
في المقالة السابقة من سلسة شبكات الخصومة التوليدية تعرفنا على شبكات الترميز التلقائيه (Autoencoders) و على مميزاتها و عيوبها ، وفي هذه المقالة سنتعرف على التطور التالي لهذه الشبكات و هي شبكات الترميز التلقائي المتغيره (variational autoencoder) ، ولكن في البداية قصة
معرض الفن المتنوع
بعد النتائج المخيبة لمعرض الفن التوليدي ، قام السيد مشفر بتوظيف ابنته إيبسلون . بعد مناقشة قصيرة ، قرروا تغيير الطريقة التي يتم بها تحديد علامات اللوحات الجديدة على الحائط. و الطريقة الجديدة كالأتي :
عندما تصل لوحة جديدة إلى المعرض ، يختار السيد مشفر نقطة على الحائط حيث يرغب في وضع العلامة لتمثيل العمل الفني ، كما كان يفعل من قبل. ولكن الآن ، بدلاً من وضع العلامة على الحائط بنفسه ، ينقل رأيه حول المكان الذي يجب أن وضع العلامه فيه إلى إبنته إبسيلون ، و التي تفرر مكان وضع العلامة. هي بالطبع تأخذ رأي والدها في الاعتبار ، لذلك عادة ما تضع العلامة في مكان ما بالقرب من النقطة التي يقترحها. بعد ذلك يقوم السيد مفكك بإيجاد العلامة التي وضعهتا إبسيلون من دون أن يأخذ راي السيد مشفر الأصلي في الأعتبار
كما يقدم السيد مشفر لابنته إشارة إلى مدى تأكده من مكان وضع العلامة عند نقطة معينة. كلما كان أكثر ثقة ، تضع إبسيلون العلامه بالقرب من اقتراحه بشكل عام.
هناك تغيير أخير في النظام القديم. فسابقاً ، كانت آلية التغذية الراجعة الوحيدة هي فقدان الأرباح في مكتب التذاكر الناتج عن الصور التي أعيد بناؤها بشكل سيئ. إذا رأى الأخوة أنه لم يتم إعادة إنشاء لوحات معينة بدقة ، فسيقومون بتعديل فهمهم لوضع العلامات وتجديد الصور لضمان تقليل الخسائر في الإيرادات إلى أدنى حد.
الآن ، هناك مصدر آخر. إبسيلون كسوله للغاية وتنزعج عندما يطلب منها والدها وضع علامات بعيدًا عن مركز الجدار ، حيث يقع السلم. كما أنها لا تحبه عندما يكون صارمًا للغاية بشأن مكان وضع العلامات ، حيث تشعر أنه لا يثق فبها كفاية و لا يعطيها مسؤولية الكافية. وبالمثل ، إذا كان والدها يصرح بالقليل من الثقة في المكان الذي يجب أن تذهب إليه العلامات ، فإنها تشعر أنها هي التي تقوم بكل العمل! يجب أن تكون ثقته في مواضع العلامات التي يقدمها مناسبة لها حتى تكون سعيدة.
للتعويض عن انزعاجها ، بدفع لها والدها أكثر للقيام بهذه المهمة عندما لا يلتزم بهذه القواعد. يتم إدراج هذه المصروفات في كتب الميزانية على أنها خسارة تعويض إبنته. لذلك عليه أن يكون حذرا لأن لا ينتهي به المطاف بدفع مبالغ كبيره لابنته وفي نفس الوقت يراقب أيضا خسارة الإيرادات في مكتب التذاكر. بعد التدريب على هذه التغييرات البسيطة ، يحاول السيد مشفر مرة أخرى إستراتيجيته بوضع علامات على أجزاء من الجدار فارغة ، بحيث يمكن للسيد مشفر تجديد هذه النقاط كعمل فني أصلي.
يتم عرض بعض هذه النقاط أدناه ، إلى جانب الصور التي تم إنشاؤها.
