
تحدثنا في المقالات السابقة عن الشبكات العصبية و من خلال سلسة التبصير الحاسوبي تعرفنا على مرشحات اللف الرياضي و كذلك على أنواعها السمات المختلفة كما تعرفنا كذلك على طريقة إستغلال خوازمية هوف لهذا المرشحات للكشف عن الأجسام المميزة في الصورة ـ و الأن في هذه المقالة سنتعرف على شبكات اللف الرياضي العصبية (convolutional neural network) و تستخدم هذه الشبكات في كل مكان في حياتنا اليوم .
شبكات اللف الرياضي العصبية
تتألف شبكات اللف الرياضي العصبية من سلسلة من الطبقات و التي تتعلم إستخراج السمات المميزة من أي صورة ، و العمود الفقري لهذا النوع من الشبكات العصبية هو طبقة اللف الرياضي. و تقوم طبقة اللف الرياضي بتطبيق سلسة من مُرشحات الصور (filters) المختلفة و المعروفة أيضاً بأنوية اللف الرياضي إلى الصورة المدخلة. و هذه المُرشحات تستخرج سمات مختلفة من الصورة مثل حواف الأجسام و الزوايا و التدرجات اللونية . و بينما تتدرب شبكات اللف الرياضي العصبية فهي تقوم بتحديث الأوزان في طبقة اللف الرياضي بإستخدام الإنتشارالعكسي (backpropagation) و هذه الأوزان بدورها تحدد نوعية مُرشح الصورة. و الناتج النهائي هو مُصنف (classifier) يتألف من العديد من طبقات اللف الرياضي و التي بدورها تعلمت كيفية ترشيح الصورة لإستخراج السمات (features) المهمة منها .
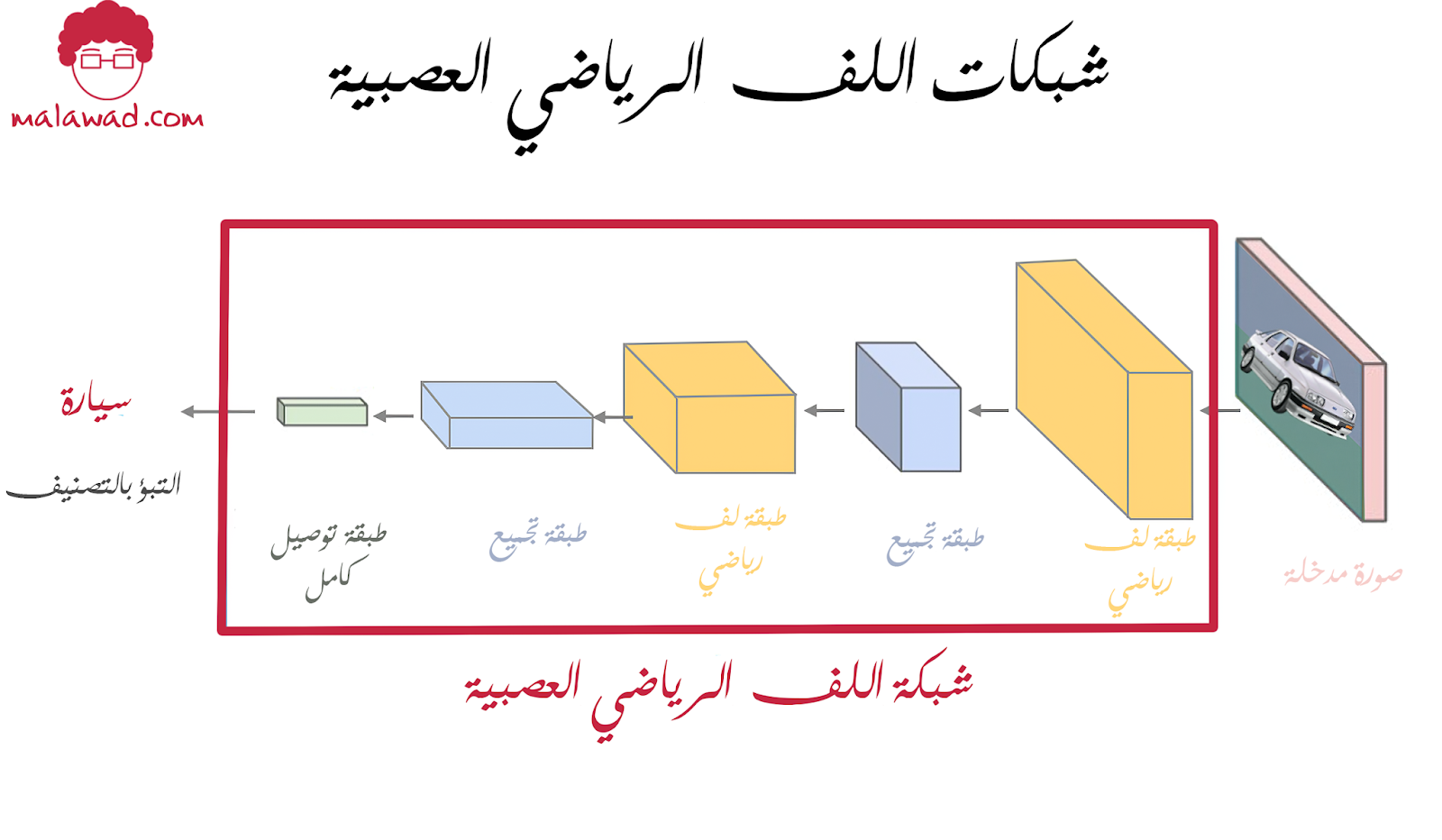
طبقات اللف الرياضي :
أي صورة ملونة تحتوي على ثلاثة قنوات لونية الأحمر و الأزرق و الأخضر (RGB) و لنفترض أن لدينا الصورة التالية ذات الأبعاد 32×32×3 حيث يمثل العمق هنا قنوات الصورة اللونية ، وسنقوم بعملية اللف الرياضي بإستخدم مرشح (filter) أبعاده 5×5×3 و نلاحظ هنا أن المرشح قيمة العمق لديه 3 و هذا يتناسب مع عمق الصورة التي سيتم ترشحيها.
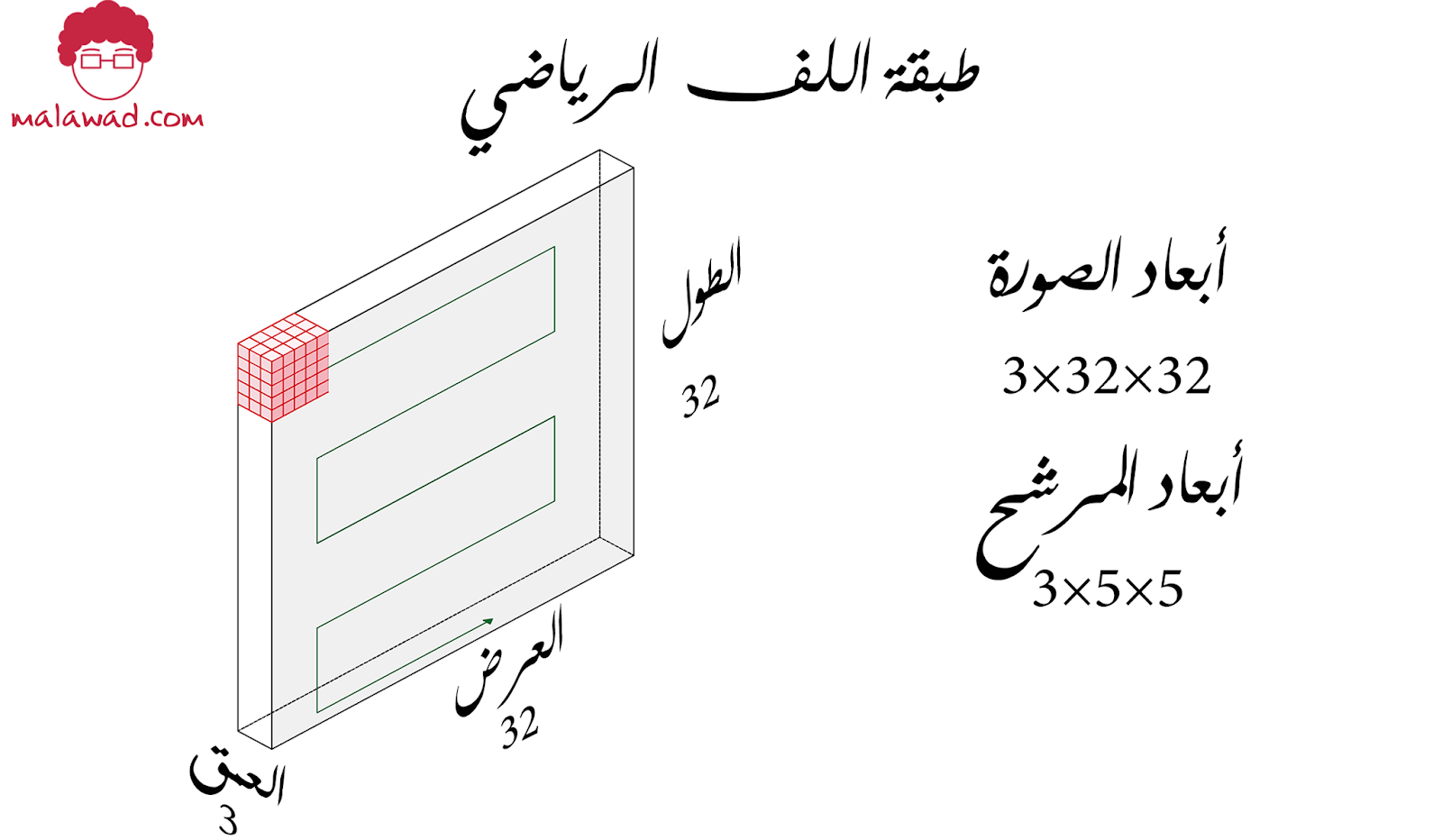
و عملية اللف الرياضي هي عبارة عن تحريك المرشح على كامل الصورة و إجراء عملية الضرب النقطي (dot product) و حساب القيم الجديدة ، وبعد إجراء هذه العملية سنحصل على خريطة تفعيل (Activation map ) وقد تسمى احيانا بخريطة سمات (feature map) و حجمها 28 × 28 × 1 و السبب في أن حجم الخريطة هو 28 × 28 هو أن المرشح سيتحرك 28 مرة أفقياً و 28 مرة عامودياً حتى يغطي كامل الصورة.

