
عند الانتهاء من إنشاء مئات الآلاف من السمات ، فقد حان الوقت لتحديد عدد قليل منها. حسنًا ، لا يجب أبدًا إنشاء مئات الآلاف من السمات غير المجدية. إن وجود الكثير من السمات يمثل مشكلة معروفة باسم لعنة الأبعاد ( curse of dimensionality) . إذا كان لديك الكثير من السمات ، فيجب أن يكون لديك أيضًا الكثير من عينات التدريب لالتقاط جميع السمات. ما يعتبر “كثير” لم يتم تعريفه و تحديده لكن يعود الأمر إليك لمعرفة ذلك من خلال إطار التحقق الخاصة بك بالإضافة إلى التحقق من الوقت المستغرق لتدريب نماذجك.
إختيار السمات بناءً على التباين
إن أبسط أشكال اختيار السمات هو إزالة السمات ذات التباين المنخفض جدًا. إذا كانت السمات ذات تباين منخفض جدًا (أي قريبة جدًا من 0) ، فهي قريبة من أن تكون ثابتة ، وبالتالي ، لا تضيف أي قيمة إلى أي نموذج على الإطلاق. سيكون من الجيد التخلص منها وبالتالي تقليل التعقيد. يرجى ملاحظة أن التباين يعتمد أيضًا على قياس البيانات.
لدى Scikit-Learn تطبيق لـ VarianceThreshold يقوم بهذا بالضبط.
from sklearn.feature_selection import VarianceThreshold data =... var_thresh = VarianceThreshold(threshold=0.1) transformed_data = var_thresh.fit_transform(data) # البيانات المحولة ستحتوي على جميع الأعمدة بتباين أقل # تمت إزالة ما يقل عن 0.1
يمكننا أيضًا إزالة السمات التي لها ارتباط كبير (high correlation) . لحساب الارتباط بين السمات العددية المختلفة ، يمكنك استخدام ارتباط بيرسون (Pearson correlation) .