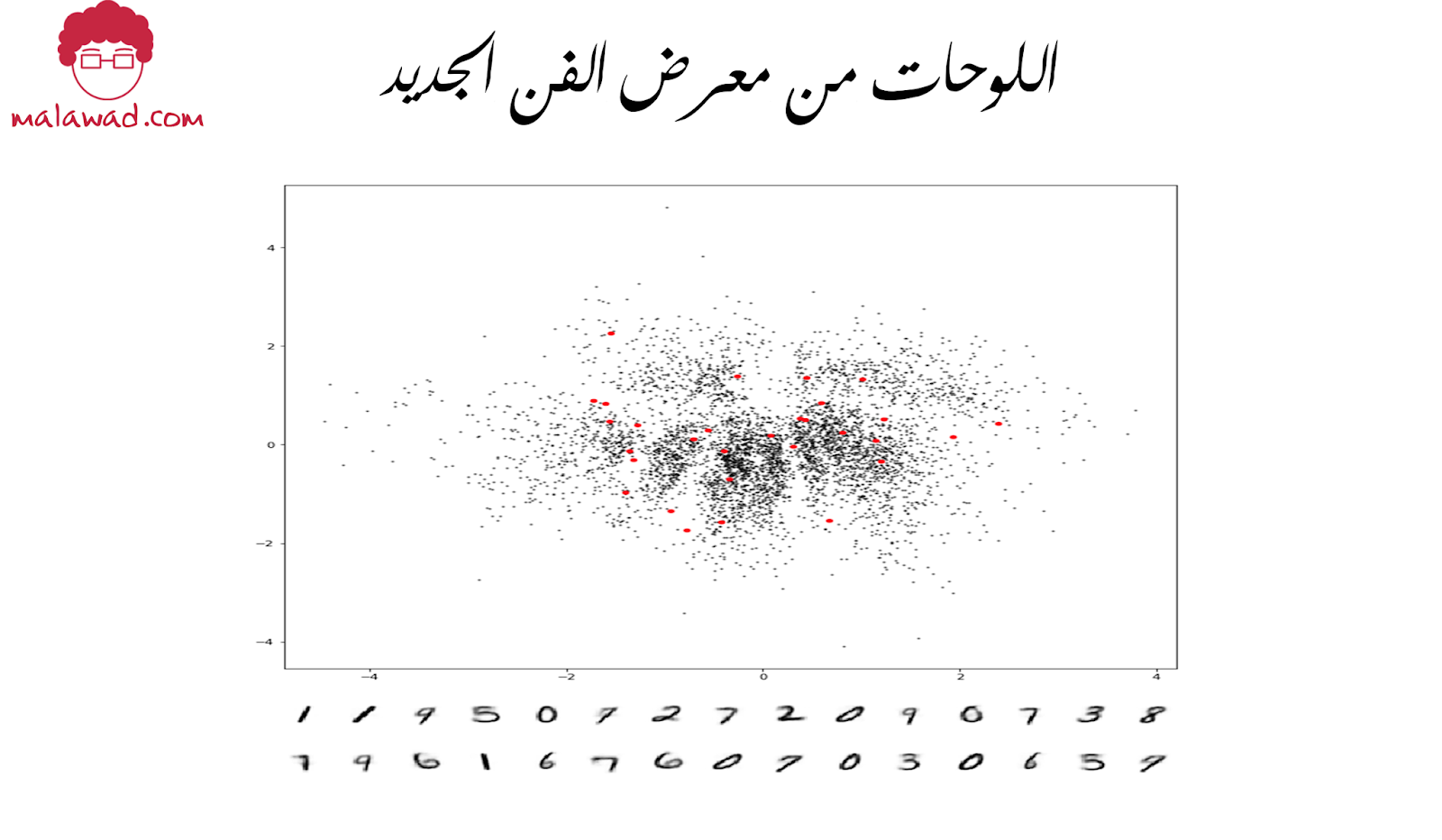
هذا أفضل بكثير! تصل الحشود في أمواج كبيرة لرؤية هذا الفن التوليدي الجديد والمثير وهي مندهشة من أصالة اللوحات وتنوعها.
بناء شبكة الترميز التلقائي المتغيره
أظهرت القصة السابقة كيف يمكن ، مع بعض التغييرات البسيطة ، تحويل المعرض الفني إلى عملية توليدية ناجحة. دعنا نحاول الآن أن نفهم رياضيًا ما يتعين علينا القيام به لشبكة الترميز التلقائي (autoencoder) لتحويلها إلى شبكة الترميز التلقائي المتغيره (variational autoencoder) وبالتالي جعله نموذجًا حقيقيًا.
في الواقع ، هناك جزءان فقط نحتاج إلى تغييرهما: التشفير ودالة الخسارة.
