تنبيه : هذه المقالة مُترجمة و بالإمكانكم الإطلاع على المقاله الأصلية في مدونة فكتور جو و عنوانها
An Introduction to Neural Networks
نسمع كثيرا عن مصطلح الـ Neural Network أو الشبكات العصبية بالعربية . و هذا المصطلح قد يعطي الإنطباع بالصعوبة و التقيد و لكن الأمر أسهل بكثير مما قد يتخيلة الكثيرين. و من خلال هذا المقال سنحاول أن نفهم ما هي الشبكات العصبية و سنقاوم كذلك ببنائها من الصفر بإستخدام البايثون.
1- حجر الأساس : العصبونات (Neurons)
الوحدة الأساسية للشبكات العصبية ( Neural Network ) تعرف بأسم العصبونه (Neurons ) و مهمتها هي أن تأخذ بعض المدخلات و تجري عليها عدة عمليات حسابية و تنتج لنا نتيجة أو مخرج .

هناك ثلاثة أمور تحدث داخل العصبونه (Neuron ) في الصورة السابقة :
أولاً : كل مدخل تم ضربه بـ وَزن (Weight):


ثانياً : كل المدخلات الموزونه تم جمعها مع بعضها و إضافة إنحياز (Bias ) لها :

ثالثاً : المجموع تم تمريره بدالة تنشيط (Activation Function) :

