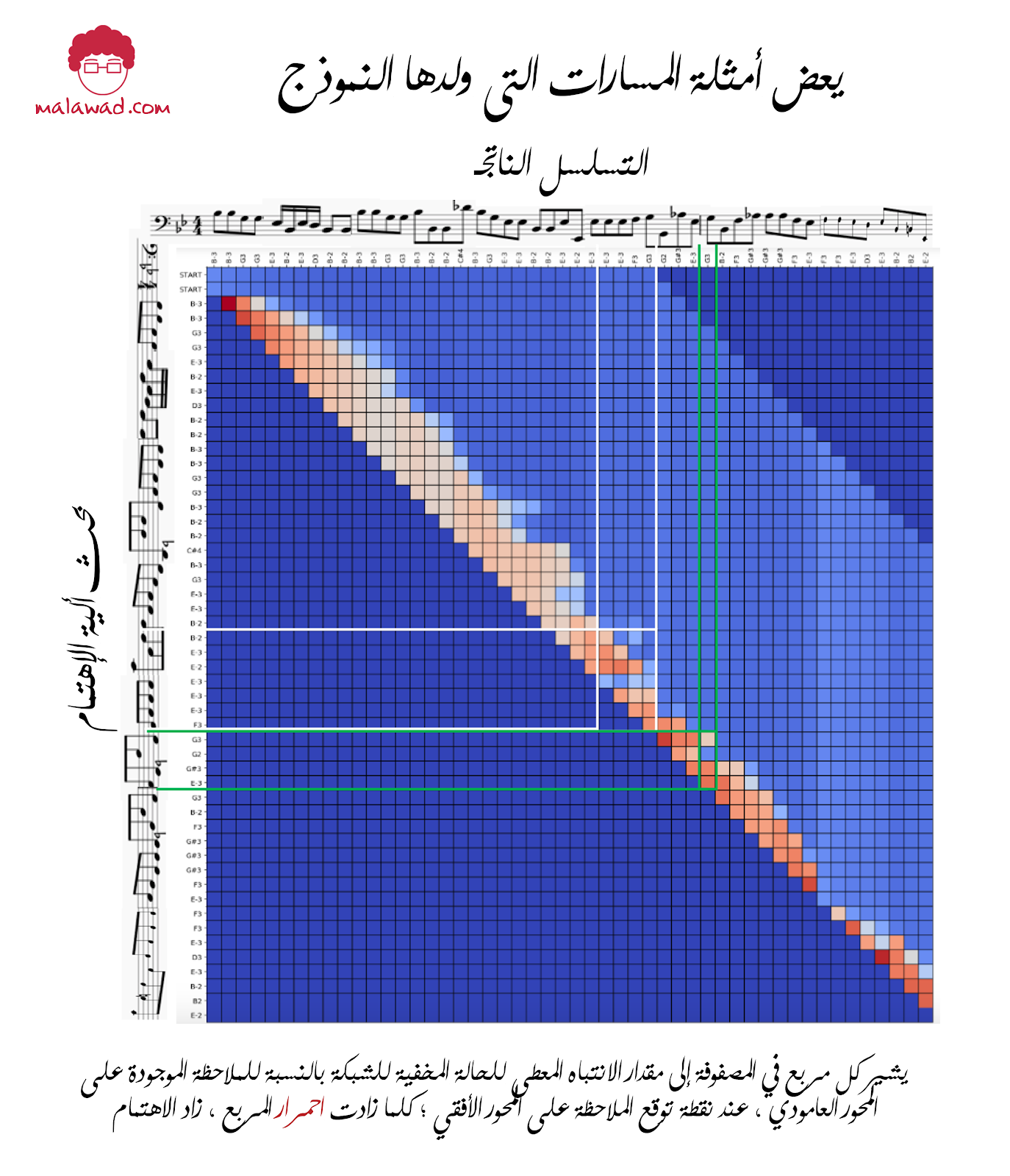
يمكننا أن نرى أنه بالنسبة للملاحظة الثانية للقطعة (B-3 = B-flat) ، اختارت الشبكة أن تضع كل انتباهها تقريبًا على حقيقة أن الملاحظة الأولى للقطعة كانت أيضًا B-3. هذا يبدو منطقيا؛ إذا كنت تعلم أن الملاحظة الأولى هي B-flat ، فمن المحتمل أن تستخدم هذه المعلومات لإبلاغ قرارك بشأن الملاحظة التالية.
بينما ننتقل خلال الملاحظات القليلة التالية ، تنشر الشبكة اهتمامها بالتساوي تقريبًا بين الملاحظات السابقة – ومع ذلك ، نادرًا ما تضع أي وزن على الملاحظات قبل أكثر من ست ملاحظات. مرة أخرى ، هذا منطقي ؛ ربما تكون هناك معلومات كافية واردة في الحالات المخفية الست السابقة لفهم كيفية استمرار العبارة.
