
الخطوة الأولى في عملية تطوير أي نظام معالجة اللغة الطبيعية هي جمع البيانات (Data acquisition) ذات الصلة بالمهمة المحددة. حتى إذا كنا نبني نظامًا قائمًا على القواعد ، ما زلنا بحاجة إلى بعض البيانات لتصميم واختبار قواعدنا.
نادرًا ما تكون البيانات التي نحصل عليها نظيفة ، وهنا يأتي دور تنظيف النص (Text cleaning) . بعد التنظيف ، غالبًا ما تحتوي بيانات النص على الكثير من الاختلافات ويجب تحويلها إلى نموذج أساسي.
يتم ذلك في خطوة ما قبل المعالجة (Pre-processing) . ويلي ذلك هندسة السمات (Feature engineering)، حيث نقوم باقتطاع المؤشرات الأكثر ملاءمة للمهمة قيد البحث. يتم تحويل هذه المؤشرات إلى تنسيق يمكن فهمه من خلال خوارزميات النمذجة (modeling algorithms) . ثم تأتي مرحلة النمذجة (Modeling) والتقييم (Evaluation) ، حيث نبني نموذجًا واحدًا أو أكثر ونقارنها باستخدام مقياس التقييم ذات الصلة.
بمجرد اختيار أفضل نموذج من بين النماذج التي تم تقييمها ، نتحرك نحو نشر (Deployment) هذا النموذج في الإنتاج. أخيرًا ، نراقب أداء النموذج بانتظام ، وإذا لزم الأمر ، نقوم بتحديثه للحفاظ على أدائه.
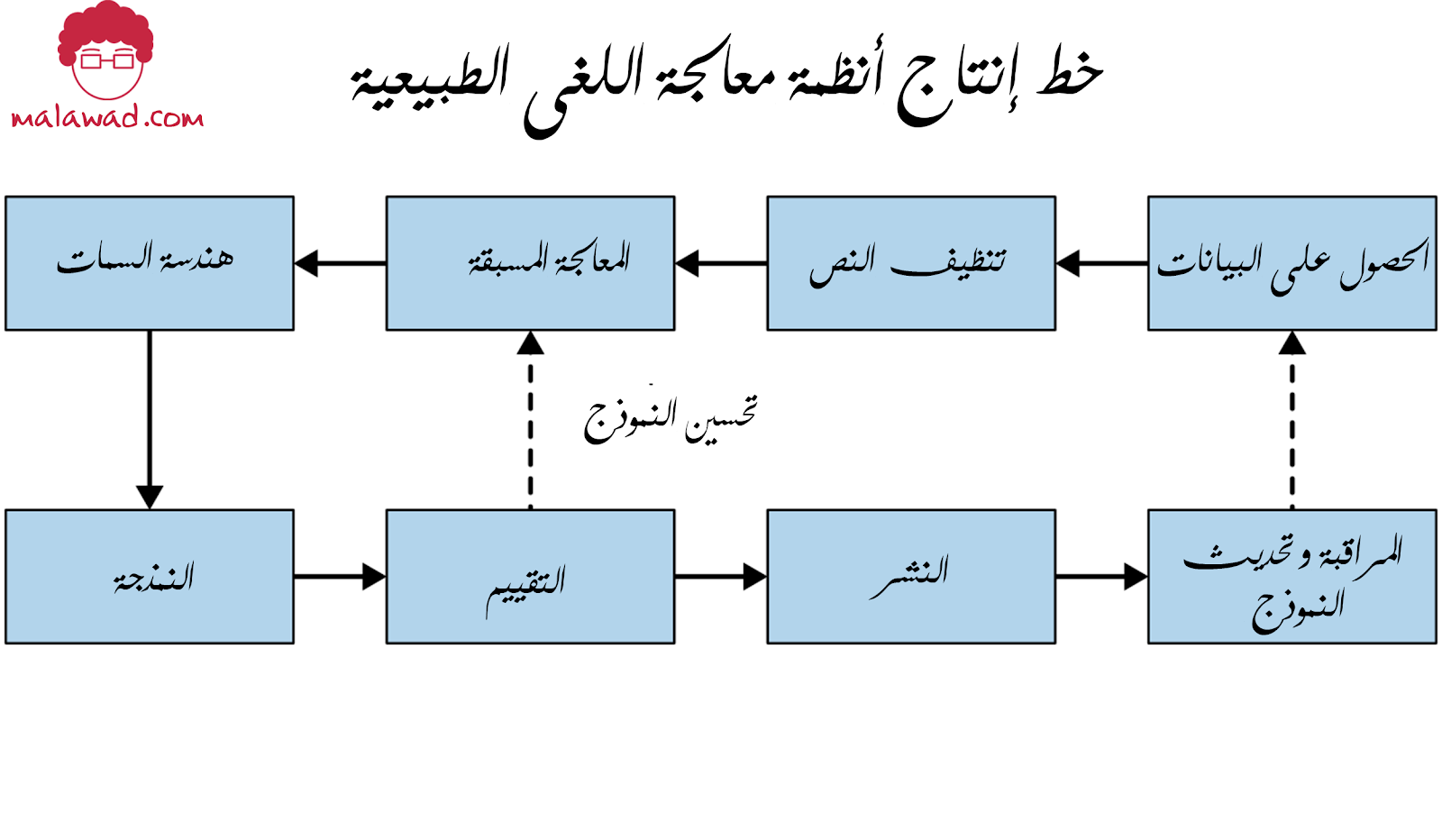
لاحظ أنه في العالم الحقيقي ، قد لا تكون العملية دائمًا خطية كما هو موضح في خط الإنتاج في الشكل أعلاه ؛ غالبًا ما يتضمن الانتقال ذهابًا وإيابًا بين الخطوات الفردية (على سبيل المثال ، بين استخراج السمات والنمذجة أوالنمذجة والتقييم وما إلى ذلك).
لاحظ أن كيفية عمل هذه الخطوات الدقيقة قد تعتمد على المهمة المحددة في متناول اليد. على سبيل المثال ، قد يتطلب نظام تصنيف النص خطوة استخراج السمات مختلفة مقارنة بنظام تلخيص النص.
سنلقي نظرة على المراحل الفردية ، جنبًا إلى جنب مع الأمثلة. سنصف بعض الإجراءات الأكثر شيوعًا في كل مرحلة ونناقش بعض حالات الاستخدام لتوضيحها. لنبدأ بالخطوة الأولى: الحصول على البيانات.