الهدف و الحكمة من دالة التنشيط ( Activation Function ) هو تحويل مدخل عير مُقيد إلى مخرج مقيد ذا بشكل يمكن التبؤ به. و أحد أكثر دوال التنشيط رواجاً هي دالة السيجمويد (Sigmoid Function )
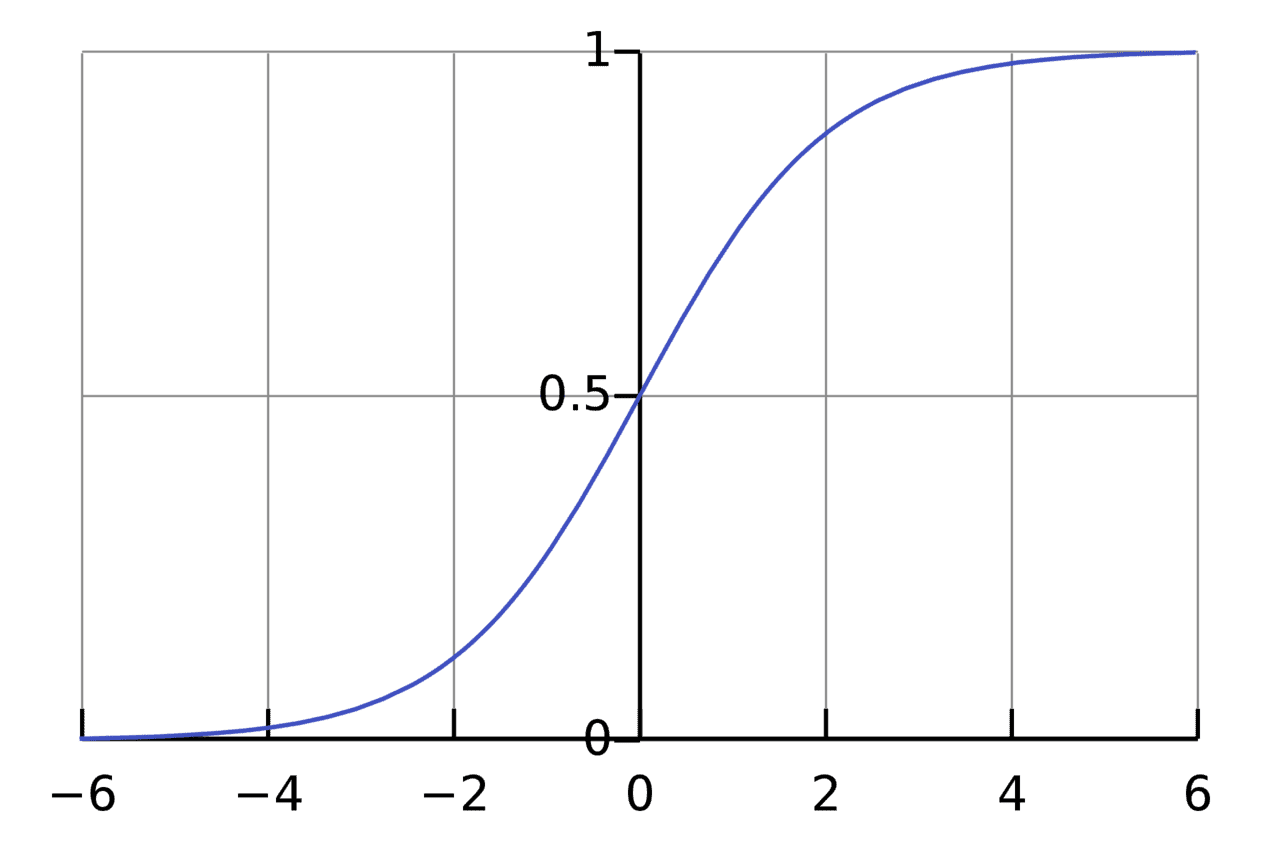
مخرجات دالة السيجمويد تتمثل في أرقام بين 0 و 1 حيث تقوم الدالة بتحويل أي رقم سلبي كبير إلى ~0 و أي رقم موجب كبير إلى ~1 فبالتالي يمكن تصور هذه الدالة بأنها تقوم بضعط أو عصر (-∞ , ∞ ) إلى ( 0 , 1 ) .
مثال للتوضيح
فلنفترض أن لدينا عصبونه بمدخلين و كذلك نستخدم دالة السيجمويد مع المعطيات التالية
![\begin{array}{c}{\omega=[0,1]} \\ {\quad b=4}\end{array}](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-20662489e075fdc207833d39e7571dfd_l3.png "Rendered by QuickLaTeX.com")
![\omega=[0,1]](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-fad918cffe48d853a3b3c6c95f195344_l3.png "Rendered by QuickLaTeX.com") هي طريقة أخرى لكتابة
هي طريقة أخرى لكتابة  في هيئة المتجهات (Vector Form) ، و الأن لنفترض أن مدخلات العصبونه لديها هذه القيم [X=[2,3 سنستخدم الضرب النقطي (Dot product ) لتبسيط كتابة المعادلات و سهولة قرائتها
في هيئة المتجهات (Vector Form) ، و الأن لنفترض أن مدخلات العصبونه لديها هذه القيم [X=[2,3 سنستخدم الضرب النقطي (Dot product ) لتبسيط كتابة المعادلات و سهولة قرائتها

