
بالنسبة لمعظم الاقتصادات المتقدمة ، تمثل الرعاية الصحية جزءًا كبيرًا من الناتج المحلي الإجمالي ، وغالبًا ما يتجاوز 10 ٪. نظرًا لكونه شريحة كبيرة ، فهناك فوائد هائلة لأتمتة هذه العمليات والأنظمة وتحسينها ، وهنا يأتي دور معالجة اللغة الطبيعية. تشمل الرعاية الصحية كصناعة كلاً من السلع (أي الأدوية والمعدات) والخدمات (الاستشارة أو الاختبارات التشخيصية) للرعاية العلاجية والوقائية والتسكينية والتأهيلية.
يوضح الشكل أدناه من Chilmark Research مجموعة من التطبيقات التي تساعد فيها معالجة اللغة الطبيعية.
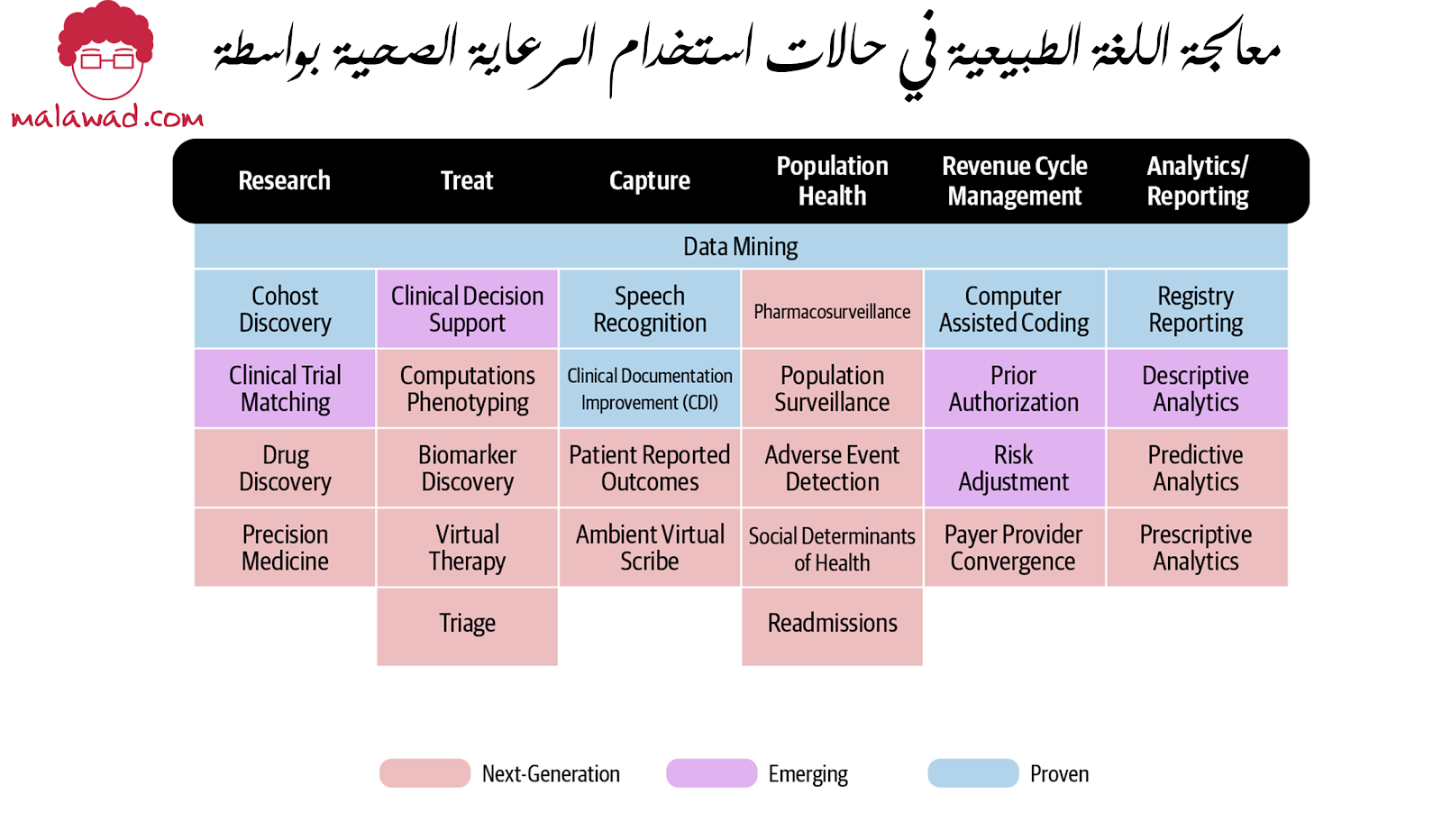
يُظهر كل عمود المجال الواسع ، مثل البحث السريري أو إدارة دورة الإيرادات. تُظهر الخلايا الزرقاء التطبيقات المستخدمة حاليًا ، والخلايا الأرجوانية هي تطبيقات ناشئة ويتم اختبارها ، والخلايا الحمراء هي الجيل القادم وستكون قابلة للتطبيق عمليًا في أفق زمني أطول.
تتعامل الرعاية الصحية مع كميات كبيرة من النصوص غير المهيكلة ، ويمكن استخدام معالجة اللغة الطبيعية في مثل هذه الأماكن لتحسين النتائج الصحية.
تشمل المجالات الواسعة التي يمكن أن تساعد فيها معالجة اللغة الطبيعية ، على سبيل المثال ، تحليل السجلات الطبية والفواتير وضمان سلامة الأدوية. في الأقسام التالية سنغطي بإيجاز بعض هذه التطبيقات.
السجلات الصحية والطبية
غالبًا ما يتم جمع نسبة كبيرة من البيانات الصحية والطبية وتخزينها في تنسيقات نصية غير منظمة. يتضمن ذلك الملاحظات الطبية والوصفات الطبية والنصوص الصوتية ، بالإضافة إلى تقارير علم الأمراض والأشعة. يظهر مثال على مثل هذا السجل في الشكل أدناه.

يؤدي ذلك إلى صعوبة البحث عن البيانات وتنظيمها ودراستها وفهمها في شكلها الأولي. يتفاقم هذا بسبب الافتقار إلى التوحيد القياسي في كيفية تخزين البيانات. يمكن أن يساعد معالجة اللغة الطبيعية (NLP) الأطباء في البحث عن هذه البيانات وتحليلها بشكل أفضل وحتى أتمتة بعض مهام سير العمل ، مثل إنشاء أنظمة تلقائية للإجابة على الأسئلة لتقليل الوقت للبحث عن معلومات المريض ذات الصلة.
تحديد أولويات المريض والفواتير
يمكن استخدام تقنيات معالجة اللغة الطبيعية في ملاحظات الطبيب لفهم حالتها وضرورة إعطاء الأولوية للإجراءات الصحية والفحوصات المختلفة. يمكن أن يقلل هذا من التأخير والأخطاء الإدارية وأتمتة العمليات. وبالمثل ، فإن تحليل واستخراج المعلومات من الملاحظات غير المنظمة لتحديد الرموز الطبية يمكن أن يسهل عملية إعداد الفواتير.
