
في هذه المقالة من سلسة شبكات الخصومة التوليدية سنتعرف على واحدة من أكثر تقنيات التعلم العميق استخدامًا ونجاحًا للبيانات المتسلسلة (sequential data) مثل النص هي شبكة الذاكرة طويلة قصيرة المدى (Long Short-Term Memory Network) أو بإختصار (LSTM).
شبكة LSTM هي نوع معين من الشبكات العصبية المتكررة (recurrent neural network) أو بإختصار (RNN). تحتوي شبكات RNN على طبقة (أو خلية) متكررة قادرة على التعامل مع البيانات المتسلسلة من خلال جعل إخراجها الخاص في خطوة زمنية معينة تشكل جزءًا من الإدخال إلى الخطوة الزمنية التالية ، بحيث يمكن أن تؤثر المعلومات من الماضي على التنبؤ في الوقت الحالي. نقول أن شبكة LSTM تعني شبكة عصبية ذات طبقة LSTM المتكررة.
عندما تم تقديم RNNs لأول مرة في الثمانينات (أحد الأوراق البحثية الأولى في هذه الفكرة) ، كانت الطبقات المتكررة بسيطة للغاية وتتألف فقط من عامل دالة زائدية (tanh) يضمن أن المعلومات التي تم تمريرها بين الخطوات الزمنية تم قياسها بين -1 و 1. ومع ذلك ، فقد تبين أنها تعاني من مشكلة تلاشي الإشتقاق (vanishing gradient) ولم تكن كذلك مقياس جيد لتسلسل طويل من البيانات.
تم تقديم خلايا LSTM لأول مرة في عام 1997 (الورقة البحثية)، يصف المؤلفون كيف لا تعاني LSTMs من نفس مشكلة تلاشي الإشتقاق التي تعاني منها شبكات RNN التقليدية ويمكن تدريبها على التسلسلات الطويلة المكونه من المئات من الخطوات.
منذ ذلك الحين ، تم تكييف وتحسين معماريية LSTM ، و اليوم يتم استخدام أحد تطوراتها المعروفة بأسم الوحدات المتكررة المحكومة ببوابات (gated recurrent units) أو بإختصار (GRUs) على نطاق واسع والمتاحة كطبقات في Keras .
لنبدأ بإلقاء نظرة على كيفية إنشاء شبكة LSTM بسيطة جدًا في Keras يمكنها إنشاء نص بأسلوب Aesop’s Fables.
إنشاء شبكة الذاكرة طويلة قصيرة المدى (LSTM)
كالعادة ، تحتاج أولاً إلى مجموعة بيانات. سنقوم بتنزيل مجموعة من أساطير إيسوب من مشروع جوتنبرج. هذه مجموعة من الكتب الإلكترونية المجانية التي يمكن تنزيلها كملفات نصية عادية. يعد هذا مصدرًا رائعًا للحصول على البيانات التي يمكن استخدامها لتدريب نماذج التعلم العميق القائمة على النصوص.
الآن سنلقي نظرة على الخطوات التي نحتاج إلى اتخاذها من أجل تنظيم و تهيئة البيانات بالشكل الصحيح لتدريب شبكة LSTM.
التعميل (Tokenization)
الخطوة الأولى هي تنظيف النص و تعميله . التعميل هو عملية تقسيم النص إلى وحدات فردية ، مثل الكلمات أو الأحرف.
تعتمد كيفية تعميل النص الخاص بك على ما تحاول تحقيقه باستخدام نموذج إنشاء النص. هناك إيجابيات وسلبيات لاستخدام عملة (Token) للكلمة أوالحرف ، وسيؤثر اختيارك على كيفية احتياجك لتهيئة النص قبل النمذجة و ما هو مخرج النموذج.
إذا كنت ستستخدم عملة الكلمات (Word Token ) :
- يمكن تحويل جميع النصوص إلى أحرف صغيرة (اللغة الإنجليزية) ، لضمان تعميل الكلمات ذات الأحرف الكبيرة في بداية الجمل بنفس الطريقة التي تظهر بها الكلمات نفسها في منتصف الجملة. ومع ذلك ، في بعض الحالات ، قد لا يكون هذا مرغوبًا ؛ على سبيل المثال ، قد تستفيد بعض الكلمات، مثل الأسماء أو الأماكن ، من الاحتفاظ بحروف كبيرة حتى يتم تعميلها بشكل مستقل.
- قد تكون مفردات النص (مجموعة الكلمات المميزة في مجموعة التدريب) كبيرة جدًا ، مع ظهور بعض الكلمات بشكل ضئيل جدًا أو ربما مرة واحدة فقط. قد يكون من الحكمة استبدال الكلمات المتفرقة بعملة لكلمة غير معروفة ، بدلاً من تضمينها كعملة منفصلة ، لتقليل عدد الأوزان التي تحتاج الشبكة العصبية إلى تعلمها.
- يمكن تجذير (stemming) الكلمات ، مما يعني أنه يتم اختزالها إلى أبسط أشكالها. على سبيل المثال (browse, browsing, browses, and browsed) كلها ستصبح (brows)
- ستحتاج إما إلى تعميل (tokenize) علامات الترقيم أو إزالتها تمامًا.
- يعني استخدام تعميل الكلمات (word tokenization) أن النموذج لن يكون قادرًا على التنبؤ بالكلمات خارج مفردات التدريب.
إذا كنت تستخدم عملة الأحرف (Letter Token ):
- قد يولد النموذج تسلسلات من الأحرف التي تشكل كلمات جديدة خارج مفردات التدريب – قد يكون هذا مرغوبًا في بعض السياقات ، ولكن ليس في سياقات أخرى.
- يمكن تحويل الأحرف الكبيرة إلى نظيراتها من الأحرف الصغيرة أو الاحتفاظ بها كرموز منفصلة.
- عادة ما تكون المفردات أصغر بكثير عند استخدام تعميل الأحرف، هذا مفيد لسرعة تدريب النموذج حيث يوجد عدد أقل من الأوزان للتعلم في طبقة الإخراج النهائية.
في هذا المثال ، سنستخدم تعميل الكلمات بحيث :
1- سنستحدم عملة (Token) الأحرف الصغيرة للكلمات (lowercase).
2- لن نقوم بتجذير الكلمات.