و بالتالي مُخرج العصبونه سيكون 0.999 في حال كانت قيم المدخلات X=[2,3]
و تسمى هذه العملية بالتغذية الأمامية (Feed Forward ) .
برمجة العصبونه ( Neurons) :
في هذه الجزئية نستخدم نمباي ( NumPY ) و هي مكتبة حسابية في البايثون :
import numpy as np
def sigmoid(x):
# دالة التفعيل
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# ضرب الأوزان مع المدخلات ثم جمعها مع الإنحياز
total = np.dot(self.weights, inputs) + self.bias
# إستخدام دالة السيجمويد
return sigmoid(total)
# إستهلال الأوزان و الإنحياز
weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
# قيم مدخلات العصبونه
x = np.array([2, 3]) # x1 = 2, x2 = 3
# ناتج الشبكة
print(n.feedforward(x)) # 0.9990889488055994
و كما نرى فالنتيجة مشابة للنيجة التي حصلنا عليها سابقا.
2- ضم العصبونات لتكوين شبكة عصبية :
الشبكة العصيبة (Neural Network ) ليست سوى مجموعة من العصبونات الموصولة ببعضها البعض . و هنا مثال لشبكة عصبية بسيطة :
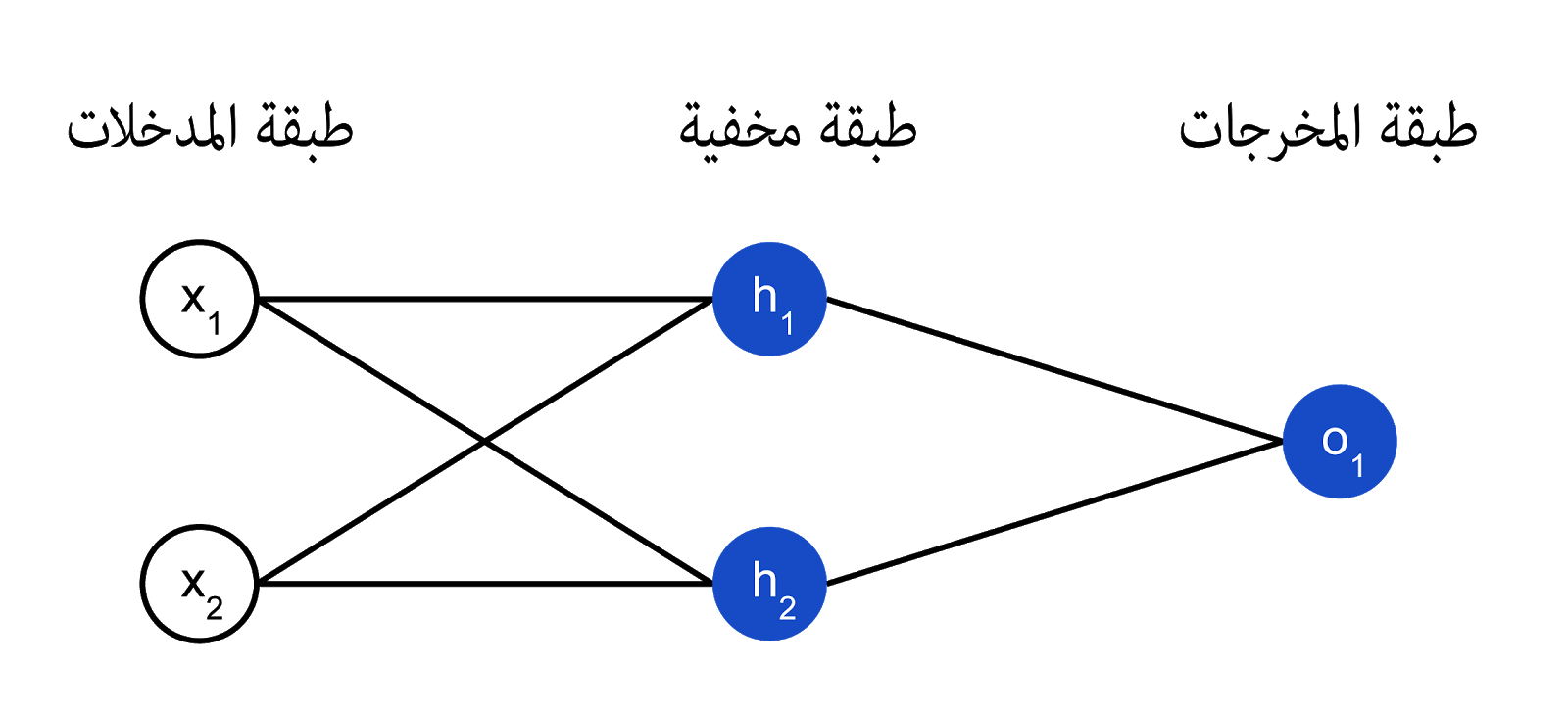
هذه الشبكة تتألف من مُدخلين ثم طبقة مخفية ( Hidden Layer ) تتألف من عصبونين ( h1 و h2 ) بالإضافة إلى طبقة المخرجات و التي تحتوي على عصبون (o1) ، من الجدير بالملاحظة أن مُدخلات O1 هي مُخرجات كٍلا العصبونين h1 و h2 و هذا ما يشكل شبكة.
الطبقة الخفية : هي أي طبقة تقع بين طبقة المدخلات ( الطبقة الأولى) و طبقة المخرجات ( الطبقة الأخيرة ).
مثال : التغذية الأمامية (Feed Forward) :
دعونا نستخدم الشبكة أعلاه و لنتفرض أن كل العصبونات ( Neurons ) لديها نفس الأوزان w=[0,1] و نفس الإنحياز b = 0 و نستخدم دالة السيجمويد في جميعها . و لتمثل h1 , h2 ,o1 مخرجات العصبونات التي تمثلها .
ماذا سيحدث لو مررنا المدخلين x = [2,3] على هذه الشبكة ؟