في العادة سيكون لدينا عدة مرشحات ذات حجم واحد ولكن قيم مختلفة و بدورها ستقوم كذلك بعملية اللف الرياضي لينتج لنا خريطة التفعيل التالية .
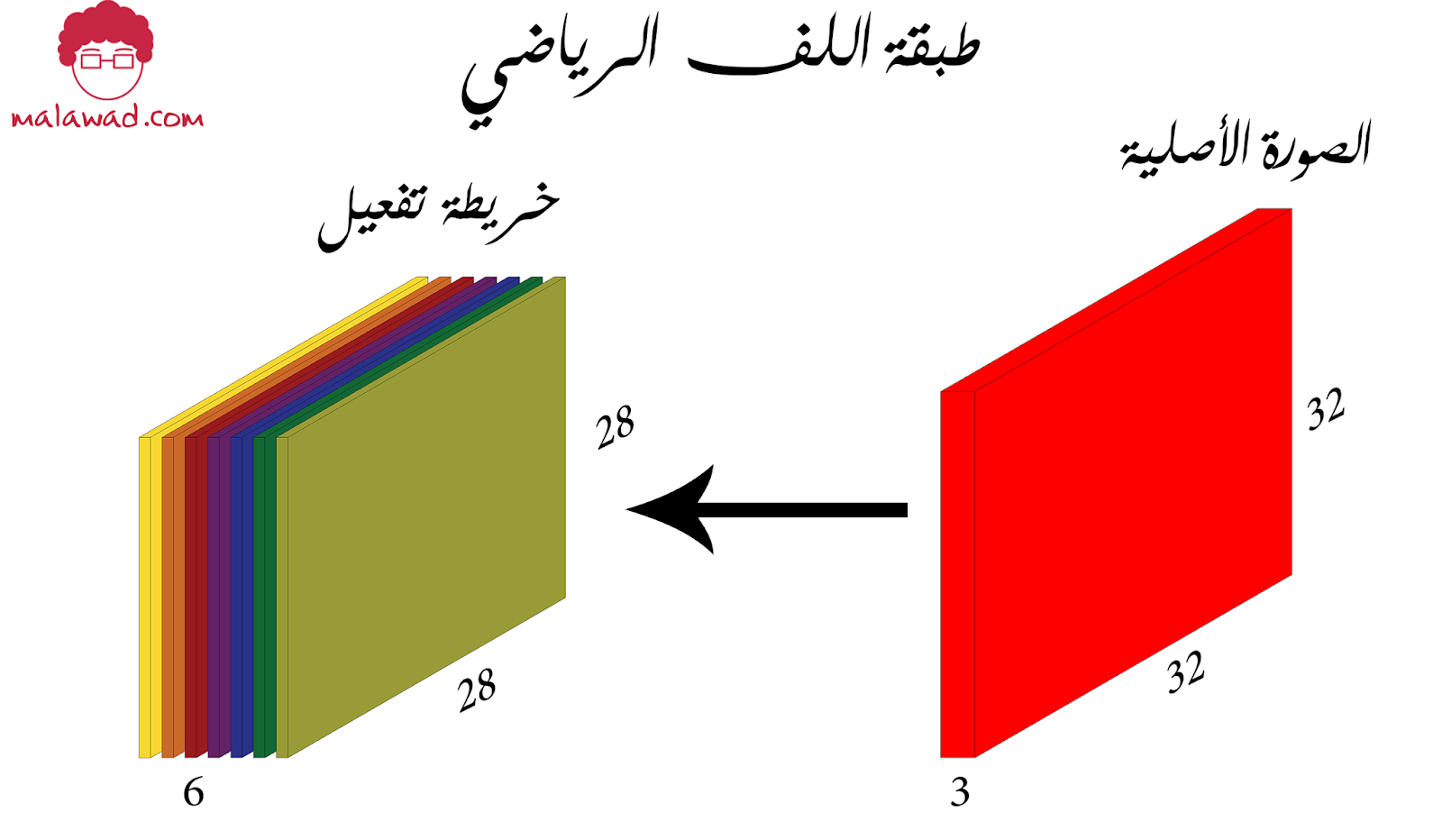
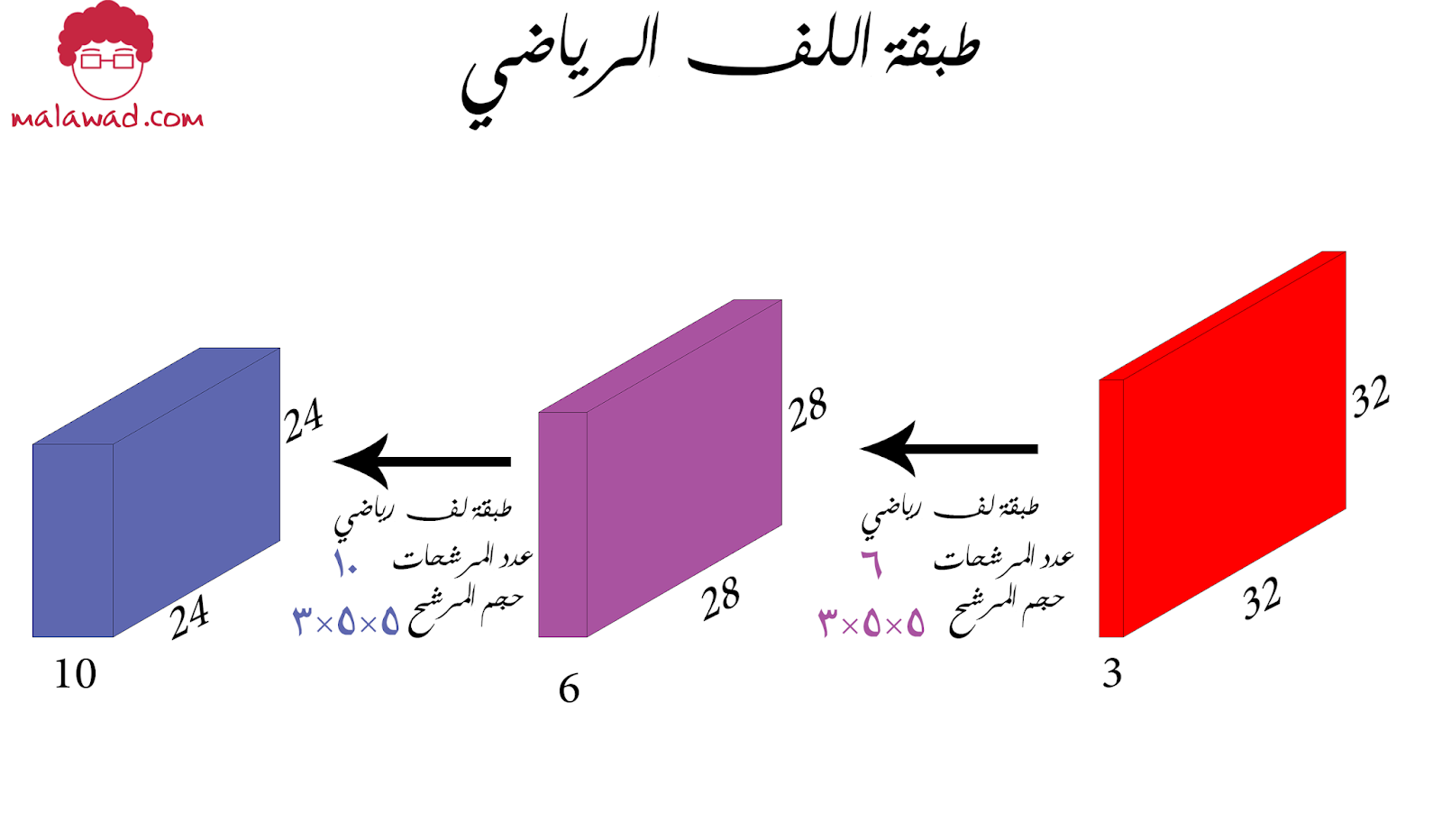
و هذه الخريطة هي عبارة عن تكدس ستة مرشحات مختلفة و لذلك الحجم النهائية للصورة الناتجة من طبقة اللف الرياضي هي 28×28×6 و الصورة الناتجة نقوم بإدخالها في طبقة لف رياضي أخرى لكن بمرشحات ذات قيم مختلفة و كميات مختلفة. بشكل عام شبكات اللف الرياضي هي عبارة عن تتابع لطبقات اللف الرياضي .
في شبكات اللف الرياضي العصبية تقوم الشبكة بتعلم قيم هذه المرشحات من تلقاء نفسها و لذلك عند محاولة تصور قيم هذه الشبكات سنحصل على الأتي :

سنلاحظ بأن المرشحات في طبقات اللف الرياضي في المستوى الأدنى ستقوم بمحاولة إكتشاف الحواف و الزواية و المناطق ذات لون معين أو نسيج معين ، و في المستوى المتوسط ستقوم طبقة اللف الرياضي بمحاولة توصيل الحواف أو الأنسجة مع بعضها البعض وتطبيقها على الصورة المدخلة لنحصل على تفغيل ما . أم في المستوى العالي فستقوم طبقة اللف الرياضي بتركيب الأشكال الناتجة من الطبقة السابقة لتكون جسم ما و من هذا الجسم يتم تصنيف الصورة المدخلة.
