
التضمينات عبارة عن تمثيل بيانات قابل للتعلم يقوم بتعيين البيانات عالية الأبعاد في فضاء أقل بعدًا بطريقة تحفظ المعلومات ذات الصلة بمشكلة التعلم. تستخدم التضمينات في صميم أنظمة تعلم الألة في العصر الحديث ولها تجسيدات مختلفة في جميع أنحاء المجال.
المشكلة
تبحث نماذج تعلم الألة بشكل منهجي عن الأنماط في البيانات التي تلتقط كيفية ارتباط خصائص سمات إدخال النموذج بتسمية الإخراج.
نتيجة لذلك ، يؤثر تمثيل البيانات لسمات الإدخال بشكل مباشر على جودة النموذج النهائي. في حين أن التعامل مع المدخلات العددية المنظمة يعتبر بسيط إلى حد ما ، يمكن أن تأتي البيانات اللازمة لتدريب نموذج تعلم الألة في أنواع لا تعد ولا تحصى ، مثل السمات الفئوية والنصوص والصور والصوت والسلاسل الزمنية وغير ذلك الكثير.
بالنسبة إلى تمثيلات البيانات هذه ، نحتاج إلى قيمة عددية ذات مغزى لتوفيرها لنموذج تعلم الألة الخاص بنا بحيث يمكن أن تتناسب هذه السمات مع نموذج التدريب النموذجي.
توفر عمليات التضمين طريقة للتعامل مع بعض أنواع البيانات المتباينة هذه بطريقة تحافظ على التشابه بين العناصر وبالتالي تُحسِّن من قدرة نموذجنا على تعلم تلك الأنماط الأساسية.
يعد خط الترميز الأحادي (One-hot encoding) طريقة شائعة لتمثيل متغيرات الإدخال الفئوية.
على سبيل المثال ، ضع في اعتبارك إدخال التعددية في مجموعة بيانات الولادة. هذا إدخال فئوي يحتوي على ست قيم محتملة:
[‘Single (1)’ ، ‘Multiple (2+)’ ، ‘Twins (2)’ ، ‘Triplets ( 3) ‘،’ Quadruplets(4) ‘،’ Quintuplets (5) ‘].يمكننا التعامل مع هذا المدخلات الفئوية باستخدام خط الترميز الأحادي بحيث يقوم بتعيين كل قيمة كسلسلة إدخال محتملة إلى متجه وحدة في R^6 ، كما هو موضح في الجدول .
| التعددية | خط الترميز الأحادي |
| مفرد (1) | [1،0،0،0،0،0] |
| متعددة (2+) | [0،1،0،0،0،0] |
| التوائم (2) | [0،0،1،0،0،0] |
| ثلاثة توائم (3) | [0،0،0،1،0،0] |
| أربعة توائم (4) | [0،0،0،0،1،0] |
| خمسة توائم (5) | [0،0،0،0،0،1] |
عند الترميز بهذه الطريقة ، نحتاج إلى ستة أبعاد لتمثيل كل فئة من الفئات المختلفة. قد لا تكون الأبعاد الستة سيئة للغاية ، ولكن ماذا لو كان لدينا العديد من الفئات الأخرى التي يجب وضعها في الاعتبار؟
على سبيل المثال ، ماذا لو كانت مجموعة البيانات الخاصة بنا تتكون من سجل مشاهدة العملاء لقاعدة بيانات الفيديو الخاصة بنا ومهمتنا هي اقتراح قائمة بمقاطع الفيديو الجديدة في ضوء تفاعلات العملاء السابقة مع الفيديو؟
في هذا السيناريو ، قد يحتوي الحقل customer_id على ملايين الإدخالات الفريدة. وبالمثل ، يمكن أن يحتوي video_id الخاص بمقاطع الفيديو التي تمت مشاهدتها مسبقًا على آلاف الإدخالات أيضًا.
تؤدي السمات الفئوية ذات العناصر المرتفعة للغاية مثل video_ids أو customer_ids كمدخلات لنموذج تعلم الألة إلى مصفوفة متناثرة (sparse) غير مناسبة تمامًا لعدد من خوارزميات تعلم الألة.
المشكلة الثانية في خط الترميز الأحادي هو أنه يتعامل مع المتغيرات الفئوية على أنها مستقلة. ومع ذلك ، يجب أن يكون تمثيل البيانات للتوائم قريبًا من تمثيل البيانات لثلاثة توائم وبعيدًا جدًا عن تمثيل البيانات لخمس توائم. المتعدد هو على الأرجح توأم ، لكن يمكن أن يكون ثلاثيًا. كمثال ، يوضح الجدول أدناه تمثيلاً بديلاً لعمود التعددية في بُعد أقل يلتقط علاقة التقارب هذه.
| التعددية | ترميز مقترح |
| مفرد (1) | [1.0،0.0] |
| متعددة (2+) | [0.0،0.6] |
| التوائم (2) | [0.0،0.5] |
| ثلاثة توائم (3) | [0.0،0.7] |
| أربعة توائم (4) | [0.0،0.8] |
| خمسة توائم (5) | [0.0،0.9] |
هذه الأرقام عشوائية بالطبع. ولكن هل من الممكن معرفة أفضل تمثيل ممكن لعمود التعددية باستخدام بعدين فقط لمسألة الولادة؟ هذه هي المشكلة التي يحلها نمط تصميم التضمينات (Embeddings ) .
تحدث نفس المشكلة المتمثلة في ارتفاع عدد العناصر والبيانات التابعة في الصور والنصوص. تتكون الصور من آلاف النقاط الضوئية، وهي ليست مستقلة عن بعضها البعض. يتم استخلاص نص اللغة الطبيعية من مفردات في عشرات الآلاف من الكلمات ، وكلمة مثل المشي أقرب إلى كلمة جري منها إلى كلمة كتاب.