![\begin{aligned} o_{1} &=f\left(w \cdot\left[h_{1}, h_{2}\right]+b\right) \\ &=f\left(\left(0 * h_{1}\right)+\left(1 * h_{2}\right)+0\right) \\ &=f(0.9526) \\ &=0.7216 \end{aligned}](https://ai.malawad.com/wp-content/ql-cache/quicklatex.com-b78f73889ad9159dfec7865de0c34a4d_l3.png "Rendered by QuickLaTeX.com")
وبالتالي نجد أن الشبكة العصبية ستعطينا نتيجة 0.7216 إذا ما كانت مدخلاتها x=[2,3]
الجدير بالذكر بأن الشبكة العصبية قد تتألف من أي عدد من الطبقات و أي عدد من العصبونات في كل طبقة و لكن تبقى الفكرة نفسها نغذي الشبكة بالمُدخلات من المقدمة عن طريق العصبونات من أجل الحصول على مُخرجات في النهاية . من أجل التبسيط سنستخدم نفس الشبكة في الصورة أعلاه.
برمجة الشبكة العصبية : التعذية الأمامية
فلتقم الأن ببرمجة التقذية الأمامية للشبكة العصبية ، هذه صورة الشبكة العصبية كمرجع.
import numpy as np
# كود من الجزئية السابقة
class OurNeuralNetwork:
'''
:الشبكة العصبية لديها
- مدخلين
- (h1, h2) طبقة خفية تحتوي على عصبونين
- (o1) طبقة مخرجات تحتوي على عصبون واحد
:كل عصبون لديه نفس الأوزان و الإنحياز
- w = [0, 1]
- b = 0
'''
def __init__(self):
# إستهلال قيم الأوزان و الإنحياز
weights = np.array([0, 1])
bias = 0
# تم إنشاءه في الجزئية السابقة Neuron class
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
# h2 , h1 هي مخرجات o1 مدخلات
out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))
return out_o1
network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421
و حصلنا على نفس النتيجة 0.7216 .
3- تدريب الشبكة العصبية: الجزء الأول
لدينا القياسات التالية :
| الأسم | الوزن ( كج) | الطول (سم) | الجنس |
| إيمان | 70 | 165 | أنثى |
| محمد | 97 | 172 | ذكر |
| عبد الفتاح | 89 | 170 | ذكر |
| أمال | 57 | 160 | أنثى |
نرغب في تدريب الشبكة للتتنبأ بجنس الشخص بناءً على وزنه و طوله
سنمثل الذكر بـ 0 و الأنثى بـ 1 و كما سنقوم تحريك البيانات لنجعل قرائتها أسهل .
| الأسم | الوزن (ناقص 72) | الطول ( ناقص 166) | الجنس |
| إيمان | -2 | -1 | 1 |
| محمد | 25 | 6 | 0 |
| عبد الفتاح | 17 | 4 | 0 |
| أمال | -15 | -6 | 1 |
هنا قمنا بإختيار قيم التحريك ( 72و 166) و هي أرقام قمت بإختيارها من عندي لجعل البيانات أسهل للقراءة و التوضيح لكن في العادة نقوم بتحريك البيانات بناءً على المتوسط (mean ) .
الخسارة (Loss) :
قبل أن ندرب الشبكة العصبية نحن بحاجة لطريقة نخبر بها الشبكة العصبية عن جودة أدائها و إذا ما كان هناك إمكانية لتقوم بعمل أفضل . و هذه وظيفة دالة الخسارة ( Loss function )
هنالك العديد من دوال الخسارة و هنا سنستخدم دالة تعرف بـ متوسط خطأ التربيع ( Mean Square Error MSE )

