
سنلقي الآن نظرة عميقة على تطبيق معالجة اللغة الطبيعية على البيانات النصية لمنصات التواصل الإجتماعي لبناء بعض التطبيقات الشيقة التي يمكننا تطبيقها على مجموعة متنوعة من المشكلات.
قد نحتاج إلى معرفة كيفية استجابة العملاء لإعلان أو منتج معين أصدرناه ، أو أن نكون قادرين على تحديد الخصائص الديمغرافية للمستخدم ، على سبيل المثال. سنبدأ بتطبيقات بسيطة مثل سحابة الكلمات وننتقل إلى تطبيقات أكثر تعقيدًا ، مثل فهم المشاعر في المشاركات على منصات التواصل الاجتماعية مثل Twitter.
سحابة الكلمات
سحابة الكلمات هي طريقة تصويرية لالتقاط أهم الكلمات في مستند أو مجموعة بيانات معينة. إنها ليست سوى صورة مكونة من كلمات (بأحجام مختلفة) من النص قيد الدراسة ، حيث يتناسب حجم الكلمة مع أهميتها (تكرارها) في مجموعة النص. إنها طريقة سريعة لفهم المصطلحات الأساسية في مجموعة الوثائق.

كيف يمكننا إنشاء سحب كلمات من مجموعة تغريدات؟ ما هو خط إنتاج معالجة اللغة الطبيعية لهذا؟ إليك عملية خطوة بخطوة لإنشاء سحابة كلمات:
- قم بتعميل (Tokenize ) محتوى أو وثيقة معينة
- إزالة كلمات التوقف
- رتب الكلمات المتبقية بترتيب تنازلي للتكرار
- خذ أفضل كلمات k وأرسمها “جماليًا”
يوضح مقتطف الكود التالي كيفية تنفيذ خط الإنتاج هذا عمليًا والتي تحتوي على وظيفة مضمنة لإنشاء سحب الكلمات:
import pandas as pd
import string
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.tokenize.treebank import TreebankWordDetokenizer
# قراءة ملفات تويتر
df_tweets = pd.read_csv("Data/sts_gold_tweet.csv", delimiter=";")
df_tweets = df_tweets.iloc[1750:]
# وضع التغريدات في قائمة
corpus_split = list(df_tweets['tweet'])
#وظيفة مساعدة لوضع البيانات في مجموعة واحدة
def concatenate_list_data(list):
result = ''
for element in list:
result += str(element)
return result
corpus_twitter = concatenate_list_data(corpus_split)
corpus_twitter[:10000]
corpus_twitter = corpus_twitter.split()
# إزالة علامات الترقيم من كل كلمة
table = str.maketrans('', '', string.punctuation)
stripped_twitter = [w.translate(table) for w in corpus_twitter]
TreebankWordDetokenizer().detokenize(stripped_twitter)
# إضافة البيانات في القائمة إلى سلسة
string_twitter =' '
string_twitter = string_twitter.join(stripped_twitter)
# إختيار اللغة الإنجليزية لكلامات التوقف
stop_words = set(stopwords.words('english'))
# تعميل السلسلة
word_tokens_twitter = word_tokenize(string_twitter)
# إزالة كلمات التوقف
filtered_corpus_twitter = [w for w in word_tokens_twitter if not w in stop_words]
# حساب تكرار كل كلمة
wordfreq_twitter = [filtered_corpus_twitter.count(p) for p in filtered_corpus_twitter]
result_twitter = dict(zip(filtered_corpus_twitter, wordfreq_twitter))
#طباعة السحابة
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(width = 1200, height = 1200, background_color="white",min_font_size =10).generate_from_frequencies(result_twitter)
plt.figure(figsize = (8, 8), facecolor = None)
plt.imshow(wordcloud)
plt.axis("off")
plt.tight_layout()
plt.show()
#طباعة السحابة بقناع معين
from PIL import Image
import numpy as np
import urllib
import requests
def generate_wordcloud(words, mask):
wordcloud = WordCloud(width = 1200, height = 1200,background_color="white", min_font_size =10,mask=mask).generate_from_frequencies(words)
plt.figure(figsize=(10,8),facecolor = 'white', edgecolor='blue')
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.tight_layout(pad=0)
plt.show()
mask = np.array(Image.open('mask.png'))
generate_wordcloud(result_twitter, mask_house)
اعتمادًا على التصميم ، يمكننا إنشاء سحب كلمات بأشكال مختلفة لتناسب تطبيقنا ، كما هو موضح أدناه.