اليقظة الدوائية (Pharmacovigilance)
وهي جميع الأنشطة اللازمة للتأكد من أن الدواء آمن. وهذا يشمل جمع وكشف ورصد التفاعلات العكسية للأدوية . يمكن أن يكون لإجراء طبي أو دواء آثار غير مقصودة أو ضارة ، ومن الضروري مراقبة هذه الآثار ومنعها للتأكد من أن الدواء يعمل على النحو المنشود.
مع زيادة استخدام وسائل التواصل الاجتماعي ، يتم ذكر المزيد من هذه الآثار الجانبية في رسائل وسائل التواصل الاجتماعي ؛ مراقبة وتحديد هذه هي جزء من الحل. قمنا بتغطية بعض هذه التقنيات في مقال سابق ، والذي ركز على التحليل العام لوسائل التواصل الاجتماعي. إلى جانب وسائل التواصل الاجتماعي ، تسهل تقنيات معالجة اللغة الطبيعية المطبقة على السجلات الطبية أيضًا التيقظ الدوائي.
أنظمة دعم القرار السريري
تساعد أنظمة دعم القرار العاملين في المجال الطبي في اتخاذ القرارات المتعلقة بالرعاية الصحية. وتشمل هذه الفحوصات والتشخيص والعلاج والمراقبة. يمكن استخدام البيانات النصية المختلفة كمدخلات لهذه الأنظمة ، بما في ذلك السجلات الصحية الإلكترونية ، ونتائج المختبر المجدولة بالعمود ، والملاحظات العملية. يتم استخدام معالجة اللغة الطبيعية في كل هذه لتحسين أنظمة دعم القرار.
مساعدي الصحة
يمكن للمساعدين الصحيين وروبوتات المحادثة تحسين تجارب المريض ومقدمي الرعاية باستخدام جوانب مختلفة من الأنظمة الخبيرة و معالجة اللغة الطبيعية. على سبيل المثال ، يمكن لخدمات مثل Woebot أن تحافظ على معنويات المرضى الذين يعانون من الأمراض العقلية والاكتئاب مرتفعة. يجمع Woebot بين معالجة اللغة الطبيعية والعلاج المعرفي للقيام بذلك عن طريق طرح أسئلة ذات صلة تعزز الأفكار الإيجابية.
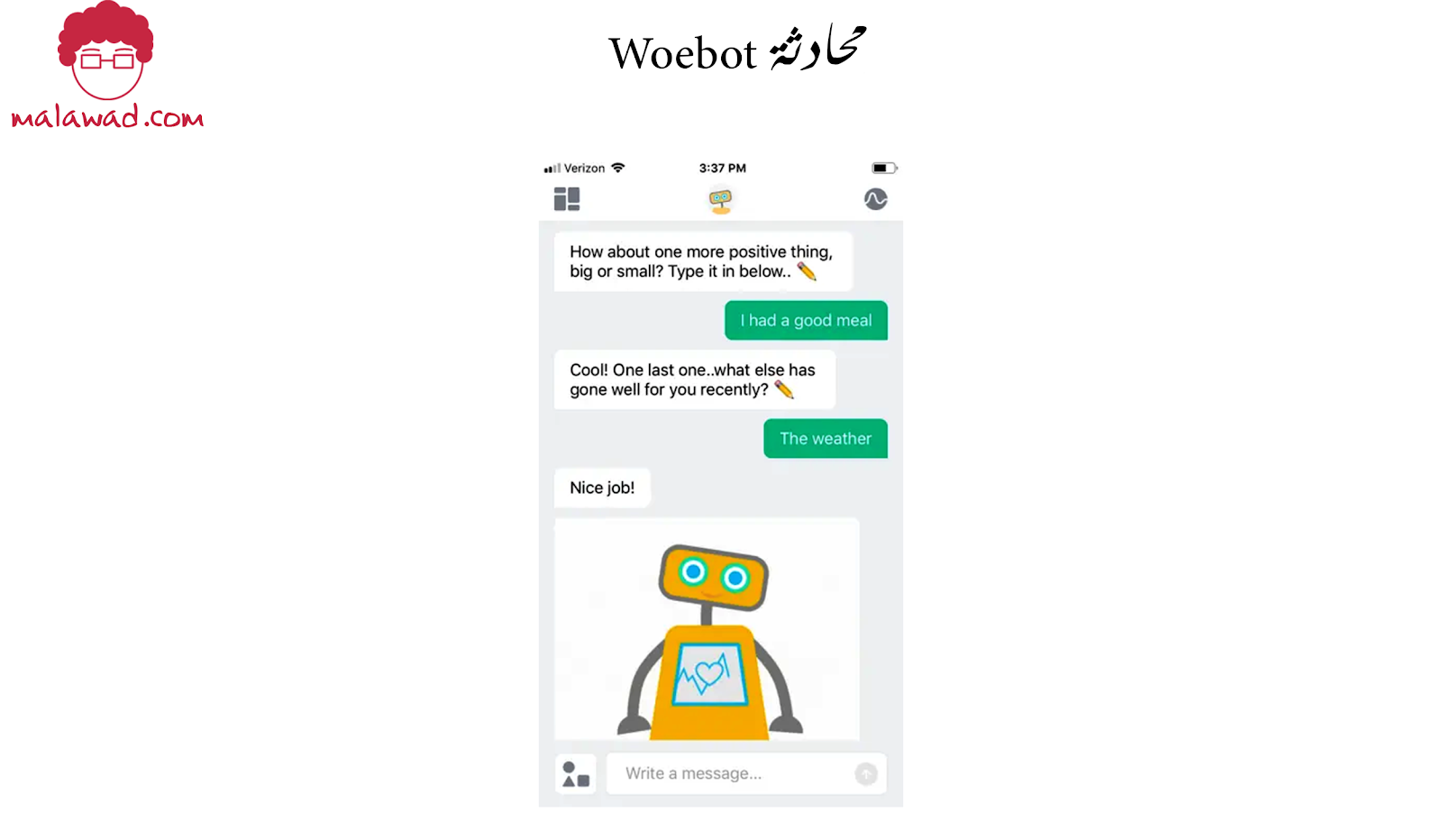
وبالمثل ، يمكن للمساعدين تقييم أعراض المرضى لتشخيص المشكلات الطبية المحتملة. اعتمادًا على الطابع الملح والحرج للتشخيصات ، يمكن لبرامج الدردشة الآلية حجز المواعيد مع الأطباء المعنيين. أحد الأمثلة على مثل هذا النظام هو Buoy يمكن أيضًا إنشاء هذه الأنظمة بناءً على احتياجات المستخدم المحددة من خلال استخدام أطر التشخيص الحالية.