فلنقم بتفصيل هذه المعادلة
- n هو عدد الأمثلة ، و هنا لدينا أربعة
- y تمثل المتغير الذي نرغب بالتنبؤ به
- Ytrue تمثل القيمة الحقيقية للمتغير ( الجواب الصحيح ) كمثال Ytrue بالنسبة لإيمان تعتبر 1 (أنثى)
- Ypred تمثل القيمة المتنبأ بها للمتغير و هي قيمة المخرجات من الشبكة
تعرف  بـ خطا التربيع ( Squared error ) و ببساطة كل ما تقوم به دالة الخسارة هي حساب المتوسط من ناتج كل الأخطاء التربيعية و لذلك تسمى بـ متوسط خطأ التربيع ( Mean square error ) و كلما كانت تنبؤات الشبكة أفضل كلما كانت قيمة الخسارة قليلة .
بـ خطا التربيع ( Squared error ) و ببساطة كل ما تقوم به دالة الخسارة هي حساب المتوسط من ناتج كل الأخطاء التربيعية و لذلك تسمى بـ متوسط خطأ التربيع ( Mean square error ) و كلما كانت تنبؤات الشبكة أفضل كلما كانت قيمة الخسارة قليلة .
و بالتالي : تبؤات أفضل = خسارة أقل .
مثال على حساب الخسارة:
فلنفترض أن مخرجات شبكتنا كانت 0 بمعنى أن الشبكة واثقة بأن كل البشر هم ذكور ، في هذه الحالة ماذا ستكون الخسارة
| الأسم | ytrue | ypred | ytrue−ypred2 |
| إيمان | 1 | 0 | 1 |
| مدثر | 0 | 0 | 0 |
| عبد الفتاح | 0 | 0 | 0 |
| أمال | 1 | 0 | 1 |

و هذه الخسارة تعتبر كبيرة جداً
برمجة دالة الخسارة :
هنا سنقوم ببرمجة دالة الخسارة :
import numpy as np def mse_loss(y_true, y_pred): return ((y_true - y_pred) ** 2).mean() y_true = np.array([1, 0, 0, 1]) y_pred = np.array([0, 0, 0, 0]) print(mse_loss(y_true, y_pred)) # 0.5
و النتيجة هي 0.5 .
4- تدريب الشبكة العصبية: الجزء الثاني
الأن لدينا هدف واضح كالشمس و هو تقليل خسارة الشبكة العصبية . نعلم بأنه بمقدورنا تغيير أوزان الشبكة و الإنحياز من أجل التأثير على التنبؤات . ولكن السؤال هو كيف نفعل ذلك بطريقة تقلل من الخسارة.
| الأسم | الوزن (ناقص 72) | الطول ( ناقص 166) | الجنس |
| إيمان | -2 | -1 | 1 |
و بالتالي متوسط الخطأ التربيعي ( mean square error ) سيصبح الخطأ التربيعي لإيمان سيصبح