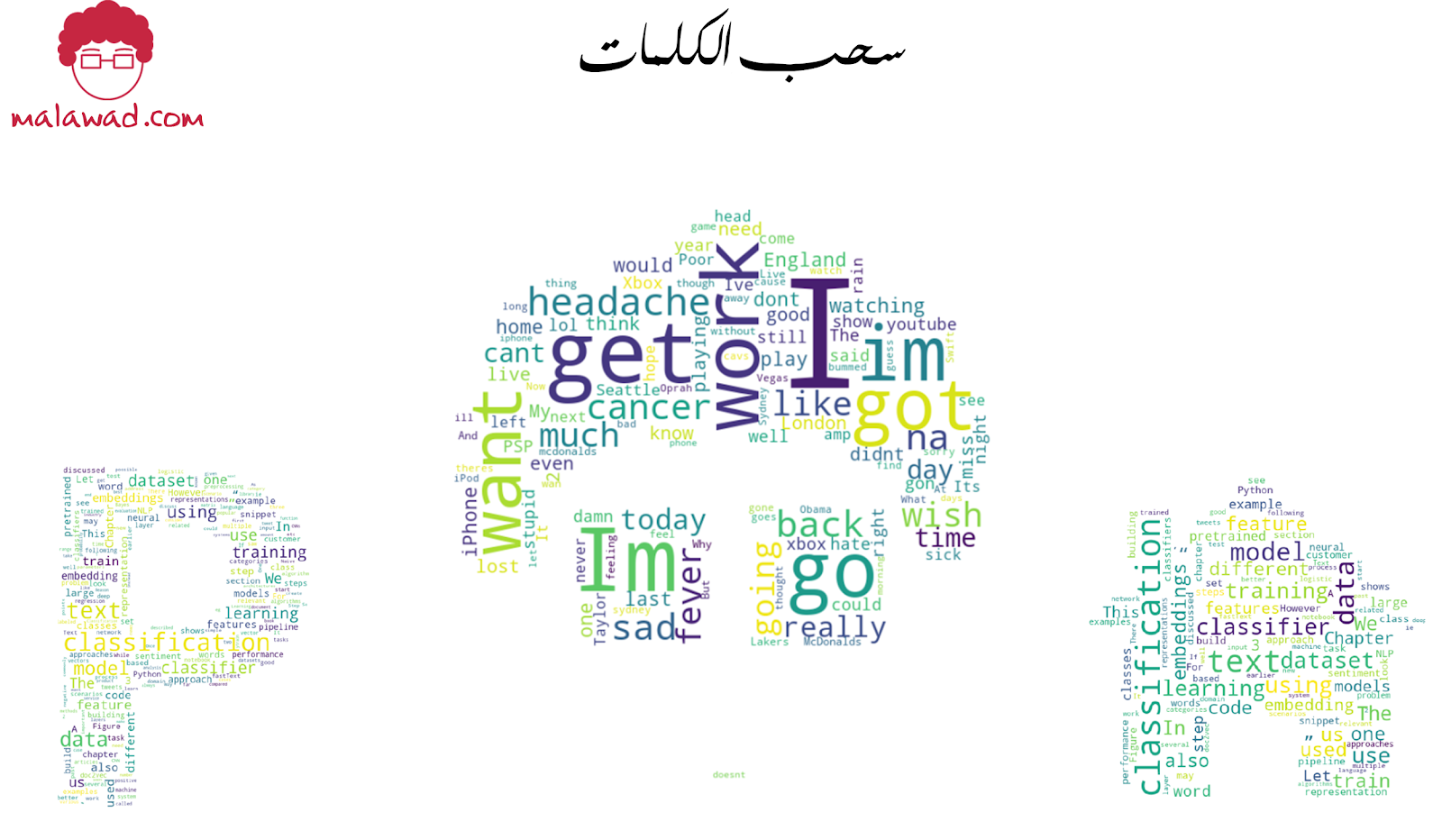
تعميل البيانات النصية لمنصات التواصل الإجتماعي
تتمثل إحدى الخطوات الأساسية في العملية المذكورة أعلاه في تعميل البيانات النصية بشكل صحيح. لهذا ، استخدمنا وظيفة twokenize للحصول على العملات (Tokens) من مجموعة النص.
هذه وظيفة متخصصة للحصول على العملات من البيانات النصية للتغريدات. و هي جزء من مجموعة أدوات معالجة اللغة الطبيعية المصممة خصيصًا للتعامل مع توتير (هنا ، هنا ). الآن ، قد نسأل: لماذا نحتاج إلى مٌعمل متخصص (specialized tokenizer) ، ولماذا لا نستخدم المُعمل القياسي المتاح في NLTK؟
تكمن الإجابة في حقيقة أن المٌعمل المتوفر في NLTK مصمم للعمل مع اللغة الإنجليزية القياسية. في اللغة الإنجليزية على وجه التحديد ، يتم فصل كلمتين بمسافة. قد لا يكون هذا صحيحًا بالضرورة بالنسبة للغة الإنجليزية المستخدمة على Twitter.
يشير هذا إلى أن المٌعمل الذي يستخدم المساحة كطريقة لتحديد حدود الكلمات قد لا يكون جيدًا في التعامل مع البيانات النصية لمنصات التواصل.
دعونا نفهم هذا بمثال. ضع في اعتبارك التغريدة التالية: “Hey @NLPer! This is a #NLProc tweet 😀 “. الطريقة المثلى لتعميل هذا النص هي كما يلي: [‘Hey’, ‘@NLPer’, ‘!’, ‘This’, ‘is’, ‘a’, ‘#NLProc’, ‘tweet’, ‘:-D’].
باستخدام مُعمل مصمم للغة الإنجليزية ، مثل nltk.tokenize.word_tokenize ، سنحصل على العملات التالية:
[‘Hey’, ‘@’, ‘NLPer’, ‘!’, ‘This’, ‘is’, ‘a’, ‘#’, ‘NLProc’, ‘tweet’, ‘:’, ‘-D’]
من الواضح أن مجموعة العملات التي قدمها المُعمل في NLTK ليست صحيحة. من المهم استخدام المُعمل الذي يقدم العملات الصحيحة. تم تصميم twokenize خصيصًا للتعامل مع التغريدات.
بمجرد أن نحصل على المجموعة الصحيحة من العملات ، يكون حساب التكرار سهلاً. هناك عدد من المُعملات المتخصصة المتاحة للعمل مع منصات التواصل. ومن أشهرها nltk.tokenize.TweetTokenizer و Twikenizer و Twokenizer و twokenize . بالنسبة إلى تغريدة مُدخلة ، يمكن لكل واحد منهم أن يعطي مخرجات مختلفة قليلاً.
الموضوعات الشائعة
قبل عدة أعوام فقط ، كان إطلاعك على أحدث الموضوعات أمرًا بسيطًا جدًا – اختر جريدة اليوم ، واقرأ العناوين الرئيسية ، وبذلك تكون قد انتهيت. لقد غيرت وسائل التواصل الاجتماعي هذا. نظرًا لحجم حركة المرور ، يمكن (وغالبًا ما يتغير) ما هو شائع في غضون ساعات قليلة. قد لا يكون تتبع الشائع على مدار الساعة أمرًا مهمًا جدًا بالنسبة للفرد ، ولكن بالنسبة لكيان تجاري ، قد يكون ذلك مهمًا للغاية.