الحصول على البيانات
البيانات هي قلب أي نظام تعلم ألة . في معظم المشاريع الصناعية ، غالبًا ما تصبح البيانات هي عنق الزجاجة. في هذا القسم ، سنناقش استراتيجيات مختلفة لجمع البيانات ذات الصلة لمشروع معالجة اللغة الطبيعية.
لنفترض أنه طُلب منا تطوير نظام معالجة اللغة الطبيعية لتحديد ما إذا كان إستفسار العميل الوارد (على سبيل المثال ، باستخدام واجهة الدردشة) هو إستفسار مبيعات أو إستفسار رعاية العملاء. اعتمادًا على نوع الإستفسار ، يجب توجيهه تلقائيًا إلى الفريق المناسب. كيف يمكن للمرء أن يبني مثل هذا النظام؟ حسنًا ، تعتمد الإجابة على نوع وكمية البيانات التي يتعين علينا العمل بها.
في وضع مثالي ، سيكون لدينا مجموعات البيانات المطلوبة مع الآلاف – وربما الملايين – من نقاط البيانات. في مثل هذه الحالات ، لا داعي للقلق بشأن الحصول على البيانات. على سبيل المثال ، في السيناريو الذي وصفناه للتو ، لدينا استفسارات تاريخية من السنوات السابقة ، استجابت لها فرق المبيعات والدعم.
علاوة على ذلك ، قامت الفرق بتمييز هذه الاستعلامات على أنها مبيعات أو دعم أو غير ذلك. لذلك ، ليس لدينا البيانات فحسب ، بل لدينا أيضًا المسميات (labels). ومع ذلك ، في العديد من مشاريع الذكاء الاصطناعي ، لا يكون المرء محظوظًا جدًا. دعونا نلقي نظرة على ما يمكننا القيام به في سيناريو أقل من مثالي.
إذا كانت لدينا بيانات قليلة أو معدومة ، فيمكننا البدء بالنظر إلى الأنماط الموجودة في البيانات التي تشير إلى ما إذا كانت الرسالة الواردة هي استعلام مبيعات أو دعم. يمكننا بعد ذلك استخدام التعبيرات العادية والاستدلالات الأخرى لمطابقة هذه الأنماط لفصل إستفسارات المبيعات عن إستفسارات الدعم. نقوم بتقييم هذا الحل من خلال جمع مجموعة من الإستفسارات من الفئتين وحساب النسبة المئوية للرسائل التي تم تحديدها بشكل صحيح بواسطة نظامنا. لنفترض أننا حصلنا على أرقام جيدة. نود تحسين أداء النظام.
