
بعد أن تحدثنا عن الصعوبات التي عانت منها شبكات الخصومة التوليدية في المقال السابق ، سننتقل في حديثنا عن أحد التطورات الرئيسية المعروفة بأسم شبكة واسرستين الخصمية التوليدية ( Wasserstein GAN ) أو بإختصار Wgan التي أدت إلى تحسن الاستقرار العام لنماذج GAN بشكل كبير وتقليل احتمالية حدوث بعض المشكلات المذكورة سابقًا ، مثل انهيار الوضع.
شبكة واسرستين الخصمية التوليدية
كانت شبكة واسرستين الخصمية التوليدية ( Wasserstein GAN ) واحدة من أولى الخطوات الكبيرة نحو إسقرارية تدريب شبكات الخصومة التوليدية مع بعض التغييرات ، تمكن المؤلفون من إظهار كيفية تدريب GANs التي لها الخصائص التالية (مقتبسة من الورقة):
- مقياس خسارة ذو مغزى يرتبط بتقارب (convergence) المولد وجودة العينة.
- تحسين استقرار عملية التحسين.
على وجه التحديد ، تقدم الورقة دالة خسارة جديدة لكل من المميز والمولد. يؤدي استخدام دالة الخسارة هذه بدلاً من الانتروبيا الثنائية المتقاطعة (binary cross entropy) إلى تقارب أكثر استقرارًا لشبكة الخصومة التوليدية. دعونا نلقي نظرة على تعريف دالة خسارة واسرستين ( Wasserstein).
خسارة واسرستين
دعنا نذكر أنفسنا أولاً بخسارة الانتروبيا الثنائية المتقاطعة – الوظيفة التي نستخدمها حاليًا لتدريب المميّز والمولّد لـ GAN:
خسارة الانتروبيا الثنائية المتقاطعة

لتدريب مميّز شبكة الخصومة التوليدية D ، نحسب الخسارة عند مقارنة التنبؤات للصور الحقيقية ( pi=D(xi بالنسبة للاستجابة yi = 1 والتنبؤات للصور المولده ((pi=D(G(zi بالنسبة للاستجابة yi = 0. لذلك بالنسبة لمميز GAN ، يمكن كتابة تقليل دالة الخسارة على النحو التالي:
تقليل خسارة المميّز في شبكة الخصومة التوليدية
![\min _{D}-\left(\mathrm{E}_{x \sim p_{X}}[\log D(x)]+\mathrm{E}_{z \sim p z}[\log (1-D(G(z))])\right.](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-2f6f15663032a7547a0e028ab6777837_l3.png "Rendered by QuickLaTeX.com")
لتدريب مولد شبكة الخصومة التوليدية G، نحسب الخسارة عند مقارنة التنبؤات للصور المولدةpi=D(G(z)) i بالنسبة للاستجابة yi = 1. لذلك بالنسبة لمولد GAN ، يمكن كتابة تقليل دالةالخسارة على النحو التالي:
تقليل خسارة المولد في شبكة الخصومة التوليدية
![\min _{G}-\left(\mathbb{E}_{\boldsymbol{z} \sim p_{\mathcal{Z}}}[\log D(G(z)))\right]](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-65708fd376288db54d287d1ddbc783f4_l3.png "Rendered by QuickLaTeX.com")
الآن دعونا نقارن هذا دالة خسارة واسرستين.