كيف يمكننا تتبع الموضوعات الشائعة؟ في لغة وسائل التواصل الاجتماعي ، غالبًا ما ترتبط أي محادثة حول موضوع ما بعلامة تصنيف. وبالتالي ، فإن العثور على الموضوعات الشائعة يعني العثور على علامات التجزئة الأكثر شيوعًا في نافذة زمنية معينة.
إذن كيف نطبق نظامًا يمكنه جمع الموضوعات الشائعة؟ واحدة من أبسط الطرق للقيام بذلك هي استخدام Python API يسمى Tweepy . يعطي Tweepy وظيفة بسيطة ، trends_available ، لجلب الموضوعات الشائعة.
يأخذ الموقع الجغرافي ( معرّف أين على الأرض (Where On Earth Identifier) أو WOEID ) كمدخل ويعيد الموضوعات الشائعة في هذا الموقع الجغرافي.
ترجع الوظيفة trends_available أهم 10 موضوعات شائعة لمعرف WOEID معين ، بشرط أن تكون معلومات الاتجاه الخاصة بـ WOEID المحدد متاحة. استجابة استدعاء الوظيفة هذه عبارة عن مصفوفة من الكائنات “الشائعة”.
استجابةً لذلك ، يقوم كل كائن بترميز المعلومات التالية: اسم الموضوع الرائج ، ومعلمات الاستعلام المقابلة التي يمكن استخدامها للبحث عن الموضوع باستخدام بحث Twitter ، وعنوان URL لبحث تويتر يوجد أدناه مقتطف للكود الذي يوضح كيف يمكننا استخدام Tweepy لجلب الموضوعات الشائعة :
import tweepy, json
# وضع كل البيانات المطلوبة من حساب تويتر للمطورين
CONSUMER_KEY= 'insert your customer key'
CONSUMER_SECRET= 'insert your customer secrect key'
ACCESS_KEY= 'insert your access key here'
ACCESS_SECRET= 'insert your access secret key here'
#الوصول إلى حساب تويتر
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
auth.set_access_token(ACCESS_KEY, ACCESS_SECRET)
api = tweepy.API(auth)
# WOEID
WORLD_WOE_ID =1
BRAZIL_WOE_ID = 23424768
#الحصول على الموضوعات الشائعة
brazil_trends = api.trends_place(BRAZIL_WOE_ID)
trends = json.loads(json.dumps(brazil_trends, indent=1))
brazil_trend_list=[]
for trend in trends[0]["trends"]:
brazil_trend_list.append(trend["name"].strip("#"))
#الحصول على الموضوعات الشائعة للعالم
world_trends = api.trends_place(WORLD_WOE_ID)
world_trends_json = json.loads(json.dumps(world_trends, indent=1))
world_trend_list=[]
for trend in world_trends_json[0]["trends"]:
world_trend_list.append(trend["name"].strip("#"))
#طباعة الموضوعات الشائعة في كل من العالم و الدولة اللتي إخترناها
print(set(world_trend_list).intersection(set(brazil_trend_list)))
سيعطينا هذا المقتطف الصغير من الكود أفضل المواضيع الشائعة لموقع معين. المشكلة الوحيدة هي أن Tweepy هي واجهة برمجة تطبيقات مجانية ، لذلك لديها حدود للمعدل.
يفرض Twitter قيودًا على معدل عدد الطلبات التي يمكن أن يقدمها تطبيق إلى أي مورد محدد لواجهة برمجة التطبيقات خلال فترة زمنية معينة – لا يمكنك إجراء آلاف الطلبات. حدود معدل Twitter موثقة جيدًا. في حال احتجت إلى تجاوز هذا المعدل ، انظر إلى Gnip ، وهو عبارة عن أنبوب بيانات مدفوعة من Twitter.
فهم مشاعر تويتر
عندما يتعلق الأمر بمعالجة اللغات الطبيعية والوسائط الاجتماعية ، يجب أن يكون تحليل المشاعر أحد أكثر التطبيقات شيوعًا. بالنسبة للأنشطة التجارية والعلامات التجارية في جميع أنحاء العالم ، من الأهمية الاستماع إلى ما يقوله الناس عنها وعن منتجاتهم وخدماتهم.
والأهم من ذلك هو معرفة ما إذا كان رأي الناس إيجابيًا أم سلبيًا وما إذا كانت قطبية المشاعر هذه تتغير بمرور الوقت. في حقبة ما قبل التواصل الاجتماعي ، كان يتم ذلك باستخدام استبيانات العملاء ، بما في ذلك الزيارات من الباب إلى الباب. في عالم اليوم ، تعد وسائل التواصل الاجتماعي طريقة رائعة لفهم شعور الناس تجاه العلامة التجارية.
والأهم من ذلك هو كيف يتغير هذا الشعور بمرور الوقت. يوضح الشكل أدناه كيف تتغير المشاعر بمرور الوقت لمؤسسة معينة. توفر مثل هذه التصورات رؤى رائعة لفرق ومؤسسات التسويق – حيث يساعد تحليل ردود أفعال الجمهور على حملاتهم وأحداثهم في التخطيط الاستراتيجي للحملات والمحتوى في المستقبل.