فلننظر للمثال التالي و الذي يحتوي صورة جزء من السيارة كمدخل ، ولدينا 32 مرشح و منها سنتصور خريطة التفعيل بحيث الأبيض يمثل إستجابة عالية بينما الأسود يمثل إستجابة منخفضة للمرشح

و شبكات اللف الرياضي يكون لديها معماريات كهذه :
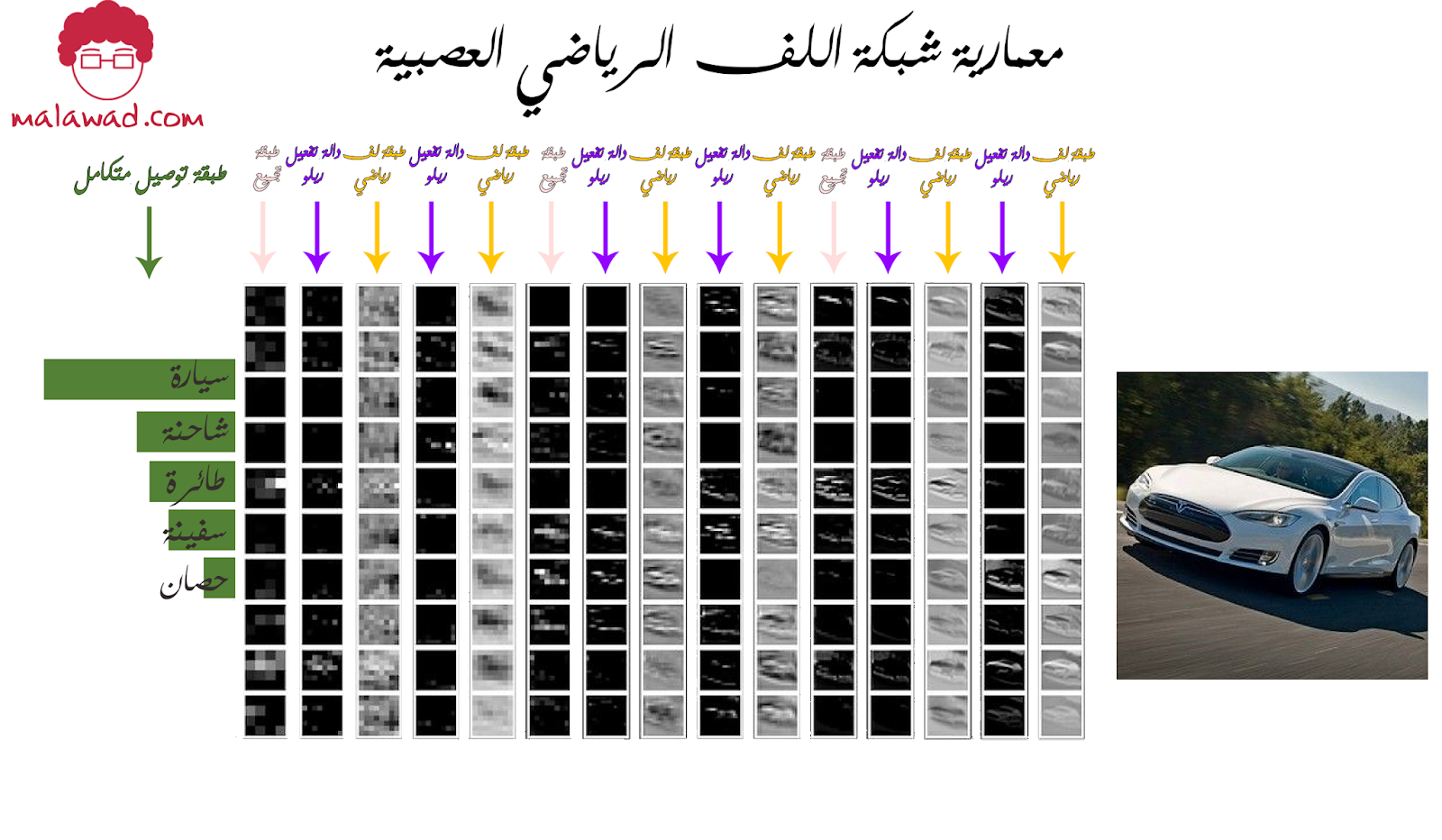
و تتالف هذه المعمارية من طبقة اللف الرياضي و التي تحتوي على عشرة مرشحات يتم إدخال هذه المرشحات على دالة التفعيل و التي تعتبر عتبة (threshold) لقيم الطبقة و من ثم يتم إدخال هذا الناتج إلى طبقة لف رياضي أخرى و بعد مرور ناتج تلك الطبقة بدالة التفعيل يتم إدخالها على طبقة تجميع . و في النهاية يتم إدخال النواتج على طبقة كاملة الإتصال (fully connected layer) و هناك يتم التصنيف الصورة المدخلة .
طريقة عمل المرشحات في شبكات اللف الرياضي :
رأينا سابقا أننا إذا طبقنا مرشح حجمه 5×5×3 على صورة حجمها 32×32×3 سنحصل على خريطة تفعيل حجمها 28×28×1 ، سنأخذ الأن نظرة أعمق على أبعاد خريطة التفعيل .