3- سنقوم أيضًا بإسخدام عملة علامات الترقيم ، حيث نرغب في أن يتنبأ النموذج بالوقت الذي ينبغي فيه إنهاء الجمل
4- أخيرًا ، بين كل قصة و أخرى في بيانات التدريب يوجد عدة أسطر فارغة سنقوم باستبدالها بالرمز ||||||||||||||| ، و في هذه الحالة عندما نقوم بالتدريب سنخبر النموذج أن هذا الرمز يعني أن عليه أن يبدأ قصة جديدة من الصفر .
برمجة عملية التنظيف و التعميل :
import re
from keras.preprocessing.text import Tokenizer
filename = "./data/aesop/data.txt"
with open(filename, encoding='utf-8-sig') as f:
text = f.read()
seq_length = 20
start_story = '| ' * seq_length
# CLEANUP
text = text.lower()
text = start_story + text
text = text.replace('\n\n\n\n\n', start_story)
text = text.replace('\n', ' ')
text = re.sub(' +', '. ', text).strip()
text = text.replace('..', '.')
text = re.sub('([!"#$%&()*+,-./:;<=>?@[\]^_`{|}~])', r' \1 ', text)
text = re.sub('\s{2,}', ' ', text)
# TOKENIZATION
tokenizer = Tokenizer(char_level = False, filters = '')
tokenizer.fit_on_texts()
total_words = len(tokenizer.word_index) + 1
token_list = tokenizer.texts_to_sequences()[0]
مقتطف من النص بعد التنظيف

يمكننا أن نرى قاموس العملات التي تم ربطها بقيمها الخاصة وأيضًا مقتطف من تعميل النص ، مع عرض الكلمات المقابلة باللون الأخضر.

بناء مجموعة البيانات
سيتم تدريب شبكة LSTM الخاصة بنا على التنبؤ بالكلمة التالية في تسلسل أرقام العملات ، مع الأخذ في الاعتبار تسلسل الكلمات التي تسبق هذه النقطة. على سبيل المثال ، يمكننا تغذية النموذج بالعملات التالية (the greedy cat and the) ونتوقع أن ينتج النموذج كلمة تالية مناسبة (على سبيل المثال ، dog ، بدلاً من in).
طول التسلسل الذي نستخدمه لتدريب النموذج هو معييار (parameter) لعملية التدريب. في هذا المثال ، اخترنا استخدام طول تسلسل 20 ، لذلك قمنا بتقسيم النص إلى أجزاء مكونة من 20 كلمة. يمكن إنشاء ما مجموعه 50416 من هذه التسلسلات ، لذا فإن مجموعة بيانات التدريب لدينا : X عبارة عن مصفوفة حجمها [50416 ، 20].
متغير الاستجابة لكل تسلسل هو الكلمة التالية ، تم إستخدام خط الترميز الأحادي (one-hot encoded) لوضعه في متجه طولها 4،169 (عدد الكلمات الموجوده في المفردات). لذلك ، استجابتنا y : هي مصفوفة ثنائية (binary) حجمها [50416 ، 4169].