دالة خسارة واسرستين
أولاً ، تتطلب خسارة واسرستين (Wasserstein ) أن نستخدم yi = 1 و yi = -1 كتصنيفات (labels) ، بدلاً من 1 و 0. نتخلص كذلك من دالة التنشيط السغمويد من الطبقة الأخيرة للمميز ، بحيث لا تكون التنبؤات pi مقيدة بالسقوط في النطاق [0،1] ، ولكن بدلاً من ذلك يمكن أن يكون الآن أي رقم في النطاق [–∞ ، ∞]. لهذا السبب ، يُشار عادةً إلى المُميِّز في WGAN على أنه ناقد (critic) . يتم بعد ذلك تعريف دالة خسارة واسرستين على النحو التالي:
خسارة واسرستين

لتدريب ناقد WGAN المسمى D، نحسب الخسارة عند مقارنة التنبؤات للصور الحقيقية ( pi=D(xi للاستجابة yi = 1 والتنبؤات للصور المولدة ((pi=D(G(zi للاستجابة yi = – 1. لذلك بالنسبة لناقد WGAN ، يمكن كتابة تقليل دالة الخسارة على النحو التالي:
تقليل خسارة ناقد WGAN
![\left.\min _{D}-\left(\mathbb{E}_{x \sim p x} \mid D(x)\right]-\mathbb{E}_{z \sim p z} \mid D(G(z))\right)](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-b2fa219e668c9fea3e091fae384d2f70_l3.png "Rendered by QuickLaTeX.com")
بمعنى آخر ، يحاول ناقد WGAN تعظيم الفرق بين تنبؤاته للصور الحقيقية والصور التي تم توليدها ، مع حصول الصور الحقيقية على نقاط أعلى .
لتدريب مولد WGAN ، نحسب الخسارة عند مقارنة التنبؤات للصور المولدة ((pi=D(G(z مع الاستجابة yi = 1. لذلك بالنسبة لمولد WGAN ، يمكن كتابة تقليل دالة الخسارة على النحو التالي:
تقليل خسارة مولد WGAN
![\min _{C}-\left(\mathbb{E}_{z \sim p_{Z}}[D(G(z))]\right)](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-ce01ad6e46f3f5f6ac09f99b77b63deb_l3.png "Rendered by QuickLaTeX.com")
تقيد ليبشيتز (The Lipschitz Constraint)
قد يفاجئك أننا نسمح الآن للناقد بإخراج أي رقم في النطاق [–∞ ، ∞] ، بدلاً من تطبيق دالة سيغمويد لتقييد الإخراج إلى النطاق المعتاد [0 ، 1]. لذلك يمكن أن تكون خسارة واسرستين (Wasserstein ) كبيرة جدًا ، وهو أمر مقلق – عادة ، يجب تجنب أرقام كبيرة في الشبكات العصبية!
في الواقع ، أظهر مؤلفو ورقة WGAN أنه لكي تعمل خسارة واسرستين، نحتاج أيضًا إلى وضع قيد إضافي على الناقد. على وجه التحديد ، من الضروري أن يكون الناقد هو الدالة المستمرة 1-Lipschitz. دعنا نبدأ الأن في تفصيل هذا
الناقد هو الدالة D التي تحول صورة إلى تنبؤ. نقول أن هذه الدالة هي 1-Lipschitz إذا كانت تحقق عدم المساواة التالية لأي صورتين إدخال ، x1 و x2:

هنا ، x1 – x2 هو متوسط الفرق المطلق بالنقاط الضوئية بين صورتين أما |(D(x1) – D(x2| هو الفرق المطلق بين تنبؤات الناقد. بشكل أساسي ، نطلب حدًا للمعدل الذي يمكن أن تتغير به تنبؤات الناقد بين صورتين (أي يجب أن تكون القيمة المطلقة للإشتقاق على الأكثر 1 في كل مكان).
يمكننا أن نرى هذا مطبقًا على دالة ليبشيتز المستمرة في الصورة أدناه حيث لا يدخل الخط في أي نقطة إلى المخروط ، أينما تضع المخروط على الخط. بعبارة أخرى ، هناك حد للمعدل الذي يمكن أن يرتفع عنده الخط أو ينخفض عند أي نقطة.