الحل
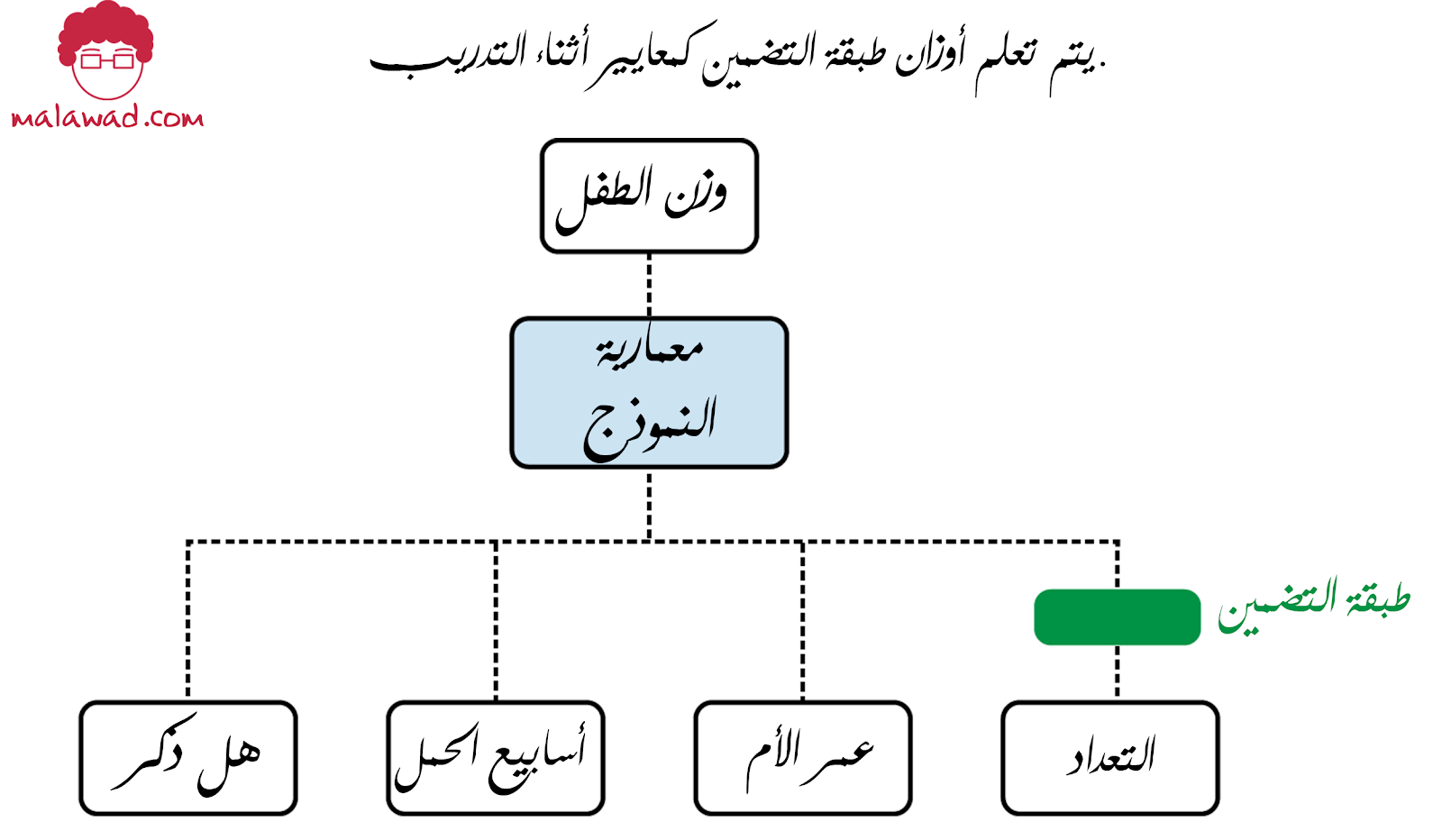
يعالج نمط تصميم التضمينات (Embeddings ) مشكلة تمثيل البيانات ذات عدد العناصر المرتفعة بواسطة تكثيفها في بُعد أقل عن طريق تمرير بيانات الإدخال عبر طبقة التضمين التي تحتوي على أوزان قابلة للتدريب.
سيؤدي هذا إلى تعيين متغير الإدخال الفئوي عالي الأبعاد إلى متجه ذي قيمة حقيقية في بعض الفضاء منخفض الأبعاد. يتم تعلم الأوزان لإنشاء التمثيل الكثيف كجزء من تحسين النموذج. في الممارسة العملية ، ينتهي الأمر بهذه التضمينات إلى التقاط علاقات التقارب في بيانات الإدخال.
معلومة
نظرًا لأن عمليات التضمين تلتقط علاقات التقارب في بيانات الإدخال في تمثيل منخفض الأبعاد ، يمكننا استخدام طبقة التضمين كبديل لتقنيات التجميع (على سبيل المثال ، تجزئة العملاء) وطرق تقليل الأبعاد مثل تحليل المكونات الرئيسية (PCA). يتم تحديد أوزان التضمين في حلقة تدريب النموذج الرئيسي ، وبالتالي توفير الحاجة إلى التجميع أو عمل PCA مسبقًا.
سيتم تعلم الأوزان في طبقة التضمين كجزء من إجراء الإشتقاق النزولي (gradient descen) عند تدريب نموذج الولادة.
في نهاية التدريب ، قد تصيح أوزان طبقة التضمين بحيث يكون ترميز المتغيرات الفئوية كما هو موضح في الجدول.
| التعددية | خط الترميز الأحادي | الترميز المتعلم |
| مفرد (1) | [1،0،0،0،0،0] | [0.4، 0.6] |
| متعددة (2+) | [0،1،0،0،0،0] | [0.1، 0.5] |
| التوائم (2) | [0،0،1،0،0،0] | [-0.1، 0.3] |
| ثلاثة توائم (3) | [0،0،0،1،0،0] | [-0.2، 0.5] |
| أربعة توائم (4) | [0،0،0،0،1،0] | [-0.4، 0.3] |
| خمسة توائم (5) | [0،0،0،0،0،1] | [-0.6، 0.5] |
يقوم التضمين بتعيين متجه خط الترميز الأحادي المتناثرة إلى متجه كثيف في R^2.