طريقة أخرى للتفكير في دالة الخسارة هي بإعتبارها دالة الأوزان و الإنحيازان . و بالتالي دعونا نميز كل الأوزان و الإنحيازات في شبكتنا :
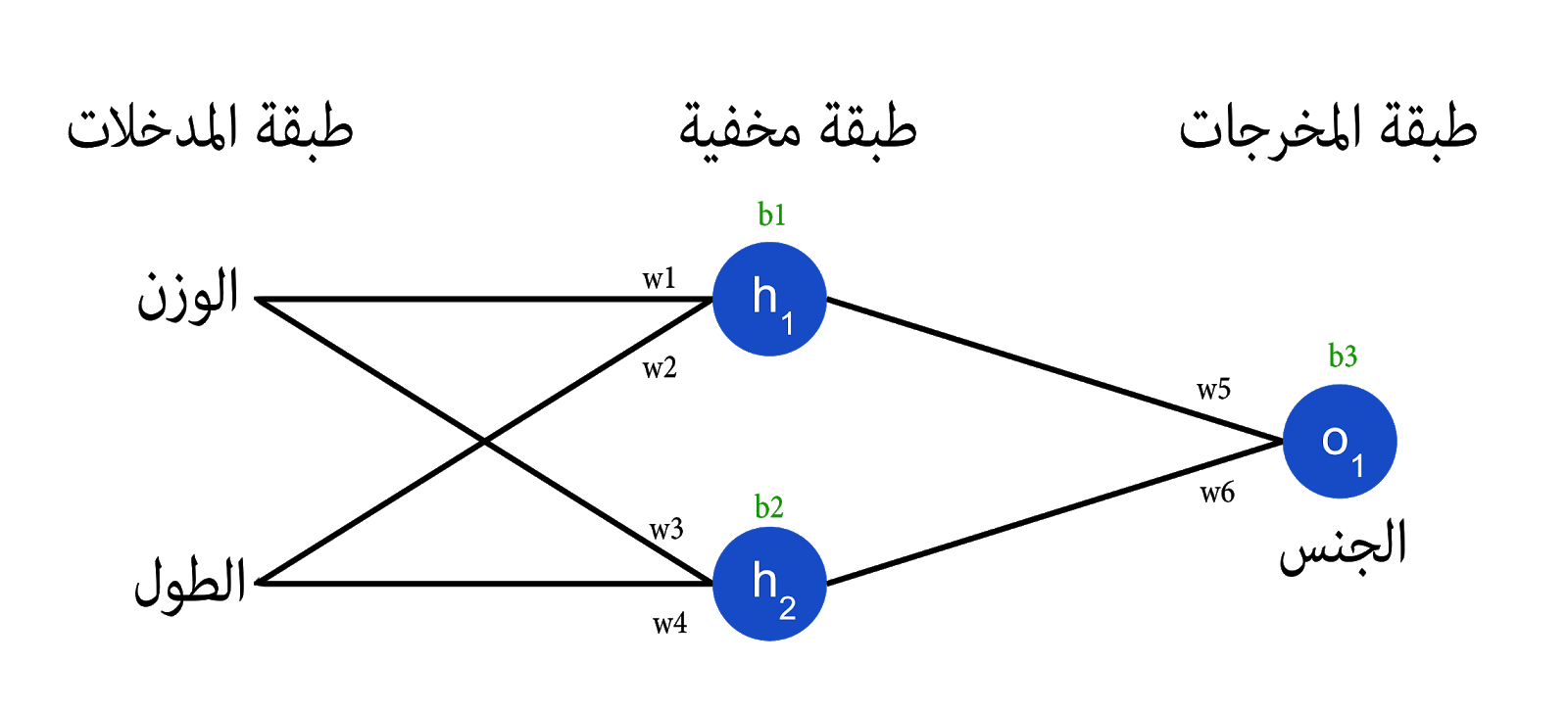
و الأن يمكننا أن نكتب الخسارة (Loss) كدالة متعددة المتغيرات ( Multivariable Function ) :

فلنفترض أننا نرغب بتعديل w1 فكيف سيأثر ذلك على دالة الخسارة L ؟ جواب هذا السؤال يمكن الوصول إليه بإستخدام المشتقات الجزئية لــ 
حتى نبدأ بالحساب علينا أولا أن نقوم بإعادة ترتيب المشتقة الجزئية نسبة إلى 

هنا قمنا بإستخدام قاعدة التسلسل ( Chain rule )
بإمكاننا حساب المشتقة  لأنه سبق و قمنا و بحساب
لأنه سبق و قمنا و بحساب 

الأن نحن بحاجة لأن نتعامل مع  و كما فعلنا سابقاً فلنفرض بأن h1 , h2 ,o1 هم مخرجات العصبونات اللاتي يمثلُهن ، و بالتالي :
و كما فعلنا سابقاً فلنفرض بأن h1 , h2 ,o1 هم مخرجات العصبونات اللاتي يمثلُهن ، و بالتالي :