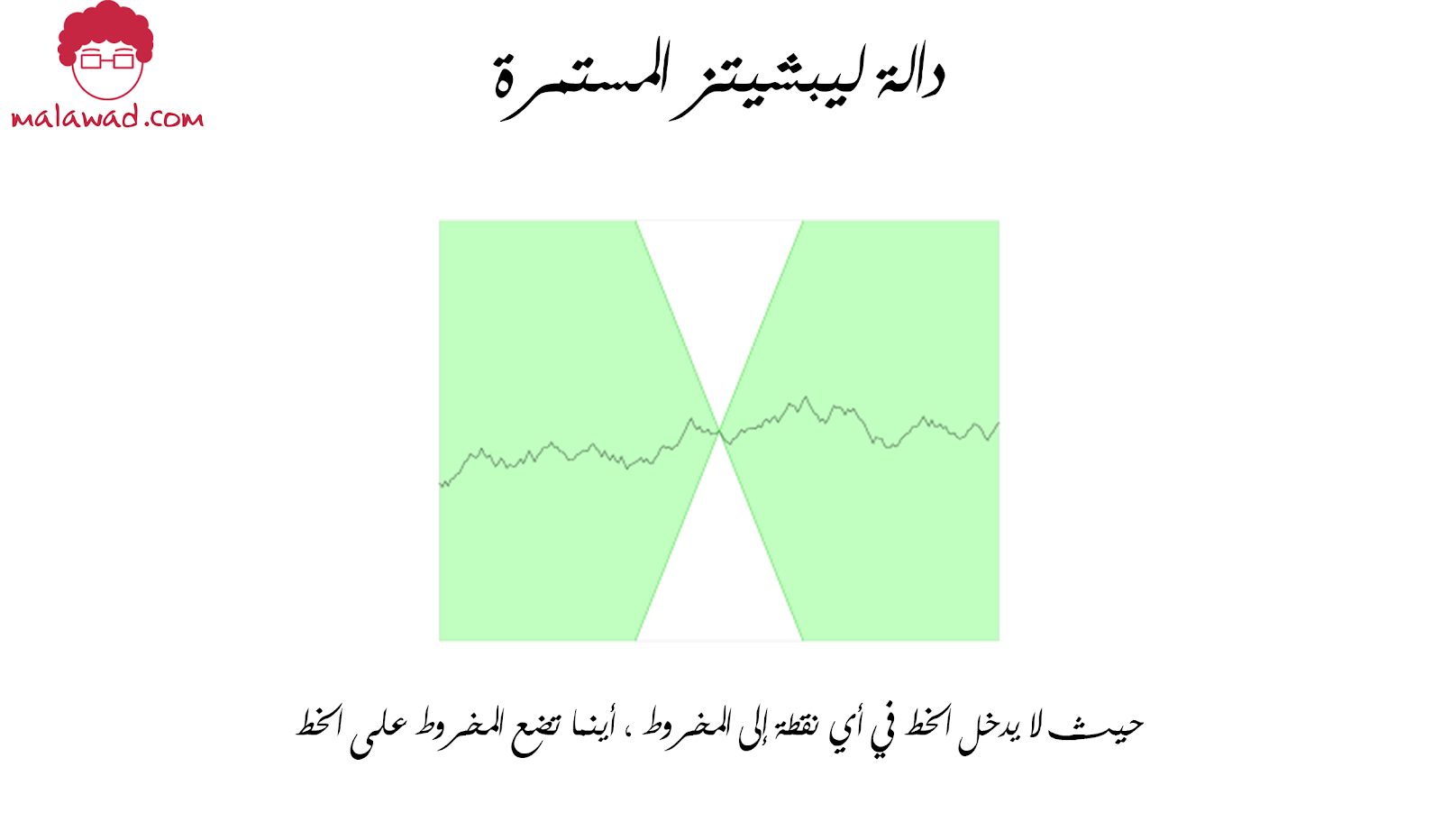
بالنسبة لأولئك الذين يريدون التعمق في الأساس المنطقي الرياضي وراء سبب نجاح خسارة واسرستين فقط عندما يتم فرض هذا القيد ، يمكنكم قراءة هذه المدونه.
قص الوزن
في ورقة WGAN ، يوضح المؤلفون كيف يمكن فرض قيود على Lipschitz عن طريق قص أوزان (Weight Clipping) الناقد ليقع ضمن نطاق صغير ، [–0.01 ، 0.01] ، بعد كل حزمة تدريب.
