
يعاني الكثير من الناس عند التعامل مع المتغيرات الفئوية (categorical variables) ، في هذا المقال سأتحدث عن أنواع مختلفة من البيانات الفئوية وكيفية التعامل مع مشكلة ما باستخدام المتغيرات الفئوية.
ما هي المتغيرات الفئوية؟
المتغيرات / السمات الفئوية هي أي نوع من السمات يمكن تصنيفها إلى نوعين رئيسيين:
• الاسمية (Nominal)
• الترتيبية (Ordinal)
المتغيرات الاسمية (Nominal variables) هي متغيرات لها فئتان أو أكثر ليس لها أي نوع من الترتيب المرتبط بها. على سبيل المثال ، إذا تم تصنيف الجنس إلى مجموعتين ، أي ذكر وأنثى ، فيمكن اعتباره متغيرًا اسميًا.
المتغيرات الترتيبية (Ordinal variables) من ناحية أخرى ، فإن المتغيرات الترتيبية لها “مستويات” أو فئات ذات ترتيب معين مرتبط بها. على سبيل المثال ، يمكن أن يكون المتغير الترتيبي الفئوي سمة ذات ثلاثة مستويات مختلفة: منخفض ومتوسط وعالي. الترتيب مهم.
بقدر ما يتعلق الأمر بالتعريفات ، يمكننا أيضًا تصنيف المتغيرات الفئوية على أنها ثنائية ، أي متغير فئوي بفئتين فقط. حتى أن البعض يتحدث عن نوع يسمى “دوري (cyclic)” للمتغيرات الفئوية.
المتغيرات الدورية (Cyclic variables) موجودة في “دورات” على سبيل المثال ، أيام الأسبوع: الأحد ، الاثنين ، الثلاثاء ، الأربعاء ، الخميس ، الجمعة والسبت. بعد يوم السبت ، لدينا يوم الأحد مرة أخرى. هذه دورة. مثال آخر سيكون ساعات في اليوم إذا اعتبرناها فئات.
هناك العديد من التعريفات المختلفة للمتغيرات الفئوية ، ويتحدث الكثير من الناس عن التعامل مع المتغيرات الفئوية بشكل مختلف اعتمادًا على نوع المتغير الفئوي. ومع ذلك ، لا أرى أي حاجة لذلك. يمكن التعامل مع جميع مشاكل المتغيرات الفئوية بنفس الطريقة.
قبل أن نبدأ ، نحتاج إلى مجموعة بيانات للعمل معها (كما هو الحال دائمًا). واحدة من أفضل مجموعات البيانات المجانية لفهم المتغيرات الفئوية هي cat-in-the-dat من تحدي ترميز السمات الفئوية من Kaggle. كان هناك تحديين ، وسنستخدم البيانات من التحدي الثاني (هنا) حيث كان يحتوي على متغيرات أكثر وكان أصعب من الإصدار السابق.
مجموعة البيانات
دعونا نلقي نظرة على البيانات.

تتكون مجموعة البيانات من جميع أنواع المتغيرات الفئوية:
• اسمي
• ترتيبي
• دوري
• ثنائي
في الصورة أعلاه ، نرى فقط مجموعة فرعية من جميع المتغيرات الموجودة والمتغير الهدف.
إنها مشكلة تصنيف ثنائي.
الهدف ليس مهمًا جدًا بالنسبة لنا لتعلم المتغيرات الفئوية ، ولكن في النهاية ، سنبني نموذجًا متكاملاً ، لذلك دعونا نلقي نظرة على التوزيع المستهدف في الصورة أدناه.
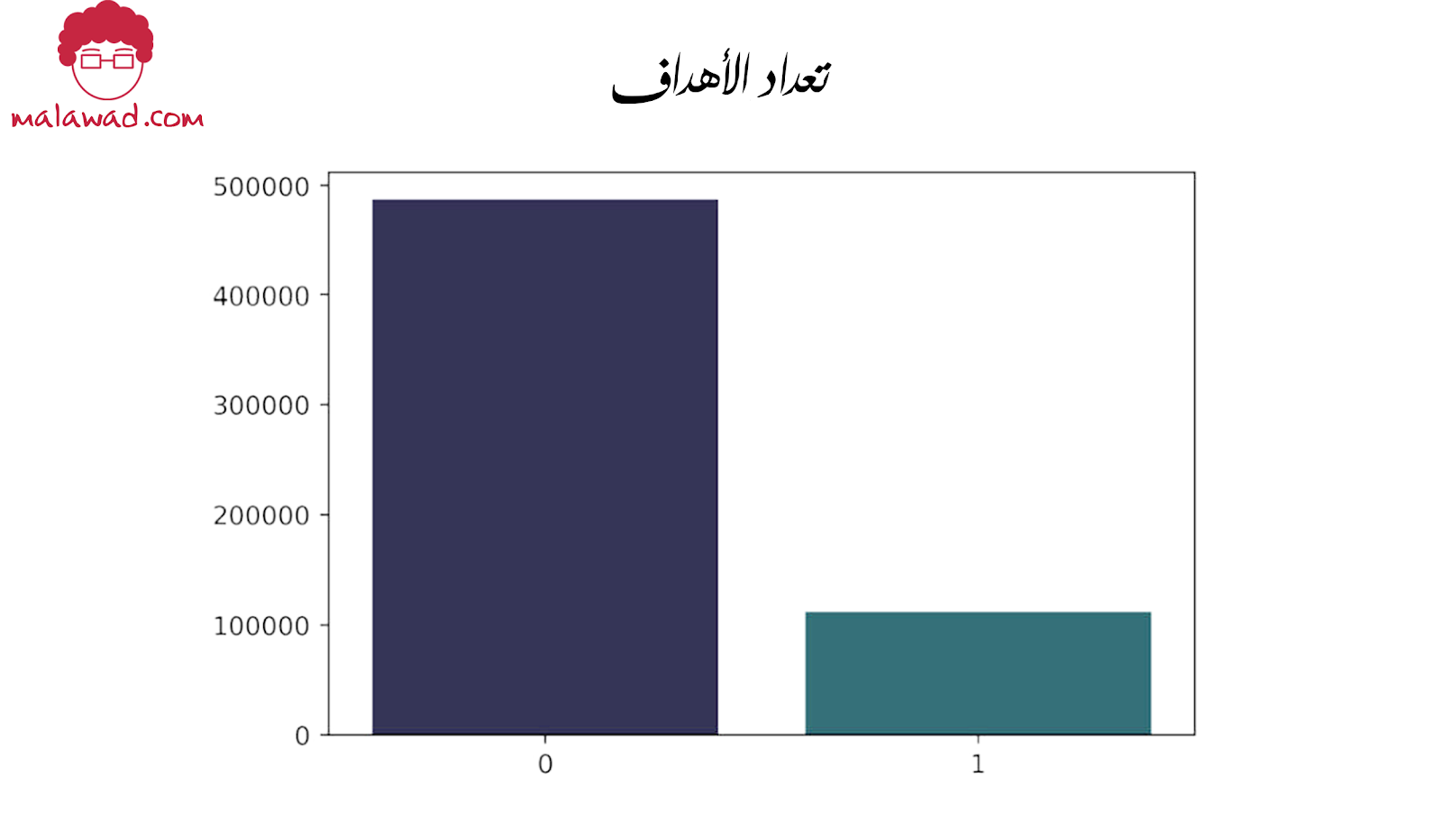
نرى أن الهدف منحرف و وبالتالي فإن أفضل مقياس لمشكلة التصنيف الثنائي سيكون المنطقة الواقعة تحت منحنى ROC (AUC). يمكننا استخدام الضبط والاستدعاء أيضًا ، لكن AUC يجمع بين هذين المقياسين. وبالتالي ، سنستخدم AUC لتقييم النموذج الذي نبنيه على مجموعة البيانات هذه.