أحد الأمثلة على مثل هذا الإطار هو Infermedica ، حيث يمكن لواجهة الدردشة أن تثير أعراضًا من المستخدم بالإضافة إلى تقديم قائمة بالأمراض المحتملة مع احتمالية حدوثها.

السجلات الصحية الإلكترونية
أدت زيادة اعتماد تخزين البيانات السريرية وبيانات الرعاية الصحية إلكترونيًا إلى انفجار في البيانات الطبية والسجلات الشخصية الكبيرة للغاية. مع هذا الاعتماد المتزايد وحجم المستند وتاريخه الأكبر ، أصبح من الصعب على الأطباء والموظفين السريريين الوصول إلى هذه البيانات ، مما يؤدي إلى زيادة المعلومات. وهذا بدوره يؤدي إلى المزيد من الأخطاء والإغفالات والتأخير ويؤثر على سلامة المرضى.
هارفست: فهم التقارير الطويلة
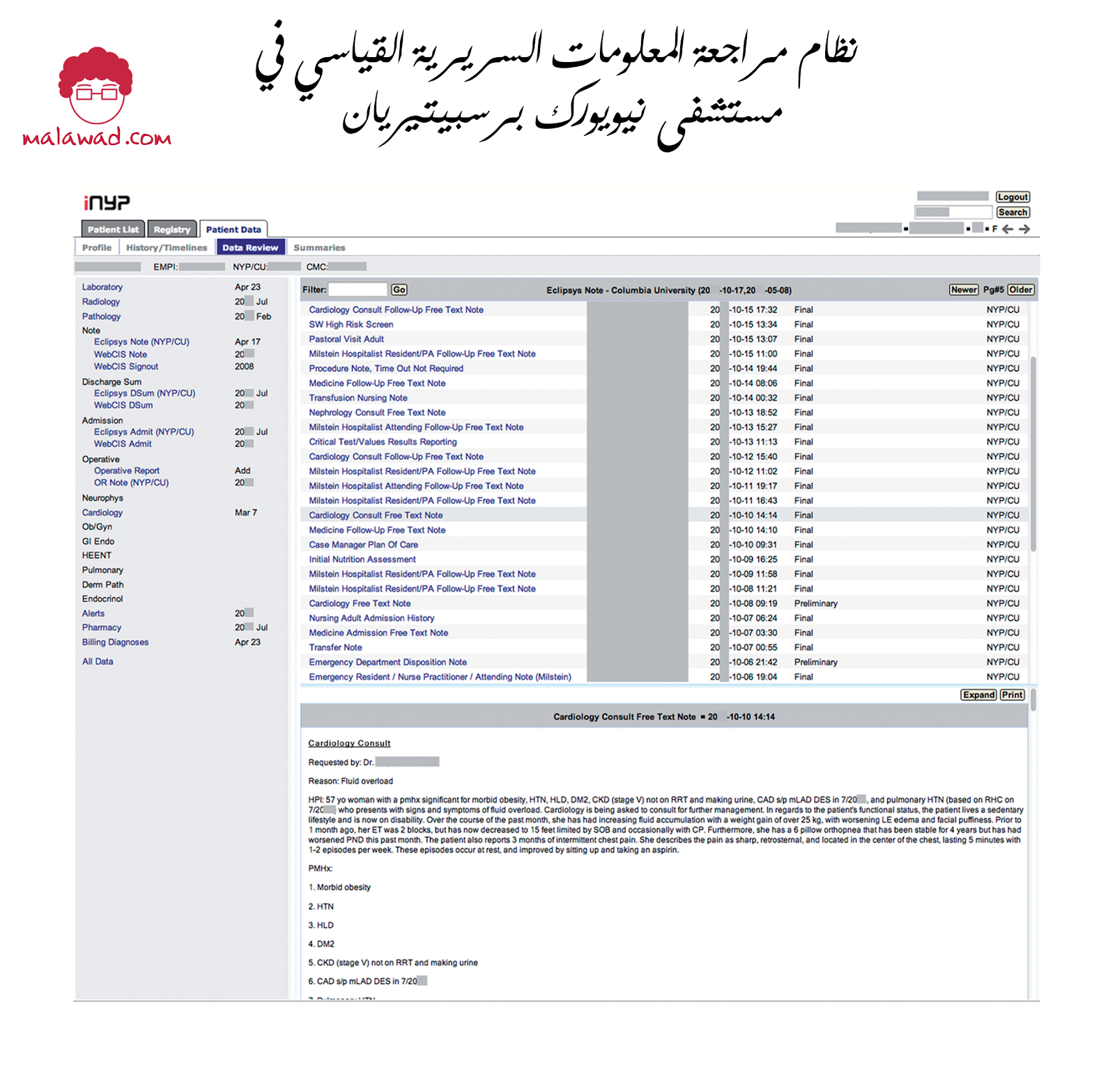
تم إنشاء أدوات مختلفة للتغلب على الحمل المعلوماتي الزائد الذي ذكرناه سابقًا. إحداها يسمى HARVEST من جامعة كولومبيا. تم استخدام الأداة على نطاق واسع عبر المستشفيات في مدينة نيويورك. ومع ذلك ، في البداية ، نحتاج إلى تغطية كيفية عمل نظام المعلومات السريرية القياسي.
يوضح الشكل أدناه لقطة شاشة لنظام مراجعة معلومات سريرية قياسي يتم استخدامه في مستشفى نيويورك المشيخي (iNYP). يقدم iNYP تقارير مليئة بالنصوص ، وكثيفة ، ومستهلكة للوقت ، وغير عملية بشكل عام. هناك خيار للبحث الأساسي عن النص ، ولكن المعلومات مليئة بالنصوص ، وهو ما يمثل عائقًا في سياق بيئة المستشفى المزدحمة.
في المقابل ، تقوم هارفست بتوزيع جميع البيانات الطبية لتسهيل تحليلها ويمكن وضعها فوق أي نظام طبي. يوضح الشكل أدناه كيفية استخدام هارفست في نظام iNYP ، ويظهر التصوير المرئي الذي تم تجديده وتطوره لتنسيق التقارير المليء بالنصوص سابقًا.

يمكننا أن نرى الجدول الزمني لكل زيارة للعيادة أو المستشفى. إنه مصحوب بسحابة كلمات من الحالات الطبية المهمة للمريض في النطاق الزمني المحدد. يمكن للمستخدم الانتقال إلى الملاحظات التفصيلية والتاريخ إذا لزم الأمر أيضًا.
كل هذا مدعوم أيضًا بملخصات كل تقرير حتى يتمكن المستخدم من الحصول على لمحة سريعة عن التاريخ الطبي للمريض. يعد هارفست أكثر من مجرد حداثة مُعاد تنسيقها — فهو مفيد للغاية ليس فقط لمنح الأطباء ، ولكن أيضًا الطاقم الطبي العام ومقدمي الرعاية ، لقطة إعلامية في الوقت الفعلي تقريبًا لما يحدث مع المريض.
