
في المقال السابق، نظرنا في استخدام شبكات LSTM لتوليد استمرار تسلسل نصي موجود. لقد رأينا كيف يمكن لطبقة LSTM واحدة معالجة البيانات بشكل تسلسلي لتحديث الحالة المخفية التي تمثل فهم الطبقة الحالي للتسلسل. من خلال توصيل الحالة المخفية النهائية بطبقة كثيفة ، يمكن للشبكة إخراج توزيع احتمالي للكلمة التالية.
بالنسبة لبعض المهام ، لا يتمثل الهدف في توقع الكلمة التالية المفردة في التسلسل الحالي ؛ بدلاً من ذلك ، نرغب في توقع تسلسل مختلف تمامًا للكلمات يرتبط بطريقة ما بتسلسل الإدخال. بعض الأمثلة على هذا النمط من المهمة هي:
ترجمة اللغة
يتم تغذية الشبكة بسلسلة نصية في اللغة المصدر والهدف هو إخراج النص المترجم إلى لغة الهدف.
توليد الأسئلة
يتم تغذية الشبكة بمقطع من النص والهدف هو إنشاء سؤال قابل للتطبيق يمكن طرحه حول النص.
تلخيص النص
يتم تغذية الشبكة بمقطع طويل من النص والهدف هو إنشاء ملخص قصير للمقطع.
بالنسبة لهذه الأنواع من المشكلات ، يمكننا استخدام نوع من الشبكات يُعرف باسم شبكات الترميز فك الترميز (encoder–decoder network) . لقد رأينا بالفعل نوعًا واحدًا من شبكات الترميز – فك الترميز في سياق توليد الصور: متمثلة في شبكات الترميز التلقائي المتغيرة .
شبكات الترميز فك الترميز (encoder–decoder network)
بالنسبة للبيانات المتسلسلة ، تعمل شبكات الترميز – فك الترميز على النحو التالي:
1- يتم تلخيص تسلسل الإدخال الأصلي في متجه واحدة بواسطة المشفر RNN.
2- تستخدم هذا المتجه لتهيئة مفكك الترميز RNN.
3- الحالة المخفية لـ RNN لمفكك الترميز تتصل في كل خطوة زمنية بطبقة كثيفة تنتج توزيعًا احتماليًا على مفردات الكلمات. بهذه الطريقة ، يمكن لمفكك الترميز إنشاء تسلسل جديد للنص ، بعد أن تمت تهيئته بتمثيل بيانات الإدخال التي ينتجها المشفر .
تظهر هذه العملية في الصورة التالية ، في سياق الترجمة بين الإنجليزية والألمانية.

يمكن اعتبار الحالة المخفية النهائية للمشفر بمثابة تمثيل للمستند المدخل بالكامل. ثم يقوم المشفر بتحويل هذا التمثيل إلى إخراج متسلسل ، مثل ترجمة النص إلى لغة أخرى ، أو سؤال يتعلق بالمستند.
أثناء التدريب ، تتم مقارنة توزيع الإخراج الذي ينتجه المشفر في كل خطوة زمنية مقابل الكلمة التالية الحقيقية ، لحساب الخسارة. لا يحتاج المفكك إلى أخذ عينات من هذا التوزيع لتوليد الكلمات أثناء عملية التدريب ، حيث يتم تغذية الخلية اللاحقة بالكلمة التالية الحقيقة (ground-truth) ، بدلاً من كلمة مأخوذة من توزيع الإخراج السابق.
تُعرف طريقة تدريب شبكات المشفر و المفكك هذه باسم إجبار المعلم (teacher forcing). يمكننا أن نتخيل أن الشبكة عبارة عن طالب يقوم أحيانًا بتنبؤات توزيع خاطئة ، ولكن بغض النظر عن مخرجات الشبكة في كل خطوة زمنية ، يقدم المعلم الاستجابة الصحيحة كمدخل إلى الشبكة لمحاولة الكلمة التالية.
مولد سؤال وجواب (A Question and Answer Generator)
سنقوم الآن بتجميع كل شيء معًا وبناء نموذج يمكنه إنشاء أزواج من الأسئلة والأجوبة من كتلة نصية.
يتكون النموذج من جزأين:
- شبكة عصبية متكررة (RNN) الذي يحدد الإجابات المرشحة من كتلة النص.