في TensorFlow ، نقوم أولاً بإنشاء عمود سمة فئوي للسمة ، ثم نلفه في عمود سمة التضمين. على سبيل المثال ، بالنسبة لسمة التعددية الخاصة بنا ، سيكون لدينا:
plurality = tf.feature_column.categorical_column_with_vocabulary_list(
'plurality', ['Single(1)', 'Multiple(2+)', 'Twins(2)',
'Triplets(3)', 'Quadruplets(4)', 'Quintuplets(5)'])
plurality_embed = tf.feature_column.embedding_column(plurality, dimension=2)
يتم استخدام عمود السمة الناتج (plurality_embed) كمدخل إلى العقد النهائية للشبكة العصبية بدلاً من عمود خط الترميز الأحادي (plurality).
تضمينات النص
يوفر النص بيئة طبيعية حيث يكون من المفيد استخدام طبقة التضمين. بالنظر إلى عدد المفردات الأساسية (غالبًا بترتيب عشرات الآلاف من الكلمات) ، فإن خط الترميز الأحادي لكل كلمة ليس عمليًا. سيؤدي ذلك إلى إنشاء مصفوفة كبيرة (عالية الأبعاد) ومتناثرة بشكل لا يصدق للتدريب.
أيضًا ، نرغب في استخدام كلمات متشابهة بحيث تكون الكلمات غير ذات الصلة في التضمينات بعيدة جدًا في فضاء التضمين. لذلك ، نستخدم تضمين كلمة كثيف لإنشاء متجهات من النص المدخل قبل تمريره إلى نموذجنا.
لتنفيذ تضمين نص في Keras ، نقوم أولاً بتعميل (tokenize ) كل كلمة في مفرداتنا ، كما هو موضح في الشكل. ثم نستخدم هذا التعميل و تعيينه إلى طبقة التضمين.
يُنشئ المُعمل جدول بحث يقوم بتعيين كل كلمة إلى فهرس.
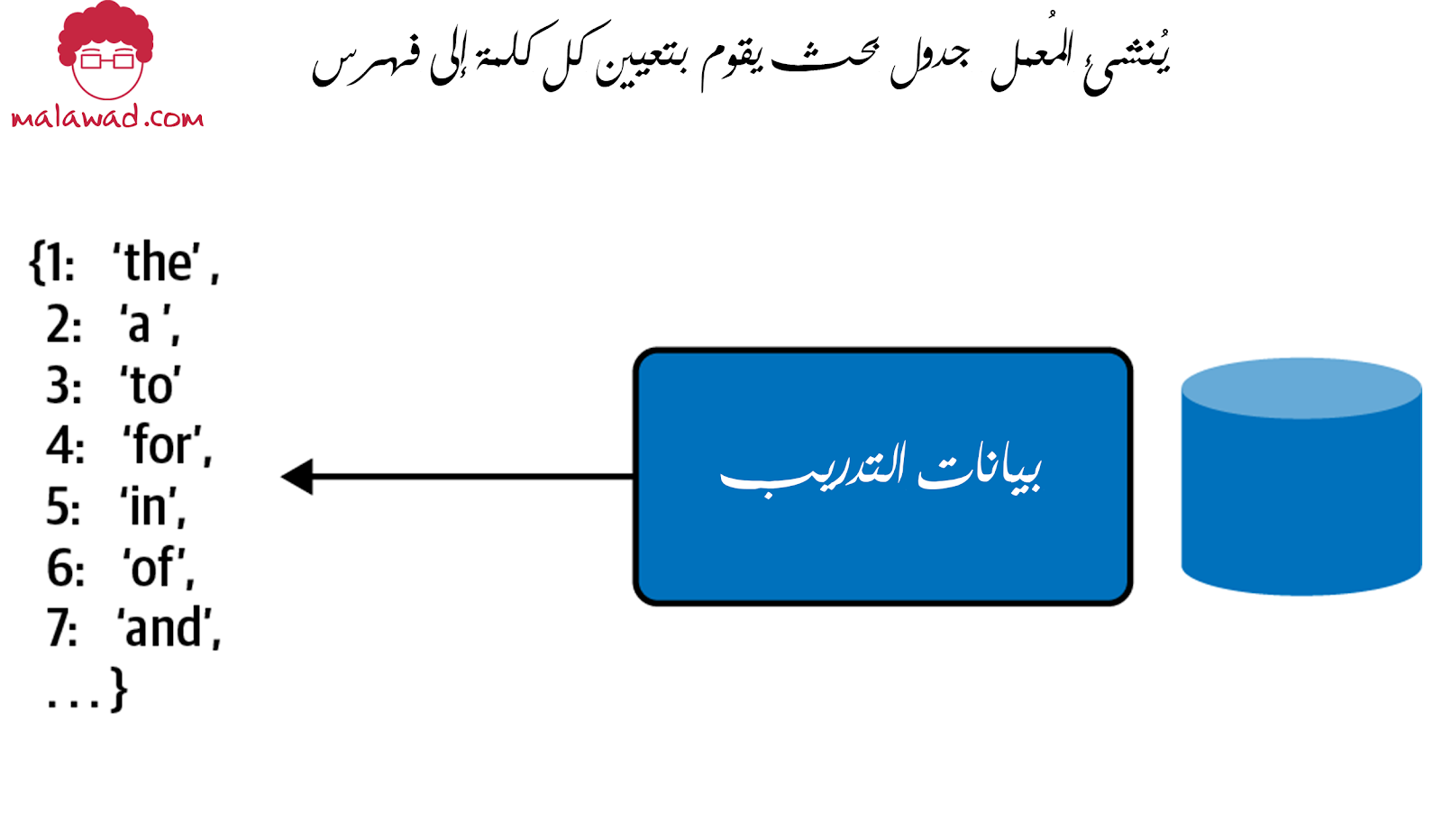
التعميل (tokenize) هو جدول بحث يقوم بتعيين كل كلمة في مفرداتنا إلى فهرس. يمكننا التفكير في هذا باعتباره خط ترميز أحادي لكل كلمة حيث يكون الفهرس بعد التعميل هو موقع العنصر غير الصفري في خط ترميز أحادي.