هناك أيضًا أمثلة على الأماكن التي اختارت الشبكة تجاهل ملاحظة معينة قريبة منها ، حيث إنها لا تضيف أي معلومات إضافية لفهمها لهذه العبارة. على سبيل المثال ، ألق نظرة داخل المربع الأبيض المحدد في وسط الرسم التخطيطي ، ولاحظ كيف يوجد شريط من الصناديق في المنتصف يقطع النمط المعتاد للنظر إلى الوراء في الملاحظات الأربع إلى الست السابقة. لماذا تختار الشبكة عن طيب خاطر تجاهل هذه الملاحظة عند تقرير كيفية متابعة العبارة؟
إذا نظرت عبرها لترى أي ملاحظة تتوافق معها ، يمكنك أن ترى أنها الأولى من ثلاث ملاحظات E-3 (E-flat). اختار النموذج تجاهل هذا لأن الملاحظة السابقة لذلك هي أيضًا E-flat ، وأوكتاف أقل (E-2). ستوفر الحالة المخفية للشبكة في هذه المرحلة معلومات كافية للنموذج لفهم أن E-flat هي ملاحظة مهمة في هذا المقطع ، وبالتالي لا يحتاج النموذج إلى الانتباه إلى E-flat الأعلى لاحقًا ، لأنه لا تضيف أي معلومات إضافية.
يمكن رؤية دليل إضافي على أن النموذج قد بدأ في فهم مفهوم الأوكتاف داخل المربع الأخضر أدناه وإلى اليمين. هنا اختار النموذج تجاهل G (G2) المنخفضة لأن الملاحظة السابقة لذلك كانت أيضًا G (G3) ، أوكتاف أعلى. تذكر أننا لم نخبر النموذج بأي شيء يتعلق بالملاحظات المرتبطة من خلال الأوكتافات – لقد نجح في ذلك بنفسه فقط من خلال دراسة موسيقى ج. باخ ، وهو أمر رائع.
ألية الاهتمام في شبكات الترميز- فك الترميز
آلية الانتباه هي أداة قوية تساعد الشبكة على تحديد الحالات السابقة للطبقة المتكررة المهمة للتنبؤ باستمرار التسلسل. حتى الآن ، رأينا هذا بالنسبة للتنبؤات ذات الملاحظة الواحدة. ومع ذلك ، قد نرغب أيضًا في جذب الانتباه إلى شبكات التشفير وفك التشفير ، حيث نتوقع سلسلة من الملاحظات المستقبلية باستخدام مفكك تشفير RNN ، بدلاً من بناء تسلسلات ملاحظة واحدة في كل مرة.
للتلخيص ، يوضح الصورة التالية كيف يمكن أن يبدو نموذج شبكة فك الشفير المعياري لتوليد الموسيقى ، دون الانتباه – النوع الذي قدمناه في المقال الثالث عشر من سلسلة شبكات فك الخصومة التوليدية .
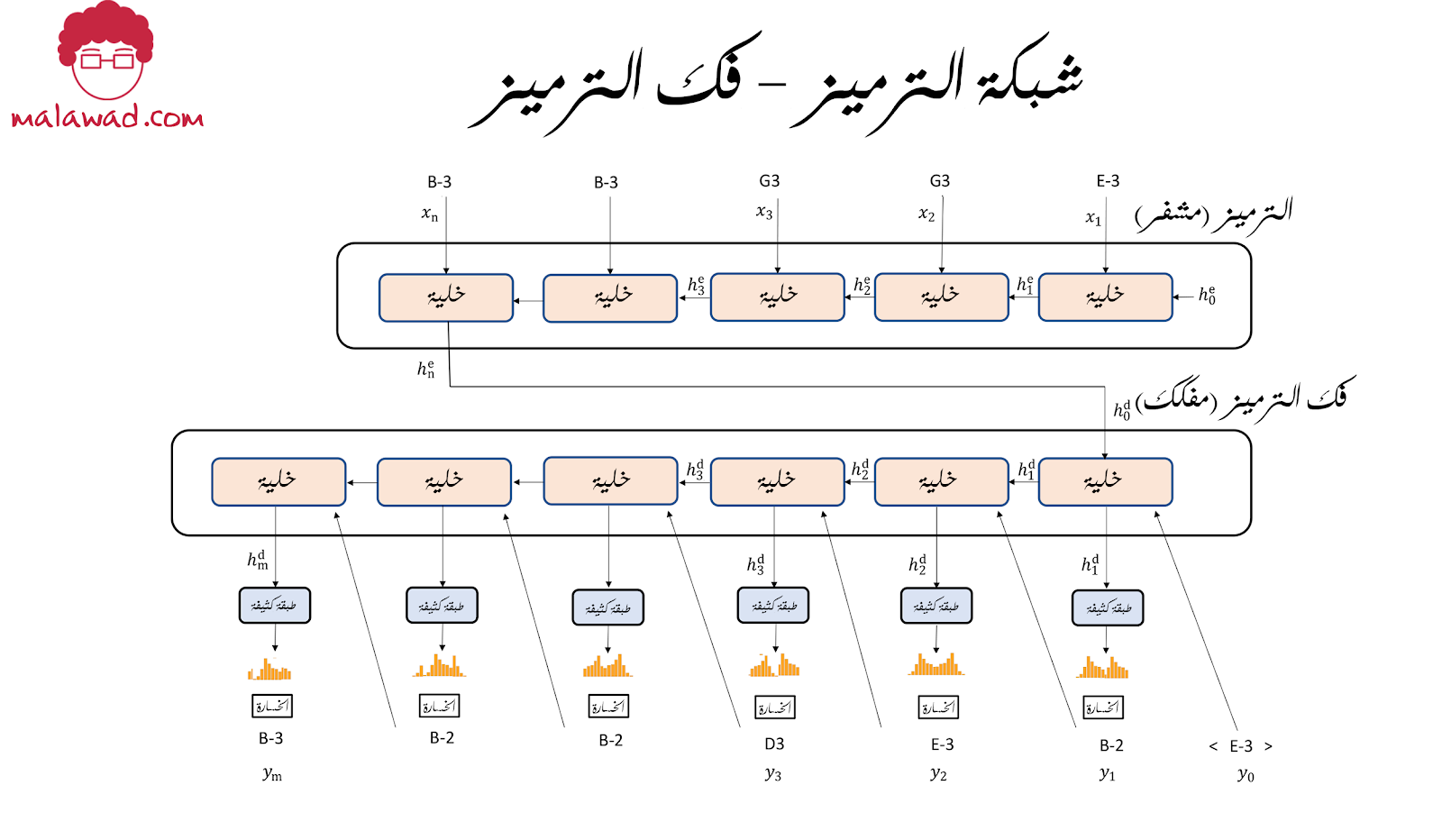