import pandas as pd import numpy as np from sklearn.datasets import fetch_california_housing # الحصول على بيانات الإنحدار data = fetch_california_housing() X = data["data"] col_names = data["feature_names"] y = data["target"] # تحويل إلى إطار بيانات باندا df = pd.DataFrame(X, columns=col_names) # أحد الأعمدة التي لديها إرتباط عالي df.loc[:, "MedInc_Sqrt"] = df.MedInc.apply(np.sqrt) df.corr()
والتي تعطي مصفوفة ارتباط ، كما هو موضح أدناه.
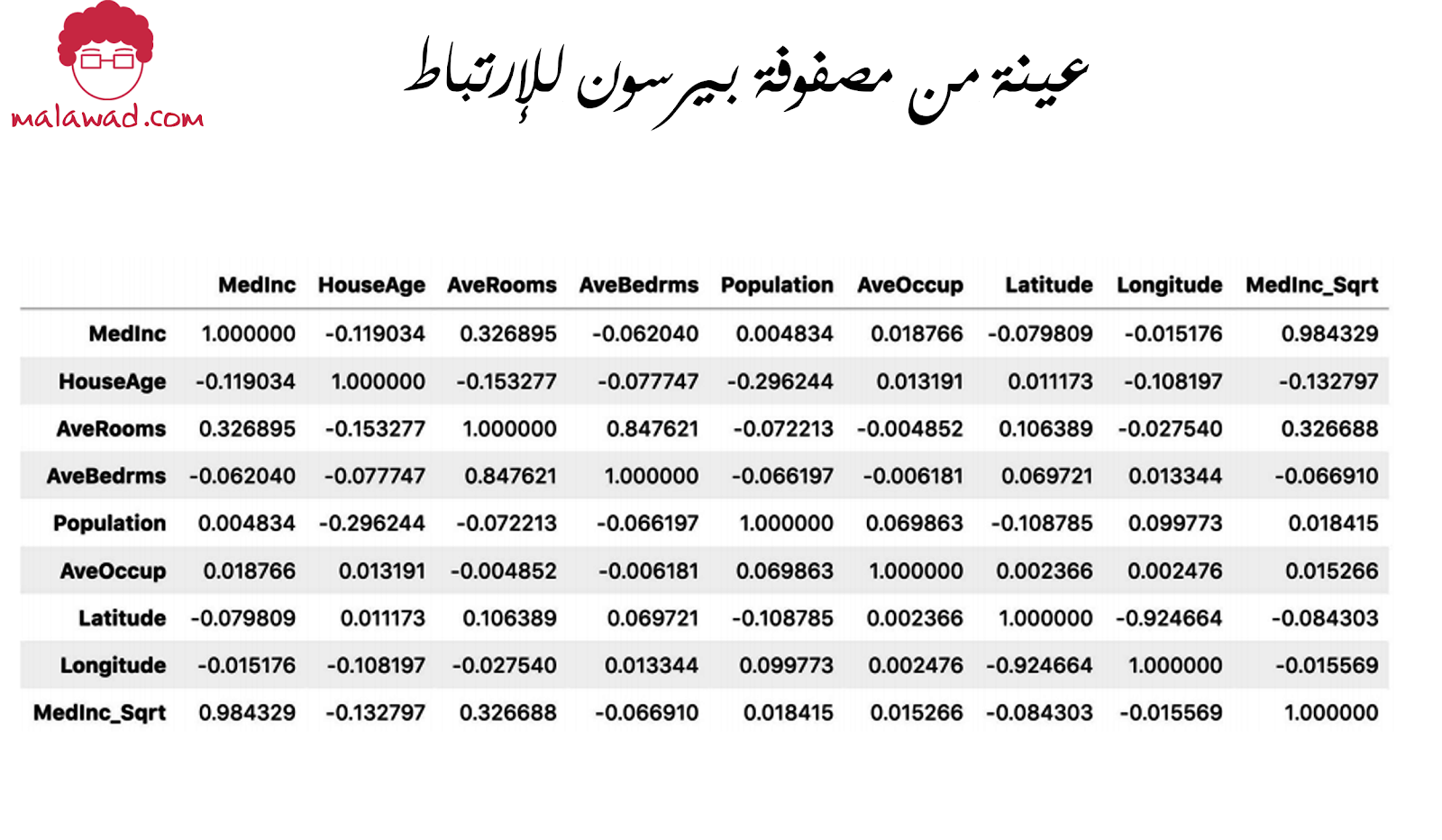
نرى أن سمه MedInc_Sqrt لها ارتباط كبير جدًا مع MedInc. وبالتالي يمكننا إزالة واحد منهم.
والآن يمكننا الانتقال إلى بعض الطرق أحادية المتغير لاختيار السمه.
إختيار السمات أحادية المتغير (Univariate feature selection)
اختيار سمه أحادية المتغير ليس سوى تسجيل كل سمه مقابل هدف معين. تعد المعلومات المتبادلة و ANOVA F-test و chi2 من أكثر الطرق شيوعًا لاختيار السمات أحادية المتغير. هناك طريقتان لاستخدام هذه في scikitlearn.
– SelectKBest: يحافظ على سمات ذات أعلى درجات k
– SelectPercentile: يحافظ على أهم السمات التي تكون في النسبة المئوية المحددة من قبل المستخدم
وتجدر الإشارة إلى أنه يمكنك استخدام chi2 فقط للبيانات غير السلبية بطبيعتها. يعد هذا أسلوبًا مفيدًا بشكل خاص لاختيار سمه في معالجة اللغة الطبيعية عندما يكون لدينا حقيبة من الكلمات أو سمات قائمة على tf-idf.