يتطلب هذا المرور عبر مجموعة البيانات بأكملها (لنفترض أن البيانات تتكون من عناوين المقالات) لإنشاء جدول البحث في Keras. نقوم بالأتي
from tensorflow.keras.preprocessing.text import Tokenizer tokenizer = Tokenizer() tokenizer.fit_on_texts(titles_df.title)
هنا يمكننا استخدام فئة Tokenizer في مكتبة keras.preprocessing.text. يؤدي استدعاء fit_on_texts إلى إنشاء جدول بحث يقوم بتعيين كل كلمة من الكلمات الموجودة في عناويننا إلى فهرس.
من خلال استدعاء tokenizer.index_word ، يمكننا فحص جدول البحث هذا مباشرة:
tokenizer.index_word
{1: 'the',
2: 'a',
3: 'to',
4: 'for',
5: 'in',
6: 'of',
7: 'and',
8: 's',
9: 'on',
10: 'with',
11: 'show',
...
يمكننا بعد ذلك استدعاء هذا التعيين باستخدام الوظيفة المساعدة text_to_sequences الخاصة بالمعمل الخاص بنا. يقوم هذا بتعيين كل سلسلة من الكلمات في النص الذي يتم تمثيله (هنا ، نفترض أنها عناوين مقالات) إلى سلسلة من العملات المقابلة لكل كلمة كما في الشكل:
integerized_titles = tokenizer.texts_to_sequences(titles_df.title)

يحتوي المُعمل (tokenizer ) على معلومات أخرى ذات صلة سنستخدمها لاحقًا لإنشاء طبقة التضمين. على وجه الخصوص ، يلتقط VOCAB_SIZE عدد عناصر جدول بحث الفهرس ويحتوي MAX_LEN على الحد الأقصى لطول السلاسل النصية في مجموعة البيانات:
VOCAB_SIZE = len(tokenizer.index_word) MAX_LEN = max(len(sequence) for sequence in integerized_titles)
قبل إنشاء النموذج ، من الضروري معالجة العناوين الموجودة في مجموعة البيانات مسبقًا. سنحتاج إلى حشو (pad ) عناصر عنواننا لإدخالها في النموذج. لدى Keras الوظيفة المساعدة pad_sequence للقيام بذلك. تأخذ الوظيقة create_sequences كلاً من العناوين بالإضافة إلى الحد الأقصى لطول الجملة كمدخلات وتعيد قائمة بالأعداد الصحيحة المقابلة للعملات التي تم حشوها لتصل لأقصى طول للجملة:
from tensorflow.keras.preprocessing.sequence import pad_sequences
def create_sequences(texts, max_len=MAX_LEN):
sequences = tokenizer.texts_to_sequences(texts)
padded_sequences = pad_sequences(sequences,
max_len,
padding='post')
return padded_sequences
بعد ذلك ، سنقوم ببناء نموذج شبكة عصبية عميقة (DNN) في Keras الذي يطبق طبقة تضمين بسيطة لتحويل الأعداد الصحيحة للكلمة إلى متجهات كثيفة.
يمكن اعتبار طبقة Keras Embedding كربط مؤشرات الأعداد الصحيحة لكلمات محددة إلى متجهات كثيفة ( أي تضميناتها). يتم تحديد أبعاد التضمين بواسطة output_dim.
تشير input_dim إلى حجم المفردات ، وتشير input_shape إلى طول تسلسلات الإدخال. بما أننا قمنا بحشو العناوين قبل تمريرها على النموذج ، سنقوم بتعيين input_shape = [MAX_LEN]:
model = models.Sequential([layers.Embedding(input_dim=VOCAB_SIZE + 1,
output_dim=embed_dim,
input_shape=[MAX_LEN]),
layers.Lambda(lambda x: tf.reduce_mean(x,axis=1)),
layers.Dense(N_CLASSES, activation='softmax')])
لاحظ أننا نحتاج إلى وضع طبقة Keras Lambda مخصصة بين طبقة التضمين وطبقة softmax الكثيفة لمتوسط متجهات الكلمات التي تعيدها طبقة التضمين.
هذا هو المتوسط الذي يتم تغذيته لطبقة softmax الكثيفة. من خلال القيام بذلك ، نقوم بإنشاء نموذج بسيط ولكنه يفقد المعلومات حول ترتيب الكلمات ، مما يؤدي إلى إنشاء نموذج يرى الجمل على أنها “حقيبة من الكلمات”.
تضمينات الصور
بينما يتعامل النص مع مدخلات متناثرة للغاية ، فإن أنواع البيانات الأخرى ، مثل الصور أو الصوت ، تتكون من متجهات كثيفة وعالية الأبعاد ، عادةً مع قنوات متعددة تحتوي على معلومات النقاط الضوئية أو التردد. في هذه الحالة، يلتقط التضمين تمثيلًا ذا صلة منخفض الأبعاد للمدخل.
لتضمين الصور ، يتم تدريب شبكة لف رياضي عصبية أو تلافيفية معقدة – مثل Inception أو ResNet – أولاً على مجموعة بيانات صور كبيرة ، مثل ImageNet ، تحتوي على ملايين الصور والآلاف من التصنيفات المحتملة.
بعد ذلك ، تتم إزالة آخر طبقة softmax من النموذج. بدون طبقة softmax النهائية للتصنيف ، يمكن استخدام النموذج لاستخراج متجه السمات لمدخل معين.
تحتوي متجه السمات هذا على جميع المعلومات ذات الصلة بالصورة ، لذا فهو في الأساس عبارة عن تضمين منخفض الأبعاد لصورة الإدخال.
وبالمثل ، ضع في اعتبارك مهمة التعليق على الصورة ، أي إنشاء تعليق نصي لصورة معينة ، كما هو موضح في الشكل.