F هنا هي دالة السيجمويد للتنشيط و هي التنبؤ المطلوب و المعروف أيضاً بالمُخرج o1
هي التنبؤ المطلوب و المعروف أيضاً بالمُخرج o1
بما أن w1 تؤثر فقط على h1 يمكننا كتابة الأتي :

و سنقوم بالمثل مع  :
:

و بالتالي

x1 هنا تمثل الوزن و x2 تمثل الطول . هذه المرة الثانية التي نرى فيها f'(x) ( والتي تمثل المشتقة لدالة السيجمويد ) ، لذلك هيا نشتقها :

سنستخدم هذه الصيغة لـ f'(x) لاحقا.
و بذلك نكون قد إنتهينا من جميع المعادلات الرياضية و حساباتها بحيث تمكنا من تقسيم لعدة أجزاء بإمكاننا بسهولة حسابتها :

ملاحظة :نظام حساب المشتقات الجزئية عكسيا بمعنى البدء من النهاية و الرجوع للوراء يعرف بـ الإنتشار العكسي (BackPropagation) .
مثال لحساب المشتقات الجزئية :
فلنفترض أن لدينا إيمان فقط في بياناتنا
| الأسم | الوزن (ناقص 72) | الطول ( ناقص 166) | الجنس |
| إيمان | -2 | -1 | 1 |
فلنقم أولا بإستهلال قيم الأوزان بـ 1 و قيم الإنحيازات بـ 0 . و من ثم نقوم بعملية التغذية الأمامية خلال الشبكة كاملة و بالتالي سنحصل على



و هنا نجد بأن الشبكة أنتجت لنا  وهذه النتيجة في المنتصف فهي لا تفضل الذكر (1) أو الأنثى (0)
وهذه النتيجة في المنتصف فهي لا تفضل الذكر (1) أو الأنثى (0)
و الأن نقوم بحساب المشتقة :





للتذكير فقد قمنا سابقاً بإشتقاق دالة السيجمويد بهذه الطريقة
.
و هذا يخبرنا بأنه لو زدنا قيمة w1 فستزيد قيمة الخسارة بشكل طفيف
5- تدريب النزول الإشتقاقي العشوائي ( Stochastic Gradient Descent ) :
الأن أصبح بحوزتنا جميع الأدوات المطلوبة لنقوم بتمرين شبكة عصبية ، و سنقوم بإستخدام خوارزمية تحسين (Optimization Algorthim ) تسمى النزول الإشتقاقي العشوائي ( Stochastic Gradient Descent ) أو SGD بإختصار ، و هذه الخوارزمية تقوم بإخبارنا كيف نغير قيم الوزن و الإنحياز حتى نقلل الخسارة وهذا هو أهم شيئ بالنسبة لنا . و ببساطة هي معادلة التحديث التالية :