- شبكة ترميز- فك ترميز تولد سؤالًا مناسبًا ، نظرًا لإحدى الإجابات المرشحة التي أبرزتها RNN
على سبيل المثال ،لدينا الافتتاحية التالية لمقطع نصي عن مباراة كرة قدم:
The winning goal was scored by 23-year-old striker Joe Bloggs during the match between Arsenal and Barcelona . Arsenal recently signed the striker for 50 million pounds . The next match is in two weeks time, on July 31st 2005 . “
نود أن تكون شبكتنا الأولى قادرة على تحديد الإجابات المحتملة مثل:
“Joe Bloggs”
“Arsenal”
“Barcelona”
“50 million pounds”
“July 31st 2005”
ويجب أن تكون شبكتنا الثانية قادرة على إنشاء سؤال ، مع الأخذ في الاعتبار كل من الإجابات ، مثل:
“Who scored the winning goal?”
“Who won the match?”
“Who were Arsenal playing?”
“How much did the striker cost?”
“When is the next match?”
دعنا أولاً نلقي نظرة على مجموعة البيانات التي سنستخدمها بمزيد من التفصيل.
مجموعة بيانات سؤال وجواب
سنستخدم مجموعة بيانات Maluuba NewsQA ، والتي يمكنك تنزيلها باتباع التعليمات على GitHub.
يجب وضع ملفات train.csv و test.csv و dev.csv الناتجة في المجلد ./data/qa/ كل هذه الملفات لها نفس التنظيم ، على النحو التالي:
معرف القصة (story_id)
معرّف فريد للقصة.
نص_القصة (story_text)
نص القصة (على سبيل المثال ، “هدف الفوز سجله المهاجم جو بلوجز البالغ من العمر 23 عامًا أثناء المباراة …”).
السؤال (question)
السؤال يمكن طرحه حول نص القصة (على سبيل المثال ، “كم كلف المهاجم؟”).
نطاقات عملة الأجوبة (answer_token_ranges)
موضع العملة في نص القصة (على سبيل المثال ، 24:27). قد تكون هناك نطاقات متعددة (مفصولة بفواصل) إذا ظهرت الإجابة عدة مرات في القصة.
تتم معالجة هذه البيانات الأولية و تعميلها (tokenized) بحيث يمكن استخدامها كمدخلات في نموذجنا. بعد هذا التحول ، تتكون كل ملاحظة في مجموعة التدريب من الميزات الخمس التالية:
عملات المستند (document_tokens)
نص القصة بعد التعميل (على سبيل المثال ، [1 ، 4633 ، 7 ، 66 ، 11 ، …]) ، مقطوع / مبطن (clipped/padded) بأصفار ليكون بطول المعيار أقصى طول للمستند (max_document_length) .
عملات الأسئلة المدخلة (question_input_tokens)
السؤال بعد التعميل (على سبيل المثال ، [2 ، 39 ، 1 ، 52 ، …]) ، مبطن بالأصفار ليكون بطول المعيار أقصى طول للسؤال (max_question_length )
عملات الأسئلة المخرجة (question_output_tokens)
السؤال بعد التعميل ، تمت إزاحته بخطوة زمنية واحدة (على سبيل المثال ، [39 ، 1 ، 52 ، 1866 ، …] ، مبطن بالأصفار ليكون بطول المعيار أقصى طول للسؤال (max_question_length )
أقنعة الإجابة (answer_masks)
مصفوفة قناع ثنائي لها الحجم [max_answer_length، max_document_length]. و القيمة [i، j] للمصفوفة هي 1 إذا كانت الكلمة ith للإجابة على السؤال موجودة في الكلمة jth من المستند و 0 بخلاف ذلك.
تسميات الإجابة (answer_labels)
متجه ثنائي بطول max_document_length (على سبيل المثال ، [0 ، 1 ، 1 ، 0 ، …]). العنصر i في المتجه هو 1 إذا كان بالإمكان اعتبار الكلمة i في المستند جزءًا من الإجابة و 0 بخلاف ذلك.
دعنا الآن نلقي نظرة على معمارية النموذج القادرة على إنشاء أزواج من الأسئلة والأجوبة من كتلة نصية معينة.
معمارية النموذج
توضح الصورة التالية معمارية النموذج الشاملة التي سنبنيها.