من خلال تدريب معمارية النموذج هذه على مجموعة بيانات ضخمة من أزواج الصور / التسمية التوضيحية ، يتعلم المشفر تمثيل متجه فعال للصور. يتعلم المفكك كيفية ترجمة هذا المتجه إلى تعليق نصي. بهذا المعنى ، يصبح المشفر آلة تضمين Image2Vec.
لماذا تعمل التضمينات
طبقة التضمين هي مجرد طبقة مخفية أخرى من الشبكة العصبية. ثم يتم ربط الأوزان بكل من العناصر الأساسية عالية الأبعاد ، ويتم تمرير المخرجات عبر بقية الشبكة. لذلك ، يتم تعلم الأوزان لإنشاء التضمين من خلال عملية الإشتقاق النزولي (gradient descent) تمامًا مثل أي أوزان أخرى في الشبكة العصبية. هذا يعني أن متجهة التضمينات الناتجة تمثل التمثيل منخفض الأبعاد الأكثر فعالية لقيم هذه السمات فيما يتعلق بمهمة التعلم.
في حين أن هذا التضمين المحسن يساعد النموذج ، فإن التضمينات نفسها لها قيمة متأصلة وتسمح لنا باكتساب نظرة ثاقبة على مجموعة البيانات الخاصة بنا.
ضع في اعتبارك مرة أخرى مجموعة بيانات فيديو العميل. باستخدام خط الترميز الأحادي فقط ، سيكون لأي مستخدمين منفصلين ، user_i و user_j ، نفس مقياس التشابه.
وبالمثل ، فإن حاصل الضرب النقطي أو تشابه جيب التمام لأي خط ترميز أحادي سداسي الأبعاد لتعدد المواليد لن يكون لهما أي تشابه.
هذا أمر منطقي نظرًا لأن خط الترميز الأحادي يخبر نموذجنا أن يتعامل مع أي تعددين مختلفين للولادة على أنهما منفصلان وغير مرتبطين.
بالنسبة إلى مجموعة البيانات الخاصة بالعملاء ومشاهدة الفيديو ، نفقد أي فكرة عن التشابه بين العملاء أو مقاطع الفيديو. لكن هذا لا يبدو صحيحًا تمامًا. من المحتمل أن يكون هناك تشابه بين عميلين أو مقاطع فيديو مختلفة. الشيء نفسه ينطبق على تعدد المواليد.
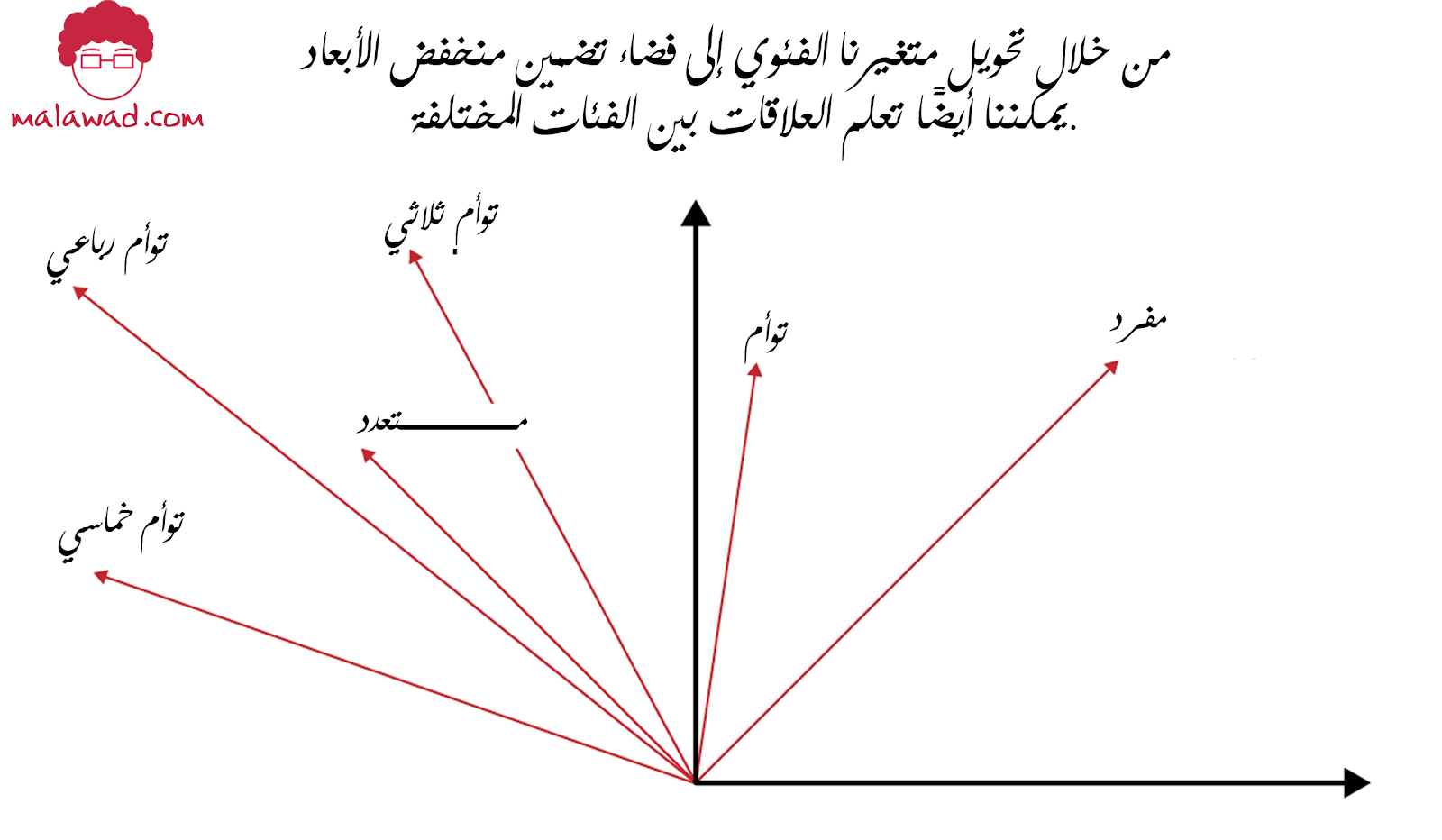
عند حساب تشابه فئات التعددية كمتجهات خط ترميز أحادي (one-hot encoded ) ، نحصل على مصفوفة الوحدة (identity matrix) حيث يتم التعامل مع كل فئة على أنها سمة مستقلة .
