
يوجد في قلب أي نموذج لتعلم الألة وظيفة رياضية يتم تعريفها للعمل على أنواع معينة من البيانات فقط. في الوقت نفسه ، تحتاج نماذج تعلم الألة في العالم الحقيقي إلى العمل على البيانات التي قد لا تكون قابلة للإستخدام من قبل الوظيفة الرياضية.
على سبيل المثال ، يعمل الجوهر الرياضي لشجرة القرار (decision tree,) على المتغيرات المنطقية. لاحظ أننا نتحدث هنا عن الجوهر الرياضي لشجرة القرار – سيتضمن برنامج تعلم الألة لشجرة القرار عادةً أيضًا وظائف لتعلم شجرة مثالية من البيانات وطرق قراءة ومعالجة أنواع مختلفة من البيانات الرقمية والفئوية.
ومع ذلك ، فإن الوظيفة الرياضية في الشكل أدناه التي تدعم شجرة القرار ، تعمل على المتغيرات المنطقية وتستخدم عمليات مثل AND (&& في الرسم) و OR (+ في الرسم).
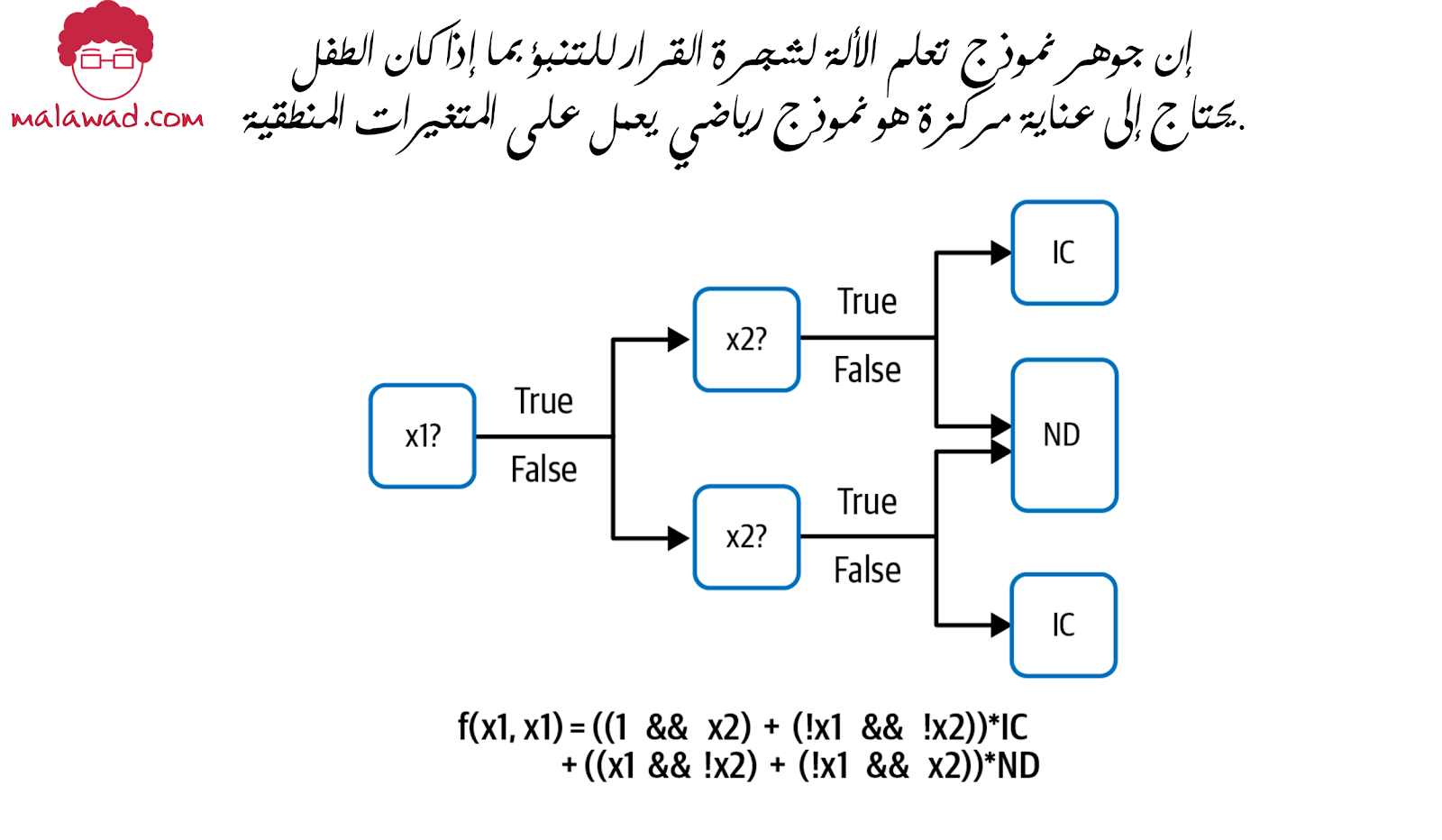
لنفترض أن لدينا شجرة قرار للتنبؤ بما إذا كان الطفل سيحتاج إلى رعاية مركزة (intensive care) أو (IC) أو يمكن تصريفه بشكل طبيعي (normally discharged) أو (ND) ، وافترض أن شجرة القرار تأخذ كمدخلات متغيرين ، x1 و x2. قد يبدو النموذج المدرب مثل الشكل أعلاه.