يوضح االصورة التالية نفس الشبكة ، ولكن مع آلية انتباه بين المشفر ووحدة فك التشفير.

تعمل آلية الانتباه تمامًا بالطريقة نفسها التي رأيناها سابقًا ، مع تغيير واحد: يتم أيضًا إدخال الحالة المخفية لشبكة فك التشفير في الآلية حتى يتمكن النموذج من تحديد مكان تركيز انتباهه ليس فقط من خلال الحالات المخفية السابقة للمشفر، ولكن أيضًا من الحالة المخفية للمفكك الحالية. توضح الصورة التالية العملية الداخلية لوحدة الانتباه داخل إطار عمل شبكة التشفير فك التشفير.

في حين أن هناك العديد من نسخ آلية الانتباه داخل شبكة التشفير وفك الشفرة ، إلا أنها تشترك جميعها في نفس الأوزان ، لذلك لا يوجد حمل إضافي في عدد المعايير التي يجب تعلمها. التغيير الوحيد هو أنه الآن ، يتم وضع الحالة المخفية لوحدة فك التشفير في حسابات الانتباه (الخطوط الحمراء في الرسم التخطيطي). يغير هذا قليلاً المعادلات حيث نضيف (i) لتحديد خطوة شبكة فك التشفير.
لاحظ أيضًا كيف نستخدم في صورة نموج التشفير فك التشفير التقليدية الحالة النهائية للمشفر لتهيئة الحالة المخفيه للمفكك . في نموذج التشفير – فك التشفير مع الانتباه ، نقوم بدلاً من ذلك بتهيئة المفكك باستخدام المهييات القياسية (standard initializers) المدمجة لطبقة متكررة .
يتم ربط متجه السياق ci بالبيانات الواردة yi – 1 لتشكيل متجه موسعه للبيانات في كل خلية من وحدة فك التشفير. وبالتالي ، فإننا نتعامل مع متجهات السياق كبيانات إضافية يتم إدخالها في وحدة فك التشفير.
ختاماً
يتشابه LSTM المكدس في التصميم مع الشبكات التي رأيناها في المقالين السابقين لتوليد النص. يشترك إنشاء الموسيقى والنصوص في الكثير من الميزات المشتركة ، وغالبًا ما يمكن استخدام تقنيات مماثلة لكليهما. لقد عززنا الشبكة المتكررة بآلية الانتباه التي تسمح للنموذج بالتركيز على خطوات زمنية سابقة محددة من أجل التنبؤ بالنغمات التالية ورأينا كيف تمكن النموذج من التعرف على مفاهيم مثل الأوكتافات والمفاتيح ، وذلك ببساطة عن طريق تعلم موسيقى باخ بدقة .
رابط الكود على الغيتهاب













إضافة تعليق