| مفرد (1) | متعددة (2+) | التوائم (2) | ثلاثة توائم (3) | أربعة توائم (4) | خمس توائم (5) | |
| مفرد (1) | 1 | 0 | 0 | 0 | 0 | 0 |
| متعددة (2+) | – | 1 | 0 | 0 | 0 | 0 |
| التوائم (2) | – | – | 1 | 0 | 0 | 0 |
| ثلاثة توائم (3) | – | – | – | 1 | 0 | 0 |
| أربعة توائم (4) | – | – | – | – | 1 | 0 |
| خمس توائم (5) | – | – | – | – | – | 1 |
ومع ذلك ، بمجرد دمج التعددية في بعدين ، يصبح مقياس التشابه غير بديهي ، وتظهر علاقات مهمة بين الفئات المختلفة
| مفرد (1) | متعددة (2+) | التوائم (2) | ثلاثة توائم (3) | أربعة توائم (4) | خمس توائم (5) | |
| مفرد (1) | 1 | 0.92 | 0.61 | 0.57 | 0.06 | 0.1 |
| متعددة (2+) | – | 1 | 0 | 0.83 | 0.43 | 0.48 |
| التوائم (2) | – | 1 | 0.99 | 0.82 | 0.85 | |
| ثلاثة توائم (3) | – | 1 | 0.85 | 0.88 | ||
| أربعة توائم (4) | – | 1 | 0.99 | |||
| خمس توائم (5) | – | – | – | – | – | 1 |
وبالتالي ، يسمح لنا التضمين المكتسب باستخراج أوجه التشابه المتأصلة بين فئتين منفصلتين ، ونظرًا لوجود تمثيل متجهة عددي ، يمكننا تحديد التشابه بين سمتين فئويتين بدقة.
من السهل تصور ذلك باستخدام مجموعة بيانات الولادة ، ولكن ينطبق نفس المبدأ عند التعامل مع customer_ids المضمنة في فضاء من 20 بعدًا. عند تطبيقها على مجموعة بيانات عملائنا ، تسمح لنا التضمينات باسترداد عملاء مشابهين لمعرّف عميل معين وتقديم اقتراحات بناءً على التشابه ، مثل مقاطع الفيديو التي من المحتمل مشاهدتها ، كما هو موضح في الشكل.
علاوة على ذلك ، يمكن دمج التضمينات الخاصة بالمستخدمين والعناصر مع سمات أخرى عند تدريب نموذج منفصل لتعلم الألة. يُشار إلى استخدام التضمينات المدربة مسبقًا في نماذج تعلم الألة باسم نقل التعلم (transfer learning).

علاوة على ذلك ، يمكن دمج التضمينات الخاصة بالمستخدمين والعناصر مع سمات أخرى عند تدريب نموذج منفصل لتعلم الألة. يُشار إلى استخدام التضمينات المدربة مسبقًا في نماذج تعلم الألة باسم نقل التعلم (transfer learning).
المقايضات والبدائل
المقايضة الرئيسية في استخدام التضمين هي أن هناك خسارة في المعلومات أثناء الانتقال من التمثيل الأساسي إلى تمثيل منخفض الأبعاد. في المقابل ، نحصل على معلومات حول التقارب وسياق العناصر.
اختيار بُعد التضمين
الأبعاد الدقيقة لفضاء التضمين هي شيء نختاره أثناء الممارسة. لذا ، هل يجب أن نختار بُعد تضمين كبير أم صغير؟ بالطبع ، كما هو الحال مع معظم الأشياء في تعلم الألة ، هناك مقايضة.
يتم التحكم في فقدان التمثيل من خلال حجم طبقة التضمين. باختيار بُعد إخراج صغير جدًا لطبقة التضمين ، يتم فرض الكثير من المعلومات في فضاء متجه صغيرة ويمكن فقد السياق. من ناحية أخرى ، عندما يكون بُعد التضمين كبيرًا جدًا ، يفقد التضمين الأهمية السياقية المكتسبة للسمات.
في الحالات القصوى ، نعود إلى المشكلة التي واجهناها مع خط الترميز الأحادي (one-hot encoding) . غالبًا ما يتم العثور على بُعد التضمين الأمثل من خلال التجريب ، كما هو الحال مع اختيار عدد االعصبونات في طبقة شبكة عصبية عميقة.
إذا كنا في عجلة من أمرنا ، فإن إحدى القواعد الأساسية تتمثل في استخدام الجذر الرابع للعدد الإجمالي للعناصر الفئوية الفريدة في حين أن قاعدة أخرى هي أن بُعد التضمين يجب أن يكون 1.6 مرة تقريبًا من الجذر التربيعي لعدد العناصر الفريدة في الفئة ، وما لا يقل عن 600.
على سبيل المثال ، افترض أننا أردنا استخدام طبقة التضمين لتشفير سمة تحتوي على 625 قيمة فريدة. باستخدام القاعدة الأساسية الأولى ، سنختار بُعد التضمين للتعددية 5 ، وباستخدام القاعدة الثانية ، سنختار 40. إذا كنا نجري ضبطًا لمدخلات الضبط (hyperparameter ) ، فقد يكون من المفيد البحث ضمن هذا النطاق.
الترميز التلقائي (Autoencoders)
قد يكون تدريب التضمينات بطريقة خاضعة للإشراف أمرًا صعبًا لأنه يتطلب الكثير من البيانات المصنفة. لكي يتمكن نموذج تصنيف الصور مثل Inception من إنتاج تضمينات مفيدة ، يتم تدريبه على ImageNet ، التي تحتوي على 14 مليون صورة مصنفة. يوفر الترميز التلقائي طريقة واحدة للتغلب على هذه الحاجة لمجموعة بيانات ذات تصنيف ضخم.