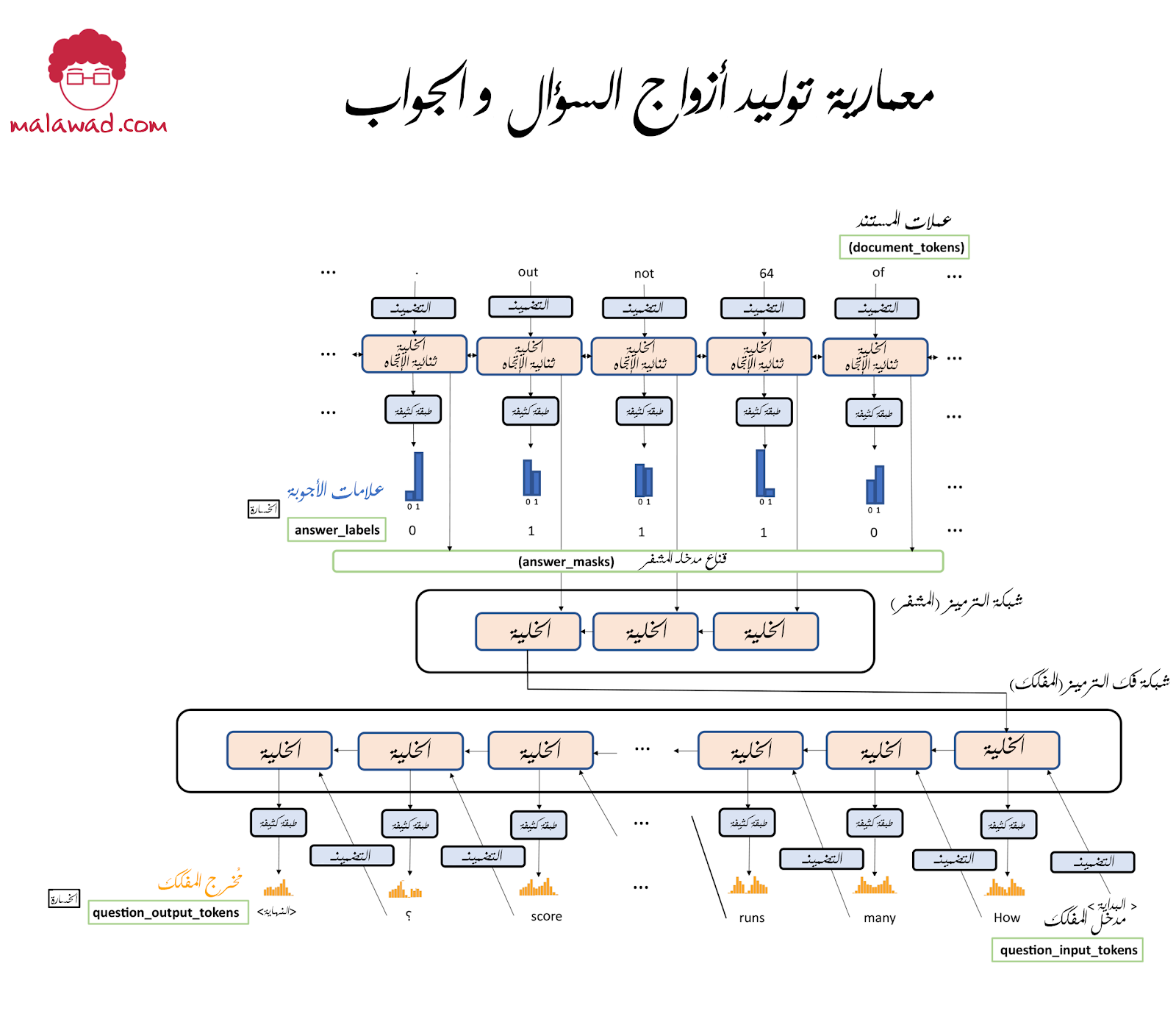
لنبدأ بإلقاء نظرة على كود Keras الذي يبني جزءًا من النموذج في أعلى الرسم التخطيطي ، والذي يتنبأ بما إذا كانت كل كلمة في المستند جزءًا من إجابة أم لا.