التشفير
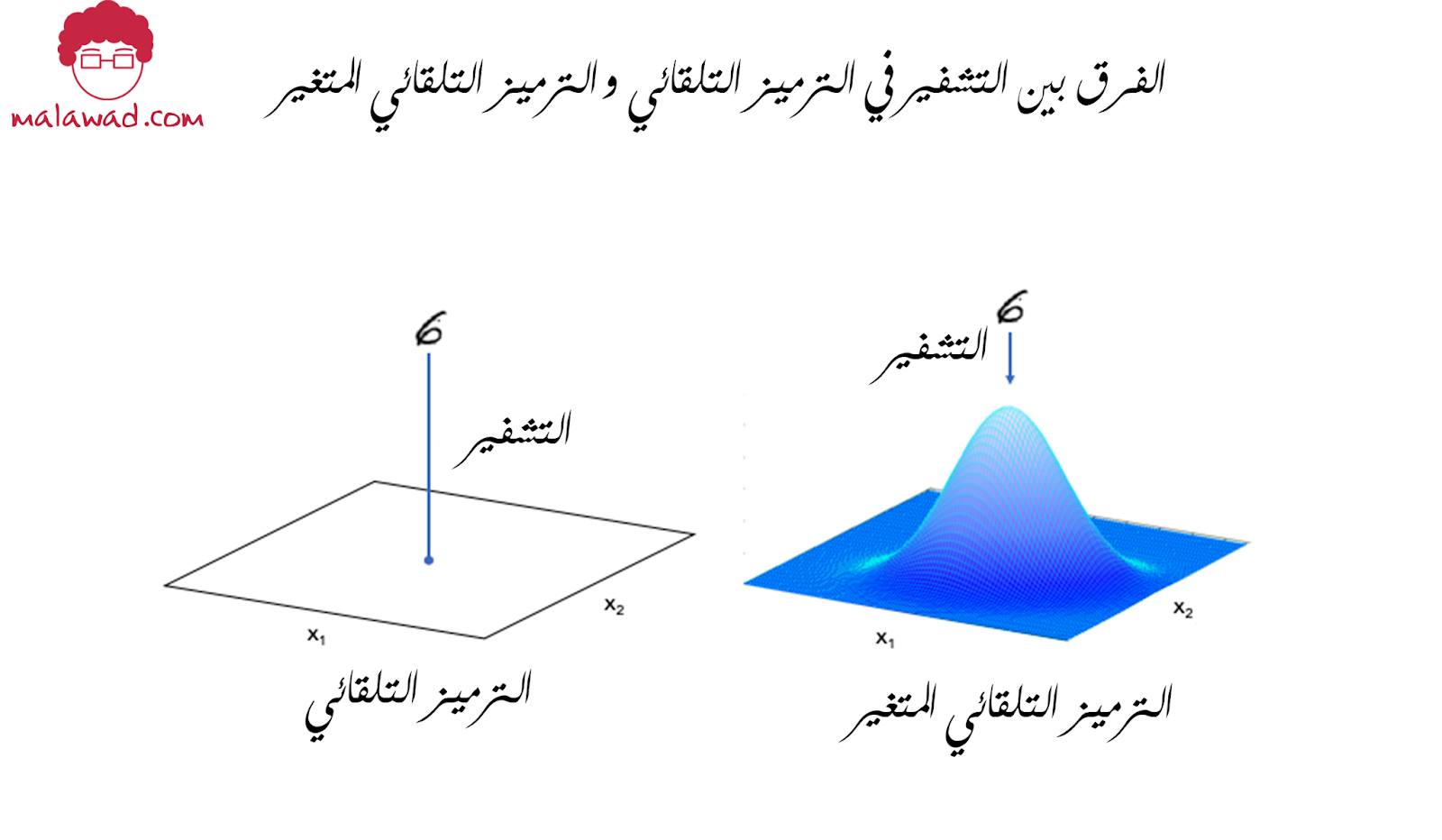
في شبكة الترميز التلقائي ، يتم تعيين كل صورة مباشرة إلى نقطة واحدة في الفضاء الكامن. في شبكة الترميز التلقائي المتغيره ، يتم تعيين كل صورة بدلاً من ذلك إلى توزيع عادي متعدد المتغيرات حول نقطة في الفضاء الكامن. ، كما هو موضح في الصورة أدناه
التوزيع الطبيعي
التوزيع الطبيعي (normal distribution) هو توزيع احتمالي يتميز بشكل منحنى جرس مميز. في أحد الأبعاد ، يتم تعريفه بمتغيرين: المتوسط (μ) والتباين (σ2). اما الانحراف المعياري (σ) فهو الجذر التربيعي للتباين.