و هنا مقتطف من برمجة توليد مجموعة البيانات
import numpy as np
from keras.utils import np_utils
def generate_sequences(token_list, step):
X = []
y = []
for i in range(0, len(token_list) - seq_length, step):
X.append(token_list[i: i + seq_length])
y.append(token_list[i + seq_length])
y = np_utils.to_categorical(y, num_classes = total_words)
num_seq = len(X)
print('Number of sequences:', num_seq, "\n")
return X, y, num_seq
step = 1
seq_length = 20
X, y, num_seq = generate_sequences(token_list, step)
X = np.array(X)
y = np.array(y
معمارية LSTM
تظهر معمارية النموذج العام في الصورة الأتية . مدخل النموذج عبارة عن سلسلة من أرقام العملات والمخرجات هي احتمالية ظهور كل كلمة في المفردات في التسلسل القادم . لفهم كيفية عمل هذا بالتفصيل ، نحتاج إلى تقديم نوعين جديدين من الطبقات ، طبقة التضمين (Embedding) و طبقة ذاكرة طويلة قصيرة المدى LSTM.

طبقة التضمين (Embedding Layer)
طبقة التضمين هي في الأساس جدول بحث يحول كل عملة إلى متجه بطول حجم التضمين (embedding_size) . وبالتالي ، فإن عدد الأوزان التي تعلمتها هذه الطبقة يساوي حجم المفردات ، مضروبًا في حجم التضمين.
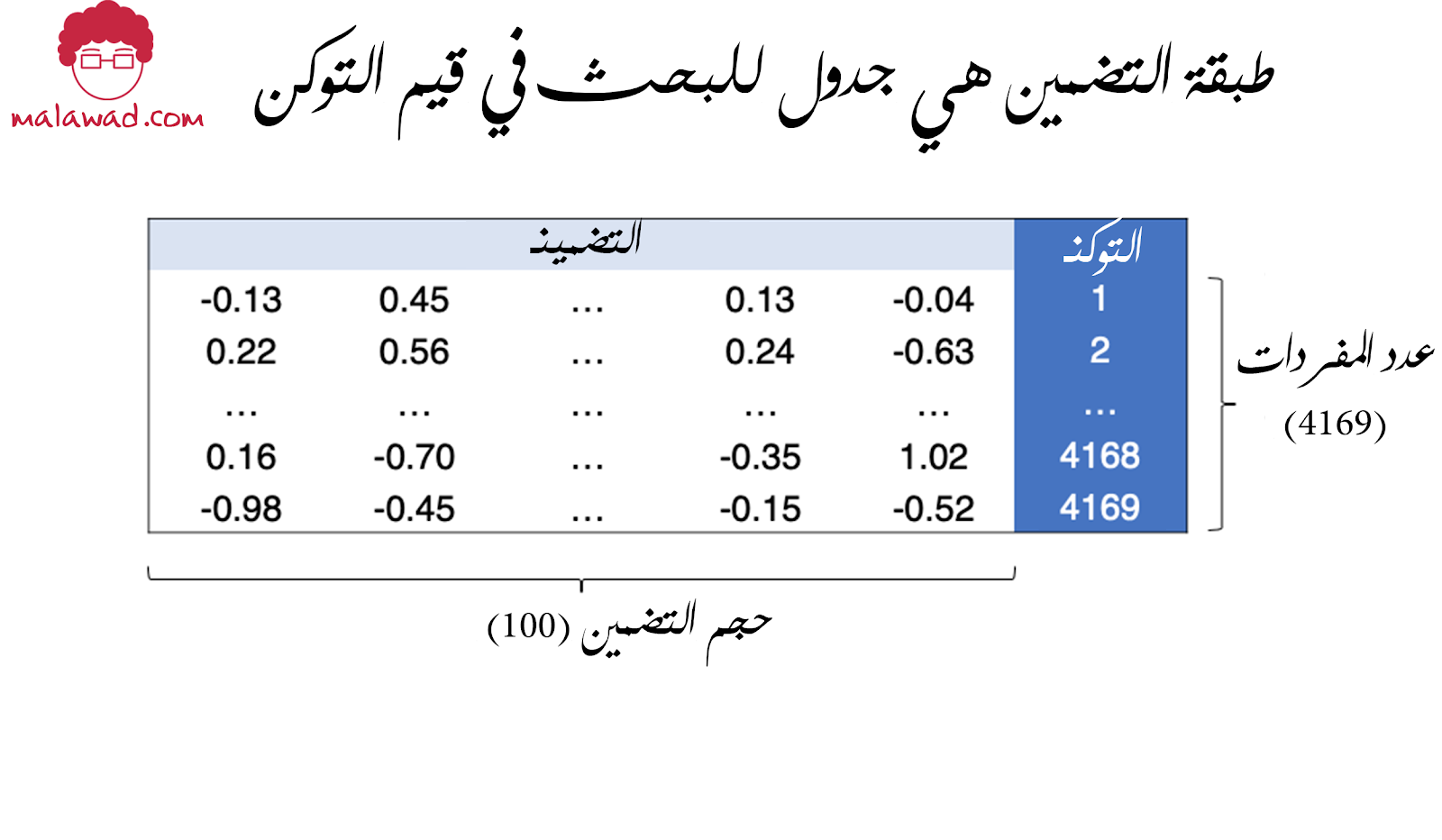
تمرر الطبقة المدخلة تنسور (tensor) من تسلسل أعدد صحيحة حجمها [حجم الحزمة ، طول التسلسل] إلى طبقة التضمين ، التي تُخرج تنسوراً أخر حجمه [حجم الحزمة ، طول التسلسل، حجم التضمين]. ثم يتم تمرير هذا إلى طبقة ذاكرة طويلة قصيرة المدى LSTM.
نقوم بتضمين كل عملة في متجه مستمرة (continuous vector) لأنها تُمكن النموذج من تعلم تمثيل لكل كلمة بحيث يمكن تحديثها من خلال عملية الإنتشار العكسي (backpropagation) .
يمكننا أيضًا إستخدام خط الترميز الأحادي (one-hot encoded) لكل عملة ، ولكن يفضل استخدام طبقة التضمين لأنه يجعل التضمين نفسه قابلاً للتدريب ، مما يمنح النموذج مزيدًا من المرونة في تحديد كيفية تضمين كل عملة لتحسين أداء النموذج.
طبقة ذاكرة طويلة قصيرة المدى LSTM.
لفهم طبقة LSTM ، يجب علينا أولاً أن ننظر في كيفية عمل الطبقة المتكررة (recurrent layer) العامة.
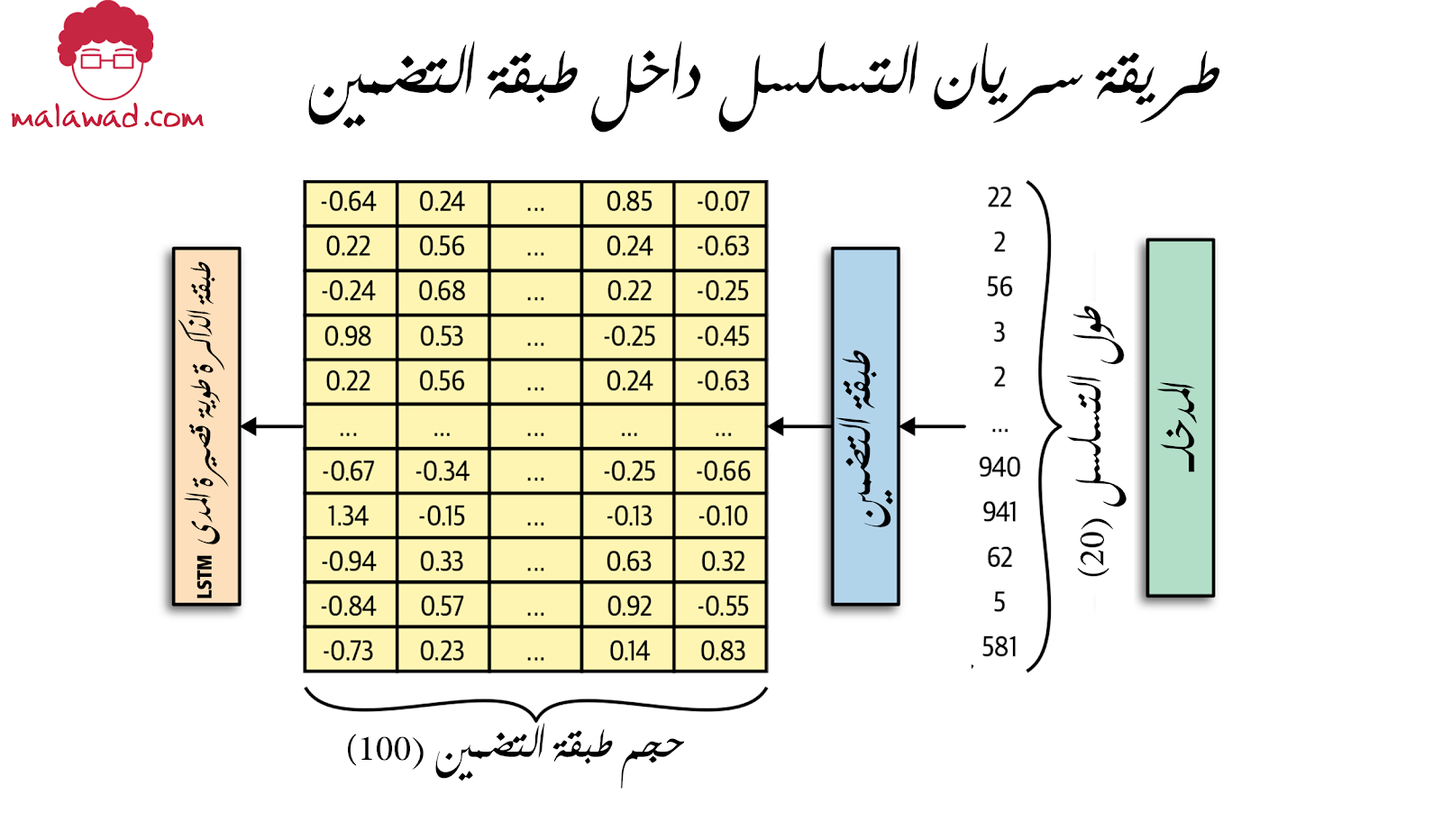
تتميز الطبقة المتكررة بخاصية خاصة تتمثل في قدرتها على معالجة بيانات الإدخال المتسلسلة [x1 ، … ، xn]. حيث تتكون من خلية تقوم بتحديث حالتها المخفية (hidden state) يرمز لها ht .