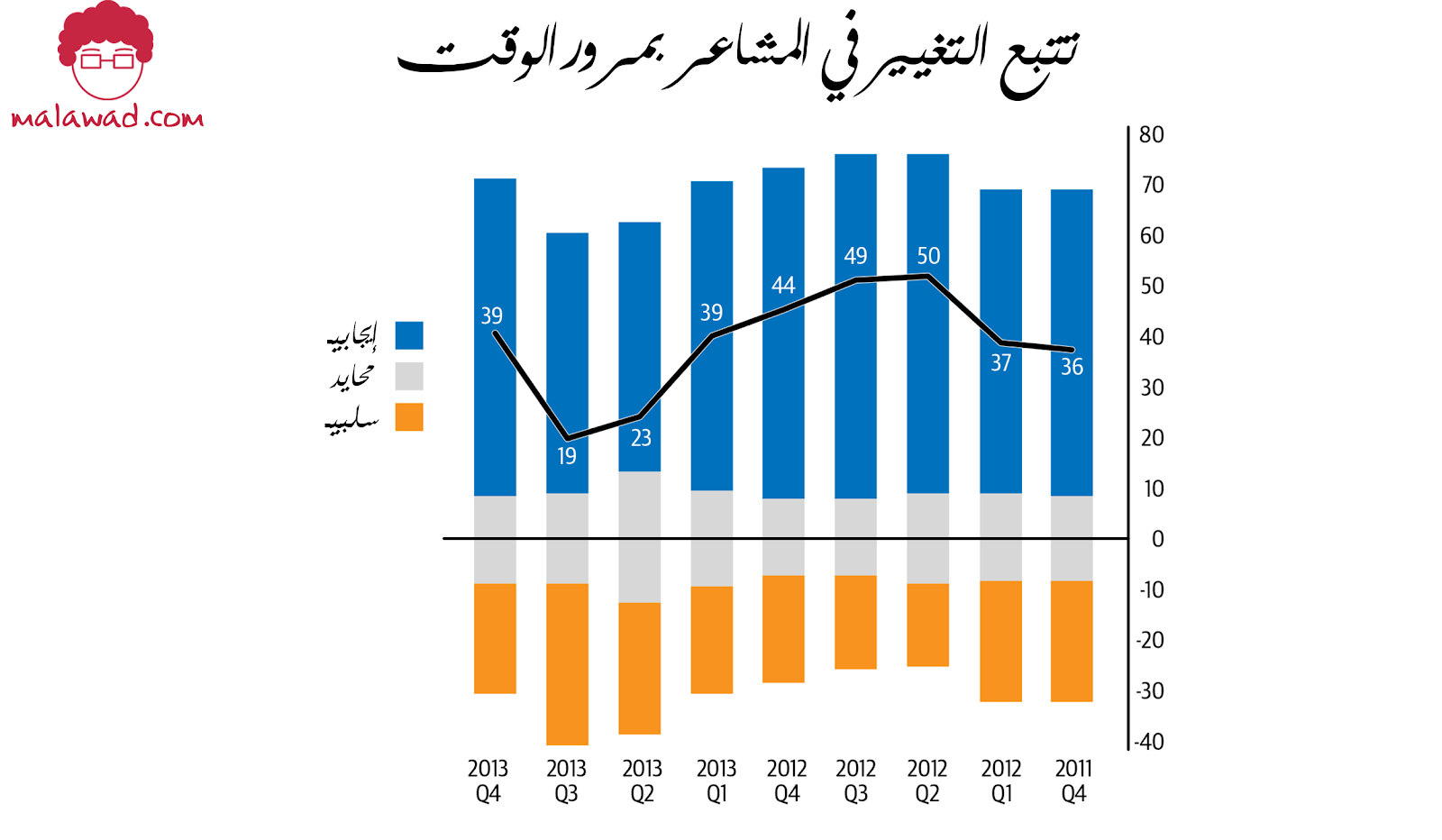
.في هذا القسم ، سنركز على بناء تحليل المشاعر لبيانات تويتر . هناك العديد من مجموعات البيانات المتاحة على الإنترنت – على سبيل المثال ، مسابقة تحليل المشاعر بجامعة ميشيغان على Kaggle و Twitter Sentiment Corpus بواسطة Niek Sanders
سنقوم ببناء نظام لتحليل المشاعر وإنشاء خط أساس. لهذا ، سنستخدم TextBlob ، وهو عبارة عن مجموعة أدوات NLP مبنية على لغة معالجة اللغة الطبيعية (NLP) في NLTK. يأتي مع مجموعة من الوحدات النمطية لمعالجة النصوص واستخراج النصوص وتحليل النص. كل ما يتطلبه الأمر هو خمسة أسطر من التعليمات البرمجية للحصول على مصنف أساسي للمشاعر:
import pandas as pd
from textblob import TextBlob
#تحميل البيانات
df = pd.read_csv("sts_gold_tweet.csv",error_bad_lines=False,delimiter=";")
print(df.columns)
#عمل قائمة من كل التغريدات
tweets_text_collection = list(df['tweet'])
for tweet_text in tweets_text_collection:
print(tweet_text)
analysis = TextBlob(tweet_text)
print(analysis.sentiment)#analyse the sentitment
print("-"*20)
سيعطينا هذا قيم القطبية والذاتية لكل من التغريدات في المجموعة. القطبية هي قيمة تقع بين [–1.0، 1.0] وتوضح مدى إيجابية أو سلبية النص. تقع الذاتية في النطاق [0.0 ، 1.0] حيث 0.0 موضوعية للغاية و 1.0 ذاتية للغاية.
و هي تستخدم فكرة بسيطة: تعميل التغريدة وحساب القطبية والذاتية لكل من العملات. ثم اجمع بين عددي القطبية والذاتية للوصول إلى قيمة واحدة للجملة بأكملها.
قد لا يعمل مصنف المشاعر البسيط هذا بشكل جيد ، ويرجع ذلك أساسًا إلى المُرمز (tokenizer ) الذي يستخدمه TextBlob. تأتي بياناتنا من وسائل التواصل الاجتماعي ، لذلك من المحتمل ألا يتبع اللغة الإنجليزية الرسمية. وبالتالي ، بعد التعميل، قد لا تكون العديد من العملات كلمات قياسية موجودة في قاموس اللغة الإنجليزية ، لذلك لن نمتلك القطبية والذاتية لجميع هذه العملات.
لنفترض أنه قد طُلب منا تحسين المصنف لدينا. يمكننا تجربة تقنيات وخوارزميات مختلفة تعلمناها تحدثنا عنها سابقاً في هذه السلسلة من المقالات عن معالجة اللغة الطبيعية ومع ذلك ، قد لا نشهد تحسنًا كبيرًا في الأداء بسبب الضوضاء الموجودة في البيانات. وبالتالي ، فإن مفتاح تحسين النظام يكمن في التنظيف الأفضل والمعالجة المسبقة للبيانات النصية. هذا أمر بالغ الأهمية لبيانات منصات التواصل الإجتماعي.