from keras.layers import Input, Embedding, GRU, Bidirectional, Dense, Lambda
from keras.models import Model, load_model
import keras.backend as K
from qgen.embedding import glove
#### PARAMETERS ####
VOCAB_SIZE = glove.shape[0] # 9984
EMBEDDING_DIMENS = glove.shape[1] # 100
GRU_UNITS = 100
DOC_SIZE = None
ANSWER_SIZE = None
Q_SIZE = None
document_tokens = Input(shape=(DOC_SIZE,), name="document_tokens") #1
embedding = Embedding(input_dim = VOCAB_SIZE, output_dim = EMBEDDING_DIMENS
, weights=[glove], mask_zero = True, name = 'embedding') #2
document_emb = embedding(document_tokens)
answer_outputs = Bidirectional(GRU(GRU_UNITS, return_sequences=True)
, name = 'answer_outputs')(document__emb) #3
answer_tags = Dense(2, activation = 'softmax'
, name = 'answer_tags')(answer_outputs) #4
1- يتم توفير علامات المستند كمدخلات في النموذج. هنا ، نستخدم المتغير DOC_SIZE لوصف حجم هذا الإدخال ، لكن المتغير مضبوط على None . هذا لأن معمارية النموذج لا تعتمد على طول تسلسل الإدخال – ستتكيف عدد الخلايا في الطبقة لتساوي طول تسلسل الإدخال ، لذلك لا نحتاج إلى تحديده بشكل صريح.
2- تتم تهيئة طبقة التضمين باستخدام متجهات كلمات العالمية GloVe.
3- الطبقة المتكررة هي الوحدات المتكررة ذات البوابات (GRU) ثنائية الاتجاه و التي تقوم بإرجاع الحالة المخفية في كل خطوة زمنية.
4- الطبقة الكثيفة المخرجة ترتبط بالحالة المخفية في كل خطوة زمنية ولديها وحدتان فقط ، مع تنشيط سوفت ماكس ، و يمثل احتمال أن تكون كل كلمة جزءًا من إجابة (1) أو ليست جزءًا من إجابة (0).
متجهات الكلمات GloVe
تتم تهيئة طبقة التضمين بمجموعة تضمينات الكلمات المدربة مسبقًا ، بدلاً من المتجهات العشوائية كما رأينا سابقًا. تم إنشاء متجهات الكلمات هذه كجزء من مشروع Stanford GloVe و التي تسمى المتجهات العالمي (Global Vectors) ، والذي يستخدم التعلم غير الخاضع للإشراف للحصول على متجهات تمثيلية لمجموعة كبيرة من الكلمات.
هذه المتجهات لها العديد من الخصائص المفيدة ، مثل تشابه المتجهات بين الكلمات المتصلة. على سبيل المثال ، المتجه بين التضمين للكلمتين رجل (man) وامرأة (woman) هو تقريبًا نفس المتجه بين الكلمتين الملك (king) والملكة (queen) . يبدو الأمر كما لو أن جنس الكلمة مشفر في الفضاء الكامن الذي توجد فيه متجهات الكلمة. غالبًا ما يكون تهيئة طبقة التضمين باستخدام GloVe أفضل من التدريب من البداية لأن الكثير من العمل الشاق لالتقاط تمثيل كلمة ما تم تحقيقه بالفعل من خلال عملية تدريب GloVe. يمكن أن تقوم الخوارزمية بعد ذلك بتعديل كلمة التضمينات لتناسب السياق المحدد لمشكلة التعلم الآلي لديك.
للعمل مع متجهات كلمات GloVe في حالتنا ، سنقوم بتنزيل ملف (glove.6B.100d.txt) من موقع مشروع GloVe ثم قم بتشغيل الملف النصي للقيام بقص هذا الملف ليشمل فقط الكلمات الموجودة في مجموعة التدريب:
python ./utils/write.py
الجزء الثاني من النموذج هو شبكة الترميز وفك الترميز التي تأخذ إجابة معينة وتحاول صياغة سؤال مطابق
encoder_input_mask = Input(shape=(ANSWER_SIZE, DOC_SIZE) , name="encoder_input_mask") #1 encoder_inputs = Lambda(lambda x: K.batch_dot(x[0], x[1]) , name="encoder_inputs")([encoder_input_mask, answer_outputs]) encoder_cell = GRU(2 * GRU_UNITS, name = 'encoder_cell')(encoder_inputs) #2 decoder_inputs = Input(shape=(Q_SIZE,), name="decoder_inputs") #3 decoder_emb = embedding(decoder_inputs) #4 decoder_emb.trainable = False decoder_cell = GRU(2 * GRU_UNITS, return_sequences = True, name = 'decoder_cell') decoder_states = decoder_cell(decoder_emb, initial_state = [encoder_cell]) #5 decoder_projection = Dense(VOCAB_SIZE, name = 'decoder_projection' , activation = 'softmax', use_bias = False) decoder_outputs = decoder_projection(decoder_states) #6 total_model = Model([document_tokens, decoder_inputs, encoder_input_mask] , [answer_tags, decoder_outputs]) answer_model = Model(document_tokens, [answer_tags]) decoder_initial_state_model = Model([document_tokens, encoder_input_mask] , [encoder_cell])
1- يتم تمرير قناع الإجابة كمدخل إلى النموذج – وهذا يسمح لنا بتمرير الحالات المخفية من نطاق إجابة واحده عبر شبكة الترميز وفك الترميز . يتم تحقيق ذلك باستخدام طبقة Lambda.