ويتم تمرير كل عنصر من عناصر التسلسل xt من خلاله ، مرة واحدة في كل مرة. الحالة المخفية عبارة عن متجه بطول يساوي عدد الوحدات في الخلية – يمكن اعتبارها بمثابة فهم الخلية الحالي للتسلسل.
في الخطوة الزمنية t ، تستخدم الخلية القيمة السابقة للحالة المخفية ht – 1 مع البيانات من الخطوة الزمنية الحالية xt لإنتاج متجه حالة مخفي محدثه ht.
تستمر هذه العملية المتكررة حتى نهاية التسلسل. بمجرد الانتهاء من التسلسل ، تُخرج الطبقة الحالة المخفية النهائية للخلية ، hn ، والتي يتم تمريرها بعد ذلك إلى الطبقة التالية من الشبكة.

لنرى كيف يتم تغذية تسلسل واحد من خلال الطبقة
هنا ، نمثل العملية المتكررة من خلال رسم نسخة من الخلية في كل خطوة زمنية وإظهار كيف يتم تحديث الحالة المخفية باستمرار أثناء سريانها عبر الخلايا. يمكننا أن نرى بوضوح كيف يتم مزج الحالة المخفية السابقة مع نقطة البيانات المتسلسلة الحالية (أي متجه كلمة التضمين الحالي) لإنتاج الحالة المخفية التالية.
الناتج من الطبقة هو الحالة المخفية النهائية للخلية ، بعد معالجة كل كلمة في تسلسل الإدخال. من المهم أن تتذكر أن جميع الخلايا في هذا الرسم البياني تشترك في نفس الأوزان (لأنها في الحقيقة نفس الخلية). لا يوجد فرق بين هذا الرسم البياني و الرسم البياني السابق. بل هي مجرد طريقة مختلفة لرسم ميكانيكا الطبقة المتكررة.
ملحوظة :
حقيقة أن الناتج من الخلية يسمى الحالة المخفية هو اصطلاح تسمية مؤسف – فهي ليس مخفيًا حقًا ، ولا يجب أن تفكر فيه على هذا النحو. في الواقع ، الحالة المخفية الأخيرة هي الناتج الإجمالي من الطبقة ، وسوف نستفيد من حقيقة أنه يمكننا الوصول إلى الحالة المخفية في كل خطوة زمنية فردية لاحقًا.
خلية الذاكرة طويلة قصيرة المدى LSTM
الآن وقد رأينا كيف تعمل الطبقة المتكررة ، دعنا نلقي نظرة داخل خلية LSTM الفردية.
وظيفة خلية LSTM هي إخراج حالة مخفية جديدة (ht) ، بالنظر إلى حالتها المخفية السابقة (ht – 1) ، و كلمة التضمين الحالية (xt) .
للتذكير، طول ht يساوي عدد الوحدات في LSTM. هذا هو المعامل الذي يتم تعيينه عند تحديد الطبقة وليس له علاقة بطول التسلسل. تأكد من أنك لا تخلط بين مصطلح الخلية (cell) والوحدة (unit) . توجد خلية واحدة في طبقة LSTM يتم تحديدها بعدد الوحدات التي تحتويها.
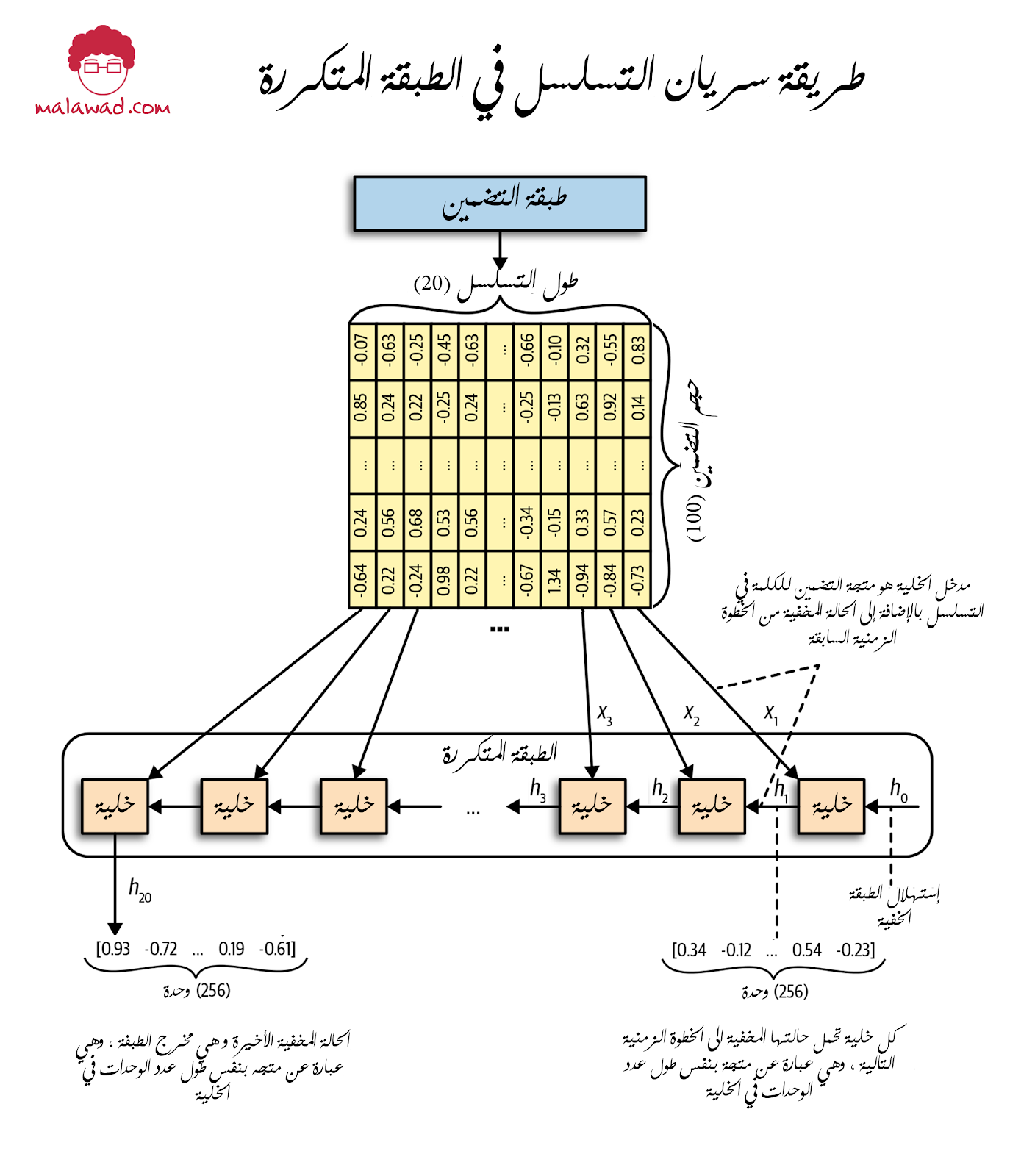
غالبًا ما نرسم الطبقة المتكررة (recurrent layer ) كسلسلة من الخلايا الغير ملتفة (unrolled) ، لأنها تساعد في تصور كيفية تحديث الحالة المخفية في كل خطوة زمنية.