المعالجة المسبقة لبيانات منصات التواصل الإجتماعي
تحتوي معظم أنظمة معالجة اللغة الطبيعية التي تعمل مع بيانات منصات التواصل الإجتماعي على خط إنتاج غني للمعالجة المسبقة يتضمن العديد من الخطوات. في هذا القسم ، سنغطي بعض الخطوات التي تظهر كثيرًا.
إزالة عناصر الترميز
ليس من المستغرب أن ترى عناصر الترميز (HTML ، XML ، XHTML ، إلخ) في بيانات منصات التواصل الإجتماعي، ومن المهم إزالتها. طريقة رائعة لتحقيق ذلك هي استخدام مكتبة تسمى Beautiful Soup :
from bs4 import BeautifulSoup markup = '<a href="http://nlp.com/">\nI love <i>nlp</i>\n</a>' soup = BeautifulSoup(markup) soup.get_text()
معالجة البيانات غير النصية
غالبًا ما تكون بيانات منصات التواصل مليئة بالرموز والأحرف الخاصة وما إلى ذلك ، وغالبًا ما تحتوي ترميزات مثل Latin و Unicode. لفهمها ، من المهم تحويل الرموز الموجودة في البيانات إلى أحرف بسيطة وسهلة الفهم.
يتم ذلك غالبًا عن طريق التحويل إلى تنسيق ترميز قياسي مثل UTF-8. في المثال أدناه ، نرى كيف يتم تحويل النص بالكامل إلى نموذج يمكن قراءته آليًا:
text = 'I love Pizza 🍕! Shall we book a cab 🚕 to gizza?'
Text = text.encode("utf-8")
print(Text)
b'I love Pizza \xf0\x9f\x8d\x95!
Shall we book a cab \xf0\x9f\x9a\x95 to get pizza?'
التعامل مع فواصل
السمة المميزة الأخرى لـ بيانات منصات التواصل هي استخدام الفاصلة ؛ من الشائع جدًا مشاهدة سيناريوهات مثل ‘s, ‘re, ‘r ، إلخ. طريقة التعامل مع هذا هو توسيع الفواصل العليا. يتطلب هذا قاموسًا يمكنه تعيين الفواصل العليا للنماذج الكاملة:
Apostrophes_expansion = {
“'s" : " is",
"'re" : " are",
"'r" : " are", ...} ## Given such a dictionary
words = twokenize(tweet_text)
processed_tweet_text = [Apostrophes_expansion[word] if word
in Apostrophes_expansion else word for word in words]
processed_tweet_text = " ".join(processed_tweet_text)
التعامل مع الرموز التعبيرية
تعد الرموز التعبيرية (Emojis) في صميم التواصل عبر القنوات الاجتماعية. يمكن للصورة الصغيرة أن تصف تمامًا واحدًا أو أكثر من المشاعر البشرية. ومع ذلك ، فإنها تشكل تحديًا كبيرًا للآلات. كيف يمكننا تصميم أنظمة فرعية يمكنها فهم معنى الرموز التعبيرية؟ من السذاجة القيام به أثناء المعالجة المسبقة هو إزالة جميع الرموز التعبيرية. هذا يمكن أن يؤدي إلى فقدان كبير للمعنى.
من الطرق الجيدة لتحقيق ذلك استبدال الرموز التعبيرية بالنص المقابل الذي يوضح الرموز التعبيرية . للقيام بذلك ، نحتاج إلى ربط بين الرموز التعبيرية والتوضيح المقابل في النص. Demoji هي حزمة Python تقوم بهذا بالضبط. يحتوي على وظيفة ، findall () ، والتي تقدم قائمة بجميع الرموز التعبيرية في النص مع المعاني المقابلة لها.
tweet = "#startspreadingthenews yankees win great start by going 5strong
innings with 5k’s solo homerun with 2 solo homeruns
and 3run homerun… with rbi’s … and
to close the game!!!….WHAT A GAME!! "
demoji.findall(tweet)
{
"": "fire",
"": "volcano",
"️": "man judge: medium skin tone",
"": "Santa Claus: medium-dark skin tone",
"": "flag: Mexico",
"": "ogre",
"": "clown face",
"": "flag: Nicaragua",
"": "person rowing boat: medium-light skin tone",
"": "ox",
}
يمكننا استخدام إخراج findall () لاستبدال جميع الرموز التعبيرية في النص بالمعنى المقابل لها في الكلمات.
الكلمات المنقسمة المشتركة
المستخدمين يجمعون أحيانًا كلمات متعددة في كلمة واحدة ، حيث يتم توضيح الكلمة باستخدام الأحرف الكبيرة ، على سبيل المثال GoodMorning و RainyDay و PlayInTheCold وما إلى ذلك. يقوم مقتطف الكود التالي بالمهمة بالنسبة لنا:
processed_tweet_text = “ “.join(re.findall(‘[A-Z][^A-Z]*’, tweet_text))
إزالة عناوين المواقع
اعتمادًا على التطبيق ، قد نرغب في إزالة عنوان URL بالكامل. يستبدل مقتطف الكود جميع عناوين URL بثابت ؛ في هذه الحالة ، Constant_url. بينما في الحالات الأبسط ، يمكننا استخدام regex ، مثل http\S+ ، في في معظم الحالات ، سيتعين علينا كتابة تعبير عادي مخصص مثل الذي يظهر في الكود التالي. هذا الكود معقد لأن بعض المنشورات الاجتماعية تحتوي على عناوين URL مقصرة بدلاً من عناوين URL الكاملة:
processed_tweet_text = “ “.join(re.findall(def process_URLs(tweet_text):
'''
إزالة عنواين المواقع
'''
UrlStart1 = regex_or('https?://', r'www\.')