و نقوم بهذا كالأتي
from numpy.lib.function_base import select
from sklearn.feature_selection import chi2
from sklearn.feature_selection import f_classif
from sklearn.feature_selection import f_regression
from sklearn.feature_selection import mutual_info_classif
from sklearn.feature_selection import mutual_info_regression
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import SelectPercentile
class UnivariateFeatureSelction:
def __init__(self, n_features, problem_type, scoring):
# لنوع مشكلة معين ، هناك فقط
# بعض طرق التسجيل الصالحة
# يمكنك تمديد هذا مع الطرق الخاص بك
if problem_type == "classification" :
valid_scoring = {
"f_classif" : f_classif,
"chi2" : chi2,
"mutual_info_classif" : mutual_info_classif
}
else:
valid_scoring = {
"f_regression" : f_regression,
"mutual_info_regression": mutual_info_regression
}
if scoring not in valid_scoring:
raise Exception("invalide scoroing function")
# selectkbest عدد صحيح نستخدم n_features لو كانت
# selectpercentile عدد عائم نستخدم n_features لو كانت
if isinstance(n_features, int):
self.selection = SelectKBest(
valid_scoring[scoring],
k=n_features
)
elif isinstance(n_features,float):
self.selection = SelectPercentile(
valid_scoring[scoring],
percentile=int(n_features *100)
)
else:
raise Exception("invalid type of feature")
def fit(self, X,y):
return self.selection.fit(X,y)
def transform(self, X):
return self.selection.transform(X)
def fit_transform(self, X, y):
return self.selection.fit_transform(X,y)
و استخدامه بسيط للغاية
ufs = UnivariateFeatureSelction( n_features=0.1, problem_type="regression", scoring="f_regression" ) ufs.fit(X, y) X_transformed = ufs.transform(X)
يجب أن يعتني ذلك بمعظم احتياجات في اختيار السمه أحادية المتغير. الرجاء ملاحظة أنه من الأفضل عادةً إنشاء سمات أقل و أكثر أهمية من إنشاء مئات السمات في المقام الأول. قد لا يؤدي اختيار سمه أحادية المتغير عمل جيد دائمًا. في معظم الأوقات ، يفضل الأشخاص اختيار السمات باستخدام نموذج التعلم الآلة. دعونا نرى كيف يتم ذلك.
إختيار السمات باستخدام نماذج تعلم الألة
اختيار السمات الجشع (greedy feature selection)
يُعرف أبسط شكل من أشكال تحديد السمه الذي يستخدم نموذجًا للاختيار باسم اختيار السمات الجشع (greedy feature selection) . في اختيار السمه الجشع ، فإن:
- الخطوة الأولى هي اختيار نموذج.
- الخطوة الثانية هي تحديد وظيفة الخسارة / النتيجة.
- والخطوة الثالثة والأخيرة هي التقييم المتكرر لكل سمه وإضافتها إلى قائمة السمات “الجيدة” إذا كانت تحسن الخسارة / النتيجة
لا يمكن أن يكون أبسط من هذا. لكن يجب أن تضع في اعتبارك أن هذا يُعرف باسم اختيار السمه الجشعة لسبب ما. ستلائم عملية اختيار السمه هذه نموذجًا معينًا في كل مرة يتم فيها تقييم السمه. التكلفة الحسابية المرتبطة بهذا النوع من الطرق عالية جدًا. سيستغرق الأمر أيضًا الكثير من الوقت حتى ينتهي هذا النوع من اختيار السمات. وإذا لم تستخدمه بشكل صحيح ، فقد ينتهي بك الأمر إلى فرط تخصيص (overfitting) النموذج .
دعونا نرى كيف بتم تطبيق هذا
from numpy.lib.function_base import select
import pandas as pd
from sklearn import linear_model
from sklearn import metrics
from sklearn.datasets import make_classification
class GreedyFeatureSelection:
"""
فئة بسيطة ومخصصة لاختيار الميزات الجشعة.
ستحتاج إلى تعديله بعض الشيئ لجعله
مناسبًا لمجموعة البيانات الخاصة بك
"""
def evaluate_score(self, X, y):
"""
تقوم هذه الوظيفة بتقييم النموذج على البيانات والإرجاع
(AUC) ROC المنطقة الواقعة تحت منحنى
على نفس البيانات AUC ملاحظة: نحن نلائم البيانات ونحسب .
OVERFITTING نحن نقوم بفرط التخصيص .
لكن هذه أيضًا طريقة لتحقيق الاختيار الجشع.
k مدة أطول بمقدار k-fold سوف يستغرق .
إذا كنت ترغب في تنفيذه بطريقة صحيحة حقًا ،
k على طيات AUC وإرجاع متوسط OOF AUC فقم بحساب .
هذا يتطلب فقط تعديل بضعة أسطر
: param X: بيانات التدريب
: param X: الأهداف
: return: overfitted area under the roc curve.