يتم تشغيل جميع الملاحظات التاريخية (من الأطباء والممرضات وخبراء التغذية ، وما إلى ذلك) المتعلقة بذلك المريض من خلال أداة التعرف على الكيانات المسماة تسمى HealthTermFinder. يؤدي هذا إلى العثور على جميع المصطلحات المتعلقة بالرعاية الصحية ، والتي يتم تعيينها بعد ذلك إلى المجموعة الدلالية لنظام اللغة الطبية الموحدة (UMLS).
يتم تصور هذه المصطلحات في سحابة الكلمات. يتم تحديد أوزان سحابة الكلمات بواسطة TF-IDF. أيضًا ، تشير أحجام الخطوط الأكبر إلى الأصغر إلى درجة وتكرار المشكلات المختلفة التي كان المريض يحملها. يمكن أن يؤدي هذا النمط المرئي أيضًا إلى تحديد واستكشاف المشكلات التي ربما لم يتم أخذها في الاعتبار.
إن هارفست قادر على تصوير التاريخ الطبي للمريض عبر فترة زمنية ، مهما كانت طويلة ، بطريقة أكثر فاعلية وسهولة في الفهم. ما يصبح أكثر قيمة في مثل هذه الحالات هو أنه يساعد في القدرة التحليلية للمهني الطبي على التعامل مع المشكلات الجذرية وعدم الانخراط في مجرد علاج الأعراض أو التشخيص الخاطئ المتحيز.
مجيب أسئلة في الصحة
لأخذ تجربة المستخدم إلى المستوى التالي ، يمكننا التفكير في بناء نظام للإجابة على الأسئلة (QA) فوق هذه السجلات.تركيزنا هنا ينصب على الفروق الدقيقة في الأسئلة التي تظهر تحديدًا في سيناريوهات الرعاية الصحية. على سبيل المثال ، يمكن أن تشمل هذه الأسئلة:
- ما جرعة دواء معين يجب على المريض تناولها؟
- لأي مرض يتم تناول دواء معين؟
- ماذا كانت نتائج الفحص الطبي؟
- إلى أي مدى كانت نتيجة الاختبار الطبي خارج النطاق لتاريخ اختبار معين؟
- ما هي الاختبارات المعملية التي أكدت وجود مرض معين؟
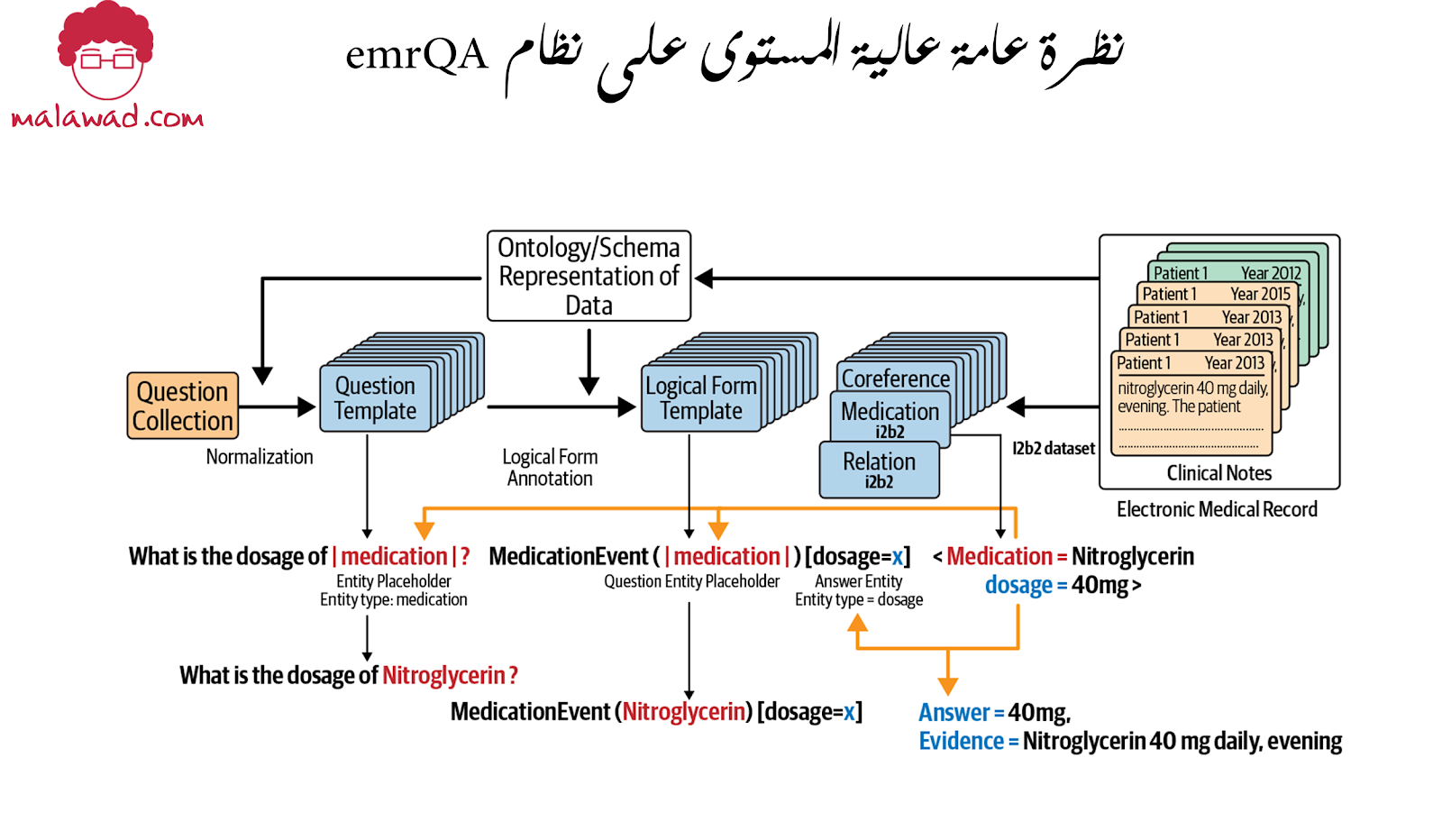
غالبًا ما يكون بناء مجموعة البيانات المناسبة لمهمة معينة هو المفتاح لحل أي مشكلة في معالجة اللغة الطبيعية. بالنسبة للمشكلة الخاصة لنظام ضمان الجودة في مجال الرعاية الصحية ، سنركز على مجموعة بيانات تُعرف باسم emrQA ، والتي تم إنشاؤها من خلال تعاون مشترك بين مركز أبحاث IBM و MIT و UIUC (ورقة البحثية)
. يوضح الشكل أدناه مثالاً لما تستلزمه مجموعة البيانات هذه. على سبيل المثال ، بالنسبة للسؤال ، “هل كان لدى المريض مؤشر كتلة جسم غير طبيعي؟” ، يتم استخلاص الإجابة الصحيحة من السجلات الصحية السابقة.