بشكل عام ، هناك:
• خمسة متغيرات ثنائية
• عشرة متغيرات اسمية
• ستة متغيرات ترتيبية
• متغيرين دوريين
• ومتغير مستهدف.
دعنا نلقي نظرة على سمه ord_2 في مجموعة البيانات. تتكون من ست فئات مختلفة:
• Freezing
• Warm
• Cold
• Boiling Hot
• Hot
• Lava Hot
علينا أن نعلم أن أجهزة الكمبيوتر لا تفهم البيانات النصية ، وبالتالي ، نحتاج إلى تحويل هذه الفئات إلى أرقام. تتمثل إحدى الطرق البسيطة للقيام بذلك في إنشاء قاموس يقوم بتعيين هذه القيم إلى أرقام تبدأ من 0 إلى N-1 ، حيث يمثل N العدد الإجمالي للفئات في ميزة معينة.
import pandas as pd
mapping = {
"Freezing" : 0,
"Warm" : 1,
"Cold" : 2,
"Boiling Hot" : 3,
"Hot" : 4,
"Lava Hot" : 5
}
الآن ، يمكننا قراءة مجموعة البيانات وتحويل هذه الفئات إلى أرقام بسهولة.
import pandas as pd
df = pd.read_csv("../input/cat_train.csv")
df.loc[: ,"ord_2"] = df.ord_2.map(mapping)
حساب القيمة قبل التعيين:
df.ord_2.value_counts() Freezing 142726 Warm 124239 Cold 97822 Boiling Hot 84790 Hot 67508 Lava Hot 64840 Name: ord_2, dtype: int64
حساب القيمة بعد التعيين:
0.0 142726 1.0 124239 2.0 97822 3.0 84790 4.0 67508 5.0 64840 Name: ord_2, dtype: int64
يُعرف هذا النوع من ترميز المتغيرات الفئوية باسم ترميز المسميات (Label Encoding) ، أي أننا نقوم بترميز كل فئة على أنها تسمية رقمية.
يمكننا أن نفعل الشيء نفسه باستخدام LabelEncoder من scikit-Learn.
import pandas as pd
from sklearn import preprocessing
# قراءة الملفات
df = pd.read_csv("../input/cat_train.csv")
# ord_2في عامود NaN تعبئة قيم
df.loc[:,"ord_2"] = df.ord_2.fillna("NONE")
# LabelEncoder تهيئة
lbl_enc = preprocessing.LabelEncoder()
df.loc[:,"ord_2"] = lbl_enc.fit_transform(df.ord_2.values)
سترى أنني أستخدم fillna من pandas. السبب هو أن LabelEncoder من scikitlearn لا يعالج قيم NaN ، ويحتوي العمود ord_2 على قيم NaN فيه.
يمكننا استخدام هذا مباشرة في العديد من النماذج المستندة إلى الأشجار(tree-based models: ) :
• أشجار القرار (Decision trees)
• غابة عشوائية (Random forest)
• أشجار إضافية (Extra Trees)
• أو أي نوع من أنواع الأشجار المعززة
- XGBoost
- GBM
- LightGBM
لا يمكن استخدام هذا النوع من الترميز في النماذج الخطية (linear models) أو متجهات ألية الدعم (support vector machines) أو الشبكات العصبية (neural networks) لأنها تتوقع أن يتم تسوية البيانات (أو توحيدها).
بالنسبة لهذه الأنواع من النماذج ، يمكننا جعل البيانات ثنائية.
Freezing --> 0 --> 0 0 0 Warm --> 1 --> 0 0 1 Cold --> 2 --> 0 1 0 Boiling Hot --> 3 --> 0 1 1 Hot --> 4 --> 1 0 0 Lava Hot --> 5 --> 1 0 1
هذا مجرد تحويل الفئات إلى أرقام ثم تحويلها إلى تمثيلها الثنائي. لذلك نقوم بتقسيم سمة واحدة إلى ثلاث (في هذه الحالة) سمات (أو أعمدة). إذا كان لدينا المزيد من الفئات ، فقد ينتهي بنا الأمر إلى التقسيم إلى المزيد من الأعمدة.
يصبح من السهل تخزين الكثير من المتغيرات الثنائية مثل هذه إذا قمنا بتخزينها في تنسيق متناثر.
التنسيق المتناثر (sparse format)
التنسيق المتناثر ليس سوى تمثيل أو طريقة لتخزين البيانات في الذاكرة حيث لا تخزن كل القيم ولكن القيم المهمة فقط. في حالة المتغيرات الثنائية الموضحة أعلاه ، كل ما يهم هو مكان وجود المتغيرات الأحادية(1s).
من الصعب تخيل هذه الصغية سيتضح كل شيئ بمثال .