تتكون معمارية الترميز التلقائي النموذجية ، الموضحة في الشكل ، من طبقة عنق الزجاجة ، وهي أساسًا طبقة تضمين. يرسم جزء الشبكة قبل عنق الزجاجة (“المشفر”) المدخلات عالية الأبعاد إلى طبقة تضمين ذات أبعاد منخفضة ، بينما تعيِّن الشبكة الأخيرة (“المفكك “) هذا التمثيل مرة أخرى إلى بُعد أعلى ، يكون عادةً مماثل للبعد كالأصل. يتم تدريب النموذج عادةً على بعض المتغيرات لخطأ إعادة البناء ، مما يفرض على أن يكون ناتج النموذج مشابهًا قدر الإمكان للمدخل.

نظرًا لأن الإدخال هو نفسه الإخراج ، فلا حاجة إلى تسميات إضافية. يتعلم المشفر الحد الأمثل من البعد الغير الخطي للمدخلات. فإن طبقة عنق الزجاجة في الترميز التلقائي قادرة على الحصول على تقليل البعد غير الخطي من خلال التضمين.
هذا يسمح لنا بتقسيم مشكلة تعلم الألة الصعبة إلى جزأين. أولاً ، نستخدم جميع البيانات غير المصنفة لدينا للانتقال من الفضاء عالي الأبعاد إلى الفضاء منخفض الأبعاد باستخدام الترميز التلقائي كمهمة تعلم مساعدة.
بعد ذلك ، نحل مشكلة تصنيف الصور الفعلية التي عادةً ما يكون لدينا بيانات مصنفة قليلة لها باستخدام التضمين الناتج عن الترميز التلقائي. من المحتمل أن يؤدي هذا إلى تعزيز أداء النموذج ، لأنه يتعين الآن على النموذج فقط أن يتعلم الأوزان الخاصة بالبعد الأدنى (أي يجب أن يتعلم أوزانًا أقل).
بالإضافة إلى إستخدام الترميز التلقائي للصور ، ركزت الأعمال الحديثة على تطبيق تقنيات التعلم العميق للبيانات المنظمة. TabNet عبارة عن شبكة عصبية عميقة مصممة خصيصًا للتعلم من البيانات المجدولة ويمكن تدريبها بطريقة غير خاضعة للإشراف. من خلال تعديل النموذج ليكون له معمارية مشفر-مفكك ، تعمل TabNet كشبكة ترميز تلقائي على البيانات المجدولة ، مما يسمح للنموذج بتعلم التضمينات من البيانات المنظمة عبر محول السمات.
نماذج لغة السياق
هل هناك مهمة تعلم مساعدة تعمل مع النص؟ نماذج لغة السياق مثل Word2Vec ونماذج اللغة المقنعة مثل تمثيلات الترميز ثنائية الاتجاه من المحولات (Bidirectional Encoding Representations from Transformers) أو (BERT) تغير مهمة التعلم إلى مشكلة بحيث لا يكون هناك ندرة في التسميات.
Word2Vec هي طريقة معروفة لبناء التضمين باستخدام الشبكات العصبية الضحلة والجمع بين تقنيتين – حقيبة الكلمات المستمرة (CBOW) ونموذج تخطي الجرام (skip-gram) – يتم تطبيقهما على مجموعة كبيرة من النصوص ، مثل ويكيبيديا.
في حين أن الهدف من كلا النموذجين هو معرفة سياق الكلمة عن طريق تعيين كلمة ( أو كلمات) الإدخال للكلمة ( أو الكلمات) المستهدفة مع طبقة تضمين وسيطة ، يتم تحقيق هدف إضافي بتعلم التضمينات منخفضة الأبعاد التي تلتقط سياق الكلمات بشكل أفضل.
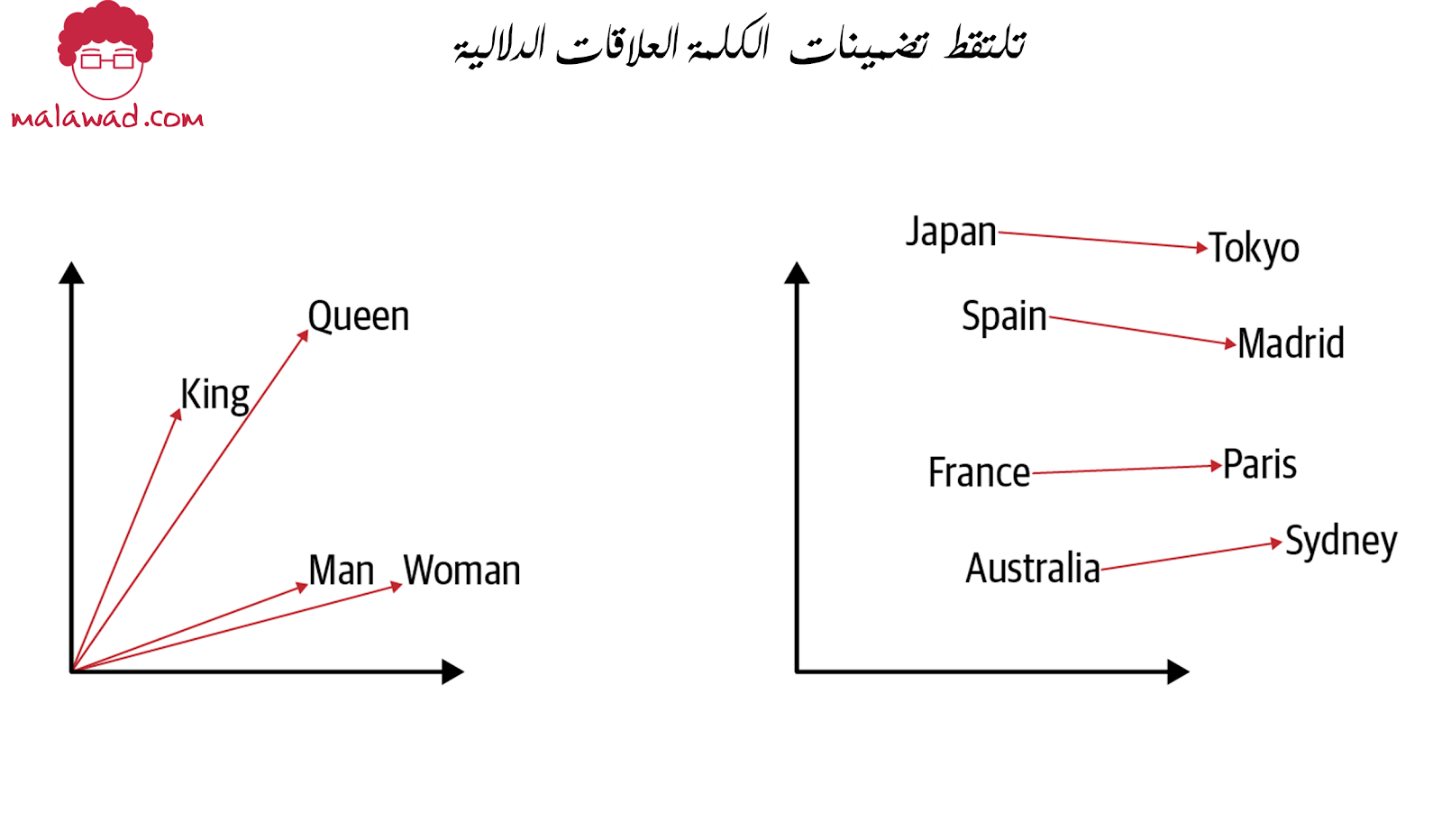
تلتقط تضمينات الكلمة الناتجة التي تم تعلمها من خلال Word2Vec العلاقات الدلالية بين الكلمات بحيث تحافظ تمثيلات المتجه في فضاء التضمين على مسافة واتجاه هادفين .