دالة كثافة الاحتمال للتوزيع الطبيعي في بعد واحد هي:

توضح الصورة أدناه عدة توزيعات طبيعية في بُعد واحد ، لقيم مختلفة من المتوسط (mean) والتباين (variance). المنحنى الأحمر هو المعيار الطبيعي القياسي(standard normal) و هو التوزيع الطبيعي بمتوسط يساوي 0 والتباين يساوي 1.

يمكننا أخذ عينة النقطة z من التوزيع الطبيعي بمتوسط μ وانحراف معياري σ باستخدام المعادلة التالية:
Z = μ + σϵ
حيث يتم أخذ ϵ من التوزيع الطبيعي القياسي (standard normal distribution).
يمتد مفهوم التوزيع الطبيعي إلى أكثر من بُعد واحد حيث أن دالة الكثافة الاحتمالية للتوزيع الطبيعي متعدد المتغيرات في k أبعاد تعطى كالأتي :

في بُعدين ، يتم تعريف متوسط المتجه μ ومصفوفة التغاير المتناظرة Σ على النحو التالي:

حيث ρ هي العلاقة بين البعدين x1 و x2.
نعود مرة أخرى إلى التشفير
تفترض شبكة الترميز التلقائي المتغيره (variational autoencoder) أنه لا يوجد ارتباط بين أي من الأبعاد في الفضاء الكامن وبالتالي فإن مصفوفة التغاير قطرية. وهذا يعني أن شبكة التشفير تحتاج فقط إلى تعيين كل مدخل (input) إلى متجه متوسط (mean vector) ومتجه تباين (variance vector) ولا داعي للقلق بشأن التباين بين الأبعاد. نختار أيضًا تعيين لوغاريتم التباين ، حيث يمكن أن يأخذ هذا أي رقم حقيقي في النطاق (- ∞ ، ∞) ، مطابقًا لنطاق المخرجات الطبيعية من وحدة الشبكة العصبية ، في حين تكون قيم التباين إيجابية دائمًا.
للتلخيص ، ستأخذ شبكة التشفير كل صورة إدخال و تشفرها إلى متجهين ، mu و log_var اللذين يحددان معًا التوزيع الطبيعي متعدد المتغيرات في الفضاء الكامن:
mu: متوسط نقطة التوزيع.
log_var : لوغاريتم تباين كل بُعد.
لتشفير صورة في نقطة معينة z في الفضاء الكامن ، يمكننا أخذ عينات من هذا التوزيع باستخدام المعادلة التالية:
z = mu + sigma * epsilon
حيث
Sigma = exp(log_var / 2 )
وفي ما يتعلق بالعودة إلى قصتنا ، تمثل mu رأي السيد مشفر حول مكان وضع العلامة على الحائط. إبسيلون هو اختيار ابنته العشوائي لمدى إبتعاد وضع العلامه عن mu ، ثم تضخيمها بقيمة sigma ، حيث تمثل ثقة السيد مشفر في موضع العلامة.
إذن ، لماذا يساعد هذا التغيير الصغير في شبكة التشفير؟
في السابق ، رأينا كيف أنه لم يكن هناك حاجة إلى استمرارية الفضاء الكامن – حتى لو كانت النقطة (-2 ، 2) تتكوّن إلى صورة جيدة لرقم 4 ، لم يكن هناك شرط لأن تكون النقطة (-2.2 ، 2.1) مشابه لها.
الآن ، بما أننا نأخذ عينات من نقطة عشوائية من منطقة حول mu ، يجب أن تضمن شبكة فك التشفير أن جميع النقاط في نفس المنطقة ستنتج صورًا متشابهة جدًا عند فك تشفيرها ، بحيث تظل خسارة إعادة البناء صغيرة.
هذه خاصية تضمن أنه حتى عندما نختار نقطة في الفضاء الكامن لم يسبق أن تم رؤيتها من قبل شبكة فك التشفير ، فمن المحتمل أن يتم فك تشفيرها إلى صورة جيدة التكوين.