لنفترض أنه تم تزويدنا بسمة واحدة فقط في إطار البيانات أعلاه: ord_2.
| الفهرس | السمة |
| 0 | Warm |
| 1 | Hot |
| 2 | Lava hot |
حاليًا ، نحن نبحث في ثلاث عينات فقط في مجموعة البيانات. دعنا نحول هذا إلى تمثيل ثنائي حيث لدينا ثلاثة عناصر لكل عينة.
هذه العناصر الثلاثة هي السمات الثلاث.
| الفهرس | سمة_0 | سمة_1 | سمة_2 |
| 0 | 0 | 0 | 1 |
| 1 | 1 | 0 | 0 |
| 2 | 1 | 0 | 1 |
لذلك ، يتم تخزين سماتنا في مصفوفة مكونة من 3 صفوف و 3 أعمدة – 3 × 3. يحتل كل عنصر من عناصر هذه المصفوفة 4 بايت.
يمكننا أيضًا التحقق من ذلك باستخدام مقتطف python بسيط.
import numpy as np
# إنشاء مصفوفة السمات
example = np.array(
[
[0, 0, 1],
[1, 0, 0],
[1, 0, 1]
])
#طباعة الحجم كبايت
print(example.nbytes)
مخرج هذا الكود هو 36 وهو إجمالي متطلبات الذاكرة الخاصة بنا لهذه المجموعة. لكن هل نحتاج إلى تخزين جميع عناصر هذه المصفوفة؟ لا ، كما ذكرنا سابقًا ، نحن مهتمون فقط بـ 1s. مما يعني 0s ليست مهمة لأن أي شيء مضروبًا في 0 سيكون صفراً و 0 مضاف / مطروح من / إلى أي شيء لا يحدث أي فرق.
إحدى الطرق لتمثيل هذه المصفوفة فقط مع أحاد ستكون نوعًا ما قاموس تكون فيها المفاتيح مؤشرات للصفوف والأعمدة والقيمة هي 1:
(0, 2) 1 (1, 0) 1 (2, 0) 1 (2, 2) 1
تدوين مثل هذا سيشغل ذاكرة أقل بكثير لأنه يجب أن يخزن أربع قيم فقط (في هذا الحالة). سيكون إجمالي الذاكرة المستخدمة 4 × 4 = 16 بايت. يمكن تحويل أي مصفوفة عددية إلى مصفوفة متفرقة بواسطة كود بيثون بسيط.
import numpy as np
from scipy import sparse
# إنشاء مصفوفة السمات
example = np.array(
[
[0, 0, 1],
[1, 0, 0],
[1, 0, 1]
])
sparse_example = sparse.csc_matrix(example)
#طباعة الحجم كبايت
print(sparse_example.data.nbytes)
سيؤدي هذا إلى طباعة 32 ، وهو أقل بكثير من مصفوفتنا الكثيفه ! الحجم الإجمالي لمصفوفة csr المتفرقة هو مجموع ثلاث قيم.
print( sparse_example.data.nbytes + sparse_example.indptr.nbytes + sparse_example.indices.nbytes )
سيؤدي هذا إلى طباعة 48 .
يصبح الاختلاف في الحجم كبيرًا عندما يكون لدينا مصفوفات أكبر بكثير ، دعنا نقول مع آلاف العينات وعشرات الآلاف من السمات. على سبيل المثال ، مجموعة بيانات نصية حيث نستخدم سمات تعتمد على العد.
import numpy as np
from scipy import sparse
# عدد الصفوف
n_rows = 10000
# عدد الأعمدة
n_cols = 10000
# إنشاء مصفوفة ثنائية عشوائية تحتوي 5% قيم 1
example = np.random.binomial(1, p=0.05, size=(n_rows, n_cols))
# طباعة الحجم كبايت
print(f"Size of dense array:{example.nbytes}")
#sparse CSR تحويل مصفوفة نمباي إلى مصفوفة
sparse_example = sparse.csc_matrix(example)
#طباعة الحجم
print(f"Size of the sparse array: {sparse_example.data.nbytes}")
full_size = (
sparse_example.data.nbytes +
sparse_example.indptr.nbytes +
sparse_example.indices.nbytes
)
# طباعة الحجم
print(f" Full size of sparse array: {full_size}")
هذا يطبع:
Size of dense array: 8000000000 Size of sparse array: 399932496 Full size of sparse array: 599938748
لذلك ، تستهلك المصفوفة الكثيفة حوالي 4000 ميجابايت أو ما يقرب من 4 جيجابايت من الذاكرة. من ناحية أخرى ، تستهلك المصفوفة المتناثرة 200 ميغابايت فقط من الذاكرة. ولهذا السبب نفضل المصفوفات المتناثرة على الكثيفة عندما يكون لدينا الكثير من الأصفار في سماتنا .
يرجى ملاحظة أن هناك العديد من الطرق المختلفة لتمثيل مصفوفة متناثرة. لقد أظهرت هنا طريقة واحدة فقط (وربما الأكثر شيوعًا).
على الرغم من أن التمثيل المتناثر للسمات الثنائية يأخذ ذاكرة أقل بكثير من تمثيله الكثيف ، إلا أن هناك تحولًا آخر للمتغيرات الفئوية التي تستغرق ذاكرة أقل. يُعرف هذا باسم خط الترميز الأحادي (One Hot Encoding).
خط الترميز الأحادي (One Hot Encoding)
خط الترميز الأحادي هو ترميز ثنائي أيضًا بمعنى أنه لا يوجد سوى قيمتين ، 0 و 1. ومع ذلك ، يجب ملاحظة أنه ليس تمثيلًا ثنائيًا. يمكن فهم تمثيلها من خلال النظر في المثال التالي.