تحتفظ خلية LSTM بحالة الخلية ( Ct) ، والتي يمكن اعتبارها المعتقدات الداخلية للخلية حول الحالة الحالية للتسلسل. هذا يختلف عن الحالة المخفية ( ht ) ، والتي يتم إخراجها في النهاية بواسطة الخلية بعد الخطوة الزمنية النهائية. حالة الخلية هي نفس طول الحالة المخفية (عدد الوحدات في الخلية).
لنلق نظرة عن كثب على خلية واحدة وكيف يتم تحديث الحالة المخفية.

يتم تحديث الحالة المخفية في ست خطوات:
1- الحالة المخفية للخطوة الزمنية السابقة ( ht – 1 ) و كلمة التضمين الحالية ( xt ) يتم إدخالهما كـمتجه متسلسلة (concatenated vector) و يتم تمريرهما عبر بوابة النسيان (forget gate). هذه البوابة هي ببساطة طبقة كثيفة ذات مصفوفة أوزان Wf ، وتحيز bf ، و دالة تنشيط سيغمويد. المتجه الناتج (ft) ، له طول يساوي عدد الوحدات في الخلية ويحتوي على قيم بين 0 و 1 تحدد مقدار حالة الخلية السابقة ( Ct – 1 ) التي يجب الاحتفاظ بها.
2- يتم أيضًا تمرير المتجه المتسلسله (concatenated vector) عبر بوابة إدخال (input gate) ، و مثل بوابة النسيان ، فهي عبارة عن طبقة كثيفة ذات مصفوفة أوزان Wi ، والتحيز bi ، و دالة تنشيط سيغمويد. الناتج من هذه البوابة ، له طول يساوي عدد الوحدات في الخلية ويحتوي على قيم بين 0 و 1 تحدد مقدار المعلومات الجديدة التي سيتم إضافتها إلى حالة الخلية السابقة ، Ct – 1.
3- يتم تمرير المتجه المتسلسلة (concatenated vector) من خلال طبقة كثيفة بمصفوفة أوزان Wc ، والتحيز bc ، ودالة تنشيط الظل الزائدي (tanh) لتوليد متجه ct و التي تحتوي على المعلومات الجديدة التي تفكر الخلية في الاحتفاظ بها. كما أن طولها يساوي عدد الوحدات في الخلية ويحتوي على قيم بين -1 و 1.
4-يتم ضرب عناصر ft و Ct – 1 ببعضمها وإضافتهما إلى حاصل ضرب عناصر it و ct . تمثل هذه العملية نسيان أجزاء من حالة الخلية السابقة ثم إضافة معلومات جديدة ذات صلة لإنتاج حالة الخلية المحدثة ، Ct.
5- يتم أيضًا تمرير المتجه المتسلسله الأصلي عبر بوابة الإخراج (output gate) وهي طبقة كثيفة ذات مصفوفة أوزان Wo ، والتحيز bo ، و دالة تنشيط سيغمويد، . المتجه الناتجة ، له طول يساوي عدد الوحدات في الخلية ويخزن القيم بين 0 و 1 التي تحدد مقدار حالة الخلية المحدثة ، Ct ، التي يجب تمريرها كمخرج .
6- يتم ضرب عناصر ot و Ct ببعضمها ، بعد تطبيق دالة تنشيط الظل الزائدي (tanh) لإنتاج الحالة المخفية الجديدة ht.
و هنا مقتطف من برمجة شبكة الذاكرة طويلة قصيرة المدى
from keras.layers import Dense, LSTM, Input, Embedding, Dropout from keras.models import Model from keras.optimizers import RMSprop n_units = 256 embedding_size = 100 text_in = Input(shape = (None,)) x = Embedding(total_words, embedding_size)(text_in) x = LSTM(n_units)(x) x = Dropout(0.2)(x) text_out = Dense(total_words, activation = 'softmax')(x) model = Model(text_in, text_out) opti = RMSprop(lr = 0.001) model.compile(loss='categorical_crossentropy', optimizer=opti) epochs = 100 batch_size = 32 model.fit(X, y, epochs=epochs, batch_size=batch_size, shuffle = True)
توليد نص جديد
الآن بعد أن قمنا بتجميع وتدريب شبكة LSTM ، يمكننا البدء في استخدامها لإنشاء سلاسل نصية طويلة من خلال تطبيق العملية التالية:
1- قم بتغذية الشبكة بتسلسل من الكلمات واطلب منها توقع الكلمة التالية.
2- إلحاق الجملة الناتجة بالتسلسل الموجود و كرر العملية.