"""
# مناسبت نموذج الانحدار اللوجستي ،
# على نفس البيانات AUC وحساب
# مرة أخرى
# يمكنك اختيار أي نموذج يناسب بياناتك
model = linear_model.LogisticRegression()
model.fit(X, y)
predictions = model.predict_proba(X)[:, 1]
auc = metrics.roc_auc_score(y, predictions)
def _feature_selection(self, X, y):
"""
تقوم هذه الوظيفة بالاختيار الجشع
: param X: data، numpy array
: param y: targets, numpy array
: return: (best scores, best features)
"""
# تهيئة قائمة السمات الجيدة
# وأفضل النتائج لتتبع كليهما
good_features = []
best_scores = []
# حساب عدد السمات
num_features = X.shape[1]
# حلقة لا نهائية
while True:
# تهيئة أفضل سمه و نتيجة لهذه الحلقة
this_feature = None
best_score = 0
# إنشاء حلقة على كل السمات
for feature in range(num_features):
# لو كانت السمه في قائمة سمه جيدة
# فتجاهل الحلقة
if feature in good_features:
continue
selected_features = good_features + [feature]
# إزالة السمات الأخرى
xtrain = X[:, selected_features]
# AUC حساب النتيجة في حالتنا
score = self.evaluate_score(xtrain, y)
# لو كانت النتيجة أكبر من أفضل نتيجة
# في هذه الحلفة فغير أفضل نتيجة و أفضل سمة
if score > best_score:
this_feature = feature
best_score = score
# لو إخترنا سمة
# فأضفها لقائمة السمات الجيدة و حدث قائمة أفضل النتائج
if this_feature != None:
good_features.append(this_feature)
best_scores.append(best_score)
# إذا لم يحدث أي تحسن في أخر حلقتين
# أخرج من الحلفة
if len(best_scores) > 2:
if best_score[-1] < best_score[-2]:
break
# أخرج أفضل نتائج و أفضل سمات
return best_scores[:-1], good_features[:-1]
def __call__(self, X, y) :
scores, features = self._feature_selection(X,y)
return X[:,features], scores
if __name__ == "__main__" :
# إنشاء بيانات التصنيف الثنائي
X, y = make_classification(n_samples=1000, n_features=100)
# تحويل البيانات عن طريق اختيار ألسمات الجشع
x_transformed, scores = GreedyFeatureSelection()(X,y)
تطبيق اختيار السمه الجشع بهذا الشكل يخرج لنا الدرجات وقائمة مؤشرات السمات. توضح الصورة أدناه كيف تتحسن هذه النتيجة بإضافة سمه جديدة في كل تكرار. نرى أننا غير قادرين على تحسين درجاتنا بعد نقطة معينة ، وهنا نتوقف

إزالة السمه العودية (recursive feature elimination)
يُعرف نهج جشع آخر بإسم إزالة السمه العودية (recursive feature elimination) أو (RFE). في الطريقة السابقة ، بدأنا بسمه واحدة واستمرنا في إضافة سمات جديدة ، ولكن في RFE ، نبدأ بجميع السمات ونستمر في إزالة سمه واحدة في كل تكرار توفر أقل قيمة لنموذج معين. ولكن كيف نعرف السمه التي تقدم أقل قيمة؟
حسنًا ، إذا استخدمنا نماذج مثل آلية متجه الدعم الخطي (SVM) أو الانحدار اللوجستي ، فسنحصل على معامل لكل سمه تحدد أهمية السمات. في حالة وجود أي نماذج قائمة على الأشجار ، نحصل على أهمية السمه بدلاً من المعاملات. في كل تكرار ، يمكننا حذف السمه الأقل أهمية والاستمرار في إزالتها حتى نصل إلى عدد السمات المطلوبة. لذا ، نعم ، لدينا القدرة على تحديد عدد السمات التي نريد الاحتفاظ بها.
عندما نستخدم إزالة السمه العودية ، في كل تكرار ، نزيل السمه التي لها أهمية السمه أو السمه التي لها معامل قريب من 0. يرجى تذكر أنه عند استخدام نموذج مثل الانحدار اللوجستي للتصنيف الثنائي ، فإن المعاملات (coefficients) للسمات تكون أكثر إيجابية إذا كانت مهمة للفئة الإيجابية وأكثر سلبية إذا كانت مهمة للفئة السلبية. من السهل جدًا تعديل فئة اختيار السمات الجشعة الخاصة بنا لإنشاء فئة جديدة لإزالة السمات العودية ، ولكن scikit-Learn توفر أيضًا RFE مباشر .