افترض أننا نمثل كل فئة من المتغيرات ord_2 بواسطة متجه. هذا المتجه له نفس حجم عدد الفئات في المتغير ord_2. في هذه الحالة المحددة ، يكون حجم كل متجه ستة ويحتوي على قيم أصفار باستثناء موضع واحد. دعونا نلقي نظرة على هذا جدول المتجهات هذا.
| Freezing | 0 | 0 | 0 | 0 | 0 | 1 |
| Warm | 0 | 0 | 0 | 0 | 1 | 0 |
| Cold | 0 | 0 | 0 | 1 | 0 | 0 |
| Boiling Hot | 0 | 0 | 1 | 0 | 0 | 0 |
| Hot | 0 | 1 | 0 | 0 | 0 | 0 |
| Lava Hot | 1 | 0 | 0 | 0 | 0 | 0 |
نرى أن حجم المتجهات هو 1×6 ، أي أن هناك ستة عناصر في المتجه. من أين يأتي هذا الرقم؟ إذا نظرت بعناية ، سترى أن هناك ست فئات ، كما ذكرنا من قبل. عند إستخدام خط الترميز الأحادي ، يجب أن يكون حجم المتجه هو نفسه عدد الفئات التي ننظر إليها. كل متجه له 1 والباقي جميع القيم الأخرى هي 0.
الآن ، دعنا نستخدم هذه السمات بدلاً من السمة الثنائية كما في السابق ونرى مقدار الذاكرة التي يمكننا حفظها.
إذا كنت تتذكر البيانات القديمة ، فإنها تبدو كما يلي:
| الفهرس | المسة |
| 0 | Warm |
| 1 | Hot |
| 2 | Lava hot |
ولدينا ثلاث سمات لكل عينة. لكن في هذه الحالة متجهة خط الترميز الأحادي لها الحجم 6. وبالتالي ، لدينا ست سمات بدلاً من 3.
| الفهرس | F_0 | F_1 | F_2 | F_3 | F_4 | F_5 |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 |
إذن ، لدينا ست سمات ، وفي هذه المصفوفة 3 × 6 ، هناك 3 سمات فقط. إيجاد الحجم باستخدام numpy مشابه جدًا للنص البرمجي لحساب حجم الترميز الثنائي. كل ما تحتاج إلى تغييره هو المصفوفة. دعونا نلقي نظرة على هذا الكود.
import numpy as np
from scipy import sparse
# إنشاء مصفوفة ثنائية عشوائية تحتوي 5% قيم 1
example = np.array(
[
[0, 0, 0, 0, 1, 0],
[0, 1, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0]
]
)
# طباعة الحجم كبايت
print(f"Size of dense array:{example.nbytes}")
#sparse CSR تحويل مصفوفة نمباي إلى مصفوفة
sparse_example = sparse.csc_matrix(example)
#طباعة الحجم
print(f"Size of the sparse array: {sparse_example.data.nbytes}")
full_size = (
sparse_example.data.nbytes +
sparse_example.indptr.nbytes +
sparse_example.indices.nbytes
)
# طباعة الحجم
print(f" Full size of sparse array: {full_size}")
سيؤدي ذلك إلى طباعة الأحجام على النحو التالي:
Size of dense array: 144 Size of sparse array: 24 Full size of sparse array: 52
نرى أن حجم المصفوفة الكثيفة أكبر بكثير من الحجم ذي الترميز الثنائي. ومع ذلك ، فإن حجم المصفوفة المتناثرة أقل بكثير. دعونا نجرب هذا مع مجموعة أكبر بكثير. في هذا المثال ، سوف نستخدم OneHotEncoder من scikit-Learn لتحويل مصفوفة السمات الخاصة بنا مع فئات 1001 إلى مصفوفات كثيفة و متناثرة.
import numpy as np
from sklearn import preprocessing
from scipy import sparse
# إنشاء مصفوفة ذات بعد واحد تحتوي على 1001 فئة مختلفة
example = np.random.randint(1000, size=1000000)
#تهيئة خط الترميز الأحادي
# لنحصل على المصفوفة الكثيفة sparse=False سنترك
ohe = preprocessing.OneHotEncoder(sparse=False)
ohe_example = ohe.fit_transform(example.reshape(-1,1))
# طباعة الحجم كبايت
print(f"Size of dense array:{ohe_example.nbytes}")
#تهيئة خط الترميز الأحادي
# لنحصل على المصفوفة المتناثرة sparse=True سنترك
ohe = preprocessing.OneHotEncoder(sparse=True)
ohe_example = ohe.fit_transform(example.reshape(-1,1))
#طباعة الحجم
print(f"Size of the sparse array: {ohe_example.data.nbytes}")
full_size = (
ohe_example.data.nbytes +
ohe_example.indptr.nbytes +
ohe_example.indices.nbytes
)
# طباعة الحجم
print(f" Full size of sparse array: {full_size}")
ويطبع هذا الرمز:
Size of dense array: 8000000000 Size of sparse array: 8000000 Full size of sparse array: 16000004
حجم المصفوفة الكثيفة هنا حوالي 8 جيجا بايت والمصفوفة المتناثرة 8 ميجا بايت. إذا كان لديك خيار ، أيهما ستختار؟ يبدو أنه اختيار بسيط للغاية بالنسبة لي ، أليس كذلك؟
تحويل المتغيرات الفئوية إلى متغيرات عددية
هذه الطرق الثلاث هي أهم الطرق للتعامل مع المتغيرات الفئوية. ومع ذلك ، هناك العديد من الطرق المختلفة الأخرى التي يمكنك استخدامها للتعامل مع المتغيرات الفئوية. مثال على إحدى هذه الطرق هو حول تحويل المتغيرات الفئوية إلى متغيرات عددية.
لنفترض أننا عدنا إلى إطار بيانات السمات الفئوية الأصلي ( cat-in-the-datii) الذي كان لدينا. كم عدد المعرفات الموجودة لدينا في إطار البيانات حيث تكون قيمة ord_2 هي Boiling Hot؟
يمكننا بسهولة حساب هذه القيمة عن طريق حساب شكل إطار البيانات حيث يحتوي العمود ord_2 على قيمة Boiling Hot.
import pandas as pd
df = pd.read_csv("../input/cat_train.csv")
df[df.ord_2 == "Boiling Hot"].shape
نرى أن هناك 84790 صفًا بهذه القيمة. يمكننا أيضًا حساب هذه القيمة لجميع الفئات باستخدام groupby في الباندا.
In [X]: df.groupby(["ord_2"])["id"].count() Out[X]: ord_2 Boiling Hot 84790 Cold 97822 Freezing 142726 Hot 67508 Lava Hot 64840 Warm 124239 Name: id, dtype: int64
إذا قمنا فقط باستبدال العمود ord_2 بقيم التعداد الخاصة به ، فقد قمنا بتحويله إلى سمة عددية نوعًا ما الآن. يمكننا إنشاء عمود جديد أو استبدال هذا العمود باستخدام وظيفة transform الخاصة بالباندا مع groupby.