ستخرج الشبكة مجموعة من الاحتمالات لكل كلمة يمكننا أخذ عينات منها. لذلك ، يمكننا أن نجعل إنشاء النص عشوائيًا (stochastic )، وليس حتميًا (deterministic) . علاوة على ذلك ، يمكننا تقديم معلمة معييار حرارة (temperature parameter) لعملية أخذ العينات للإشارة إلى مدى الحتمية التي نرغب في أن تكون عليها العملية.
def sample_with_temp(preds, temperature=1.0): #1
# helper function to sample an index from a probability array
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probs = np.random.multinomial(1, preds, 1)
return np.argmax(probs)
def generate_text(seed_text, next_words, model, max_sequence_len, temp):
output_text = seed_text
seed_text = start_story + seed_text #2
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0] #3
token_list = token_list[-max_sequence_len:] #4
token_list = np.reshape(token_list, (1, max_sequence_len))
probs = model.predict(token_list, verbose=0)[0] #5
y_class = sample_with_temp(probs, temperature = temp) #6
output_word = tokenizer.index_word[y_class] if y_class > 0 else ''
if output_word == "|": #7
break
seed_text += output_word + ' ' #8
output_text += output_word + ' '
1- تعمل هذه الدالة على وزن السجلات باستخدام عامل قياس الحرارة قبل إعادة تطبيق دالة السوفت ماكس. تجعل الحرارة القريبة من الصفر أخذ العينات أكثر حتمية (أي أنه من المحتمل جدًا اختيار الكلمة ذات الاحتمالية الأعلى) ، في حين أن درجة الحرارة 1 تعني أنه يتم اختيار كل كلمة مع الإحتمال المنتج بواسطة النموذج.
2- النص الأولي عبارة عن سلسلة من الكلمات التي ترغب في منحها للنموذج لبدء عملية الإنشاء (يمكن أن يكون فارغًا). هذا مُجهز مسبقًا بكتلة الأحرف التي نستخدمها للإشارة إلى بداية قصة (|||||||||||||||).
3- يتم تحويل الكلمات إلى قائمة العملات.
4- يتم الاحتفاظ بآخر العملات max_sequence_len فقط. يمكن لطبقة LSTM قبول أي طول للتسلسل كمدخلات ، ولكن كلما زاد طول التسلسل زاد الوقت الذي يستغرقه إنشاء الكلمة التالية ، لذلك يجب تحديد طول التسلسل.
5- يُخرج النموذج احتمالات أن تكون كل كلمة هي التالية في التسلسل.
6- يتم تمرير الاحتمالات من خلال دالة أخذ العينات لإخراج الكلمة التالية ، محددة بواسطة الحرارة.
7- إذا كانت الكلمة الناتجة هي العملة الخاصة بقصة البداية ، فإننا نتوقف عن إنشاء المزيد من الكلمات لأن النموذج هنا يخبرنا أنه يريد إنهاء هذه القصة وبدء القصة التالية!
8- بخلاف ذلك ، نلحق الكلمة الجديدة بالنص الأولي ، لتكون جاهزة للتكرار التالي للعملية التوليدية.
و هنا مثال على النص الناتج

هناك بعض الأمور التي يجب ملاحظتها حول هذين المقطعين:
أولاً ، كلاهما متشابه في الأسلوب الحكايات في مجموعة التدريب الأصلية. و كلاهما يبدأ بالعبارة المألوفة للشخصيات في القصة ، كما نلاحظ أن تم استخدام علامات الإقتباس للإشارة لحديث كل شخصية .
ثانيًا ، النص الذي تم إنشاؤه عند الحرارة = 0.2 أقل ميلًا إلى المغامرة ولكنه أكثر تماسكًا في اختيار الكلمات من النص الذي تم إنشاؤه عند الحرارة = 1.0 ، حيث تؤدي قيم الحرارة المنخفضة إلى أخذ عينات أكثر حتمية.
أخيرًا ، من الواضح أن كلا النصين لا يمثلين قصص متماسكة و مفهومة ، لأن شبكة LSTM لا تستطيع فهم المعنى الدلالي للكلمات التي تولدها. من أجل إنشاء مقاطع لها فرصة أكبر في أن تكون منطقية من الناحية اللغوية ، يمكننا إنشاء مولد نص بمساعدة الإنسان ، حيث يُخرج النموذج الكلمات العشرة الأولى بأعلى الاحتمالات ، ثم يعود الأمر في النهاية إلى الإنسان لاختيار الكلمة التالية من بين هذه القائمة. هذا مشابه للنص التنبئي في محرك غوغل و في الهاتف المحمول ، حيث يتم منحك اختيار بضع كلمات إكمالاُ لما كتبته بالفعل.
لتوضيح ذلك ، الصورة التالية توضح الكلمات العشر الأولى ذات أعلى احتمالات لاتباع التسلسلات المختلفة.

النموذج قادر على إنشاء توزيع مناسب للكلمة التالية الأكثر ترجيحًا عبر مجموعة من السياقات. على سبيل المثال ، على الرغم من أن النموذج لم يتم إخباره أبدًا عن أجزاء من الكلام مثل الأسماء والأفعال والصفات وحروف الجر ، إلا أنه قادر بشكل عام على فصل الكلمات إلى هذه الفئات واستخدامها بطريقة صحيحة نحويًا. يمكن أن يخمن أيضًا أن المقالة التي تبدأ قصة عن نسر (Eagle) من المرجح أن تكون an بدل من a
يوضح مثال علامات الترقيم من الصورة السابقة كيف أن النموذج حساس أيضًا للتغييرات الطفيفة في تسلسل الإدخال. في المقطع الأول (the lion said, ) ، يخمن النموذج أن علامات الإقتباس (“) هي التالية باحتمالية 98٪ ، بحيث تسبق الجملة الحوار المنطوق. ومع ذلك ، إذا قمنا بدلاً من ذلك بإدخال الكلمة التالية على أنها (and) ، فيمكنها فهم أن علامات الإقتباس غير مرجحة الآن ، حيث من المرجح أن تكون الجملة قد حلت محل الحوار وستستمر الجملة على الأرجح كنثر وصفي.
إمتدادات الشبكات العصبية المتكررة (RNN Extensions)
تعتبر الشبكة التي تحدثنا عنها حتى الأن مثالًا بسيطًا على كيفية تدريب شبكة LSTM على تعلم كيفية إنشاء نص بأسلوب معين. لكن هناك عدة امتدادات لهذه الفكرة.
الشبكات المتكررة المكدسة (Stacked Recurrent Networks)
احتوت الشبكة التي نظرنا إليها للتو على طبقة LSTM واحدة ، ولكن يمكننا أيضًا تدريب الشبكات مع طبقات LSTM المكدسة ، بحيث يمكن تعلم الميزات الأعمق من النص.