فلنفترض بأن لدينا مُدخل أبعاده 7×7 و كذلك مرشح أبعاده 3×3

يمكننا تحريك المرشح أفقيا خمسة حركات و عاموديا خمسة حركات لتغطية كامل الصورة و بالتالي سيكون الناتج 5×5. لاحظ أيضا أننا قمنا بتحريك المرشح خطوة (stride) واحدة للأمام لكن ماذا لو قمنا بتحريك المرشح خطوتين
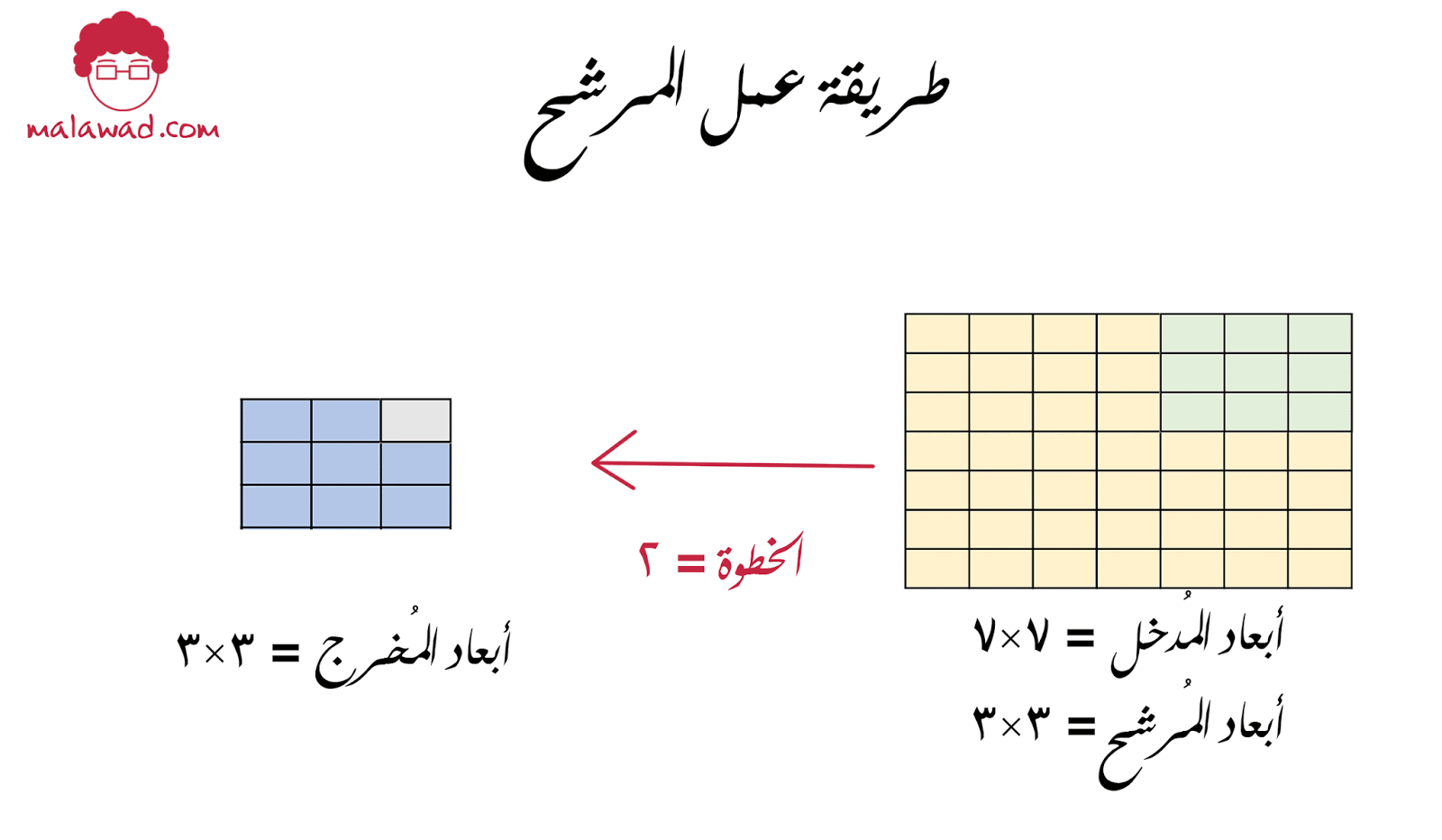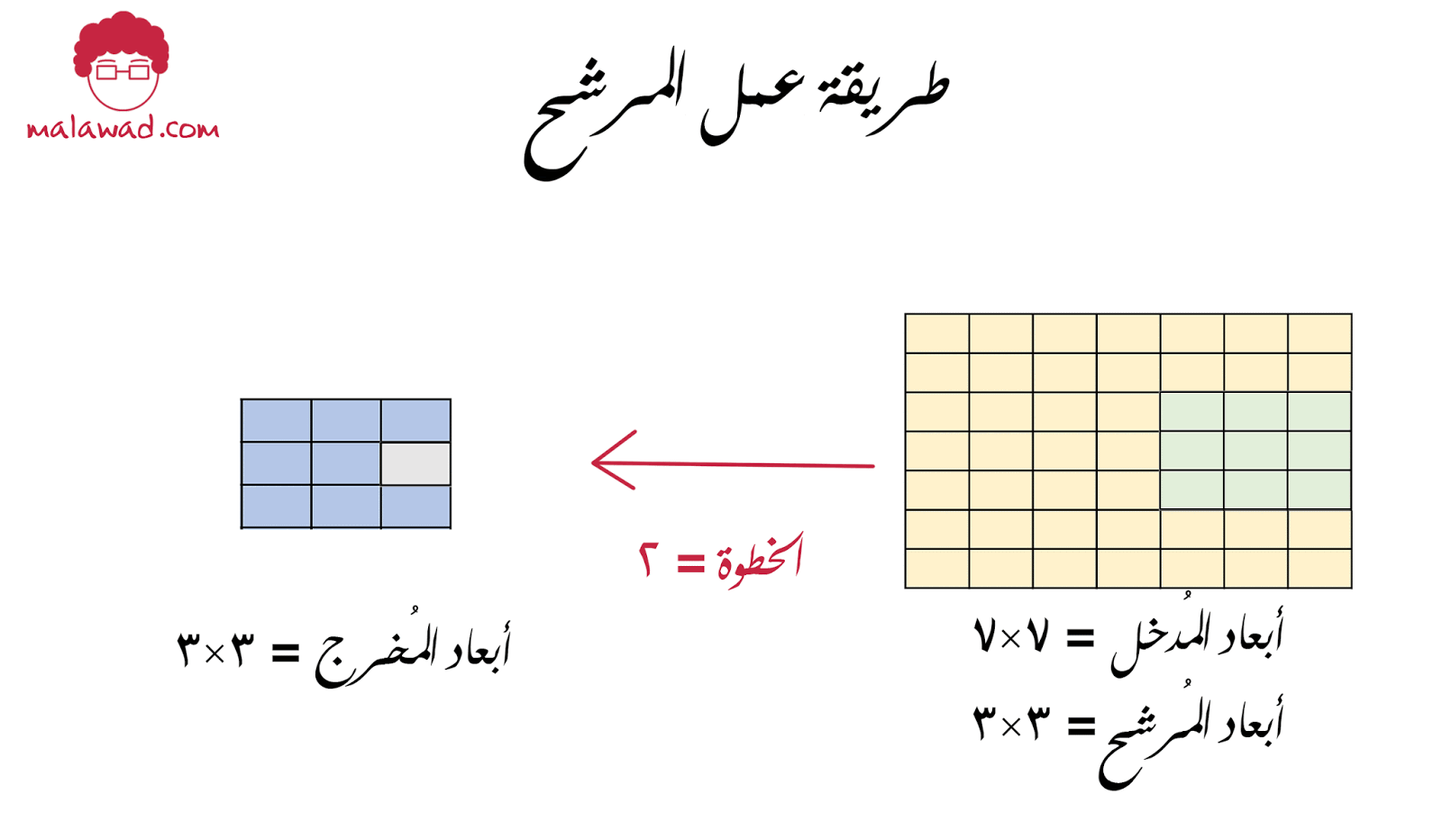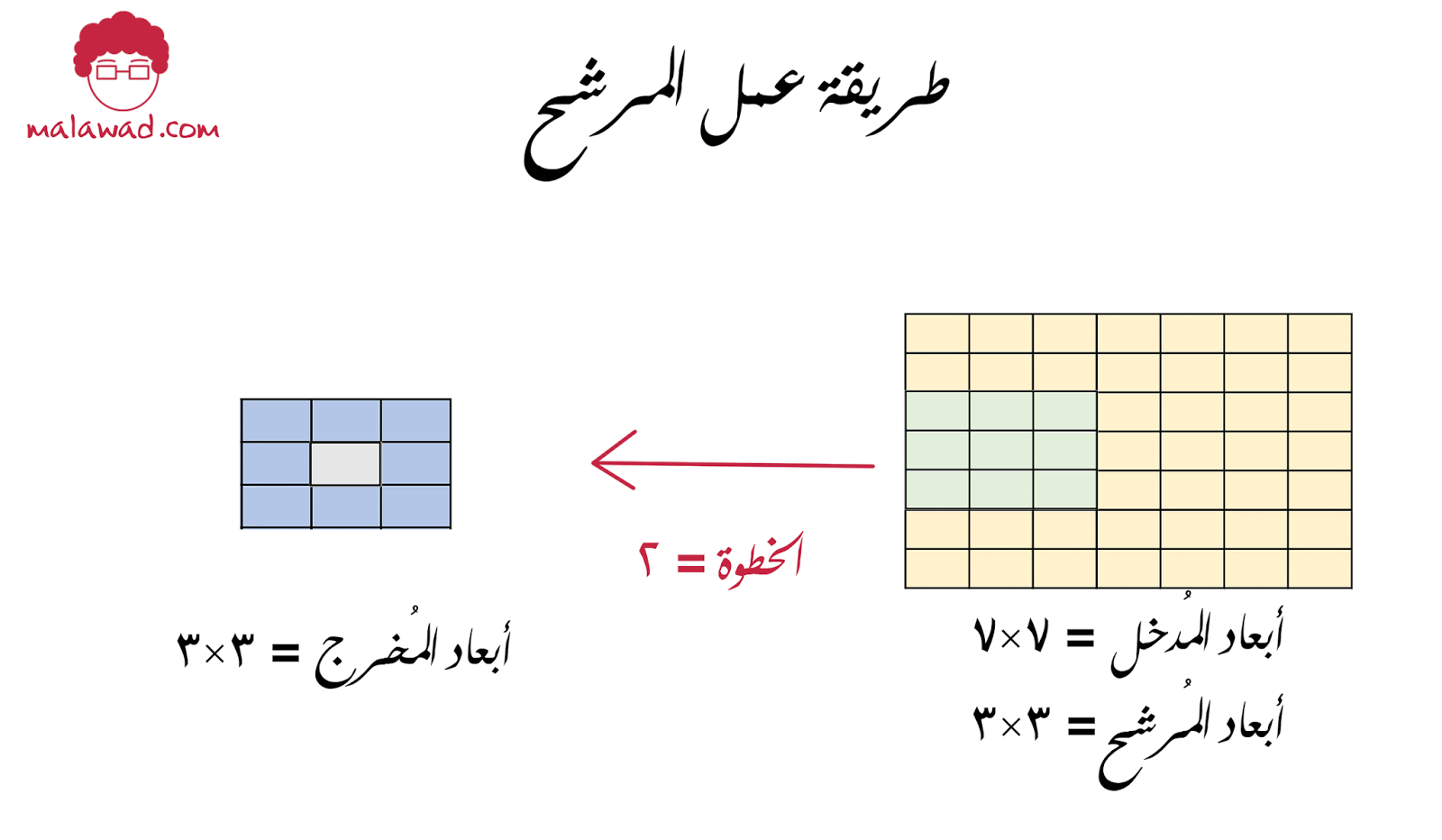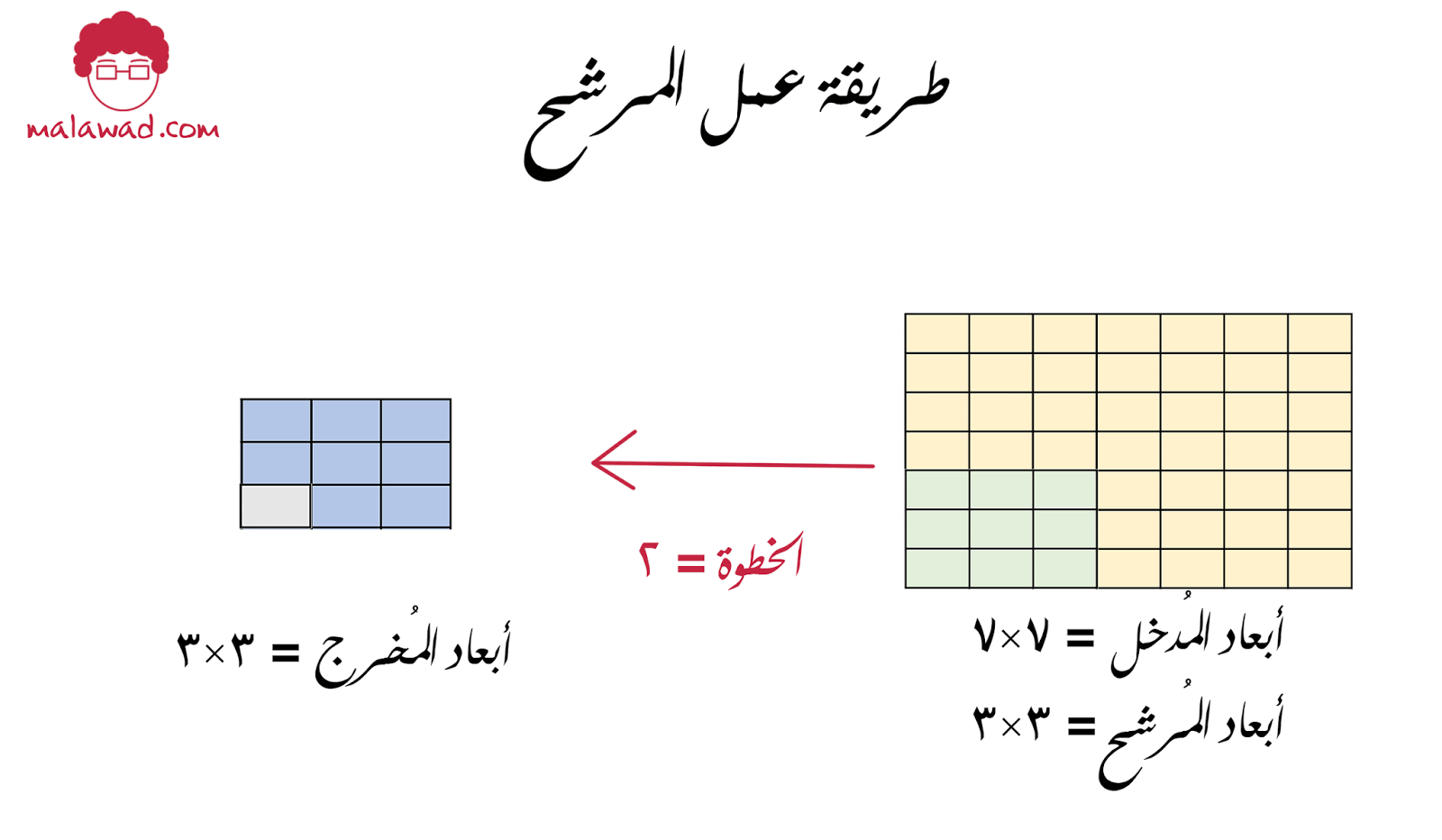
و في هذه الحالة سيتحرك المرشح ثلاثة تحركات لتغطية الصورة و الناتج سيكون 3×3 ، و يمكننا حساب الأبعاد الناتجة للصورة من خلال هذه المعادلة البسيطة
الحجم المخرج :
((حجم الصورة – حجم نافذة الترشيح) / الخطوة ) +1
فبالتالي لو فرضنا أن حجم الصورة 7×7 ، و حجم نافذة الترشيح 3×3
| الخطوة = 1 | ((7-3)/1) + 1 = 5 |