يتم تدريب BERT باستخدام نموذج لغة مقنع وتنبؤ الجملة التالية. بالنسبة لنموذج اللغة المقنع (masked language model) ، يتم إخفاء الكلمات عشوائيًا من النص ويخمن النموذج ما هي الكلمة (الكلمات) المفقودة.
توقع الجملة التالية هو مهمة تصنيف حيث يتنبأ النموذج بما إذا كانت جملتان تتبعان بعضهما البعض في النص الأصلي أم لا. لذا فإن أي مجموعة نصية تعتبر مناسبة كمجموعة بيانات مسماة.
تم تدريب BERT في البداية على كل من Wikipedia و BooksCorpus الإنجليزية. على الرغم من التعلم في هذه المهام الإضافية ، فقد أثبتت التضمينات المكتسبة من BERT أو Word2Vec أنها قوية جدًا عند استخدامها في مهام التدريب الأخرى. إن تضمينات الكلماة التي تعلمها Word2Vec هي نفسها بغض النظر عن الجملة التي تظهر فيها الكلمة. ومع ذلك ، فإن التضمينات كلمة BERT سياقية ، بمعنى أن متجه التضمين يختلف اعتمادًا على سياق كيفية استخدام الكلمة.
يمكن إضافة تضمين نص تم تدريبه مسبقًا ، مثل Word2Vec أو NNLM أو GLoVE أو BERT ، إلى نموذج تعلم الألة لمعالجة سمات النص جنبًا إلى جنب مع المدخلات المنظمة و التضمينات الأخرى المكتسبة من عملائنا ومجموعة بيانات الفيديو .
في النهاية ، تتعلم التضمينات الحفاظ على المعلومات ذات الصلة بمهمة التدريب المحددة. في حالة التعليق على الصورة ، تكمن المهمة في معرفة كيفية ارتباط سياق عناصر الصورة بالنص. في معمارية الترميز التلقائية ، تكون التسمية هي نفسها السمة ، لذا فإن تقليل أبعاد في عنق الزجاجة يحاول تعلم كل شيء بدون سياق محدد لما هو مهم.

التضميات في مستودع البيانات
من الأفضل تنفيذ تعلم الألة على البيانات المنظمة مباشرةً في SQL في مستودع البيانات. هذا يتجنب الحاجة إلى تصدير البيانات من المستودع ويخفف من مشاكل خصوصية البيانات وأمانها.
ومع ذلك ، تتطلب العديد من المشكلات مزيجًا من البيانات المهيكلة والنصوص أو بيانات الصور باللغة الطبيعية. في مستودعات البيانات ، يتم تخزين نصوص اللغة الطبيعية (مثل المراجعات) مباشرة كأعمدة ، وعادة ما يتم تخزين الصور كعناوين URL لملفات في حاوية تخزين سحابية.
في مثل هذه الحالات ، فإن هذا يبسط تعلم الألة اللاحق لتخزين تضمينات أعمدة النص أو الصور كأعمدة من نوع المصفوفة. سيؤدي القيام بذلك إلى تمكين الدمج السهل لهذه البيانات غير المهيكلة في نماذج تعلم الألة.
لإنشاء تضمينات نصية ، يمكننا تحميل نموذج مدرب مسبقًا مثل Swivel من TensorFlow Hub إلى BigQuery. ا
CREATE OR REPLACE MODEL advdata.swivel_text_embed OPTIONS(model_type='tensorflow', model_path='gs://BUCKET/swivel/*')
بعد ذلك ، استخدم النموذج لتحويل عمود نص اللغة الطبيعية إلى مصفوفة تضمين وتخزين بحث التضمين في جدول جديد:
CREATE OR REPLACE TABLE advdata.comments_embedding AS SELECT output_0 as comments_embedding, comments FROM ML.PREDICT(MODEL advdata.swivel_text_embed,( SELECT comments, LOWER(comments) AS sentences FROM `bigquery-public-data.noaa_preliminary_severe_storms.wind_reports` ))
من الممكن الآن ضم هذا الجدول للحصول على تضمينات النص لأي تعليق. بالنسبة لتضمينات الصور ، يمكننا بالمثل تحويل عناوين URL للصور إلى التضمينات وتحميلها في مستودع البيانات.













إضافة تعليق