2- المشفر عبارة عن طبقة GRU يتم تغذيتها بالحالات المخفية لنطاق الإجابة المحدد كبيانات إدخال.
3- بيانات الإدخال إلى المفكك هي السؤال المطابق لنطاق الإجابة المحدد.
4- يتم تمرير العملات لكل كلمة سؤال من خلال نفس طبقة التضمين المستخدمة في نموذج تعريف الإجابة.
5- المفكك عبارة عن طبقة GRU ويتم تهيئتها بالحالة المخفية النهائية من المشفر.
6- يتم تمرير الحالات المخفية للمشفر من خلال طبقة كثيفة لتوليد توزيع على كامل المفردات للكلمة التالية في التسلسل.
هذا يكمل شبكتنا لتوليد زوج من الأسئلة والأجوبة. لتدريب الشبكة ، نقوم بتمرير نص المستند ونص السؤال وأقنعة الإجابة كبيانات إدخال على شكل حزم خسارة فقدان الانتروبيا التقاطعية (cross-entropy loss) في كل من توقع موضع الإجابة وتوليد كلمة السؤال ، موزونين بالتساوي.
الإستنباط (Inference)
لاختبار النموذج على تسلسل مستند مدخل جديد ، فالعملية كالأتي :
1- نقوم بتغذية سلسلة المستند إلى مولد الإجابات لإنتاج نماذج مواضع للإجابات في المستند.
2- نختار واحدة من مجموعات الإجابات و ننقلها إلى شبكة الترميز- فك الترميز لتوليد الأسئلة (على سبيل المثال ، نقوم بإنشاء قناع الإجابة المناسب).
3- نقوم بتغذية المستند وقناع الإجابة إلى المشفر لإنشاء الحالة الأولية للمفكك .
4- نقوم بتهيئة والمفكك بهذه الحالة الأولية وتغذيتها في العملة <البداية> لتوليد الكلمة الأولى من السؤال. نستمر في هذه العملية ، مع تغذية الكلمات التي تم إنشاؤها واحدة تلو الأخرى حتى يتم توقع العملة <النهاية > بواسطة النموذج.
أثناء التدريب ، يستخدم النموذج إجبار المعلم (teacher forcing) ليغذي الكلمات الحقيقة الأساسية (بدلاً من الكلمات التالية المتوقعة) إلى خلية المفكك. ومع ذلك ، أثناء التهيئة ، يجب على النموذج إنشاء سؤال من تلقاء نفسه ، لذلك نريد أن نكون قادرين على إعادة تغذية الكلمات المتوقعة إلى خلية المفكك مع الاحتفاظ بحالتها المخفية.
إحدى الطرق التي يمكننا من خلالها تحقيق ذلك هي تحديد نموذج Keras إضافي (نموذج_االسؤال) الذي يقبل عملة الكلمة الحالية والحالة المخفية للمفكك الحالي كمدخلات ، ويخرج توزيع الكلمة التالية المتوقع والحالة المخفية للمفكك المحدثة.