من الواضح تمامًا أن x1 و x2 يجب أن يكونا متغيرين منطقيين حتى تعمل الدالة f (x1، x2). افترض أن اثنتين من المعلومات التي نود أن يأخذها النموذج في الاعتبار عند تصنيف الطفل على أنه يحتاج إلى عناية مركزة أم لا ، هما المستشفى الذي يولد فيه الطفل ووزن الطفل.
هل يمكننا استخدام المستشفى الذي يولد فيه الطفل كمدخل لشجرة القرار؟ لا ، لأن المستشفى لا تأخذ القيمة True ولا القيمة False ولا يمكن إدخالها في عامل التشغيل && (AND). انها غير متوافقة رياضيا. بالطبع ، يمكننا “جعل” قيمة المستشفى منطقية من خلال إجراء عملية مثل:
x1 = (مستشفى في فرنسا)
بحيث يكون x1 صحيحًا عندما يكون المستشفى في فرنسا ، وخطأ إذا لم يكن كذلك. وبالمثل ، لا يمكن إدخال وزن الطفل مباشرة في النموذج ، ولكن من خلال إجراء عملية مثل:
x1 = (وزن الطفل <3 كجم)
يمكننا استخدام وزن المستشفى أو الطفل كمدخل للنموذج. هذا مثال على كيفية تمثيل بيانات الإدخال (مستشفى ، كائن معقد أو وزن طفل ، رقم عائمة) بشكل (منطقي) الذي يتوقعه النموذج. هذا ما نعنيه بتمثيل البيانات.
في هذه السلسلة من المقالات عن أنماط التصميم ، سنستخدم مصطلح مدخلات (input) لتمثيل بيانات العالم الحقيقي التي يتم تغذيتها للنموذج (على سبيل المثال ، وزن الطفل) ومصطلح سمة (feature ) لتمثيل البيانات المحولة التي يعمل عليها النموذج بالفعل (على سبيل المثال ، ما إذا كان وزن الطفل أقل من 3 كيلوغرامات). تسمى عملية إنشاء السمات لتمثيل بيانات الإدخال هندسة السمات (feature engineering) ، ولذا يمكننا التفكير في هندسة السمات كطريقة لاختيار تمثيل البيانات.
بالطبع ، بدلاً من إستخدام معايير الترميز الثابت مثل قيمة العتبة البالغة 3 كيلوغرامات ، نفضل أن يقوم نموذج تعلم الألة بتعلم كيفية إنشاء كل عقدة عن طريق تحديد متغير الإدخال والعتبة. أشجار القرار هي مثال لنماذج تعلم الألة القادرة على تعلم تمثيل البيانات .
نمط تصميم التضمينات (Embeddings ) هو مثال أساسي لتمثيل البيانات الذي تستطيع الشبكات العصبية العميقة التعلم من تلقاء نفسها.
في التضمين ، يكون التمثيل الذي تم تعلمه كثيفًا وأقل بعدًا من المدخلات ، مما يسبب التناثر . تحتاج خوارزمية التعلم إلى استخراج المعلومات الأكثر بروزًا من المدخلات وتمثيلها بطريقة أكثر إيجازًا في السمة . تسمى عملية تعلم السمات لتمثيل بيانات الإدخال استخراج السمات، ويمكننا التفكير في تمثيلات البيانات القابلة للتعلم (مثل التضمينات) كسمات مصممة تلقائيًا.