الآن يمكننا البدء في التفكير في استخدام تقنيات معالجة اللغة الطبيعية . لهذا ، نحتاج إلى بيانات مصنفة ، وهي مجموعة من الاستفسارات حيث يتم تصنيف كل منها بالمبيعات أو الدعم. كيف يمكننا الحصول على مثل هذه البيانات؟
استخدم مجموعة بيانات عامة
يمكننا معرفة ما إذا كانت هناك أي مجموعات بيانات عامة متاحة يمكننا الاستفادة منها. ألق نظرة على هذا التجميع بواسطة Nicolas Iderhoff (هنا) أو ابحث في محرك البحث المتخصص في Google عن مجموعات البيانات (هنا). إذا وجدت مجموعة بيانات مناسبة تشبه المهمة الحالية ، فهذا رائع! يمكننا بناء نموذج وتقييم. إذا لم يكن كذلك ، فماذا بعد؟
كشط البيانات (Scrape data)
يمكننا العثور على مصدر للبيانات ذات الصلة على الإنترنت – على سبيل المثال ، المستهلك أو منتدى المناقشة حيث نشر الأشخاص استعلامات (المبيعات أو الدعم). اكشط البيانات من هناك وقم بتسميتها بواسطة المعلقين البشريين (human annotators.).
بالنسبة إلى العديد البيئات الصناعية ، لا يكفي جمع البيانات من مصادر خارجية لأن البيانات لا تحتوي على فروق دقيقة مثل أسماء المنتجات أو سلوك المستخدم الخاص بالمنتج ، وبالتالي قد تكون مختلفة جدًا عن البيانات التي تظهر في مراجل الإنتاج. هذا هو الوقت الذي سنضطر فيه إلى البدء في البحث عن البيانات داخل المنظمة .
تدخل المنتج (Product intervention)
في معظم البيئات الصناعية ، نادرًا ما توجد نماذج الذكاء الاصطناعي بمفردها. لقد تم تطويرها في الغالب لخدمة المستخدمين عبر ميزة أو منتج. في جميع هذه الحالات ، يجب على فريق الذكاء الاصطناعي العمل مع فريق المنتج لجمع المزيد من البيانات الغنية عن طريق تطوير أدوات أفضل في المنتج. في عالم التكنولوجيا ، يسمى هذا تدخل المنتج.
غالبًا ما يكون التدخل في المنتج هو أفضل طريقة لجمع البيانات لبناء تطبيقات ذكية في البيئات الصناعية. لقد عرف عمالقة التكنولوجيا مثل Google و Facebook و Microsoft و Netflix وما إلى ذلك هذا الأمر لفترة طويلة وحاولوا جمع أكبر قدر ممكن من البيانات من أكبر عدد ممكن من المستخدمين.
تعزيز البيانات (Data augmentation)
على الرغم من أن إستخدام المنتجات هي طريقة رائعة لجمع البيانات ، إلا أنها تستغرق وقتًا. حتى إذا قمت بتجهيز المنتج اليوم ، فقد يستغرق الأمر ما بين ثلاثة إلى ستة أشهر لجمع مجموعة بيانات شاملة مناسبة الحجم.
لذا ، هل يمكننا فعل شيء في هذه الأثناء؟
تحتوي معالجة اللغة الطبيعية على مجموعة من التقنيات التي يمكننا من خلالها أخذ مجموعة بيانات صغيرة واستخدام بعض الحيل لإنشاء المزيد من البيانات. تسمى هذه الحيل أيضًا تعزيز البيانات ، وهي تحاول استغلال خصائص اللغة لإنشاء نص مشابه من الناحية التركيبية لبيانات النص المصدر. دعونا نلقي نظرة على بعضها:
- استبدال المرادفات (Synonym replacement)
اختر كلمات “k” عشوائيًا في جملة لا تمثل كلمات توقف. استبدل هذه الكلمات بمرادفاتها. بالنسبة إلى المرادفات ، يمكننا استخدام Synsets في Wordnet.