| الخطوة = 2 | ((7-3)/2) + 1 = 3 |
من التطبيقات الشائعة أيضا هي حشو (padding) الصورة المدخلة ، وذلك نقوم بوضع إطار أسود على حواف الصورة وهذا يساعدنا في الحفاظ على أبعاد الصورة الأصلية عند إجراء عملية اللف الرياضي
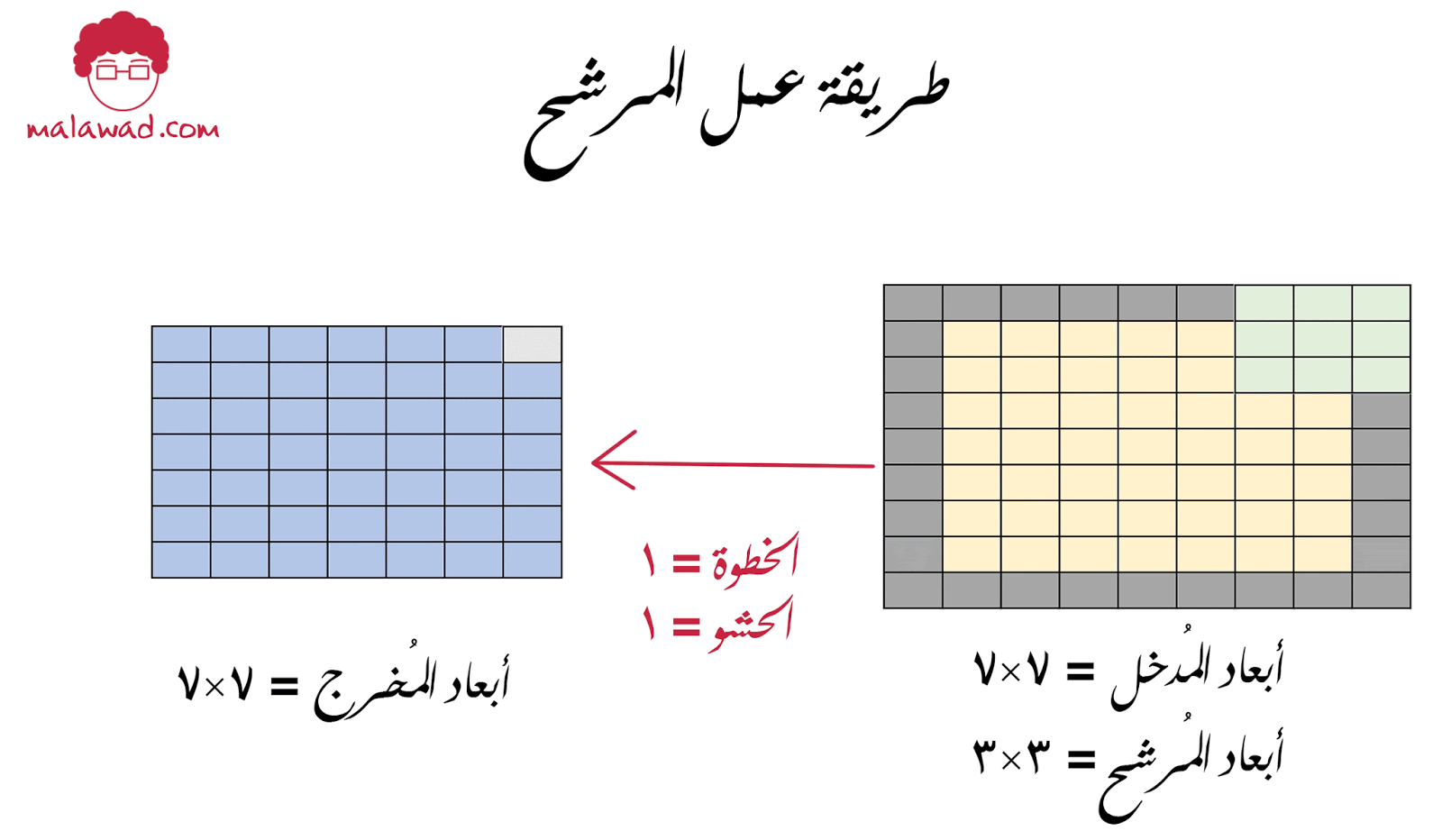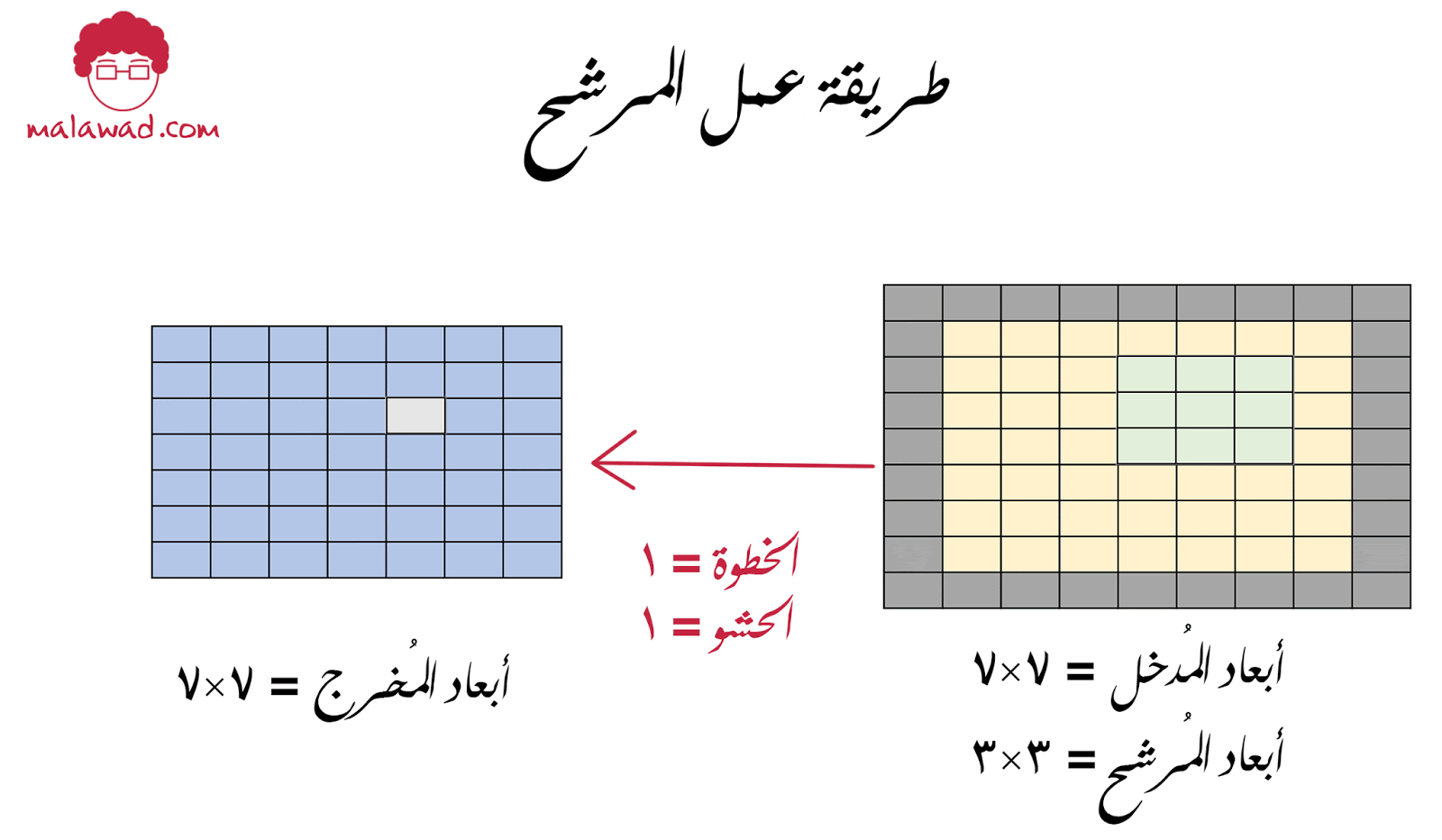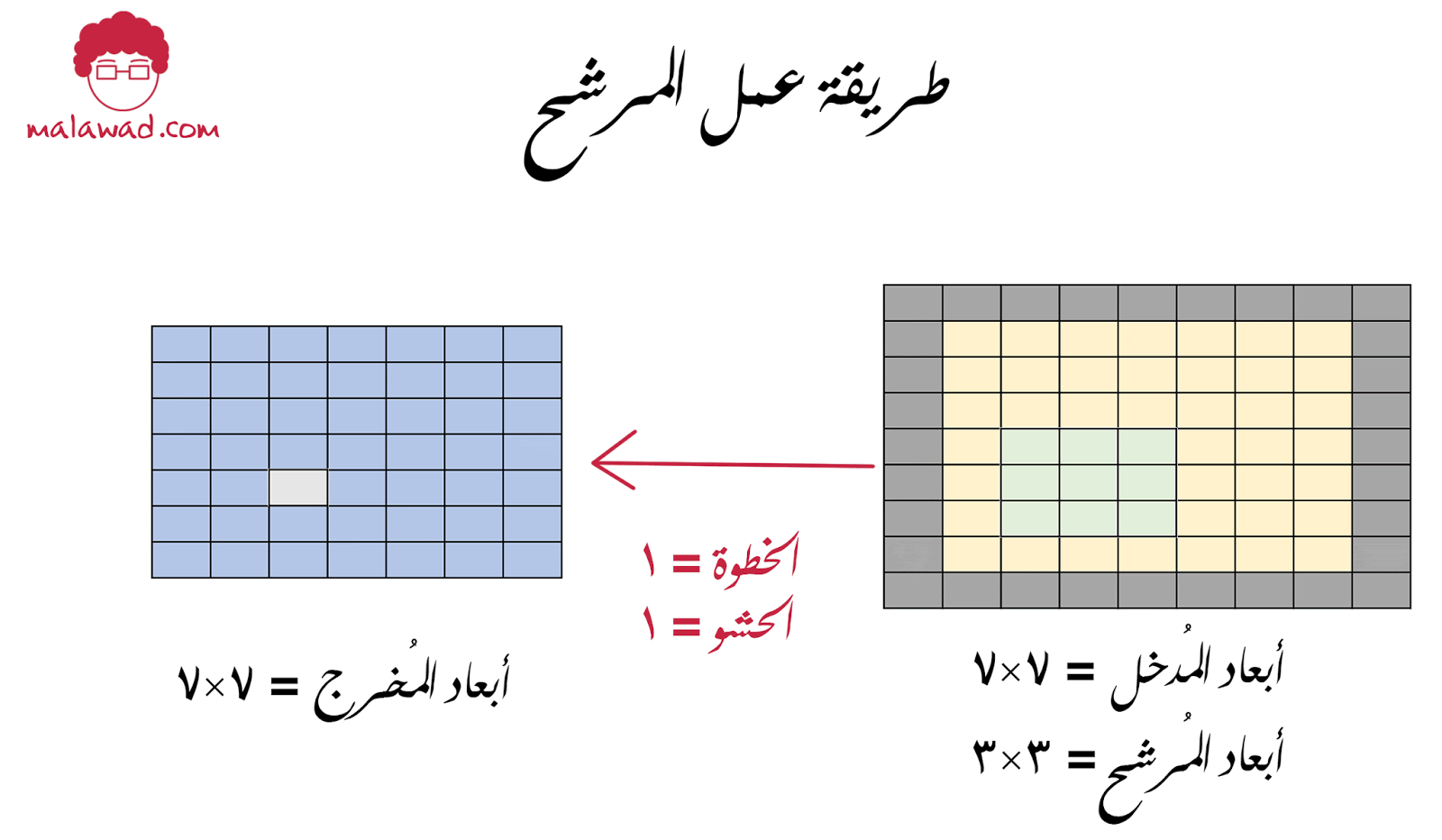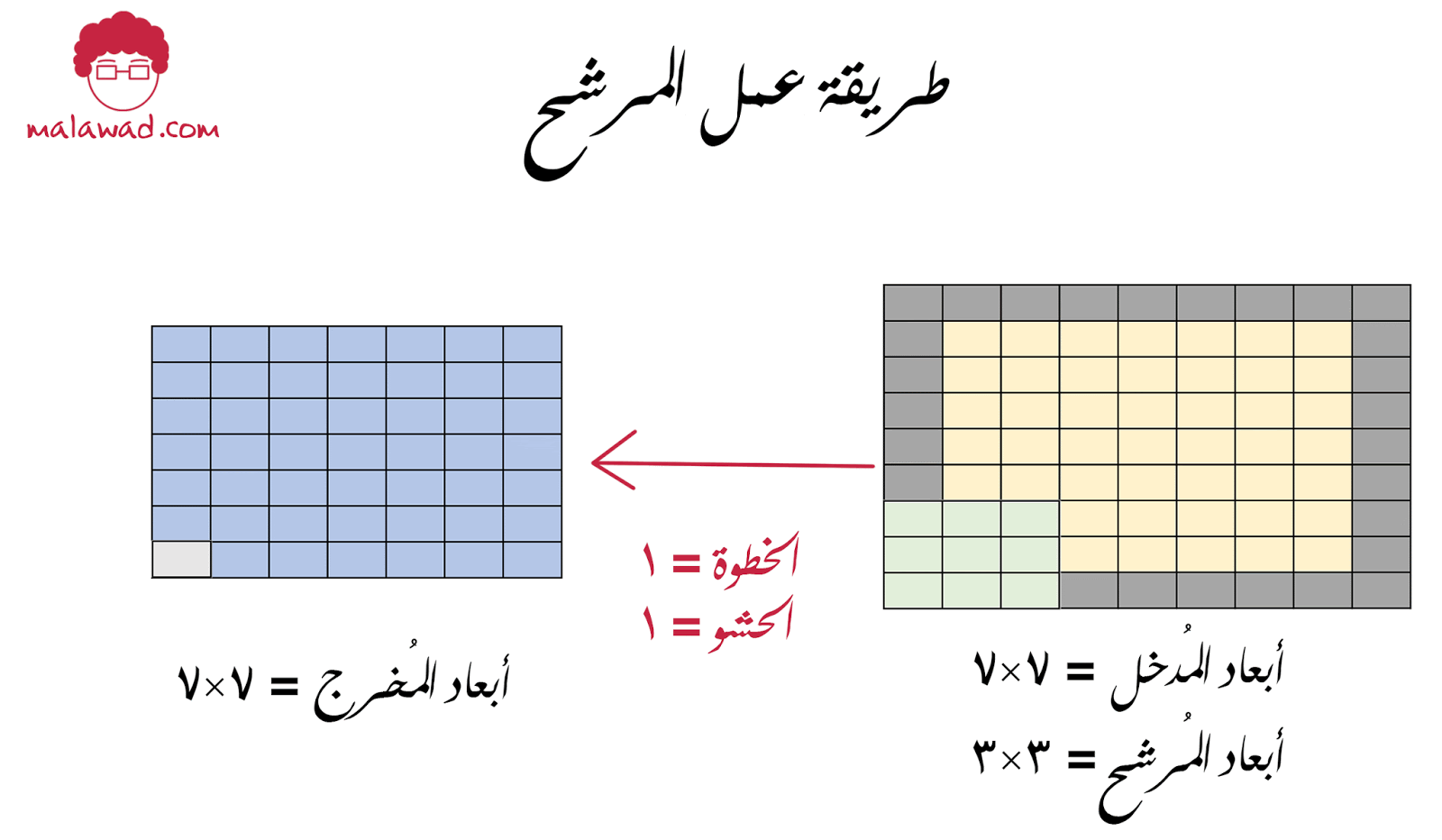
و حجم الحشو يتناسب مع أبعاد المرشح حسب المعادلة التالية ( حجم نافذة الترشيح -1)/2
| حجم نافذة الترشيح = 3 | (3-1)/2=1 | الحشو = 1 |
| حجم نافذة الترشيح = 5 | (5-1)/2=2 | الحشو = 2 |
| حجم نافذة الترشيح = 7 | (7-1)/2=3 | الحشو = 3 |
و لمعرفة أهمية الحشو فللنظر إلى التمثيل التالي للطبقات اللف الرياضي ، سنلاحظ أن عند إستخدام مرشح حجمه 5×5 فكلما تقدمنا في الطبقات كلما قل حجم الطبقات ، و بما أن شبكات اللف الرياضي تحتوي على