لإنشاء مجموعات البيانات هذه للأسئلة والأجوبة وبناء نظام ضمان الجودة عليها ، يتكون إطار إنشاء مجموعة البيانات العامة للإجابة على الأسئلة من:
- جمع الأسئلة الخاصة بالمجال ثم تسويتها. على سبيل المثال ، يمكن أن يُسأل عن علاج المريض بعدة طرق ، مثل ، “كيف تمت إدارة المشكلة؟” أو “ما الذي تم فعله لتصحيح مشكلة المريض؟” كل هذه الأمور يجب تسويتها بنفس الشكل المنطقي.
- يتم تعيين قوالب الأسئلة مع معرفة مجال الخبراء ويتم تخصيص نماذج منطقية لهم. قالب السؤال هو سؤال مجرد. على سبيل المثال ، بالنسبة لنوع معين من الأسئلة ، نتوقع عددًا أو نوعًا من الأدوية كرد. وبشكل أكثر تحديدًا ، فإن نموذج الأسئلة هو “ما جرعة الدواء؟” ، والذي يحدد بعد ذلك سؤالًا دقيقًا ، مثل ، “ما هي جرعة النتروجليسرين؟” هذا السؤال ذو شكل منطقي يتوقع جرعة كاستجابة. .
- تستخدم التعليقات الحالية والمعلومات التي تم جمعها في (1) و (2) لإنشاء مجموعة من أزواج الأسئلة والأجوبة. هنا ، يتم استخدام المعلومات المتاحة بالفعل مثل علامات NE بالإضافة إلى أنواع الإجابات المرتبطة بالنموذج المنطقي لتشغيل البيانات. هذه الخطوة ذات صلة خاصة ، لأنها تقلل من الجهد اليدوي المطلوب في إنشاء مجموعة بيانات ضمان الجودة.
وبشكل أكثر تحديدًا بالنسبة لـ emrQA ، تضمنت هذه العملية استطلاعات رأي الأطباء في إدارة المحاربين القدامى لجمع أسئلة نموذجية ، مما أدى إلى أكثر من 2000 قالب تم تسويتها إلى حوالي 600. ثم تم تعيين هذه الأسئلة النموذجية منطقيًا إلى مجموعة بيانات i2b2 .
تم إنشاء تسميات لمجموعات بيانات i2b2 مع مجموعة من المعلومات الدقيقة مثل مفاهيم الأدوية ، والعلاقات ، والتأكيدات ، ودقة المرجع ، وما إلى ذلك. على الرغم من أنها لم يتم إنشاؤها بشكل صريح لأغراض ضمان الجودة ، إلا أنه من خلال استخدام الخرائط المنطقية والتعليقات التوضيحية الحالية ، تم توليد الأسئلة والأجوبة منهم.
يتم عرض نظرة عامة عالية المستوى على هذه العملية في الشكل أدناه. يتم الإشراف على هذه العملية عن كثب من قبل مجموعة من الأطباء لضمان جودة مجموعة البيانات.
لبناء نظام أساسي لضمان الجودة ، تم استخدام نماذج التسلسل العصبي (seq-to-seq ) والنماذج القائمة على الإستدلال (heuristic-based models) . تمت تغطية هذه النماذج بمزيد من التفصيل في عمل فريق EMRQA. لتقييم هذه النماذج ، قسموا مجموعة البيانات إلى مجموعتين: emrQL-1 و emrQL-2. كان لدى emrQL-1 تنوع أكبر في المفردات في بيانات الاختبار والتدريب. كان أداء النماذج التجريبية أفضل من النماذج العصبية لـ emrQL-1 ، بينما كانت النماذج العصبية أفضل بالنسبة لـ emrQL-2.
على نطاق أوسع ، هذه حالة استخدام مثيرة للاهتمام حول كيفية إنشاء مجموعات بيانات معقدة باستخدام الاستدلال ورسم الخرائط ومجموعات البيانات التوضيحية الأخرى الأبسط. يمكن تطبيق هذه الدروس المستفادة على مجموعة من المشكلات الأخرى ، بخلاف معالجة السجلات الصحية ، والتي تتطلب إنشاء مجموعة بيانات شبيهة بضمان الجودة.
التنبؤ بالنتائج وأفضل الممارسات
لقد رأينا كيف يمكن أن يساعد معالجة اللغة الطبيعية في الاستكشاف وكيف يمكن للأطباء طرح الأسئلة من السجلات الصحية للمرضى. هنا ، سنغطي تطبيقًا أكثر تطورًا باستخدام السجلات الصحية: توقع النتائج الصحية.
النتائج الصحية هي مجموعة من السمات التي تشرح عواقب المرض على المريض. وهي تشمل مدى سرعة وكيفية تعافي المريض تمامًا. كما أنها مهمة في قياس كفاءة العلاجات المختلفة. هذا العمل هو تعاون مشترك بين Google AI و Stanford Medicine و UCSF [نظرة عامة].
إلى جانب التنبؤ بالنتائج الصحية ، فإن التركيز الآخر للتعلم العميق والقابل للتطوير والدقيق باستخدام السجلات الصحية الإلكترونية هو ضمان قدرتنا على بناء نماذج وأنظمة يمكن أن تكون قابلة للتطوير ودقيقة للغاية.
قابلية التوسع ضرورية ، حيث أن الرعاية الصحية لديها مجموعة متنوعة من المدخلات – البيانات التي تم جمعها من يمكن أن يختلف مستشفى أو قسم عن الآخر.
لذلك يجب أن يكون من السهل تدريب النظام على نتيجة مختلفة أو مستشفى مختلف. من الضروري أن تكون دقيقًا حتى لا تطلق الكثير من الإنذارات الكاذبة ؛ إن الحاجة إلى الدقة واضحة في صناعة الرعاية الصحية ، حيث تكون حياة الناس على المحك.
بهذه البساطة التي قد تبدو بها السجلات الصحية الإلكترونية ، فهي بعيدة كل البعد عن ذلك ؛ هناك الكثير من الفروق الدقيقة والتعقيد المرتبطة بها. حتى شيء بسيط مثل درجة حرارة الجسم يمكن أن يكون له مجموعة من التشخيصات اعتمادًا على ما إذا كان قد تم أخذه عن طريق اللسان أو الجبين أو أجزاء أخرى من الجسم. للتعامل مع كل هذه الحالات ، تم إنشاء معيار مفتوح لموارد التشغيل البيني للرعاية الصحية (FHIR) ، والذي استخدم تنسيقًا موحدًا مع محددات مواقع فريدة من أجل الاتساق والموثوقية.
بمجرد أن تصبح البيانات بتنسيق متناسب، يتم إدخالها في نموذج يعتمد على الشبكات العصبية المتكررة RNNs. يتم تغذية جميع البيانات التاريخية من بداية السجل حتى نهايته. متغير الإخراج هو النتيجة التي نتطلع إلى توقعها.
تم تقييم النموذج على مجموعة من النتائج الصحية. حققت درجة AUC (أو المنطقة الواقعة تحت المنحنى) 0.86 فيما يتعلق بما إذا كان المرضى سيبقون لفترة أطول في المستشفى ، و 0.77 في حالات إعادة الإدخال غير المتوقعة ، و 0.95 في التنبؤ بوفيات المرضى.