- الترجمة الرجعية (Back translation)
لنفترض أن لدينا جملة ، S1 ، باللغة الإنجليزية. نستخدم مكتبة ترجمة آلية مثل Google Translate لترجمتها إلى لغة أخرى — ولنقل الألمانية. دع الجملة المقابلة باللغة الألمانية تكون S2. الآن ، سنستخدم مكتبة الترجمة الآلية مرة أخرى للترجمة مرة أخرى إلى اللغة الإنجليزية. دع الجملة الناتجة تكون S3.
سنجد أن الترجمتين S1 و S3 متشابهان جدًا في المعنى لكن هناك اختلافات طفيفه بينهما . الآن يمكننا إضافة S3 إلى مجموعة البيانات الخاصة بنا. هذه الحيلة تعمل بشكل جميل لتصنيف النص.
- استبدال الكلمات المبنية إلى TF-IDF
يمكن أن تفقد الترجمة الرجعية بعض الكلمات المهمة للجملة. في الورقة البحثية بعنوان (Unsupervised Data Augmentation for Consistency Training) استخدم المؤلفون TF-IDF ، وهو مفهوم سنتحدث عنه لاحقا للتعامل مع هذا الأمر.
- قلب النص
قسّم الجملة إلى مجوعة كلمات صغيرة . خذ مجموعة نص واحده بشكل عشوائي واقلبه. على سبيل المثال: “I am going to the supermarket. ” هنا ، نأخذ “going to” ونستبدله بمقلوبه: ” to going”.
- استبدال الكيانات
استبدل الكيانات مثل اسم الشخص ، والموقع ، والمؤسسة ، وما إلى ذلك ، بكيانات أخرى في نفس الفئة. بمعنى ، استبدل اسم الشخص باسم شخص آخر ، أو استبدل اسم المدينة بمدينة أخرى ، إلخ. على سبيل المثال ، في “أنا أعيش في كاليفورنيا” ، استبدل “كاليفورنيا” بكلمة “لندن”.
- إضافة الضوضاء إلى البيانات
في العديد من تطبيقات معالجة اللغة الطبيعية ، تحتوي البيانات الواردة على أخطاء إملائية. هذا يرجع في المقام الأول إلى خصائص النظام الأساسي حيث يتم إنشاء البيانات (على سبيل المثال ، Twitter).
في مثل هذه الحالات ، يمكننا إضافة القليل من الضوضاء إلى البيانات لتدريب النماذج القوية. على سبيل المثال ، اختر كلمة في جملة عشوائيًا واستبدلها بكلمة أخرى أقرب في الهجاء إلى الكلمة الأولى.
مصدر آخر للضوضاء هو مشكلة “الأصابع السمينة” على لوحات مفاتيح الأجهزة المحمولة. يمكننا محاكاة خطأ لوحة مفاتيح QWERTY عن طريق استبدال بعض الأحرف بالأحرف المجاورة لها على لوحة مفاتيح QWERTY.
تقنيات متقدمة
هناك تقنيات وأنظمة متقدمة أخرى يمكنها زيادة البيانات النصية. بعض من أبرزها:
- سنوركل (Snorkel)
نظام لبناء بيانات التدريب تلقائيًا ، دون وضع المسميات يدوياً . باستخدام سنوركل، يمكن “إنشاء” مجموعة بيانات تدريب كبير باستخدام الأساليب البحثية وإنشاء بيانات إصطناعية عن طريق تحويل البيانات الحالية وإنشاء عينات بيانات جديدة. ثبت أن هذا النهج يعمل بشكل جيد في Google في الماضي القريب (الورقة البحثية)
- تعزيز البيانات بسهولة (Easy Data Augmentation) و NLPAug
يتم استخدام هاتين المكتبتين لإنشاء عينات إصطناعية لـ NLP. فهي توفر طرق إستخدام تقنيات تعزيز البيانات المختلفة .
- التعلم النشط (Active learning)
هذا نموذج متخصص من ML حيث يمكن لخوارزمية التعلم الاستعلام بشكل تفاعلي عن نقطة بيانات والحصول على مسمياتها. يتم استخدامها في السيناريوهات التي توجد فيها وفرة من البيانات غير المسماة ولكن وضع العلامات يدويًا مكلف. في مثل هذه الحالات ، يصبح السؤال: ما هي نقاط البيانات التي يجب أن نسأل عن مسمياتها لتحقيق أقصى قدر من التعلم مع إبقاء تكلفة وضع العلامات منخفضة؟
لكي تعمل معظم التقنيات التي ناقشناها في هذا القسم بشكل جيد ، فإن أحد المتطلبات الرئيسية هو مجموعة بيانات نظيفة لتبدأ بها ، حتى لو لم تكن كبيرة جدًا. في تجربتنا ، يمكن لتقنيات زيادة البيانات أن تعمل بشكل جيد حقًا. علاوة على ذلك ، في ممارسات تعلم الآلة اليومية ، تأتي مجموعات البيانات من مصادر غير متجانسة.