decoder_inputs_dynamic = Input(shape=(1,), name="decoder_inputs_dynamic")
decoder_emb_dynamic = embedding(decoder_inputs_dynamic)
decoder_init_state_dynamic = Input(shape=(2 * GRU_UNITS,)
, name = 'decoder_init_state_dynamic')
decoder_states_dynamic = decoder_cell(decoder_emb_dynamic
, initial_state = [decoder_init_state_dynamic])
decoder_outputs_dynamic = decoder_projection(decoder_states_dynamic)
question_model = Model([decoder_inputs_dynamic, decoder_init_state_dynamic]
, [decoder_outputs_dynamic, decoder_states_dynamic])
يمكننا بعد ذلك استخدام هذا النموذج في حلقة لتوليد سؤال الإخراج كلمة بكلمة ،
test_data_gen = test_data()
batch = next(test_data_gen)
answer_preds = answer_model.predict(batch["document_tokens"])
idx = 0
start_answer = 37
end_answer = 39
answers = [[0] * len(answer_preds[idx])]
for i in range(start_answer, end_answer + 1):
answers[idx][i] = 1
answer_batch = expand_answers(batch, answers)
next_decoder_init_state = decoder_initial_state_model.predict(
[answer_batch['document_tokens'][[idx]], answer_batch['answer_masks'][[idx]]])
word_tokens = [START_TOKEN]
questions = [look_up_token(START_TOKEN)]
ended = False
while not ended:
word_preds, next_decoder_init_state = question_model.predict(
[word_tokens, next_decoder_init_state])
next_decoder_init_state = np.squeeze(next_decoder_init_state, axis = 1)
word_tokens = np.argmax(word_preds, 2)[0]
questions.append(look_up_token(word_tokens[0]))
if word_tokens[0] == END_TOKEN:
ended = True
questions = ' '.join(questions)
Model Results
نتائج النموذج
يتم عرض نتائج العينة من النموذج في الصورة أدناه. يوضح الرسم البياني الموجود على اليمين احتمال أن تشكل كل كلمة في المستند جزءًا من الإجابة ، وفقًا للنموذج. يتم بعد ذلك تغذية عبارات الإجابات هذه إلى موللد الأسئلة ويظهر ناتج هذا النموذج على الجانب الأيسر من الرسم التخطيطي (“السؤال المتوقع”).
أولاً ، لاحظ كيف أن مولد الإجابات قادر على التحديد الدقيق للكلمات الموجودة في المستند التي من المرجح أن تكون موجودة في الإجابة. هذا مثير للإعجاب بالفعل نظرًا لأنه لم يسبق له رؤية هذا النص من قبل ، وربما لم ير بعض الكلمات من المستند المضمنة في الإجابة ، مثل Bloggs. إنه قادر على أن يفهم من السياق أنه من المحتمل أن يكون هذا هو اللقب لشخص ما وبالتالي من المحتمل أن يشكل جزءًا من الإجابة.

يستخرج المشفر السياق من كل من هذه الإجابات المحتملة ، بحيث يكون المفكك قادر على توليد أسئلة مناسبة. من اللافت للنظر أن المشفر قادر على التقاط أن الشخص المذكور في الإجابة الأولى ، المهاجم جو بلوجز البالغ من العمر 23 عامًا ، ربما يكون لديه سؤال مطابق يتعلق بقدراته على تسجيل الأهداف ، وهو قادر على تمرير هذا السياق إلى المفكك بحيث يمكن أن تولد السؤال “who scored the <UNK> ? ” بدلا من ، على سبيل المثال ، “who is the president ?”
المفكك انهى هذا السؤال مع العلامة <UNK>، ولكن ليس لأنه لا يعرف ما يجب القيام به بعد ذلك، بل بتوقع أن كلمة التالية من المرجح أن تكون من خارج المفردات الأساسية.
يمكننا أن نرى أنه في كل حالة ، يحتار المفكك “نوع” السؤال الصحيح – من ، وكم ، ومتى – اعتمادًا على نوع الإجابة. ومع ذلك ، لا تزال هناك بعض المشاكل ، مثل السؤال”how much money did he lose ? ” وليس “how much money was paid for the striker ?” هذا أمر مفهوم ، حيث المفكك لديه فقط حالة المشفر النهائية للعمل معها ولا يمكنه الرجوع إلى المستند الأصلي للحصول على معلومات إضافية.
هناك العديد من الامتدادات لشبكات الترميز – فك الترميز التي تعمل على تحسين الدقة والقدرة التوليدية للنموذج. اثنان من أكثر الشبكات المستخدمة على نطاق واسع هما شبكات المؤشرات (pointer networks) وآليات الانتباه (attention mechanisms) تمنح شبكات المؤشر النموذج القدرة على “الإشارة” إلى كلمات محددة في نص الإدخال لتضمينها في السؤال الذي تم إنشاؤه ، بدلاً من الاعتماد فقط على الكلمات الموجودة في المفردات المعروفة . وهذا يساعد على حل <UNK> المشكلة المذكورة في وقت سابق.
الأكواد المستخدمة على الغيتهاب













إضافة تعليق