دعونا نرى الآن كيف نبني هذا الإصدار الجديد من التشفير في Keras
### المشفر
encoder_input = Input(shape=self.input_dim, name='encoder_input')
x = encoder_input
for i in range(self.n_layers_encoder):
conv_layer = Conv2D(
filters = self.encoder_conv_filters[i]
, kernel_size = self.encoder_conv_kernel_size[i]
, strides = self.encoder_conv_strides[i]
, padding = 'same'
, name = 'encoder_conv_' + str(i)
)
x = conv_layer(x)
if self.use_batch_norm:
x = BatchNormalization()(x)
x = LeakyReLU()(x)
if self.use_dropout:
x = Dropout(rate = 0.25)(x)
shape_before_flattening = K.int_shape(x)[1:]
x = Flatten()(x)
self.mu = Dense(self.z_dim, name='mu')(x) #1
self.log_var = Dense(self.z_dim, name='log_var')(x)
encoder_mu_log_var = Model(encoder_input, (self.mu, self.log_var)) #2
def sampling(args):
mu, log_var = args
epsilon = K.random_normal(shape=K.shape(mu), mean=0., stddev=1.)
return mu + K.exp(log_var / 2) * epsilon
encoder_output = Lambda(sampling, name='encoder_output')([self.mu, self.log_var]) #3
encoder = Model(encoder_input, encoder_output) #4
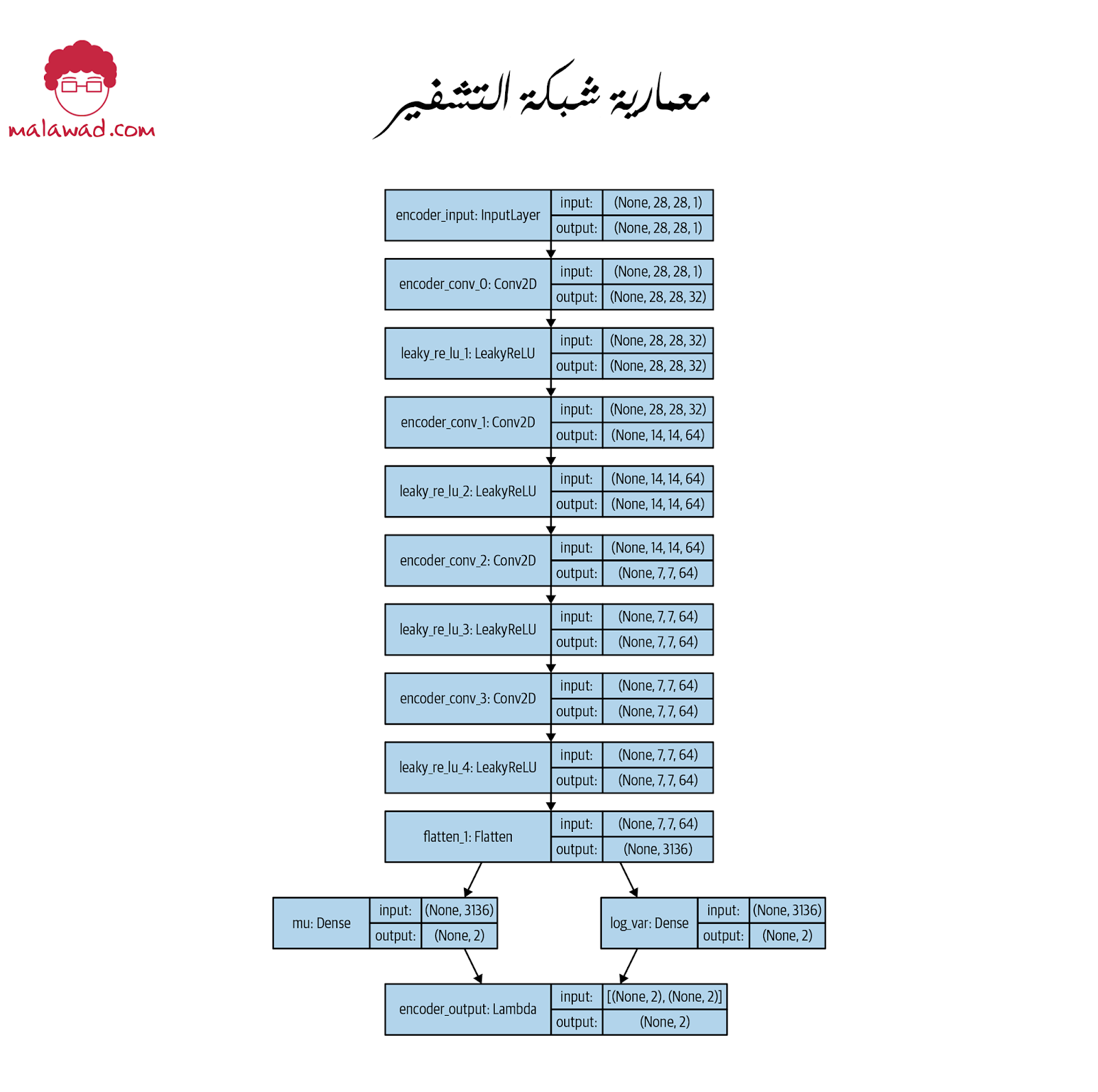
- بدلاً من ربط الطبقة المسطحة مباشرة بالفضاء الكامن ثنائية الأبعاد ، نقوم بتوصيلها بطبقات mu و log_var.