تُستخدم مجموعة من مجموعات البيانات العامة ومجموعات البيانات المصنفة ومجموعات البيانات المعززة لبناء نماذج إنتاج في مراحل مبكرة ، حيث قد لا نمتلك غالبًا مجموعات بيانات كبيرة لسيناريوهاتنا المخصصة لتبدأ بها. بمجرد حصولنا على البيانات التي نريدها لمهمة معينة ، ننتقل إلى الخطوة التالية: تنظيف النص.
استخراج النص وتنظيفه
يشير استخراج النص وتنظيفه إلى عملية استخراج النص الخام من بيانات الإدخال عن طريق إزالة جميع المعلومات غير النصية الأخرى ، مثل العلامات والبيانات الوصفية وما إلى ذلك ، وتحويل النص إلى تنسيق الترميز المطلوب. عادة ، يعتمد هذا على تنسيق البيانات المتاحة في المنظمة
يعد استخراج النص خطوة قياسية في معالجة البيانات ، ولا نستخدم عادةً أي تقنيات خاصة بمعالجة اللغات الطبيعية أثناء هذه العملية. ومع ذلك ، فهي خطوة مهمة لها آثار على جميع الجوانب الأخرى في معالجة اللغة الطبيعية . علاوة على ذلك ، يمكن أن يكون أيضًا الجزء الأكثر استهلاكا للوقت في المشروع.
تحليل وتنظيف HTML
لنفترض أننا نعمل على مشروع حيث نبني محرك بحث منتدى لأسئلة البرمجة. لقد حددنا Stack Overflow كمصدر وقررنا استخراج أزواج من الأسئلة وأفضل الإجابات من موقع الويب. كيف نمر بخطوة استخراج النص في هذه الحالة؟
إذا لاحظنا ترميز HTML لصفحة أسئلة Stack Overflow النموذجية ، فإننا نلاحظ أن الأسئلة والإجابات لها علامات خاصة مرتبطة بها. يمكننا الاستفادة من هذه المعلومات أثناء استخراج النص من صفحة HTML.
في حين أنه قد يبدو أن كتابة محلل HTML الخاص بنا هو أفضل حل ، إلا أنه في معظم الحالات التي نواجهها ، يكون من الأفضل استخدام المكتبات الموجودة مسبقاً مثل Beautiful Soup و Scrapy ، والتي توفر مجموعة من الأدوات المساعدة للتحليل صفحات الانترنت. يوضح مقتطف البرمجة التالي كيفية استخدام Beautiful Soup لمعالجة المشكلة الموضحة هنا ، واستخراج سؤال وزوج أفضل إجابة من صفحة ويب Stack Overflow:
from bs4 import BeautifulSoup
from urllib.request import urlopen
myurl = "https://stackoverflow.com/questions/415511/ \
how-to-get-the-current-time-in-python"
html = urlopen(myurl).read()
soupified = BeautifulSoup(html, "html.parser")
question = soupified.find("div", {"class": "question"})
questiontext = question.find("div", {"class": "post-text"})
print("Question: \n", questiontext.get_text().strip())
answer = soupified.find("div", {"class": "answer"})
answertext = answer.find("div", {"class": "post-text"})
print("Best answer: \n", answertext.get_text().strip())
هنا ، نعتمد على معرفتنا بهيكل مستند HTML لاستخراج ما نريد منه. وهنا مخرج البرمجة
Question: What is the module/method used to get the current time? Best answer: Use: import datetime datetime.datetime.now() datetime.datetime(2009, 1, 6, 15, 8, 24, 78915) print(datetime.datetime.now()) 2009-01-06 15:08:24.789150 And just the time: datetime.datetime.now().time() datetime.time(15, 8, 24, 78915) print(datetime.datetime.now().time()) 15:08:24.789150 See the documentation for more information. To save typing, you can import the datetime object from the datetime module: from datetime import datetime Then remove the leading datetime. from all of the above.