CommonTLDs = regex_or( 'com','co\\.uk','org','net','info','ca','biz',
'info','edu','in','au')
UrlStart2 = r'[a-z0-9\.-]+?' + r'\.' + CommonTLDs +
pos_lookahead(r'[/ \W\b]')
# * not + for case of: "go to bla.com." -- don't want period
UrlBody = r'[^ \t\r\n<>]*?'
UrlExtraCrapBeforeEnd = '%s+?' % regex_or(PunctChars, Entity)
UrlEnd = regex_or( r'\.\.+', r'[<>]', r'\s', '$')
Url = (optional(r'\b') +
regex_or(UrlStart1, UrlStart2) +
UrlBody +
pos_lookahead( optional(UrlExtraCrapBeforeEnd) + UrlEnd))
Url_RE = re.compile("(%s)" % Url, re.U|re.I)
tweet_text = re.sub(Url_RE, " constant_url ", tweet_text)
# fix to handle unicodes in URL
URL_regex2 = r'\b(htt)[p\:\/]*([\\x\\u][a-z0-9]*)*'
tweet_text = re.sub(URL_regex2, " constant_url ", tweet_text)
return tweet_text‘[A-Z][^A-Z]*’, tweet_text))
هجاء غير قياسي
على وسائل التواصل الاجتماعي ، غالبًا ما يكتب الأشخاص كلمات بها أخطاء إملائية من الناحية الفنية. على سبيل المثال ، غالبًا ما يكتب الأشخاص حرفًا واحدًا أو أكثر عدة مرات ، كما هو الحال في “yessss” أو “ssssh” (بدلاً من “yes” أو “ssh”). هذا التكرار للأحرف شائع جدًا. يوجد أدناه طريقة بسيطة لإصلاح هذا. نستخدم حقيقة أنه في اللغة الإنجليزية ، لا تكاد توجد أي كلمات لها نفس الحرف ثلاث مرات متتالية. لذلك نقوم بالقص وفقًا لذلك:
def prune_multple_consecutive_same_char(tweet_text):
tweet_text = re.sub(r'(.)\1+', r'\1\1', tweet_text)
return tweet_text
فكرة أخرى هي استخدام مكتبات التصحيح الإملائي. يستخدم معظمهم شكلاً من أشكال قياس المسافة ، مثل تعديل المسافة أو مسافة Levenshtein. يحتوي TextBlob نفسه على بعض إمكانيات التصحيح الإملائي:
from textblob import TextBlob data = "His sellection is bery antresting" output = TextBlob(data).correct() print(output)
نأمل أن يمنحك هذا فكرة جيدة عن سبب أهمية المعالجة المسبقة ، عندما يتعلق الأمر ببيانات منصات التواصل الإجتماعي، وكيف يمكن تحقيقها. هذه ليست بأي حال قائمة شاملة لخطوات المعالجة المسبقة . الآن ، سنركز على الخطوة التالية في خط إنتاج معالجة اللغة الطبيعية لدينا هندسة السمات.
تمثيل النص لبيانات منصات التواصل الإجتماعي
في السابق ، رأينا كيفية عمل مصنف بسيط للمشاعر للتغريدات باستخدام TextBlob . الآن ، دعونا نحاول بناء مصنف أكثر تعقيدًا. لنفترض أننا قمنا بتنفيذ جميع خطوات المعالجة المسبقة التي ناقشناها. ماذا الآن؟ نحتاج الآن إلى تقسيم النص إلى عملات ثم تمثيلها رياضيًا. بالنسبة إلى للتعميل، نستخدم twokenize ، وهو مُعمل مخصص مصمم للعمل مع بيانات Twitter.
مناهج إنشاء المتجهات الأساسية مثل BoW و TF-IDF لا تعمل بشكل جيد هنا، ويرجع ذلك أساسًا إلى الضوضاء والاختلاف في البيانات النصية.
الضوضاء والاختلافات تؤدي إلى متجهات متناثرة للغاية. هذا يترك لنا خيار استخدام التضمينات. كما رأينا في هنا، فإن تدريب التضمينات الخاصة بنا مكلف للغاية.
لذلك ، يمكننا أن نبدأ باستخدام التضمينات المدربة مسبقًا. رأينا كيفية استخدام تضمين الكلمات المدربة مسبقًا من Google لبناء مصنف المشاعر.
الآن ، إذا قمنا بتشغيل نفس الكود على مجموعة البيانات الخاصة بنا التي تم جمعها من منصات التواصل الاجتماعي ، فقد لا نحصل على أرقام مثيرة للإعجاب كما حدث هناك. قد يكون أحد الأسباب هو أن مفردات مجموعة البيانات الخاصة بنا تختلف اختلافًا كبيرًا عن مفردات نموذج Word2vec.
للتحقق من ذلك ، نقوم فقط بتعميل مجموعة النصوص الخاصة بنا وإنشاء مجموعة على جميع العملات ، ثم مقارنتها بمفردات Word2vec. يقوم مقتطف الكود التالي بهذا:
combined = tokenizer(train_test_X) flat_list = chain(*combined) dataset_vocab = set(flat_list) len(dataset_vocab) w2v_vocab = set(w2v_model.vocab.keys()) print(dataset_vocab - w2v_vocab)
هنا ، train_test_X هو مجموعة المراجعات المجمعة من مجموعات التدريب والاختبار في مجموعتنا.
الأن كيف نصلح هذا؟ وهناك عدد قليل من الطرق:
- استخدم التضمينات المدربة مسبقًا على البيانات الاجتماعية ، مثل تلك الموجودة في مجموعة ستانفورد في معالجة اللغة الطبيعية . قاموا بتدريب التضمينات على ملياري تغريدة .
- استخدم مٌعمل أفضل. مثل مُعمل twokenize من عمل Allen Ritter .