درجة AUC هي مقياس يُستخدم غالبًا في مثل هذه الحالات لأن AUC هي مقياس موجز للأداء عبر جميع العتبات التشخيصية المحتملة للإيجابية ، بدلاً من الأداء عند أي عتبة محددة . تشير الدرجة 1.0 إلى الدقة الكاملة ، بينما 0.5 هي نفس الفرصة العشوائية.
من المهم في مجال الرعاية الصحية أن تكون النماذج قابلة للتفسير. بمعنى آخر ، يجب عليهم تحديد سبب اقتراحهم لنتيجة معينة. بدون إمكانية التفسير ، يصعب على الأطباء استيعاب النتائج في تشخيصهم. لتحقيق ذلك ، يتم استخدام ألية الانتباه ، وهو مفهوم في التعلم العميق ، لفهم نقاط البيانات والحوادث الأكثر أهمية للنتيجة. يمكن رؤية مثال على خريطة الاهتمام هذه في الشكل أدناه.

توصل فريق الذكاء الاصطناعي من Google هذا أيضًا إلى بعض أفضل الممارسات التي يجب على المرء وضعها في الاعتبار أثناء بناء نماذج تعلم الألة للرعاية الصحية ، وتحديد الأفكار في جميع أجزاء دورة حياة التعلم الآلي ، من تحديد المشكلة وجمع البيانات للتحقق من صحة النتائج. هذه الاقتراحات ذات صلة بـ معالجة اللغة الطبيعية و التبصير الحاسوبي بالإضافة إلى مشاكل البيانات المنظمة. يمكن الاطلاع عليها بالتفصيل في هنا.
تركز هذه التقنيات في الغالب على إدارة الصحة الجسدي للإنسان ، وهو أمر سهل نسبيًا قياسة نظرًا لوجود مجموعة متنوعة من المقاييس العددية المتاحة ، ولكن لا توجد مقاييس واضحة قابلة للقياس الصحة العقلية للشخص. دعونا نلقي نظرة على بعض الأساليب لمراقبة الصحة العقلية لأي شخص.
مراقبة الرعاية الصحية العقلية
نظرًا للوتيرة السريعة للتغير الاقتصادي والتكنولوجي والوتيرة السريعة للحياة في عالم اليوم ، فليس من المستغرب أن معظم الناس ، خاصة في الأجيال X و Y و Z ، يميلون إلى تجربة شكل من أشكال مشاكل الصحة العقلية في حياتهم.
حسب بعض التقديرات ، يتأثر أكثر من 790 مليون شخص بقضايا متعلقة بالصحة العقلية على مستوى العالم ، مما يُترجم إلى أكثر من 1 من كل 10 أشخاص [مصدر].
مع استخدام الوسائط الاجتماعية في أعلى مستوياته على الإطلاق ، أصبح من الممكن بشكل متزايد استخدام الإشارات من وسائل التواصل الاجتماعي لتتبع الحالة العاطفية والتوازن العقلي لكل من الأفراد المعينين وعبر مجموعات الأفراد. يجب أن يكون من الممكن أيضًا اكتساب رؤى حول هذه الجوانب عبر مختلف المجموعات الديموغرافية ، بما في ذلك العمر والجنس. في هذا القسم ، سنغطي بإيجاز تحليلًا استكشافيًا حول البيانات العامة من مستخدمي Twitter وكيف يمكن تطبيق التقنيات التي تم ذكرناها في المقال السابق من هذه السلسلة في على هذه المشكلة.
هناك جوانب لا حصر لها لتقييم الحالة الصحية العقلية للفرد. الدراسة التي أجراها غلين كوبرسميث وآخرون. كمثال توضيحي ، يركز على استخدام وسائل التواصل الاجتماعي في تحديد الأفراد المعرضين لخطر الانتحار. كان الهدف من الدراسة هو تطوير نظام إنذار مبكر إلى جانب تحديد الأسباب الجذرية للمشكلات.
في هذه الدراسة ، تم تحديد وتقييم 554 مستخدمًا ذكروا أنهم حاولوا الانتحار. أعطى 312 من هؤلاء المستخدمين إشارة صريحة إلى محاولة الانتحار الأخيرة. لم يتم تضمين الملفات الشخصية التي تم تمييزها على أنها خاصة في هذه الدراسة. قاموا فقط بفحص البيانات العامة ، والتي لا تتضمن أي رسائل مباشرة أو منشورات محذوفة.
– تم تحليل تغريدات كل مستخدم من خلال المنظورات التالية:
- هل تصريح المستخدم بمحاولة الانتحار حقيقي على ما يبدو؟
- هل يتحدث المستخدم عن محاولة الإنتحار ؟
- هل يمكن تحديد موقع محاولة الانتحار في الوقت المناسب؟
انظر الشكل التالي لبعض أمثلة التغريدات.

تشير التغريدات الأولى والثانية إلى محاولات انتحار حقيقية ، في حين أن التويترتين السفليتين عبارة عن تصريحات ساخرة أو كاذبة. المثالان الأوسطان هما مثالان حيث تم ذكر تاريخ صريح لمحاولة الانتحار.
لتحليل البيانات تم اتباع الخطوات التالية:
- المعالجة المسبقة: نظرًا لأن بيانات Twitter غالبًا ما تكون صاخبة ، فقد تم تطبيعها وتنظيفها أولاً. يتم تمثيل عناوين URL وأسماء المستخدمين برموز متجانسة.
- نماذج حروف: تم استخدام النماذج القائمة على الحرف n-gram متبوعة بانحدار لوجستي لتصنيف التغريدات المختلفة. تم قياس الأداء من خلال التحقق بمقدار 10 طيات.
- الحالات العاطفية: لتقدير المحتوى العاطفي في التغريدات ، تم تمهيد مجموعة البيانات باستخدام علامات التصنيف. على سبيل المثال ، تم وضع جميع التغريدات التي تحتوي على #anger ولكن لا تحتوي على #sarcasm و #jk في ملصق عاطفي. كما تم تصنيف التغريدات التي لا تحتوي على محتوى عاطفي على أنها “بلا عاطفة”.
ثم تم اختبار هذه النماذج لمعرفة مدى نجاحها في تحديد مخاطر الانتحار المحتملة. تمكنوا من تحديد 70٪ من الأشخاص الذين كانوا على الأرجح يحاولون الانتحار ، مع 10٪ فقط من الإنذارات الكاذبة. يوضح الشكل التالي مصفوفة ارتباك توضح بالتفصيل التصنيف الخاطئ للمشاعر المختلفة التي تم تصميمها.

يمكن استخدام تحديد مشكلات الصحة العقلية المحتملة للتدخل في الحالات التي تم الإبلاغ عنها. من خلال المراقبة والتنبيه الدقيقين ، يمكن أيضًا استخدام روبوتات معالجة اللغة الطبيعية مثل Woebot لرفع الحالة المزاجية للأشخاص المعرضين لخطر أكبر. في القسم التالي ، سوف نتعمق أكثر في استخراج الكيانات من البيانات الطبية.