يتم عرض استخدام بسيط في المثال التالي.
import pandas as pd
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()
X = data["data"]
col_name = data["feature_names"]
y = data["target"]
# تهيئة النموذج
model = LinearRegression()
rfe = RFE(
estimator = model,n_features_to_select=3
)
rfe.fit(X,y)
X_transformed = rfe.transform(X)
إختيار السمات بواسطة المعاملات أو الأهمية
رأينا طريقتين جشعين مختلفتين لاختيار سمات من نموذج. ولكن يمكنك أيضًا ملاءمة النموذج للبيانات وتحديد سمات من النموذج حسب معاملات السمه (feature coefficients) أو أهمية السمات (importance of features). إذا كنت تستخدم معاملات ، فيمكنك تحديد حد ، وإذا كان المعامل أعلى من هذا الحد ، فيمكنك الاحتفاظ بالسمه وإلا ستزيلها.
دعونا نرى كيف يمكننا الحصول على أهمية السمه من نموذج مثل Random Forest.
import pandas as pd from sklearn.datasets import load_diabetes from sklearn.ensemble import RandomForestRegressor data = load_diabetes() X = data["data"] col_name = data["feature_names"] y = data["target"] #تهيئة النموذج model = RandomForestRegressor() model.fit(X,y)
يمكن رسم أهمية السمه من الغابة العشوائية (أو أي نموذج) على النحو التالي.
importances = model.feature_importances_
idxs = np.argsort(importances)
plt.title('Feature Importances')
plt.barh(range(len(idxs)), importances[idxs], align='center')
plt.yticks(range(len(idxs)), [col_names[i] for i in idxs])
plt.xlabel('Random Forest Feature Importance')
plt.show()

حسنًا ، اختيار أفضل السمات من النموذج ليس بالأمر الجديد. يمكنك اختيار سمات من نموذج واحد واستخدام نموذج آخر للتدريب. على سبيل المثال ، يمكنك استخدام معاملات الانحدار اللوجستي لتحديد السمات ثم استخدام الغابة العشوائية لتدريب النموذج على السمات المختارة.
تقدم Scikit-Learn أيضًا فئة SelectFromModel تساعدك في اختيار السمات مباشرةً من نموذج معين. يمكنك أيضًا تحديد الحد الأدنى للمعاملات أو أهمية السمه إذا كنت تريد والحد الأقصى لعدد السمات التي تريد تحديدها.
ألق نظرة على المقتطف التالي حيث نختار السمات باستخدام المعلمات الافتراضية في SelectFromModel.
import pandas as pd from sklearn.datasets import load_diabetes from sklearn.ensemble import RandomForestRegressor from sklearn.feature_selection import SelectFromModel data = load_diabetes() X = data["data"] col_names = data["feature_names"] y = data["target"] model = RandomForestRegressor() # إختيار من النموذج sfm = SelectFromModel(estimator = model) X_transformed = sfm.fit_transform(X, y) # لننظر أي سمات تم إختيارها support = sfm.get_support() # طباعة أسماء السمات print([ x for x, y in zip(col_names, support) if y == True ])
الذي يطبع: [‘bmi’، ‘s5’]. عندما ننظر في الصورة أعلاه ، نرى أن هذه هي أهم سمتين . وبالتالي ، كان بإمكاننا أيضًا الاختيار مباشرة من أهمية السمه التي توفرها Random Forest.
هناك شيء آخر نفتقده هنا وهو اختيار السمات باستخدام النماذج التي تحتوي على عقوبة L1 (Lasso) penalization.. عندما يكون لدينا عقوبة L1 للتنظيم ، فإن معظم المعاملات ستكون 0 (أو قريبة من 0) ، ونختار السمات ذات المعاملات غير الصفرية.
يمكنك القيام بذلك عن طريق استبدال الغابة العشوائية في مقتطف التحديد من النموذج بنموذج يدعم عقوبة L1 ، على سبيل المثال انحدار لاسو (lasso regression.) . توفر جميع النماذج المستندة إلى الأشجار أهمية سمه لذا يمكن استخدام جميع الأكواد الموضحة في هذا المقال لـ XGBoost أو LightGBM أو CatBoost.
قد تكون أسماء وظائف أهمية السمه مختلفة وقد تنتج نتائج بتنسيق مختلف ، ولكن سيظل الاستخدام كما هو.
في النهاية ، يجب أن تكون حذرًا عند اختيار السمه. حدد السمات الموجودة في بيانات التدريب وتحقق من صحة النموذج في بيانات التحقق من أجل التحديد المناسب للسمات دون تغيير النموذج.













إضافة تعليق