العديد من هذه الطبقات فهذا سيودي إلى تقليل حجم الطبقات بشكل سريع ، و هذا الأمر لا ينصح به و لذلك نستخدم الحشو لنحافظ على نفس الحجم في جميع الطبقات .

مثال بسيط :
حجم الصورة المدخلة : 32×32×3
و لدينا 10 مرشحات حجمها 5×5 و خطوة مقداراها 1 و حشو مقادره 2
حجم الصورة الناتجة : ((32+2*2-5)/1) +1 =32 وبالتالي الحجم 32×32×10
مقدار المعايير :
الأوزان لكل مُرشح = 5*5*3 =75
الإنحيازات لكل مُرشح = 1
إجمالي عدد المعايير = 76*10 = 760
تتميز طبقات اللف الرياضي بأمرين :
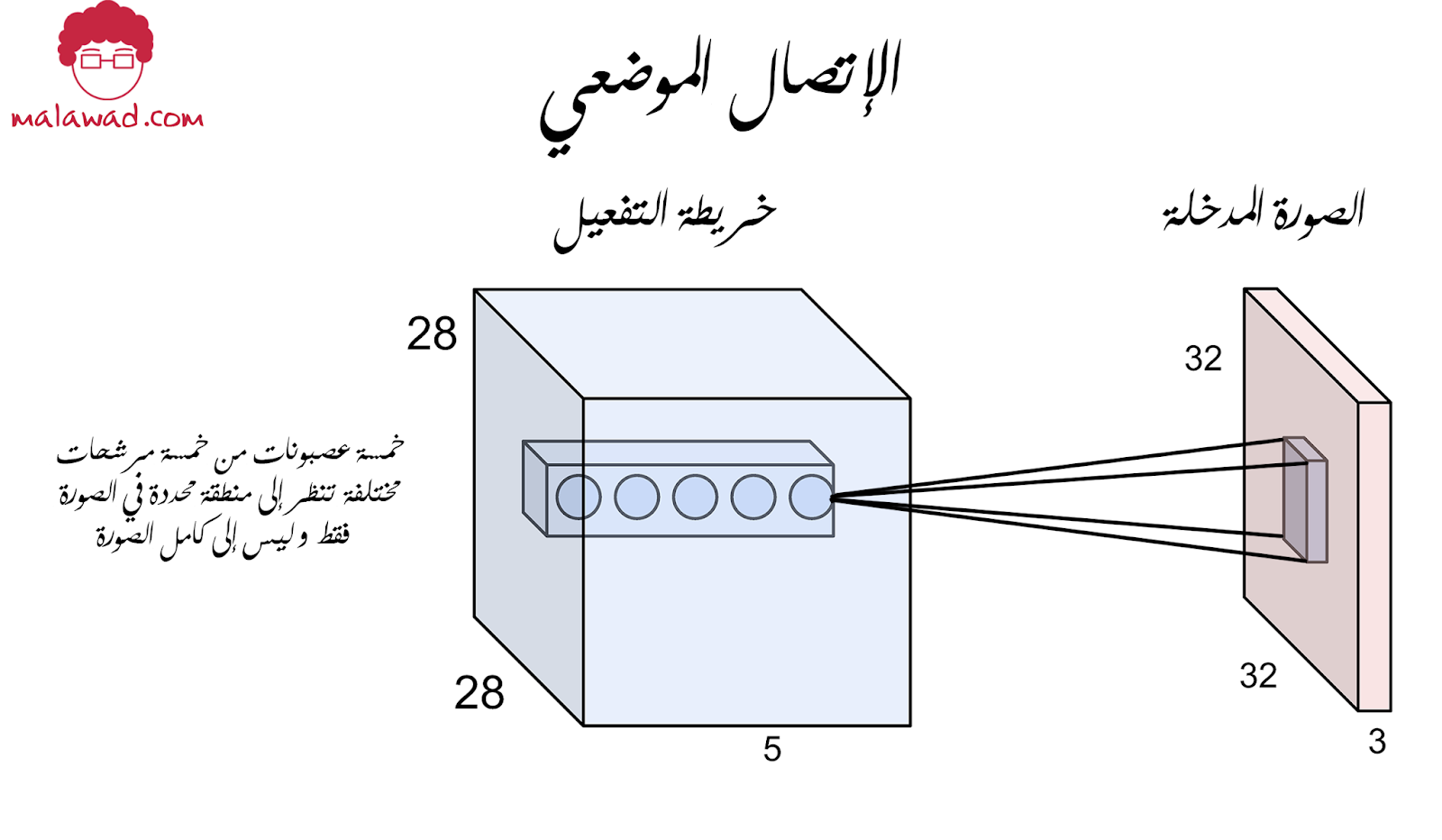
الإتصال الموضعي (Local Connectivity) : عندما نتعامل مع مدخلات ذات أبعاد كبيرة مثل الصور ، فمن غير العملي أن تتصل كل العصبونات في الطبقة الحالية بالعصبونات في الطبقة السابقة ، عوضاً عن ذلك نقوم بوصل كل عصبونه بمنطقة صغيرة محددة من المُدخل (input) ، و حجم هذه المنطقة يحددها حجم المُرشح المستخدم.