- نموذج Keras الذي ينتج قيم mu و log_var لصورة إدخال معينة.
- تُعاين طبقة Lambda النقطة z في الفضاء الكامن من التوزيع الطبيعي المحدد بواسطة المعلمات mu و log_var.
- نموذج Keras الذي يحدد المشفر – نموذج يأخذ صورة إدخال ويشفّرها في الفضاء الكامن ثنائي الأبعاد ، عن طريق أخذ عينات من نقطة التوزيع الطبيعي المحددة بواسطة mu و log_var.
طبقة لامبدا (LAMBDA LAYER)
طبقة لامدا ببساطة تقوم بلف أي دالة في طبقة Keras. على سبيل المثال ، الطبقة التالية تقوم بتربيع مدخلاتها:
Lambda(lambda x: x ** 2)
تكون مفيدة عندما تريد تطبيق دالة على تنسور لم يتم تضمينه كأحد أنواع طبقات Keras الجاهزة.
يوضح الصورة التالية معمارية شبكة التشفير.
كما ذكرنا سابقًا ، فإن مفكك التشفير التلقائي المتغير مطابق لمفكك التشفير التلقائي الإعتيادي. الجزء الآخر الوحيد الذي نحتاج إلى تغييره هو دالة الخسارة.
نظرًا لأننا نأخذ عينات من نقطة عشوائية من منطقة حول mu ، يجب أن يضمن مفكك التشفير أن جميع النقاط في نفس المنطقة تنتج صورًا متشابهة جدًا عند فك تشفيرها ، بحيث تظل خسارة إعادة البناء صغيرة.
دالة الخسارة
في السابق ، كانت دالة الخسارة (loss function) الخاصة بنا تتكون فقط من الخسارة RMSE بين الصور وإعادة بنائها بعد تمريرها من خلال شبكتي التشفير وفك الشفرة. هذه الخسارة موجودة كذلك في شبكة الترميز التلقائي المتغيره (variational autoencoder) . و لكن هنا نحتاج إلى مكون إضافي واحد: اختلاف كيلباك ليبليبر (Kullback–Leibler divergence)
اختلاف KL هو طريقة لقياس مدى اختلاف توزيع الاحتمال عن الآخر في شبكة الترميز التلقائي المتغيره، نريد قياس مدى اختلاف توزيعنا الطبيعي مع المعايير mu و log_var عن التوزيع الطبيعي القياسي. في هذه الحالة الخاصة إختلاف KL لدية هذه الهيئة المغلقة :
kl_loss = -0.5 * sum (1 + log_var – mu ^ 2 – exp (log_var))
او بطريقة رياضية
![D_{K L} \mid N(\mu, \sigma \| N(0,1)]=\frac{1}{2} \sum\left(1+\log \left(\sigma^{2}\right)-\mu^{2}-\sigma^{2}\right)](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-44c8d514df6dd3998ef0da7050eb6c95_l3.png "Rendered by QuickLaTeX.com")
يتم أخذ المجموع على جميع الأبعاد في الفضاء الكامن. يتم تصغير kl_loss إلى صفر عندما mu = 0 و log_var = 0 لجميع الأبعاد. عندما يبدأ هذان المصطلحان في الاختلاف من صفر ، يزداد kl_loss.
باختصار ، يعاقب مصطلح اختلاف KL الشبكة لتشفير الملاحظات إلى متغيرات mu و log_var التي تختلف بشكل كبير عن معايير التوزيع الطبيعي القياسي ، وهي mu = 0 و log_var = 0.