استخراج وتحليل المعلومات الطبية
لقد رأينا مجموعة من التطبيقات المبنية على السجلات والمعلومات الصحية. إذا بدأنا في إنشاء تطبيقات باستخدام السجلات الصحية ، فستكون إحدى الخطوات الأولى هي استخراج الكيانات والعلاقات الطبية منها. يساعد استخراج المعلومات الطبية في تحديد المتلازمات السريرية والحالات الطبية والأدوية والجرعة والقوة والمفاهيم الطبية الحيوية الشائعة من السجلات الصحية وتقارير الأشعة وملخصات التفريغ ، بالإضافة إلى وثائق التمريض ووثائق التعليم الطبي. يمكننا استخدام واجهات برمجة التطبيقات السحابية والنماذج الجاهزة لذلك.
أولاً ، سنبدأ بفهم Amazon Comprehend Medical . إنه جزء من مجموعة أكبر من AWS ، Amazon Comprehend ، والتي تتيح لنا القيام بمهام معالجة اللغة الطبيعية الشائعة مثل استخراج عبارة المفاتيح ، وتحليل المشاعر وبناء الجملة ، بالإضافة إلى التعرف على اللغة والكيان في السحابة.
تساعد Amazon Comprehend Medical على معالجة البيانات الطبية ، بما في ذلك الكيان الطبي المسمى واستخراج العلاقة وربط الأنطولوجيا الطبية.
يمكننا استخدام Amazon Comprehend Medical كواجهة برمجة تطبيقات سحابية في نصنا الطبي.
سنقدم نظرة عامة موجزة عن كيفية عملها. للبدء ، سنأخذ السجلات الصحية من FHIR كمدخل . للتذكير ، FHIR هو معيار يصف كيفية توثيق معلومات الرعاية الصحية ومشاركتها عبر الولايات المتحدة. سنأخذ عينة من السجل الصحي الإلكتروني من Good Health Clinic الافتراضية .
لاختبار Comprehend Medical ، سنزيل أيضًا جميع التنسيقات وفواصل الأسطر منه لمعرفة مدى نجاح النظام في القيام بذلك. كمدخل بداية ، دعنا نفكر في تسلسل صغير لهذا السجل الطبي:
Good Health Clinic Consultation Note Robert Dolin MD Robert Dolin MD Good Health Clinic Henry Levin the 7th Robert Dolin MD History of Present Illness Henry Levin, the 7th is a 67 year old male referred for further asthma management. Onset of asthma in his twenties teens. He was hospitalized twice last year, and already twice this year. He has not been able to be weaned off steroids for the past several months. Past Medical History Asthma Hypertension (see HTN.cda for details) Osteoarthritis, right knee Medications Theodur 200mg BID Proventil inhaler 2puffs QID PRN Prednisone 20mg qd HCTZ 25mg qd Theodur 200mg BID Proventil inhaler 2puffs QID PRN Prednisone 20mg qd HCTZ 25mg qd
عندما نقدم هذا كمدخل إلى Comprehend Medical ، نحصل على المخرجات الموضحة أدناه .
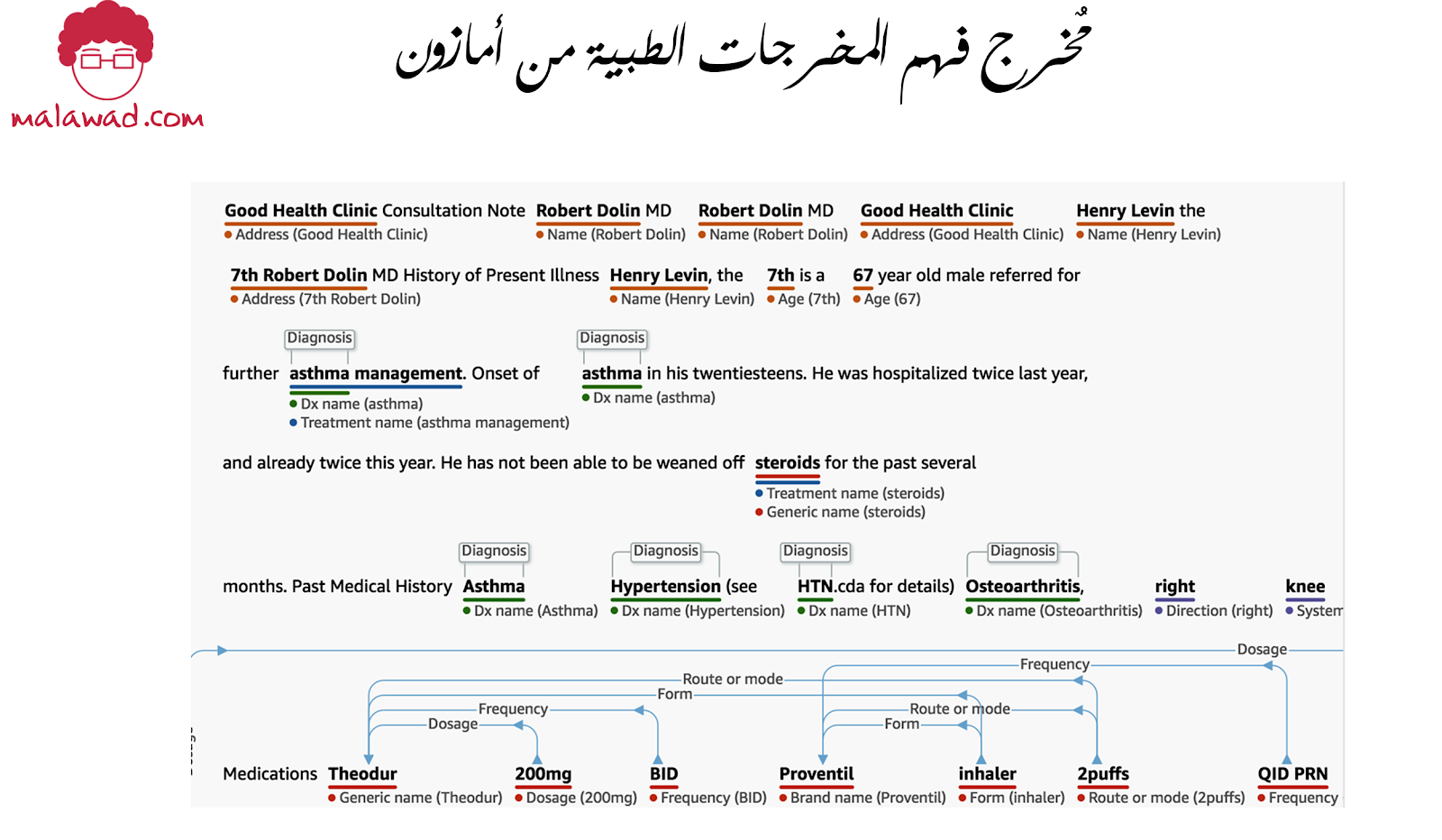
كما نرى ، تمكنا من استخراج كل شيء ، من تفاصيل العيادة والطبيب إلى التشخيص والأدوية ، بالإضافة إلى تواترها وجرعاتها وطريقها. إذا احتجنا إلى ذلك ، فيمكننا أيضًا ربط المعلومات المستخرجة بالأنطولوجيا الطبية القياسية مثل ICD-10-CM أو RxNorm. يتم الوصول إلى جميع الميزات الطبية الشاملة من خلال مكتبة AWS boto .