In [X]: df.groupby(["ord_2"])["id"].transform("count")
Out[X]:
0 67508.0
1 124239.0
2 142726.0
3 64840.0
4 97822.0
...
599995 142726.0
599996 84790.0
599997 142726.0
599998 124239.0
599999 84790.0
Name: id, Length: 600000, dtype: float64
يمكنك إضافة أعداد لجميع السمات أو يمكنك أيضًا استبدالها أو ربما تجميعها حسب أعمدة متعددة وتعدادها. على سبيل المثال ، يتم حساب الكود التالي من خلال جمع الأعمدة ord_1 و ord_2.
In [X]: df.groupby( ...: [ ...: "ord_1", ...: "ord_2" ...: ] ...: )["id"].count().reset_index(name="count") Out[X]: ord_1 ord_2 count 0 Contributor Boiling Hot 15634 1 Contributor Cold 17734 2 Contributor Freezing 26082 3 Contributor Hot 12428 4 Contributor Lava Hot 11919 5 Contributor Warm 22774 6 Expert Boiling Hot 19477 7 Expert Cold 22956 8 Expert Freezing 33249 9 Expert Hot 15792 10 Expert Lava Hot 15078 11 Expert Warm 28900 12 Grandmaster Boiling Hot 13623 13 Grandmaster Cold 15464 14 Grandmaster Freezing 22818 15 Grandmaster Hot 10805 16 Grandmaster Lava Hot 10363 17 Grandmaster Warm 19899 18 Master Boiling Hot 10800 . . . .
يرجى ملاحظة أنني قمت بإزالة بعض الصفوف من الإخراج. هذا نوع آخر من الأعداد التي يمكنك إضافتها كسمة . يجب أن تكون قد لاحظت الآن أنني أستخدم عمود المعرف للتعداد .
ومع ذلك ، يمكنك أيضًا حساب الأعمدة الأخرى عن طريق التجميع حسب مجموعات الأعمدة. هناك حيلة أخرى تتمثل في إنشاء سمات جديدة من هذه المتغيرات الفئوية. يمكنك إنشاء سمات فئوية جديدة من السمات الموجودة ، ويمكن القيام بذلك بطريقة سهلة.
In [X]: df["new_feature"] = ( ...: df.ord_1.astype(str) ...: + "_" ...: + df.ord_2.astype(str) ...: ) In [X]: df.new_feature Out[X]: 0 Contributor_Hot 1 Grandmaster_Warm 2 nan_Freezing 3 Novice_Lava Hot 4 Grandmaster_Cold ... 599995 Novice_Freezing 599996 Novice_Boiling Hot 599997 Contributor_Freezing 599998 Master_Warm 599999 Contributor_Boiling Hot Name: new_feature, Length: 600000, dtype: object
هنا ، قمنا بدمج ord_1 و ord_2 بشرطة سفلية ، وقبل ذلك ، نقوم بتحويل هذه الأعمدة إلى نوع string . لاحظ أن NaN سيتحول أيضًا إلى سلسلة. لكن لا بأس. يمكننا أيضًا التعامل مع NaN كفئة جديدة. وبالتالي ، لدينا سمة جديدة وهي مزيج من هاتين السمتين. يمكنك أيضًا دمج أكثر من ثلاثة أعمدة أو أربعة أو أكثر.
إذن ما هي الفئات التي يجب أن نجمعها؟ حسنًا ، لا توجد إجابة سهلة لذلك. يعتمد ذلك على بياناتك وأنواع السمات. قد تكون بعض المعرفة بالمجال مفيدة لإنشاء سمات مثل هذه. ولكن إذا لم تكن لديك مخاوف بشأن استخدام الذاكرة ووحدة المعالجة المركزية ، فيمكنك اتباع نهج جشع حيث يمكنك إنشاء العديد من هذه المجموعات ثم استخدام نموذج لتحديد السمات المفيدة والاحتفاظ بها.
عندما تحصل على متغيرات فئوية ، اتبع هذه الخطوات البسيطة:
• املأ قيم NaN (هذا مهم جدًا!)
• قم بتحويلها إلى أعداد صحيحة عن طريق تطبيق ترميز التسمية باستخدام LabelEncoder من scikit-Learn أو باستخدام قاموس الخرائط. إذا لم تملأ قيم NaN بشيء ما ، فقد تضطر إلى الاهتمام بها في هذه الخطوة
• إنشاء خط الترميز الأحادي. نعم ، يمكنك تخطي الترميز الثنائي!
• إبدا للنمذجة!
التعامل مع بيانات NaN
يعتبر التعامل مع بيانات NaN في الميزات الفئوية أمرًا ضروريًا تمامًا وإلا يمكنك الحصول على الخطأ الشائن من LabelEncoder الخاص بـ scikit-Learn:
ValueError: y contains previously unseen labels: [nan, nan, nan, nan, nan, nan, nan, nan]
هذا يعني ببساطة أنه عندما تقوم بتحويل بيانات الاختبار ، يكون لديك قيم NaN فيها. هذا لأنك نسيت التعامل معهم أثناء التدريب. تتمثل إحدى الطرق البسيطة للتعامل مع قيم NaN في إسقاطها.
حسنًا ، الأمر بسيط ولكنه ليس مثاليًا. قد تحتوي قيم NaN على الكثير من المعلومات ، وستفقدها إذا أسقطت هذه القيم. قد يكون هناك أيضًا العديد من المواقف حيث تحتوي معظم بياناتك على قيم NaN ، وبالتالي لا يمكنك إسقاط الصفوف / العينات بقيم NaN.
هناك طريقة أخرى للتعامل مع قيم NaN وهي معاملتها كفئة جديدة تمامًا. هذه هي الطريقة الأكثر تفضيلاً للتعامل مع قيم NaN. ويمكن تحقيقه بطريقة بسيطة للغاية إذا كنت تستخدم الباندا. تحقق من ذلك في عمود ord_2 من البيانات التي كنا نتعامل معها الآن.