لتحقيق ذلك ، قمنا بتغيير معييار return_sequences داخل طبقة LSTM الأولى من False إلى True. هذا يجعل الطبقة تُخرج الحالة المخفية من كل خطوة زمنية ، بدلاً من مجرد الخطوة الزمنية النهائية. يمكن لطبقة LSTM الثانية بعد ذلك استخدام الحالات المخفية من الطبقة الأولى كبيانات إدخال.

وهنا نرى معمارية شبكة الذاكرة طويلة قصيرة المدى المكدسة
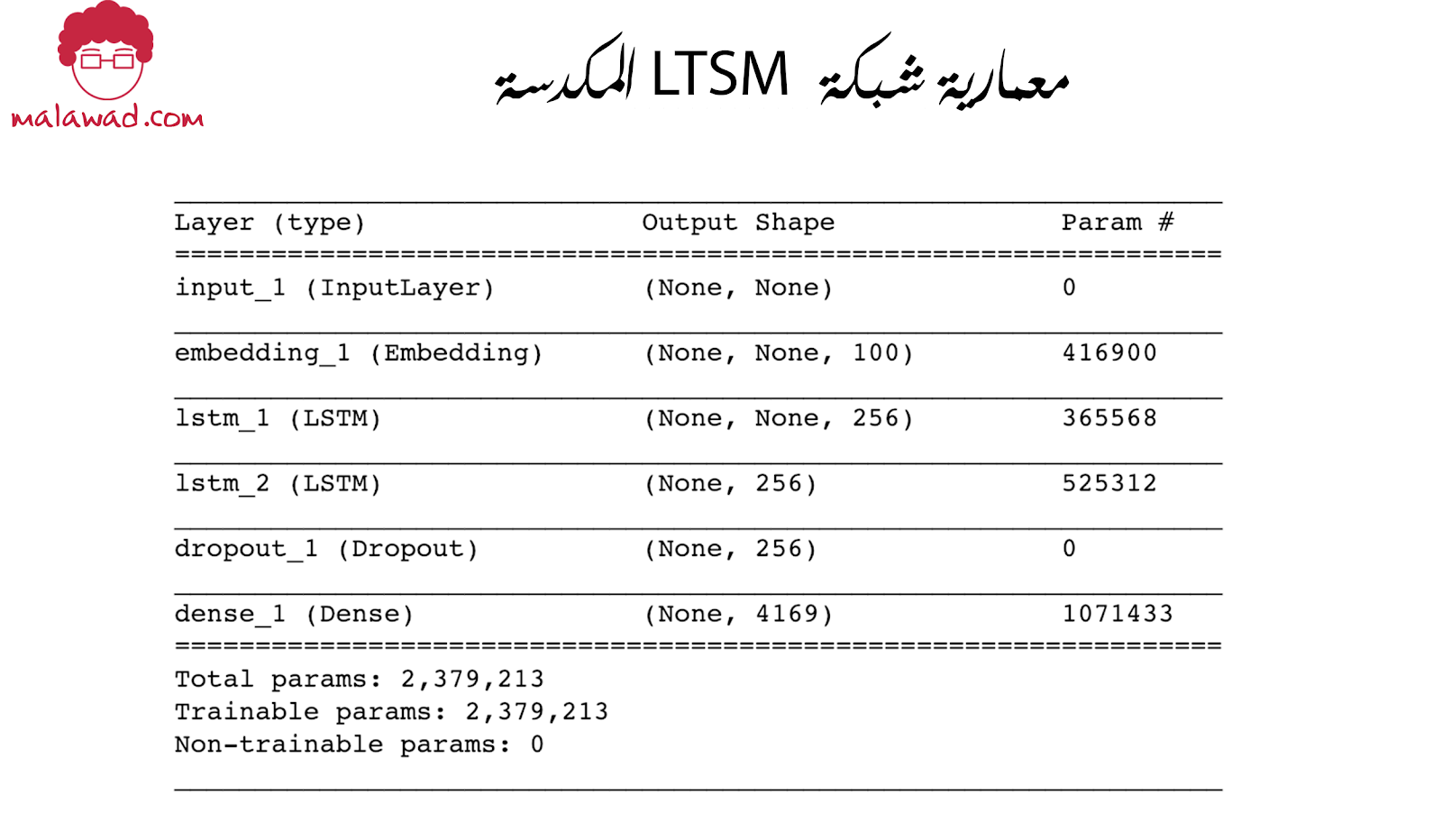
هنا طريقة برمجة معمارية شبكة LTSM المكدسة
text_in = Input(shape = (None,))
embedding = Embedding(total_words, embedding_size)
x = embedding(text_in)
x = LSTM(n_units, return_sequences = True)(x)
x = LSTM(n_units)(x)
x = Dropout(0.2)(x)
text_out = Dense(total_words, activation = 'softmax')(x)
model = Model(text_in, text_out)
الوحدات المتكررة ذات البوابات (Gated Recurrent Units)
نوع آخر من طبقة RNN شائعة الاستخدام هو الوحدات المتكررة ذات البوابات (GRU) الاختلافات الرئيسية عن وحدة LSTM هي كما يلي:
أولا : يتم استبدال بوابات النسيان والإدخال ببوابات إعادة الضبط والتحديث.
ثانياً : لا توجد حالة خلية أو بوابة إخراج ، فقط حالة مخفية يتم إخراجها من الخلية.