تدريب التضمينات الخاصة بك. يجب أن يكون هذا الخيار هو الملاذ الأخير ولا يتم تنفيذه إلا إذا كان لديك الكثير والكثير من البيانات (على الأقل 1 إلى 1.5 مليون تغريدة). حتى بعد تدريب التضمينات الخاصة بك ، قد لا تحصل على أي ارتفاع كبير في مقاييس الأداء.
حتى إذا حصلت على تحسن كبير في مقاييس الأداء ، بينما تستمر الفجوة الزمنية بين بيانات التدريب وبيانات الإنتاج في الازدياد ، يمكن أن يستمر الأداء في الانخفاض. هذا لأنه مع زيادة الفجوة الزمنية ، يستمر التداخل بين مفردات بيانات التدريب وبيانات الإنتاج في الانخفاض.
أحد الأسباب الرئيسية لذلك هو حقيقة أن مفردات وسائل التواصل الاجتماعي تتطور دائمًا – يتم إنشاء كلمات ومختصرات جديدة واستخدامها طوال الوقت. قد تعتقد أن الكلمات الجديدة تتم إضافتها مرة واحدة فقط كل فترة ، ولكن من المدهش أن هذا بعيد كل البعد عن الحقيقة.
يوضح الشكل أدناه مدى السرعة التي يمكن أن تتطور بها المفردات على وسائل التواصل الاجتماعي .
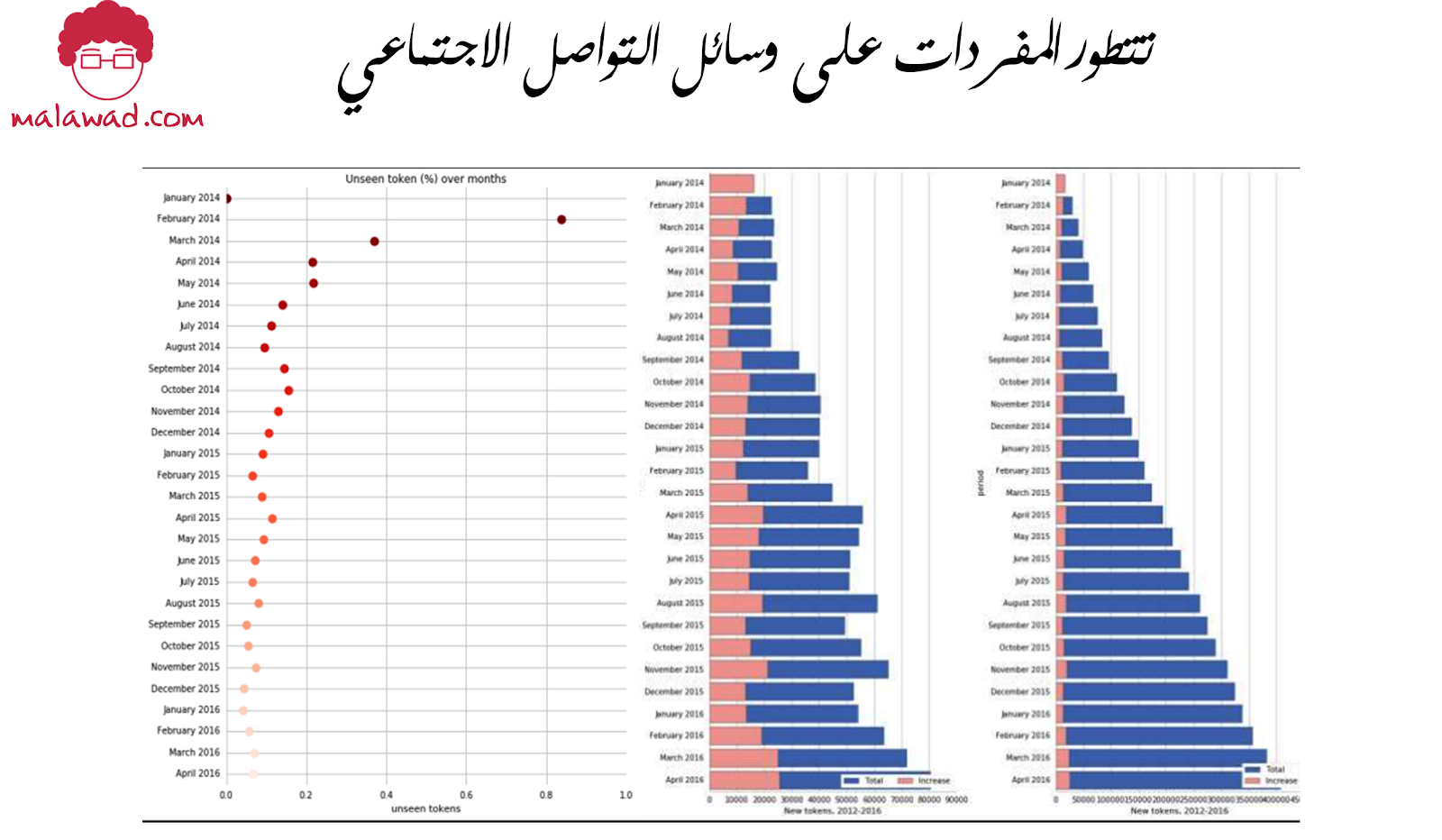
تم إجراء هذا التحليل باستخدام ما يقرب من 2 مليون تغريدة على مدى 27 شهرًا.
- تُظهر الرسمة الموجودة على اليسار النسبة المئوية للعملات غير المرئية على أساس شهري.
- تُظهر الرسمة في المنتصف نفس الإحصائيات مثل مخطط شريطي إجمالي مقابل العملات الجديدة على أساس شهري.
- الرسمة الموجودة على اليمين مخطط شريطي تراكمي. في المتوسط ، ما يقرب من 20٪ من مفردات أي شهر هي كلمات جديدة.