In [X]: df.ord_2.value_counts() Out[X]: Freezing 142726 Warm 124239 Cold 97822 Boiling Hot 84790 Hot 67508 Lava Hot 64840 Name: ord_2, dtype: int64
و بعد تعبئة قيم NaN
In [X]: df.ord_2.fillna("NONE").value_counts()
Out[X]:
Freezing 142726
Warm 124239
Cold 97822
Boiling Hot 84790
Hot 67508
Lava Hot 64840
NONE 18075
Name: ord_2, dtype: int64
نجاح باهر! كان هناك 18075 قيمة لـ NaN في هذا العمود لم نفكر في استخدامها من قبل. مع إضافة هذه الفئة الجديدة ، زاد العدد الإجمالي للفئات الآن من 6 إلى 7. هذا جيد لأنه الآن عندما نبني نماذجنا ، سننظر أيضًا في NaN. كلما توفرت لدينا معلومات أكثر صلة ، كان النموذج أفضل.
الفئة النادرة (rare category)
لنفترض أن ord_2 لم يكن له أي قيم NaN. نرى أن جميع الفئات في هذا العمود لها عدد كبير. لا توجد فئات “نادرة”. أي الفئات التي تظهر فقط في نسبة مئوية صغيرة من إجمالي عدد العينات. الآن ، لنفترض أنك قمت بنشر هذا النموذج الذي يستخدم هذا العمود في الإنتاج وعندما يتم تشغيل النموذج أو المشروع ، تحصل على فئة في العمود ord_2 غير موجودة في التدريب. نموذجك ، في هذه الحالة سيرمي خطأ ولا يوجد شيء يمكنك القيام به حيال ذلك.
إذا حدث هذا ، فمن المحتمل أن يكون هناك خطأ ما في خط الإنتاج. إذا كان هذا متوقعًا ، فيجب عليك تعديل خط إنتاج النموذج الخاص بك وتضمين فئة جديدة لهذه الفئات الست. تُعرف هذه الفئة الجديدة بالفئة “النادرة”.
الفئة النادرة (rare category) هي فئة لا تُرى كثيرًا ويمكن أن تشمل العديد من الفئات المختلفة. يمكنك أيضًا محاولة “التنبؤ” بالفئة غير المعروفة باستخدام نموذج الجار الأقرب (nearest neighbour). تذكر ، إذا توقعت هذه الفئة ، فستصبح إحدى الفئات من بيانات التدريب.
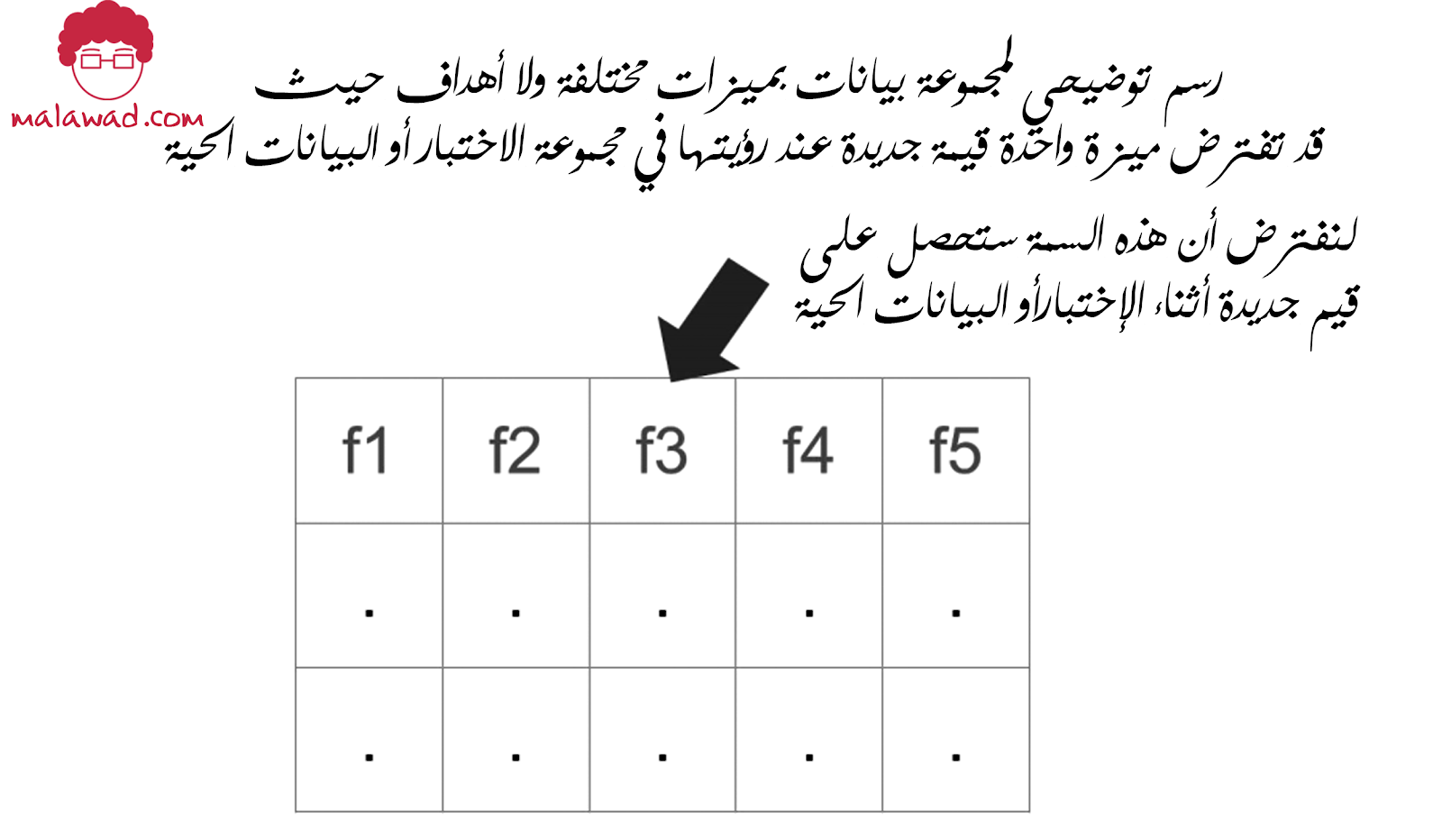
عندما يكون لدينا مجموعة بيانات كما هو موضح أعلاه ، يمكننا إنشاء نموذج بسيط يتم تدريبه على جميع السمات باستثناء “f3”. وبالتالي ، ستنشئ نموذجًا يتوقع “f3” عندما لا يكون معروفًا أو غير متاح في التدريب. لا أستطيع أن أقول ما إذا كان هذا النوع من النماذج سيمنحك أداءً ممتازًا ولكن قد يكون قادرًا على التعامل مع هذه القيم المفقودة في مجموعة الاختبار أو البيانات الحية ولا يمكن للمرء أن يجزم دون المحاولة تمامًا مثل أي شيء آخر عندما يتعلق الأمر بتعلم الألة.