يمكن أن تكون واجهات برمجة التطبيقات والمكتبات السحابية نقطة انطلاق جيدة لبناء استخراج المعلومات الطبية ، ولكن إذا كانت لدينا متطلبات محددة ونفضل بناء نظامنا الخاص ، فيمكننا استخدام BioBERT كنقطة انطلاق.
يتم تدريب نموذج BERT الافتراضي على نصوص ويب عادية ، والتي تختلف تمامًا عن النصوص الطبية والسجلات. على سبيل المثال ، تختلف توزيعات الكلمات المختلفة اختلافًا كبيرًا بين السجلات الطبية والإنجليزية العادية. يؤثر هذا على أداء BERT في المهام الطبية.
من أجل بناء نماذج أفضل للبيانات الطبية الحيوية ، تم إنشاء BERT للنص الطبي الحيوي (BioBERT) . يتكيف BERT مع النصوص الطبية الحيوية للحصول على أداء أفضل. في مرحلة تكييف المجال ، نقوم بتهيئة أوزان النموذج باستخدام نموذج BERT قياسي ونصوص طبية حيوية مدربة مسبقًا ، بما في ذلك نصوص من PubMed ، محرك بحث للنتائج الطبية. يوضح الشكل أدناه عملية التدريب المسبق والضبط الدقيق لـ BioBERT.
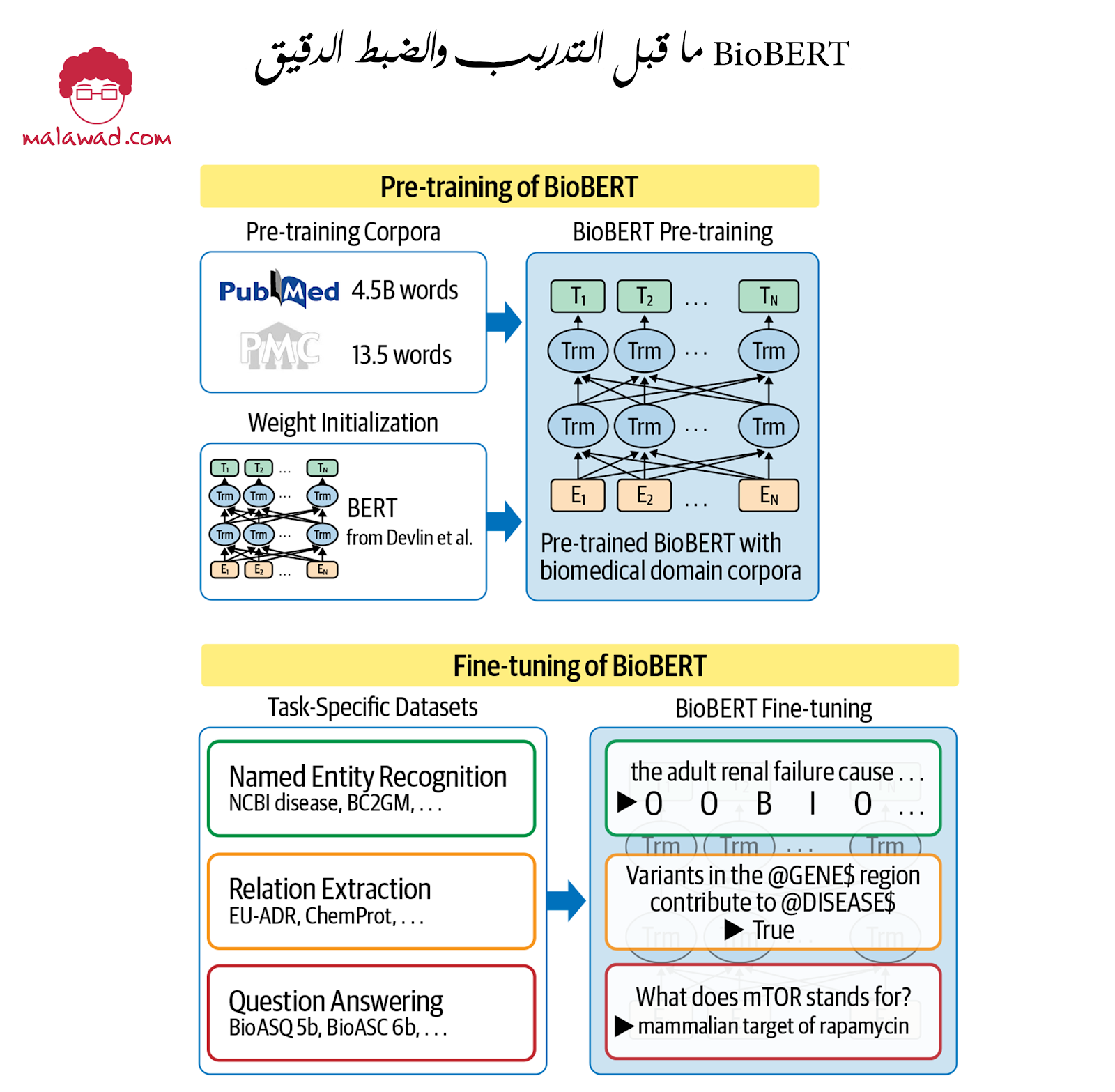
هذا النموذج والأوزان مفتوحة المصدر ويمكن العثور عليها على GitHub [هنا ، هنا]. يمكن ضبط BioBERT على مجموعة من المشكلات الطبية المحددة مثل التعرف على الكيانات الطبية المسماة واستخراج العلاقة. كما تم تطبيقه على الإجابة على الأسئلة في نصوص الرعاية الصحية. يحصل BioBERT على أداء أعلى بكثير من أداء BERT وغيره من التقنيات الحديثة. يمكن أيضًا تكييفه اعتمادًا على المهمة الطبية ومجموعة البيانات.
ختاماً
لقد ناقشنا مجموعة من تطبيقات الرعاية الصحية حيث يمكن أن تساعد معالجة اللغة الطبيعية. لقد غطينا جوانب مختلفة من التطبيقات التي يمكن بناؤها على السجلات الصحية وتعلمنا كيف يمكن تطبيق مراقبة وسائل التواصل الاجتماعي على قضايا الصحة العقلية. في النهاية ، رأينا كيف نرسي أسس تطبيق الرعاية الصحية الخاص بنا.













إضافة تعليق