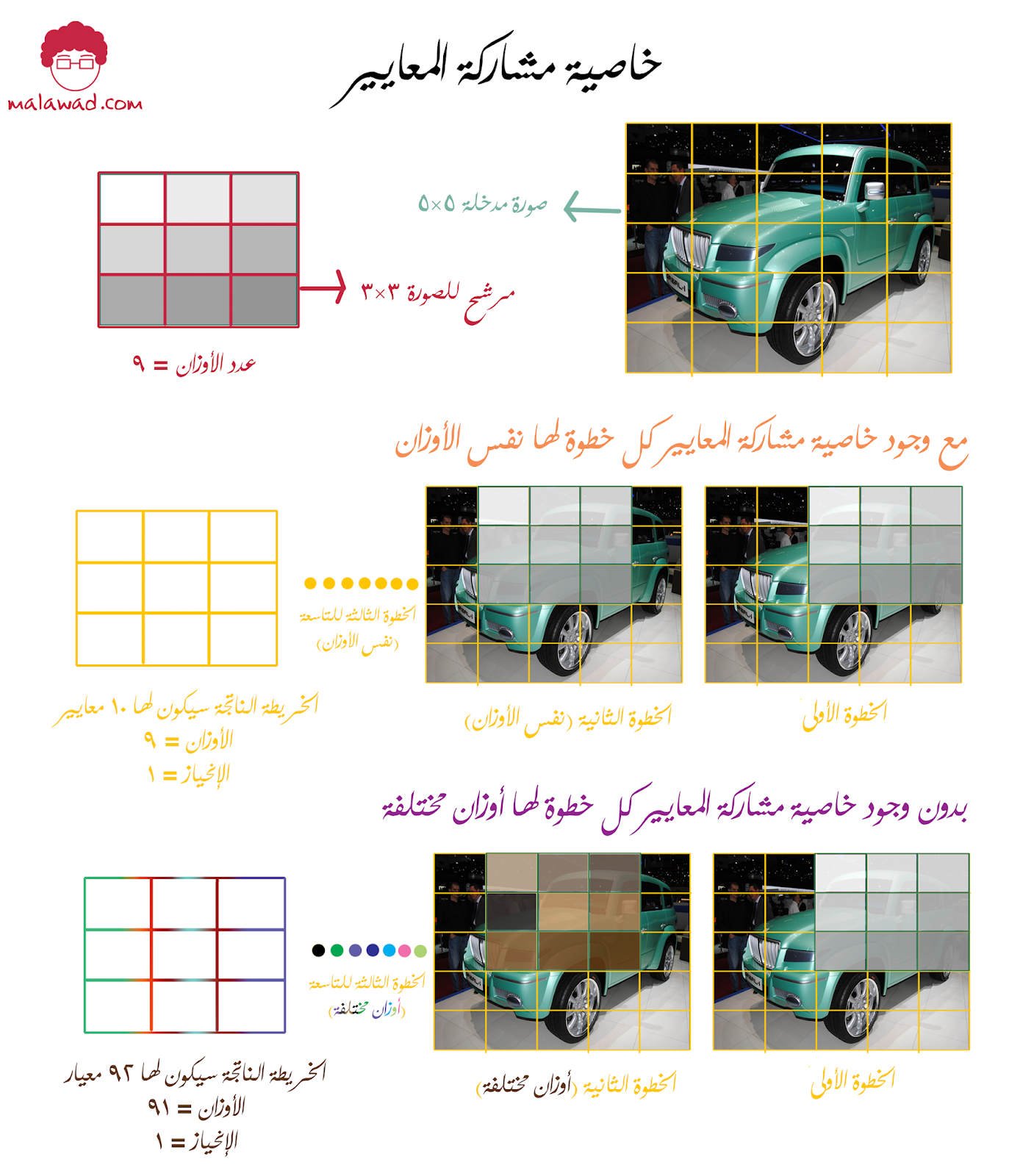
مشاركة المعايير (Parameter Sharing) : في طبقات اللف الرياضي العصبية نحن نفترض بأنه إذا كان هنالك سمة معينة قد يفيدنا حسابها في أي موضع مكاني في الصورة (y1,x1) فحتماً سيفيدنا حسابها في موضع أخر في الصورة (y2,x2).
كمثال لو أدخلنا صورة أبعادها (227×227×3) طبقة لف رياضي و إستخدمنا مرشح أبعاده (11×11×3) و خطوة حجمها (4) و بدون أي حشو . سنحصل على خريطة سمات حجمها (227-11)/4 + 1 = 55 و بالإضافة إلى ذلك سنستخدم 96 مرشح .
عند وجود خاصية مشاركة المعايير فستقوم الشبكة بتقييد العصبونات في المرشح بإستخدم نفس الوزن ، و بالتالي فلن تتأثر طبقة اللف الرياضي بتاتاً بحجم الصورة المدخلة .
- لو كان لدينا خريطة سمات حجمها (55×55×3) و إستخدمنا 96 مرشح ، حجم كل مرشح (11×11×3) فعدد المعايير سيكون (96*11*11*3) = 34,966 إضافة إلى عدد الإنحيازات و هي 96 .
أما عند إلغاء خاصية مشاركة المعايير فسيزيد عدد المعايير بشكل مأهول إعتماداً على حجم الصورة المدخلة . كمثال :
- لو كان لدينا خريطة سمات حجمها (55×55×3) و إستخدمنا 96 مرشح ، حجم كل مرشح (11×11×3) فعدد المعايير سيكون (55*55*96*11*11*3) = 105,705,600 إضافة إلى عدد الإنحيازات و هذا الرقم كبير جدا.
لتلخيص طبقات اللف الرياضي :
- حجم الصورة المدخلة هو W1 العرض × H1 الطول × D1 العمق
- تحتاج أربعة معايير :
- عدد المرشحات K
- أبعاد نافذة الترشيح F
- عدد الخطوات S
- مقدار الحشو P
- تنتج صورة أبعادها W2 العرض × H2
الطول × D2 العمق بحيث :
- W2 = (w1-F+2P)/S+1
- H2 = (H1-F+2P)/S+1
- D2=k
- و الأوزان الناتجة من الشبكة تعطى بالمعادلة F*F*D وزن لكل مرشح ، و المجموع الكامل هو (F*F*D)*K وزن بالإضافة إلى K إنحيازات
دالة التفعيل :
في شبكة اللف الرياضي العصبية نستخدم دالة التفعيل ريلو (ReLU) و التي تعني الوحدة الخطية المصححة (rectified linear unit) . في هذه الدالة أي قيمة سالبة يتم تصفيرها و أي قيمة موجبة لديها قيمة طردية خطية .