إذا كان لديك مجموعة اختبار ثابتة ، فيمكنك إضافة بيانات الاختبار الخاصة بك إلى التدريب للتعرف على الفئات الموجودة في سمة معينة. هذا مشابه جدًا للتعلم شبه الخاضع للإشراف الذي تستخدم فيه بيانات غير متوفرة للتدريب لتحسين نموذجك.
سيهتم هذا أيضًا بالقيم النادرة التي تظهر عددًا أقل من المرات في بيانات التدريب ولكنها متوفرة بكثرة في بيانات الاختبار. سيكون نموذجك أكثر قوة.
يعتقد الكثير من الناس أن هذه الفكرة قد تودي إلى فرط التخصيص (overfitting). قد يحدث هذا أو قد لا يحدث. هناك حل بسيط لذلك. إذا قمت بتصميم عملية التحقق المتقاطع (cross-validation ) بطريقة تكرر عملية التنبؤ عند تشغيل نموذجك على بيانات الاختبار ، فلن يحدث فرط التخصيص . هذا يعني أن الخطوة الأولى يجب أن تكون فصل الطيات ، وفي كل طية ، يجب أن تطبق نفس المعالجة المسبقة التي تريد تطبيقها على بيانات الاختبار.
لنفترض أنك تريد تجميع بيانات التدريب والاختبار ، ثم في كل مرة يجب عليك ربط بيانات التدريب والتحقق و التاكد أيضًا من أن مجموعة بيانات التحقق الخاصة بك تكرر مجموعة الاختبار. في هذه الحالة المحددة ، يجب عليك تصميم مجموعات التحقق الخاصة بك بطريقة تحتوي على فئات “غير مرئية” في مجموعة التدريب.
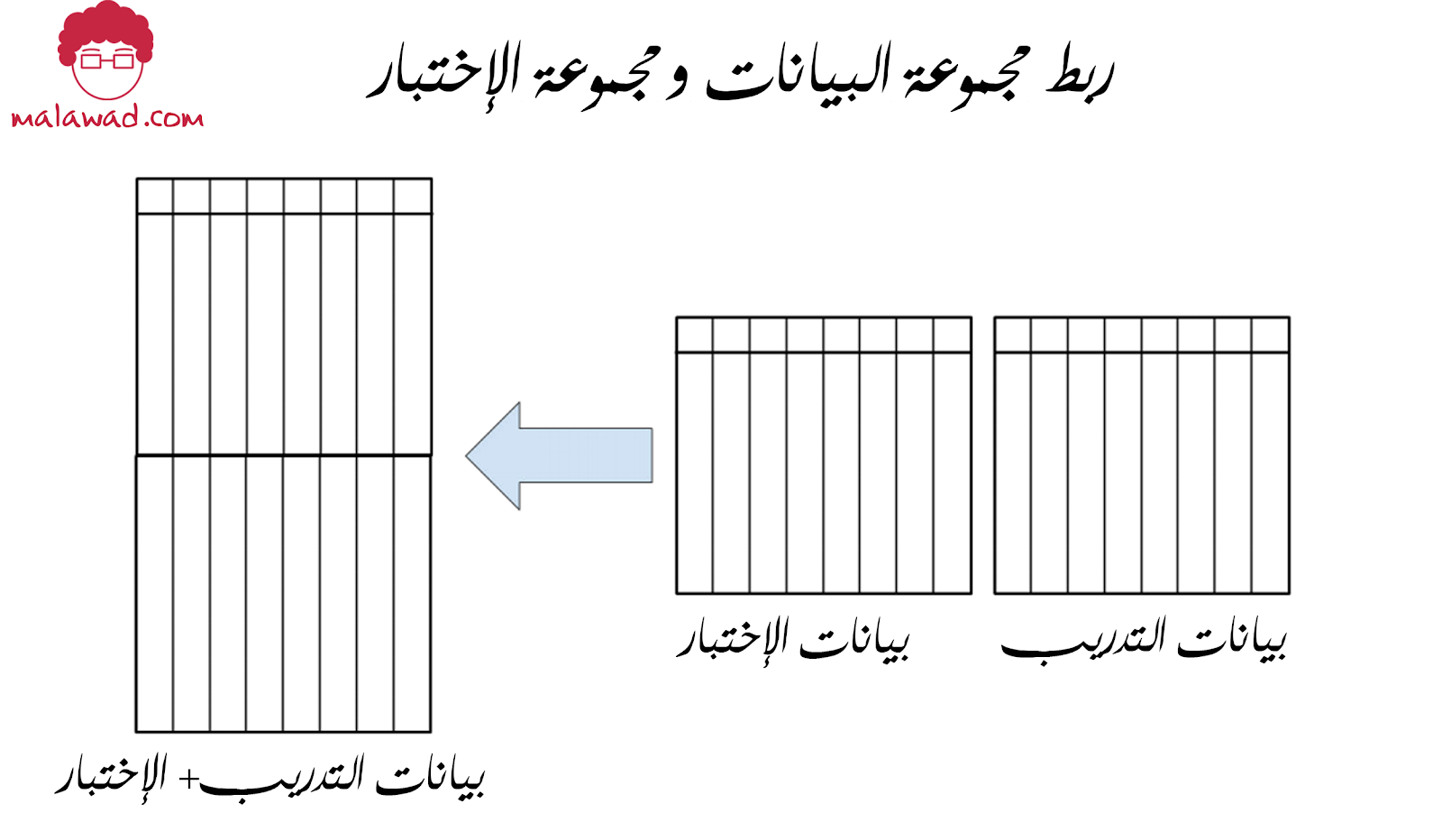
يمكن فهم كيفية عمل هذا بسهولة من خلال النظر إلى الصورة أعلاه والكود التالي.