في هذا المثال ، كانت لدينا حاجة محددة: استخراج سؤال وإجابته. في بعض السيناريوهات – على سبيل المثال ، استخراج العناوين البريدية من صفحات الويب – سنحصل على النص بالكامل (بدلاً من أجزاء منه فقط) من صفحة الويب أولاً ، قبل القيام بأي شيء آخر.
عادةً ما تحتوي جميع مكتبات HTML على بعض الوظائف التي يمكنها إزالة جميع علامات HTML وإرجاع المحتوى بين العلامات فقط. ولكن هذا غالبًا ما ينتج عنه مخرجات صاخبة ، وقد ينتهي بك الأمر برؤية الكثير من JavaScript في المحتوى المستخرج أيضًا. في مثل هذه الحالات ، يجب أن نتطلع إلى استخراج المحتوى بين تلك العلامات التي تحتوي عادةً على نص في صفحات الويب.
تسوية يونيكود (Unicode Normalization)
أثناء قيامنا بتطوير رمز لتنظيف علامات HTML ، قد نواجه أيضًا العديد من أحرف Unicode ، بما في ذلك الرموز والرموز التعبيرية والأحرف الرسومية الأخرى.

لتحليل هذه الرموز غير النصية والأحرف الخاصة ، نستخدم تسوية يونيكود. هذا يعني أنه يجب تحويل النص الذي نراه إلى شكل من أشكال التمثيل الثنائي لتخزينه في جهاز الكمبيوتر. تُعرف هذه العملية باسم ترميز النص (text encoding) . يمكن أن يؤدي تجاهل مشكلات الترميز إلى المزيد من الأخطاء لاحقا.
هناك العديد من أنظمة الترميز، ويمكن أن يختلف الترميز الافتراضي باختلاف أنظمة التشغيل. في بعض الأحيان (أكثر شيوعًا مما تعتقد) ، خاصة عند التعامل مع نص بلغات متعددة ، وبيانات الوسائط الاجتماعية ، وما إلى ذلك ، قد نضطر إلى التحويل بين مخططات الترميز هذه أثناء عملية استخراج النص. (هذا الكتاب) يعتبر مقدمة ممتازة حول كيفية تمثيل اللغة على أجهزة الكمبيوتر وما هو الاختلاف الذي يحدثه نظام الترميز. فيما يلي مثال على معالجة Unicode:

سيعطينا المخرج
b'I love Pizza \xf0\x9f\x8d\x95! Shall we book a cab \xf0\x9f\x9a\x95 to get pizza?'
هذا النص المعالج يمكن للأجهزة قراءته ويمكن استخدامه في المراحل المتقدمة من خط إنتاج معالجة اللغة الطبيعية.
تصحيح الإملاء
في عالم الكتابة السريعة والكتابة بأصابع اليد ، غالبًا ما تحتوي بيانات النص الوارد على أخطاء إملائية. يمكن أن يكون هذا سائدًا في محركات البحث وروبوتات الدردشة النصية المنتشرة على الأجهزة المحمولة ووسائل التواصل الاجتماعي والعديد من المصادر الأخرى. بينما نزيل علامات HTML ونتعامل مع أحرف Unicode ، تظل هذه مشكلة فريدة قد تضر بالفهم اللغوي للبيانات ، وغالبًا ما تعيق الرسائل النصية المختصرة في المدونات الصغيرة الاجتماعية معالجة اللغة وفهم السياق. يلي مثالان:
Shorthand typing: Hllo world! I am back!
Fat finger problem : I pronise that I will not bresk the silence again!
في حين أن الكتابة المختصرة (Shorthand typing) منتشرة في واجهات الدردشة ، فإن مشاكل الأصابع السمينة (Fat finger problem) شائعة في محركات البحث وغالبًا ما تكون غير مقصودة.