مرة أخرى ، نرجع إلى قصتنا ، يمثل هذا المصطلح إزعاج إبسيلون في الاضطرار إلى تحريك السلم بعيدًا عن منتصف الجدار (يختلف mu عن 0) وأيضًا إذا كانت ثقة السيد مشفر في وضع العلامة ليست صائبة ( يختلف log_var عن 0) ، وكلاهما يزيد الخسارة.
لماذا تساعد هذه الإضافة في دالة الخسارة؟
أولاً ، لدينا الآن توزيع محدد جيدًا يمكننا استخدامه لاختيار النقاط في الفضاء الكامن – التوزيع الطبيعي القياسي. إذا أخذنا عينة من هذا التوزيع ، فإننا نعلم أنه من المحتمل جدًا أن نحصل على نقطة تقع في حدود ما اعتاد شبكة الترميز التلقائي المتغيره (variational autoencoder) على رؤيته
ثانيًا ، نظرًا لأن هذا المصطلح يحاول فرض جميع التوزيعات المشفرة نحو التوزيع الطبيعي القياسي ، هناك فرصة أقل لوجود فجوات كبيرة. بدلاً من ذلك ، ستحاول شبكة التشفير استخدام المساحة حول نفطة المركز بشكل متماثل وفعال.
في البرمجة ، وظيفة الخسارة لـ شبكة الترميز التلقائي المتنوع هي ببساطة إضافة خسارة إعادة البناء ومصطلح خسارة الاختلاف KL. نحن نزن خسارة إعادة البناء بمصطلح ، r_loss_factor ، والذي يضمن أنه متوازن بشكل جيد مع خسارة اختلاف KL. إذا قمنا بوزن خسارة إعادة البناء بشكل كبير جدًا ، فلن يكون لخسارة KL التأثير التنظيمي المطلوب وسنرى نفس المشاكل التي واجهناها مع شبكة الترميز التلقائي العاديه. إذا كان مصطلح الترجيح صغيرًا جدًا ، فستسيطر خسارة اختلاف KL وستكون الصور التي أعيد بناؤها ضعيفة. يعد مصطلح الوزن هذا أحد المعايير التي يتعين ضبطها عندما تقوم بتدريب شبكة الترميز التلقائي المتنوع .
optimizer = Adam(lr=learning_rate)
def vae_r_loss(y_true, y_pred):
r_loss = K.mean(K.square(y_true - y_pred), axis = [1,2,3])
return r_loss_factor * r_loss
def vae_kl_loss(y_true, y_pred):
kl_loss = -0.5 * K.sum(1 + self.log_var - K.square(self.mu)
- K.exp(self.log_var), axis = 1)