 هنا تمثل عدد ثابت يسمى معدل التعلم (Learning rate) و وظيفته التحكم في سرعة التدريب ، و كل ما نقوم به هو طرح قيمة
هنا تمثل عدد ثابت يسمى معدل التعلم (Learning rate) و وظيفته التحكم في سرعة التدريب ، و كل ما نقوم به هو طرح قيمة  من
من 
- لو كانت
 موجبة ، ستنقص ، و هذا سيودي إلى إنقاص الخسارة L
موجبة ، ستنقص ، و هذا سيودي إلى إنقاص الخسارة L - لو كانت سالبة ، ستزيد ، و هذا سيودي إلى إنقاص الخسارة L
و إذا طبقنا هذا الأمر على كل وزن و على كل إنحياز في الشبكة ، فتدريجياً ستنقص الخسارة و الشبكة العصبية ستتحسن .
و الطريقة التي نتبعها في عملية التدريب كالتالي :
- نقوم بإختيار عينة واحدة من بياناتنا ، و لهذا السبب تسمى الخوارزمية بالعشوائية ( Stochastic ) لأننا نعمل على عينه واحده.
- نقوم بحساب المشتقات الجزئية للخسارة نسبةً إلى الأوزان و الإنحياز . كمثال (
 ……إلخ )
……إلخ ) - بعد ذلك نقوم بإستخدام معادلة التحديث من أجل تحديث كل وزن و إنحياز.
- نكرر الخطوات من البداية.
برمجة شبكة عصبية متكاملة :
و أخير حان الوقت لبرمجة شبكة عصبية من البداية حتى النهاية ، و للتذكير فبحوذتنا هذه البيانات :
| الأسم | الوزن (ناقص 72) | الطول ( ناقص 166) | الجنس |
| إيمان | -2 | -1 | 1 |
| مدثر | 25 | 6 | 0 |
| عبد الفتاح | 17 | 4 | 0 |
| أمال | -15 | -6 | 1 |
import numpy as np
def sigmoid(x):
# f(x) = 1 / (1 + e^(-x)) دالة السيجمويد
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# f'(x) = f(x) * (1 - f(x)) : مشتقة السيجمويد
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# بنفس الطول arrays عبارة عن y_true و y_pred
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
'''
:الشبكة العصبية لديها
- مدخلين
- (h1, h2) طبقة خفية تحتوي على عصبونين
- (o1) طبقة مخرجات تحتوي على عصبون واحد
'''
def __init__(self):
# الأوزان
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# الإنحياز
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# لها عنصرين array هي x
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
'''
تساوي عدد الأمثلة n و (n x 2) حجمها numpy array البيانات هي
عناصر n لها numpy array هي all_y_trues
تمثل البيانات all_y_trues العناصر في
'''
learn_rate = 0.1
epochs = 1000 # عدد الدورات خلال البيانات
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- التفذية الأمامية و التي سنحتاجها لاحقاً
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- .حساب المشتقات الجزئيى
d_L_d_ypred = -2 * (y_true - y_pred)
# o1 العصبون
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# h1 العصبون
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# h2 العصبون
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- تحديث الأوزان و الإنحياز
# h1 العصبون
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# h2 العصبون
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# O1 العصبون
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- epoch حساب الخسارة بعد كل
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# التغريف بالبيانات
data = np.array([
[-2, -1], # إيمان
[25, 6], # مدثر
[17, 4], # عبد الفتاح
[-15, -6], # أمال
])
all_y_trues = np.array([
1, # إيمان
0, # مدثر
0, # عبد الفتاح
1, # أمال
])
# تدريب الشبكة العصبية
network = OurNeuralNetwork()
network.train(data, all_y_trues)
بوسعكم تجريب الكود هنا و كما يتوفر الكود على github
نلاحظ أن الخسارة تتناقص بشكل ثابت و تدرجي بينما تتعلم الشبكة :
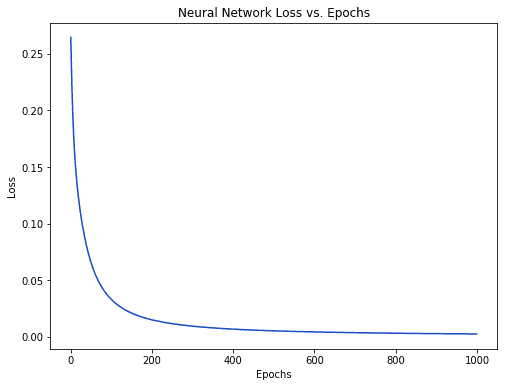
الأن بمقدورنا إستخدام الشبكة للتنبؤ بالجنس :
# القيام بالتنبؤ
Hala = np.array([-7, -3]) # 65 kg, 163 cm
Khaled = np.array([20, 2]) # 92 kg, 168 cm
print("Hala: %.3f" % network.feedforward(Hala)) # 0.951 - F
print("Khaled: %.3f" % network.feedforward(Khaled)) # 0.039 - M
و إلى هنا نكون قد وصلنا إلى نهاية هذه المقالة و التي تعرقنا فيها على أساسيات الشبكات العصبية. و بمقدوركم اللعب بالشبكات العصبية هنا.













إضافة تعليق