يمكننا تضمين عملية القص هذه في دالة تدريب ناقد WGAN الموضحة أدناه
def train_critic(x_train, batch_size, clip_threshold):
valid = np.ones((batch_size,1))
fake = -np.ones((batch_size,1))
# TRAIN ON REAL IMAGES
idx = np.random.randint(0, x_train.shape[0], batch_size)
true_imgs = x_train[idx]
self.critic.train_on_batch(true_imgs, valid)
# TRAIN ON GENERATED IMAGES
noise = np.random.normal(0, 1, (batch_size, self.z_dim))
gen_imgs = self.generator.predict(noise)
self.critic.train_on_batch(gen_imgs, fake)
for l in critic.layers:
weights = l.get_weights()
weights = [np.clip(w, -clip_threshold, clip_threshold) for w in weights]
l.set_weights(weights)
تدريب WGAN
عند استخدام وظيفة خسارة واسرستين ، يجب أن ندرب الناقد على التقارب للتأكد من دقة الاشتقاقات في تحديث المولد. هذا على خلاف GAN التقليدية، حيث كان من المهم عدم جعل المميز قوية جدًا ، لتجنب تلاشي الإشتقاقات (vanishing gradients) .
لذلك ، فإن استخدام خسارة واسرستين يزيل إحدى الصعوبات الرئيسية لتدريب شبكات GAN – كيفية الموازنة بين تدريب المميز والمولد. باستخدام WGANs ، يمكننا ببساطة تدريب الناقد عدة مرات بين تحديثات المولد ، للتأكد من أنه قريب من التقارب. النسبة النموذجية المستخدمة هي خمسة تحديثات للناقد لكل تحديث للمولد.
يتم عرض حلقة التدريب الخاصة بشبكة WGAN أدناه :
for epoch in range(epochs):
for _ in range(5):
train_critic(x_train, batch_size = 128, clip_threshold = 0.01)
train_generator(batch_size)
سنقوم بتدريب شبكة واسرستين الخصمية التوليدية على إنشاء صور للخيول من مجموعة بيانات ، وهنا بعض العينات التي تم إنشاؤها بواسطة WGAN.

WGAN قامت بعمل جيد في تحديد الميزات الرئيسية لصور الحصان (الأرجل ، السماء ، العشب ، اللون البني ، الظل ، إلخ). بالإضافة إلى الصور الملونة ، هناك أيضًا العديد من الزوايا والأشكال والخلفيات المختلفة التي يمكن لـ WGAN التعامل معها في مجموعة التدريب. لذلك ، في حين أن جودة الصورة ليست مثالية بعد ، يجب أن يشجعنا حقيقة أن WGAN لدينا يتعلم بوضوح السمات عالية المستوى التي تشكل صورة ملونة للحصان.
الخاتمه
لقد قمنا الآن بتغطية جميع الاختلافات الرئيسية بين GAN قياسي و WGAN. و الخلاصة :
- يستخدم WGAN خسارة Wasserstein.
- تم تدريب WGAN باستخدام التصنيفين 1 للحقيقي و -1 للمزيف.
- ليست هناك حاجة لتنشيط السيغمويد في الطبقة الأخيرة من ناقد WGAN.
- قص اوزان الناقد بعد كل تحديث.
- تدريب الناقد عدة مرات لكل تحديث للمولد.
أحد الانتقادات الرئيسية لشبكة WGAN هو أنه نظرًا لأننا نقوم بقص الأوزان في الناقد ، فإن قدرته على التعلم تتضاءل بشكل كبير. في الواقع ، حتى في ورقة WGAN الأصلية ، كتب المؤلفون ، “من الواضح أن اقتطاع الوزن طريقة سيئة لفرض قيود Lipschitz.”
يعتبر الناقد القوي أمرًا محوريًا لنجاح WGAN ، لأنه بدون تدرجات دقيقة ، لا يمكن للمولد تعلم كيفية تكييف أوزانه لإنتاج عينات أفضل. لذلك ، بحث باحثون آخرون عن طرق بديلة لفرض قيود Lipschitz وتحسين قدرة WGAN على تعلم الميزات المعقدة. سنتعرف على أحدها في المقال التالي .
رابط الدفتر على غيتهاب













إضافة تعليق