ماذا يعني هذا بالنسبة لنا؟ بغض النظر عن مدى جودة التضمينات لدينا ، نظرًا لتطور مفردات وسائل التواصل الاجتماعي ، في غضون شهرين ، ستصبح التضمينات لدينا قديمة (على سبيل المثال ، لن يكون جزء كبير من مفرداتنا موجودًا في التضمينات لدينا) .
هذا يعني أنه عندما نقوم بالاستعلام عن نموذج التضمين بكلمة لجلب التضمين ، فإنه سيعود فارغًا لأن كلمة الاستعلام لم تكن موجودة في بيانات التدريب عندما تم تدريب التضمينات. سيؤدي هذا بدوره إلى تقليل دقة مصنف المشاعر بشكل كبير مع مرور الوقت ، لأنه بمرور الوقت ، سيتم تجاهل المزيد والمزيد من الكلمات.
حدد الباحثون العاملون في هذا المجال هذه المشكلة في وقت مبكر جدًا وجربوا طرقًا مختلفة للالتفاف عليها. واحدة من أفضل الطرق للتعامل مع مشكلة خارج المفرادات المستمرة مع منصات التواصل هي استخدام تضمينات n-gram.
كل حرف n-gram في البيانات يحتوي على تضمين له. الآن ، إذا كانت الكلمة موجودة في مفردات التضمينات ، فإننا نستخدم كلمة التضمين مباشرة.
إذا لم يكن الأمر كذلك – أي أن الكلمة هي خارج المفردات- فنحن نقسم الكلمة إلى حرف n-grams ودمج كل هذه التضمينات للتوصل إلى تضمين للكلمة.
يحتوي fastText على تضمينات مدربة مسبقًا على حرف n-gram ولكنها ليست محددة على Twitter. جرب الباحثون أيضًا التضمينات للحروف. [هنا ، هنا، هنا، هنا].
دعم العملاء على القنوات الاجتماعية
منذ نشأتها وحتى يومنا هذا ، تطورت وسائل التواصل الاجتماعي كقناة اتصال. بدأت بشكل أساسي بهدف مساعدة الناس في جميع أنحاء العالم على التواصل والتعبير عن أنفسهم. لكن التبني الواسع لوسائل التواصل الاجتماعي أجبر العلامات التجارية والمؤسسات على إلقاء نظرة أخرى على استراتيجيات الاتصال الخاصة بهم. وخير مثال على ذلك هو العلامات التجارية التي تقدم دعم العملاء على المنصات الاجتماعية مثل Twitter و Facebook. لم تنوي العلامات التجارية أبدًا القيام بذلك في البداية.
في وقت مبكر من هذا العقد الماضي ، مع نمو اعتماد المنصات الاجتماعية ، بدأت العلامات التجارية في إنشاء وامتلاك ممتلكات وأصول مثل حسابات Twitter وصفحات Facebook للوصول بشكل أساسي إلى عملائها ومستخدميها وتشغيل حملات ترويجية وتسويقية.
ومع ذلك ، مع مرور الوقت ، لاحظت العلامات التجارية أن المستخدمين والعملاء يتواصلون معهم من خلال الشكاوى والتظلمات. مع تزايد حجم الشكاوى والقضايا ، دفع هذا العلامات التجارية إلى إنشاء حسابات وصفحات مخصصة للتعامل مع حركة مرور الدعم.
أطلق Twitter و Facebook ميزات متنوعة لدعم العلامات التجارية ، وتدعم معظم أدوات إدارة علاقات العملاء (customer relationship management) أو (CRM) خدمة العملاء على القنوات الاجتماعية. يمكن للعلامة التجارية ربط قنواتها الاجتماعية بأداة CRM واستخدام الأداة للرد على الرسائل الواردة.
بسبب الطبيعة العامة للمحادثات ، العلامات التجارية ملزمة بالاستجابة بسرعة. ومع ذلك ، تتلقى صفحات دعم العلامات التجارية عددًا كبيرًا من الزيارات.
بعض هذه الأسئلة والتظلمات والطلبات حقيقية. تُعرف هذه باسم “المحادثات القابلة للتنفيذ” ، حيث يجب على فرق دعم العملاء العمل عليها بسرعة. من ناحية أخرى ، فإن جزءًا كبيرًا من حركة المرور هو مجرد ضوضاء: العروض الترويجية ، والقسائم ، والعروض ، والآراء ، ورسائل التصيد ، وما إلى ذلك ، وهذا ما يسمى “الضوضاء”. لا تستطيع فرق دعم العملاء الاستجابة للضوضاء وتريد الابتعاد عن كل هذه الرسائل. من الناحية المثالية ، يريدون فقط تحويل الرسائل القابلة للتنفيذ إلى تذاكر في أدوات CRM الخاصة بهم.
تخيل أننا نعمل في مؤسسة منتجات CRM ويطلب منك بناء نموذج لفصل الرسائل القابلة للتنفيذ عن الضوضاء. كيف يمكننا أن نفعل ذلك؟ تتشابه مشكلة تحديد الضوضاء مقابل الرسائل القابلة للتنفيذ مع مشكلة تصنيف البريد العشوائي أو مشكلة تصنيف المشاعر. يمكننا بناء نموذج يمكنه إلقاء نظرة على الرسائل الواردة. سيكون خط الإنتاج مشابهًا جدًا:
- اجمع مجموعة بيانات مصنفة
- نظفه
- قم بمعالجتها مسبقًا
- قم بتعميلها
- قم بتمثيله
- تدريب نموذج
- إختبار النموذج
- وضع النموذج في الإنتاج
ختاما
في هذا المقال، ملقينا نظرة مفصلة على تطبيقات معالجة اللغة الطبيعية المختلفة ، مثل إنشاء سحابات الكلمات ، واكتشاف الموضوعات الشائعة على Twitter ، وفهم مشاعر التغريد ، ودعم العملاء على وسائل التواصل الاجتماعي لقد رأينا أيضًا مجموعة من مشكلات معالجة النصوص التي قد نواجهها أثناء تطوير هذه الأدوات وكيفية حلها













إضافة تعليق