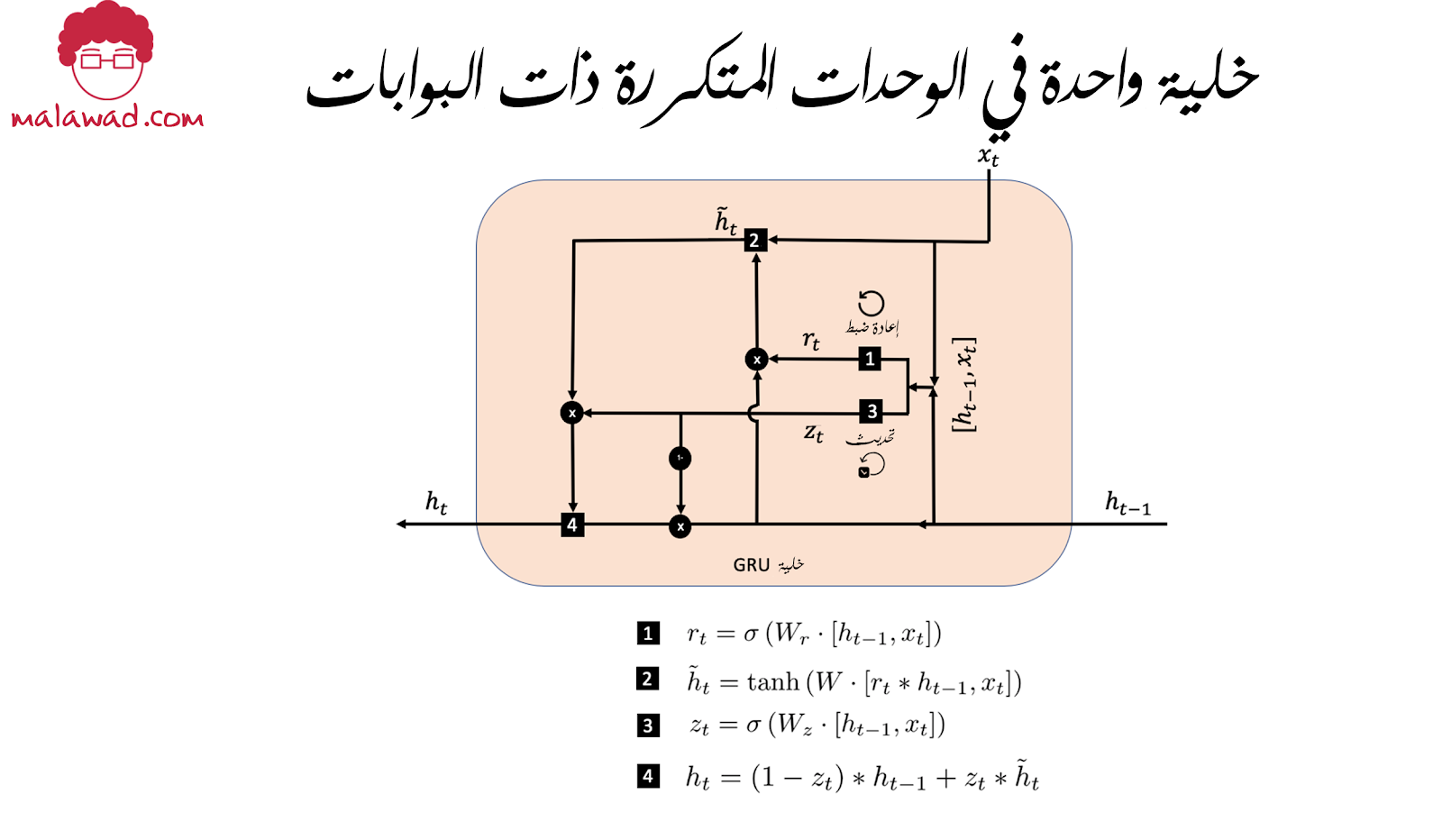
هذه العملية هي على النحو التالي:
1- الحالة المخفية للخطوة الزمنية السابقة ht – 1 ، و كلمة التضمين الحالية ( xt ) هي متجة متسلسلة وتستخدم لإنشاء بوابة إعادة الضبط (reset gate) . هذه البوابة عبارة عن طبقة كثيفة ، بها مصفوفة أوزان Wr و دالة تنشيط السيغمويد . المتجه الناتجه (rt) لها طول يساوي عدد الوحدات في الخلية وتخزن القيم بين 0 و 1 التي تحدد مقدار الحالة المخفية السابقة ht – 1 ، التي يجب أن يتم نقلها إلى الأمام في حساب الاعتقادات الجديدة للخلية.
2- يتم تطبيق بوابة إعادة الضبط على الحالة المخفية ht – 1 ، و سلسلتها مع تضمين الكلمة الحالية xt. يتم بعد ذلك تغذية هذا المتجه إلى طبقة كثيفة بمصفوفة أوزان W وودالة تنشيط الظل الزائدي (tanh) لتوليد متجه (ht) ، التي تخزن المعتقدات الجديدة للخلية. كما أن لها طول يساوي عدد الوحدات في الخلية وتخزن القيم بين -1 و 1.
3- يتم أيضًا استخدام ربط الحالة المخفية للخطوة الزمنية السابقة ht – 1 ، وكلمة التضمين الحالية xt ، لإنشاء بوابة التحديث (update gate) . هذه البوابة عبارة عن طبقة كثيفة مع مصفوفة أوزان Wz و دالة تنشيط السيغمويد. المتجه الناتجة ( zt ) ، لها طول يساوي عدد الوحدات في الخلية وتخزن القيم بين 0 و 1 ، والتي تُستخدم لتحديد مقدار المعتقدات الجديدة (ht) التي سيتم دمجها في الحالة المخفية الحالية ht – 1.
4-المعتقدات الجديدة للخلية (ht) و الحالة المخفية الحالية ht – 1 ، يتم دمجها بنسبة تحددها بوابة التحديث (zt) لإنتاج الحالة المخفية المحدثة ( ht) التي يتم إخراجها من الخلية.
الخلايا ثنائية الاتجاه (Bidirectional Cells)
بالنسبة لمشاكل التنبؤ حيث يكون النص بأكمله متاحًا للنموذج في وقت الاستدلال (inference time)، لا يوجد سبب لمعالجة التسلسل فقط في الاتجاه الأمامي — يمكن أيضًا معالجته بشكل عكسي. تستفيد الطبقة ثنائية الاتجاه من ذلك عن طريق تخزين مجموعتين من الحالات المخفية: واحدة يتم إنتاجها كنتيجة معالجة التسلسل في الاتجاه الأمامي المعتاد والأخرى التي يتم إنتاجها عند معالجة التسلسل للخلف. بهذه الطريقة ، يمكن للطبقة التعلم من المعلومات السابقة واللاحقة للخطوة الزمنية المحددة.
في Keras ، يتم تنفيذ ذلك كتغليف حول طبقة متكررة ، كما هو موضح هنا:
layer = Bidirectional(GRU(100))
الحالات المخفية في الطبقة الناتجة هي متجهات بطول يساوي ضعف عدد الوحدات في الخلية المغلفة (ربط (concatenation) بين الحالات المخفية للأمام والخلف). وبالتالي ، في هذا المثال ، تكون الحالات المخفية للطبقة متجهات بطول 200.
الخاتمة
إلى هنا نكون قد وصلنا إلى نهاية هذه المقالة و التي تعرفنا فيها على الطبقات المتككررة و شبكة الذاكرة طويلة قصيرة المدى.
برمجة الشبكة متوفرة على الغيتهاب













إضافة تعليق