return kl_loss
def vae_loss(y_true, y_pred):
r_loss = vae_r_loss(y_true, y_pred)
kl_loss = vae_kl_loss(y_true, y_pred)
return r_loss + kl_loss
optimizer = Adam(lr=learning_rate)
self.model.compile(optimizer=optimizer, loss = vae_loss
, metrics = [vae_r_loss, vae_kl_loss])
تحليل شبكة الترميز التلقائي المتغيره
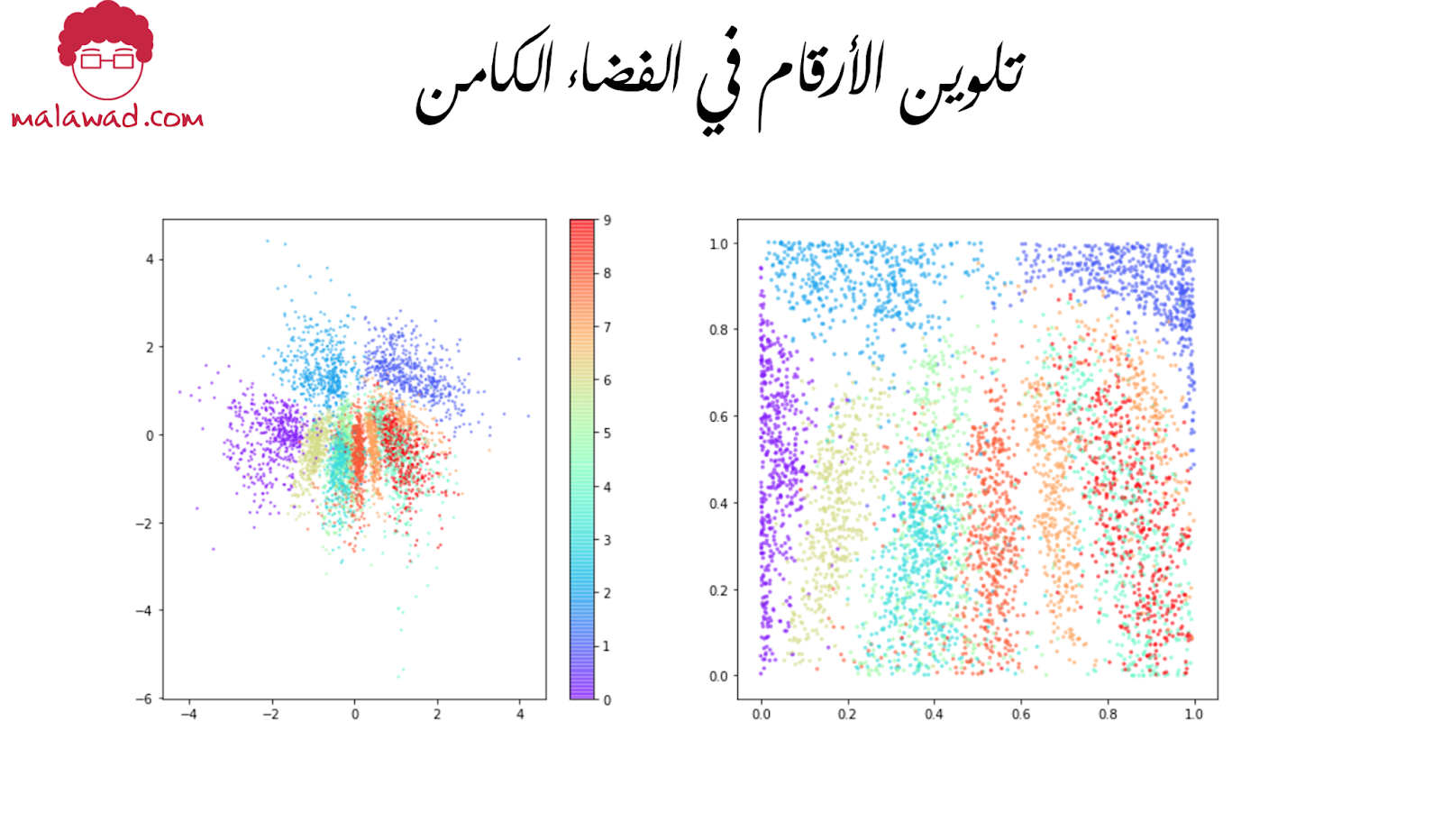
بالعودة إلى الصورة أدناه ،
يمكننا أن نرى العديد من التغييرات في كيفية تنظيم الفضاء الكامن.
أولاً : تُظهر النقاط السوداء قيم mu لكل صورة مشفرة يضمن مصطلح خسارة التباعد في KL أن قيم mu و sigma لا تبتعد أبدًا عن المعيار العادي. لذلك يمكننا أخذ عينات من التوزيع الطبيعي القياسي لتوليد نقاط جديدة في المناطق التي سيتم فك شفرتها (النقاط الحمراء).
ثانيًا ، لا يوجد الكثير من الأرقام المولدة التي تم تشكيلها بشكل سيئ ، حيث أن الفضاء الكامن مستمر الآن محليًا نظرًا لأن التشفير أصبح الآن عشوائيًا (stochastic) ، وليس محددًا (deterministic).
أخيرًا ، من خلال نقاط التلوين في الفضاء الكامن بالأرقام ، يمكننا أن نرى أنه لا توجد معاملة تفضيلية لأي نوع واحد. يُظهر المخطط الأيمن المساحة المحولة إلى قيم p ، ويمكننا أن نرى أن كل لون يتم تمثيله بشكل متساوٍ تقريبًا.
حتى الآن ، يقتصر عملنا في شبكات الترميز التلقائي و شبكات الترميز التلقائي المتنوعة على الفضاء الكامن ذو بعدين. وقد ساعدنا هذا على تصور طريقة عمل شبكات الترميز التلقائي المتنوعة وفهم لماذا ساعدت التعديلات الصغيرة التي أجريناها على معمارية الترميز التلقائي في تحويله إلى فئة شبكية أكثر قوة من يمكن استخدامها في النمذجة التوليدية.
في الختام
للتعرف أكثر على شبكات الترميز التلقائي المتغيره ، بإمكانكم مشاهده هذه المحاضرة ..
الكود المستخدم في هذه المقالة موجود على غيتهاب ..













إضافة تعليق