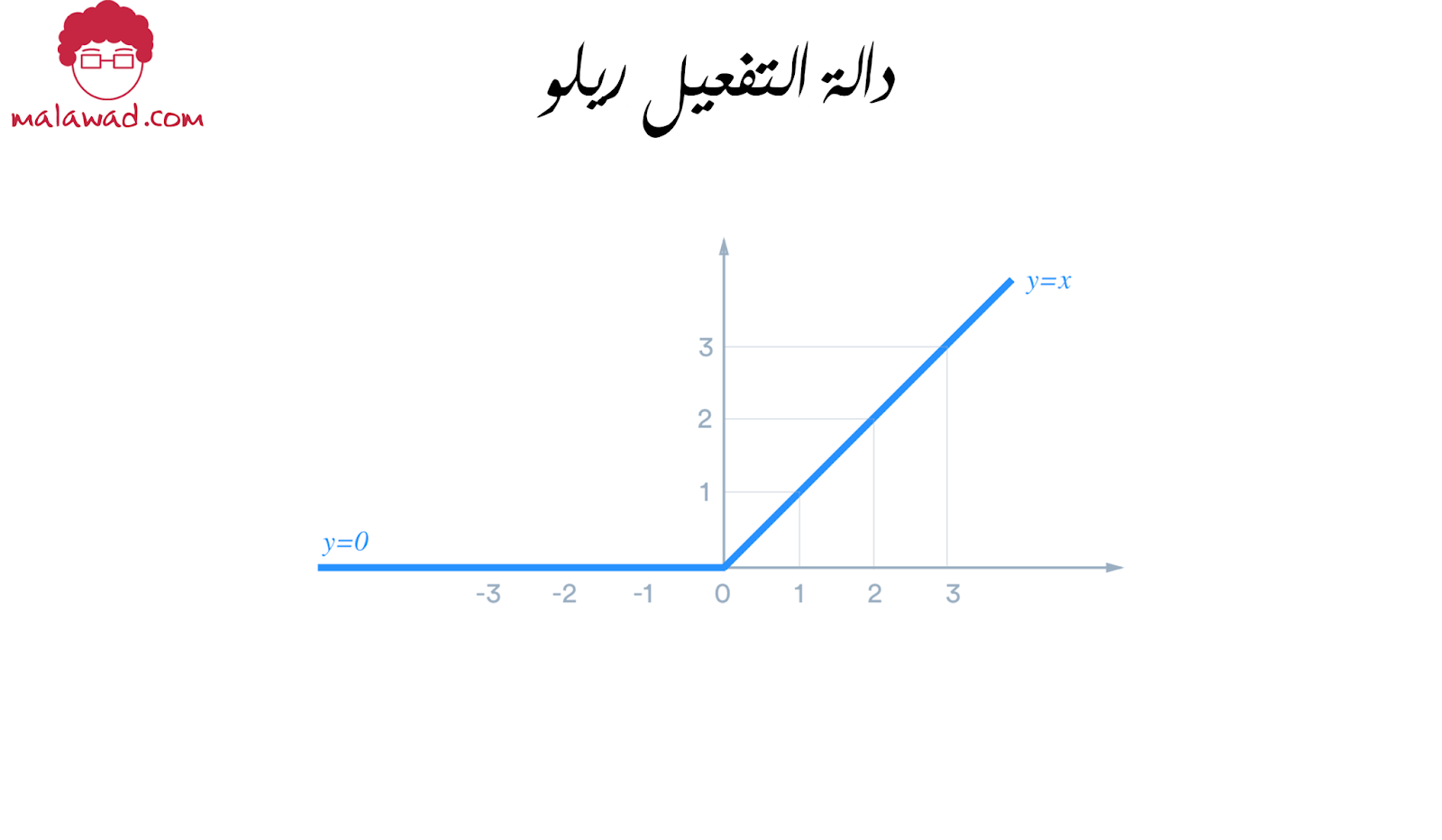
و تتميز دالة ريلو بعدة أمور:
- رخص حسابها ، حيث لا تحتوي أي عمليات رياضية معقدة و بالتالي ستأخذ الشبكة وقت أقل للتدرب
- خطية الدالة ، تعني أن الميل (slope) لن يصل لحالة الخمول أن التشبع لو كانت قيمة الـX كبيرة جداً مما يعني أننا سنحصل على الحل بشكل أسرع.
- متناثرة التفعيل ، بما أن أي قيمة سالبة للعصبونه تساوي صفر بالتالي لن يتم تفعيلها و هذا أمر مرغوب به.
لفهم أهمية التقطة الأخيرة من المهم أن ننظر إلى الشبكات العصبية في الكائنات الحالية . في أجسامنا يوجد مليارات العصبونات و لا تتنشط جميعها عند قيامنا بكل شيئ ، عوضا عن ذلك كل عصبونه لها دور معين يتم تنشيطها بإشارات مختلفة.
في الشبكات العصبية التناثر يعطينا قدرة أفضل على التنبو و ذلك لأن العصبونه غالبا تقوم بمعالجة معلومات مفيدة . كمثال لو كانت شبكتنا تقوم بمحاولة إكشاف وجه في صورة فقد يكون هناك عصبونات تحاول إكتشاف أذن و هذه العصبونه من البديهي أن لا تتفعل إذا ما كانت الصورة صورة مبنى.
طبقات التجميع
في العادة في طبقات اللف الرياضي نقوم بالمحافظة على حجم الطبقة ، و وظيقة طبقات التجميع هي تصغير حجم الطبقات . مما يقلل القوة الحسابية المطلوبة لمعالجة البيانات .
هناك نوعان طبقات التجميع ، التجميع المتوسط و التجميع الأقصى
- التجميع القيمة الأقصى : يهتم بالقيمة الأعلى في جزيئة الصورة التي تمر النافذة عليها
- التجميع المتوسط : يهتم بالقيمة المتوسطة لجميع القيم التي تمر النافذة عليه

طبقات التجميع :
- تستقبل طبقة حجمها w1×H1×D1
- تحتاج إلى معييارين :
- حجم النافذة F
- الخطوة S
- تنتج لنا طبقة حجمها w2×H2×D2
- W2 = (w1-F)/S+1
- H2 = (H1-F)/S+1
- D2=D1
عادة نستخدم نافذة حجمها F=2
وقيمة الخطوة S=2
الطبقة كاملة الإتصال
سميت بذلك لأن كل عصبونة في الطبقة متصلة بكل التفعيلات في الطبقة السابقة تماماً كما تعمل شبكة العصبية التقليدية ، فبعد إستخدام طبقات اللف الرياضي و إستخراج خرائط السمات للصورة ، نقوم بتسطيح أو بسط هذه الخرائط (flatten) و إدخالها على طابقة كاملة الإتصال (Fully connected layer) وذلك تجهيزاً لعملية التصنيف . كمثال لو كان لدينا خريطة سمات أبعادها 4×4×512 سنقوم ببسطها في مصفوفة أبعادها 8192×1 ، و في العادة هناك ثلاثة طبقات كاملة الإتصال قبل أن نقوم بتأدية عملية التصنيف النهائية.
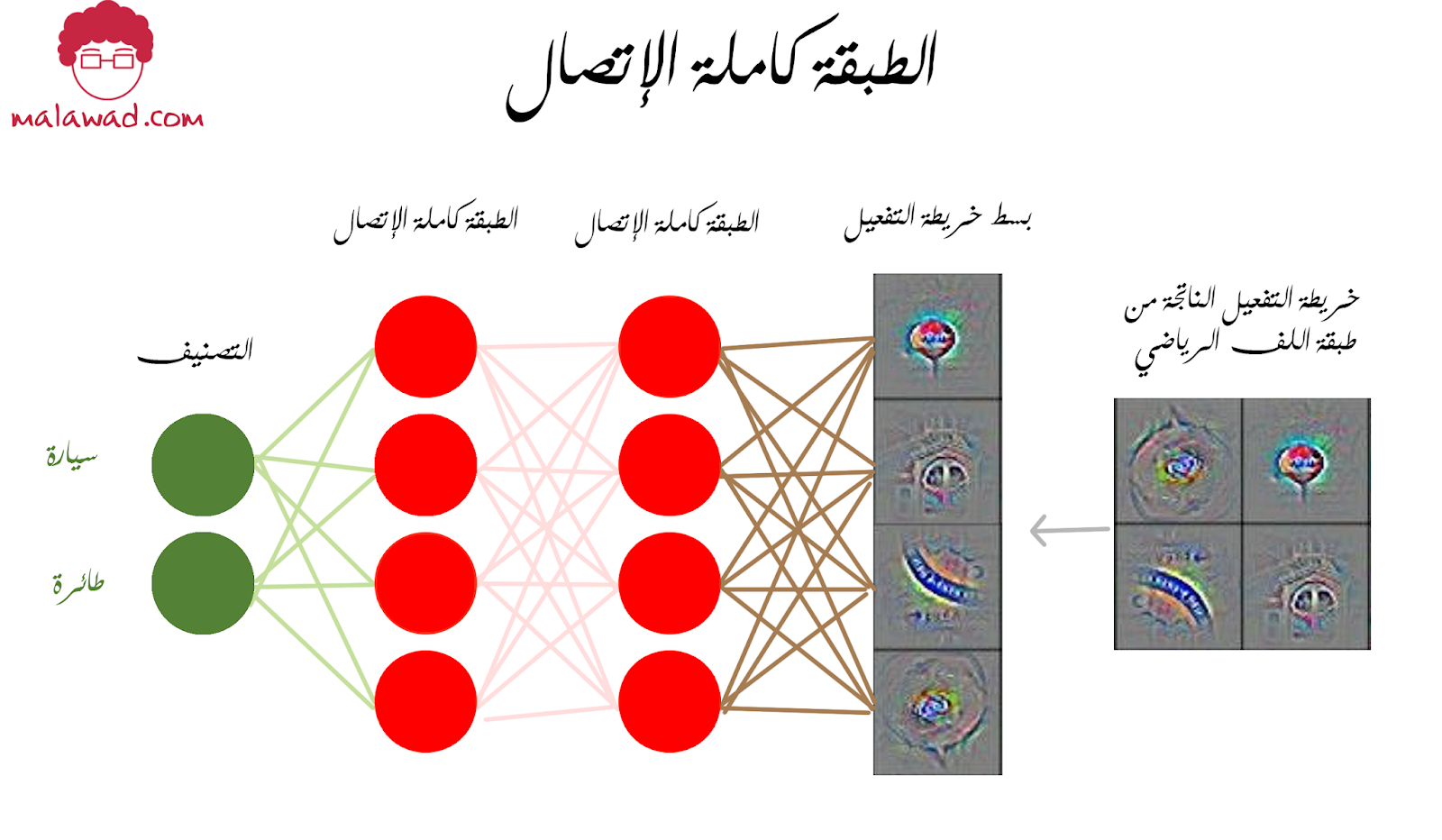
و هذه المصفوفة ستحتوي على جميع السمات التي تعملتها طبقات اللف الرياضي و بعد إدخالها على الطبقة كاملة الإتصال ستحاول الطبقة ربط السمات بالتصانيف المتوفرة لديها و في النهاية الخروج بتصنيف نهائي للصورة المدخلة.
الجدير بالذكر أن الإختلاف الوحيد بين هذه الطبقة و الطبقة اللف الرياضي هو أن العصبونات في طبقة اللف الرياضي لديها إتصال محلي فقط بالمُدخل . و هذا قد يثير تسأول ماذا لو كان لدينا قدرة حسابية غير محدودة فهل يمكن أن نستخدم شبكة عصبية مؤلفة فقط من طبقات كاملة الإتصال لتصنيف الصور؟
و بهذا نكون قد وصلنا إلى ختام المقالة و في جزئية البرمجة سنقوم بإستخدام بايتورش لبرمجة شبكة لف رياضي عصبية على حزمة بيانات FashionMNIST و هي حزمة تتألف من عشرة أنواع مختلفة من الملابس وستقوم شبكتنا العصبية بالتعرف على هذه الأنواع المختلفة.
رابط الدفتر على غوغل كولاب













إضافة تعليق