على الرغم من فهمنا للمشكلة ، ليس لدينا طريقة قوية لإصلاح ذلك ، ولكن لا يزال بإمكاننا القيام بمحاولات جيدة لتخفيف المشكلة. أصدرت مايكروسوفت REST API التي يمكن استخدامها في Python للتدقيق الإملائي المحتمل:
import requests
import json
api_key = "<ENTER-KEY-HERE>"
example_text = "Hollo, wrld" # the text to be spell-checked
data = {'text': example_text}
params = {
'mkt':'en-us',
'mode':'proof'
}
headers = {
'Content-Type': 'application/x-www-form-urlencoded',
'Ocp-Apim-Subscription-Key': api_key,
}
response = requests.post(endpoint, headers=headers, params=params, data=data)
json_response = response.json()
print(json.dumps(json_response, indent=4))
Output (partially shown here):
"suggestions": [
{
"suggestion": "Hello",
"score": 0.9115257530801
},
{
"suggestion": "Hollow",
"score": 0.858039839213461
},
{
"suggestion": "Hallo",
"score": 0.597385084464481
}
وغالبًا
تصحيح الخطأ الخاص بالنظام (System-Specific Error Correction)
إن HTML أو النص الخام المقتبس من الويب هما مجرد مصدران للبيانات النصية. ضع في اعتبارك سيناريو آخر حيث تكون مجموعة البيانات الخاصة بنا في شكل مجموعة من مستندات PDF.
يبدأ خط الإنتاج في هذه الحالة باستخراج نص عادي من مستندات PDF. ومع ذلك ، يتم ترميز مستندات PDF المختلفة بشكل مختلف ، وفي بعض الأحيان ، قد لا نتمكن من استخراج النص الكامل ، أو قد تتشوه بنية النص. إذا كنا بحاجة إلى نص كامل أو يجب أن يكون نصنا نحويًا أو في جمل كاملة (على سبيل المثال ، عندما نريد استخراج العلاقات بين مختلف الأشخاص في الأخبار بناءً على نص الصحيفة) ، فقد يؤثر ذلك على تطبيقنا.
في حين أن هناك العديد من المكتبات ، مثل PyPDF و PDFMiner وما إلى ذلك ، لاستخراج نص من مستندات PDF ، إلا أنها بعيدة كل البعد عن الكمال ، وليس من غير المألوف أن تصادف مستندات PDF لا يمكن معالجتها بواسطة هذا المكتبات
مصدر آخر شائع للبيانات النصية هو المستندات الممسوحة ضوئيًا. عادةً ما يتم استخراج النص من المستندات الممسوحة ضوئيًا من خلال التعرف الضوئي على الأحرف (OCR) ، باستخدام مكتبات مثل Tesseract. ضع في اعتبارك مثال الصورة – مقتطف من مقالة صدرت عام 1950 في مجلة The Sociological Review .

يوضح مقتطف البرمجة أدناه كيف يمكن استخدام pytesseract لاستخراج النص من هذه الصورة:
from PIL import Image from pytesseract import image_to_string filename = "somefile.png" text = image_to_string(Image.open(filename)) print(text)
سيقوم هذا الكود بطباعة الإخراج على النحو التالي ، حيث يشير “\ n” إلى حرف سطر جديد:
’in the nineteenth century the only Kind of linguistics considered\nseriously was this comparative and historical study of words in languages\nknown or believed to Fe cognate—say the Semitic languages, or the Indo-\nEuropean languages. It is significant that the Germans who really made\nthe subject what it was, used the term Indo-germanisch. Those who know\nthe popular works of Otto Jespersen will remember how fitmly he\ndeclares that linguistic science is historical. And those who have noticed’
نلاحظ وجود خطأين في إخراج نظام التعرف الضوئي على الحروف في هذه الحالة. اعتمادًا على جودة المسح الأصلي ، يمكن أن يحتوي إخراج التعرف الضوئي على الحروف على قدر أكبر من الأخطاء.
كيف ننظف هذا النص قبل إدخاله في المرحلة التالية من خط الإنتاج تتمثل إحدى الطرق في معالجة النص من خلال مدقق إملائي مثل pyenchant، والذي سيحدد الأخطاء الإملائية ويقترح بعض البدائل. تستخدم الأساليب الأكثر حداثة معماريات الشبكات العصبية لتدريب نماذج اللغة القائمة على الكلمة / الأحرف ، والتي تُستخدم بدورها لتصحيح إخراج نص التعرف الضوئي على الحروف بناءً على السياق [ochre].
ما رأيناه حتى الآن ليس سوى بعض الأمثلة على المشكلات المحتملة التي قد تظهر أثناء عملية استخراج النص والتنظيف. على الرغم من أن معالجة اللغة الطبيعية (NLP) تلعب دورًا صغيرًا جدًا في هذه العملية.













إضافة تعليق