import pandas as pd
from sklearn import preprocessing
#قراءة ملفات التدريب
train = pd.read_csv("../input/cat_train.csv")
# قراءة ملفات الإختبار
test = pd.read_csv("../input/cat_train.csv")
# إنشاء عمود هدف وهمي لبيانات الاختبار
# لأن هذا العمود غير موجود
test.loc[:, "target"] = -1
# ربط بيانات التدريب و الإختبار
data = pd.concat([train,test]).reset_index(drop=True)
# قم بعمل قائمة بالسمات التي نهتم بها
# المعرف والهدف شيئين لا ينبغي لنا ترميزه
features = [ x for x in train.columns if x not in ["id", "target"]]
# إنشاء حلقة لقائمة السمات
for feat in features:
lbl_enc = preprocessing.LabelEncoder()
# لاحظ الحيلة هنا
# string بما أن البيانات فئوية ،نحولها إلى
# strings بعض النظر سواء كانت أرقام أو لا كل البيانات ستتحول إلى
temp_col = data[feat].fillna["NONE"].astype(str).values
data.loc[:, feat] = lbl_enc.fit_transform(temp_col)
#قسم بيانات التدريب و الإختبار مرة أخرى
train = data[data.target != -1].reset_index(drop=True)
test = data[data.target == -1].reset_index(drop=True)
تعمل هذه الحيلة عندما تكون لديك مشكلة حيث لديك بالفعل مجموعة بيانات الاختبار. تجدر الإشارة إلى أن هذه الحيلة لن تعمل في بيئة حية.
على سبيل المثال ، لنفترض أنك تعمل في شركة تعمل على إنشاء حل لتقديم عروض الأسعار في الوقت الفعلي (real-time bidding solution ). تقدم أنظمة RTB المزايدة على كل مستخدم يرونه عبر الإنترنت لشراء مساحة إعلانية.
قد تتضمن السمات التي يمكن استخدامها لمثل هذا النموذج صفحات يتم عرضها في موقع ويب. لنفترض أن السمات هي آخر خمس فئات / صفحات زارها المستخدم. في هذه الحالة ، إذا قدم موقع الويب فئات جديدة ، فلن نتمكن بعد الآن من التنبؤ بدقة. نموذجنا ، في هذه الحالة ، سوف يفشل. يمكن تجنب مثل هذا الموقف باستخدام فئة “غير معروفة”.
في مجموعة بيانات cat-in-the-dat ، لدينا بالفعل عناصر مجهولة في العمود ord_2
In [X]: df.ord_2.fillna("NONE").value_counts()
Out[X]:
Freezing 142726
Warm 124239
Cold 97822
Boiling Hot 84790
Hot 67508
Lava Hot 64840
NONE 18075
Name: ord_2, dtype: int64
يمكننا التعامل مع “NONE” على أنها غير معروفة. لذلك ، إذا حصلنا أثناء الاختبار المباشر على فئات جديدة لم نشاهدها من قبل ، فسنقوم بتمييزها على أنها “NONE”.
هذا مشابه جدًا لمشاكل معالجة اللغة الطبيعية. نبني دائمًا نموذجًا يعتمد على مفردات ثابتة. زيادة حجم المفردات يزيد من حجم النموذج. تم تدريب نماذج المحولات مثل BERT على 30000 كلمة تقريبًا (للغة الإنجليزية). لذلك ، عندما تأتي كلمة جديدة ، فإننا نضعها على أنها UNK (غير معروفة).
لذلك ، يمكنك إما أن تفترض أن بيانات الاختبار الخاصة بك ستحتوي على نفس فئات التدريب أو يمكنك تقديم فئة نادرة أو غير معروفة للتدريب لرعاية الفئات الجديدة في بيانات الاختبار.
دعونا نرى عدد القيم في العمود ord_4 بعد ملء قيم NaN:
In [X]: df.ord_4.fillna("NONE").value_counts()
Out[X]:
N 39978
P 37890
Y 36657
A 36633
R 33045
U 32897
.
.
.
K 21676
I 19805
NONE 17930
D 17284
F 16721
W 8268
Z 5790
S 4595
G 3404
V 3107
J 1950
L 1657
Name: ord_4, dtype: int64
نرى أن بعض القيم تظهر فقط ألفي مرة ، وبعضها يظهر ما يقرب من 40000 مرة. يتم رؤية NaNs أيضًا كثيرًا. يرجى ملاحظة أنني قمت بإزالة بعض القيم من الإخراج. يمكننا الآن تحديد معاييرنا لاستدعاء قيمة “نادرة”. لنفترض أن شرط أن تكون القيمة نادرة في هذا العمود هو عدد أقل من 2000.
لذلك ، على ما يبدو ، يمكن تمييز J و L كقيم نادرة. مع الباندا ، من السهل جدًا استبدال الفئات بناءً على عتبة العد. دعونا نلقي نظرة على كيفية القيام بذلك.
In [X]: df.ord_4 = df.ord_4.fillna("NONE")
In [X]: df.loc[
...: df["ord_4"].value_counts()[df["ord_4"]].values < 2000,
...: "ord_4"
...: ] = "RARE"
In [X]: df.ord_4.value_counts()
Out[X]:
N 39978
P 37890
Y 36657
A 36633
R 33045
U 32897
M 32504
.
.
.
B 25212
E 21871
K 21676
I 19805
NONE 17930
D 17284
F 16721
W 8268
Z 5790
S 4595
RARE 3607
G 3404
V 3107
Name: ord_4, dtype: int64
نقول إنه عندما تكون القيمة لفئة معينة أقل من 2000 ، استبدلها بـ نادرة. لذلك ، الآن ، عندما يتعلق الأمر ببيانات الاختبار ، سيتم تعيين جميع الفئات الجديدة غير المرئية إلى “RARE” ، وسيتم تعيين جميع القيم المفقودة إلى “NONE”.
سيضمن هذا النهج أيضًا أن النموذج يعمل في بيئة حية ، حتى إذا كان لديك فئات جديدة.
و إلى هنا نصل إلى نهاية هذا المقال و في المقال القادم سنقوم ببناء نماذج متعددة للتعامل مع مجموعة البيانات هذه













إضافة تعليق