لا يلزم حتى أن يكون تمثيل البيانات من متغير إدخال واحد – على سبيل المثال ، تنشئ شجرة قرار مائلة (oblique decision tree) سمة منطقية (boolean feature) عن طريق تحديد مجموعة خطية من متغيرين أو أكثر من متغيرات الإدخال.
تتقلص شجرة القرار حيث يمكن أن تمثل كل عقدة متغير إدخال واحد فقط إلى دالة خطية متدرجة (stepwise linear function) ، في حين أن شجرة القرار المائلة حيث يمكن أن تمثل كل عقدة مجموعة خطية من متغيرات الإدخال تقل إلى دالة خطية متعددة التعريفات (piecewise linear function).
بالنظر إلى عدد الخطوات التي يجب تعلمها لتمثيل الخط بشكل مناسب ، فإن النموذج الخطي متعدد التعريف هو أبسط وأسرع للتعلم. امتداد لهذه الفكرة هو نمط تصميم السمة المتقاطع (Feature Cross )، الذي يبسط تعلم العلاقات بين المتغيرات الفئوية متعددة القيم.

لا يلزم تعلم تمثيل البيانات أو إصلاحه – فالهجين ممكن أيضًا. يعد نمط تصميم السمة المجزئة (Hashed Feature) حتميًا ، ولكنه لا يتطلب نموذجًا لمعرفة كل القيم المحتملة التي يمكن أن يتخذها إدخال معين.
تمثيلات البيانات التي نظرنا إليها حتى الآن كلها فردية. على الرغم من أنه يمكننا تمثيل بيانات الإدخال لأنواع مختلفة بشكل منفصل أو تمثيل كل جزء من البيانات كسمة واحدة فقط ، إلا أنه قد يكون من المفيد استخدام الإدخال متعدد الأنماط (Multimodal Input).
تمثيلات البيانات البسيطة
قبل الخوض في تمثيلات البيانات القابلة للتعلم ، دعنا نلقي نظرة على تمثيلات بيانات أبسط. يمكننا أن نفكر في تمثيلات البيانات البسيطة هذه على أنها مصطلحات شائعة في تعلم الألة – ليست أنماطًا ، ولكنها حلول شائعة الاستخدام مع ذلك.
المدخلات العددية
تعمل معظم نماذج تعلم الألة الحديثة والواسعة النطاق (الغابات العشوائية ، وآلات الدعم ، والشبكات العصبية) على قيم عددية ، وبالتالي إذا كانت مدخلاتنا العددية، فيمكننا تمريرها إلى النموذج دون تغيير.
لماذا التسوية أمر مرغوب فيه
غالبًا ، نظرًا لأن إطار عمل تعلم الألة يستخدم مُحسِّنًا تم ضبطه للعمل بشكل جيد مع الأرقام في النطاق [–1 ، 1] ، فإن تسوية القيم العددية لتكمن في هذا النطاق يمكن أن يكون مفيدًا.
لماذا تكمن القيم العددية للمقياس في [–1 ، 1]؟
تتطلب مُحسِنات الإشتقاق النزولي مزيدًا من الخطوات للتقارب مع زيادة انحناء دالة الخسارة. هذا لأن مشتقات السمات ذات الأحجام النسبية الأكبر تميل إلى أن تكون أكبر أيضًا ، وبالتالي تؤدي إلى تحديثات غير طبيعية للوزن. ستتطلب تحديثات الوزن الكبيرة بشكل غير طبيعي مزيدًا من الخطوات للتقارب وبالتالي زيادة حمل الحساب.
“توسيط” البيانات التي تقع في النطاق [–1 ، 1] يجعل وظيفة الخطأ أكثر كروية. لذلك ، تميل النماذج المدربة على البيانات المحولة إلى التقارب بشكل أسرع وبالتالي فهي أسرع / أرخص للتدريب. بالإضافة إلى ذلك ، يوفر النطاق [–1 ، 1] أعلى دقة للفاصلة العائمة.
يمكن أن يثبت الاختبار السريع مع إحدى مجموعات البيانات المضمنة في scikit-Learn النقطة
from sklearn import datasets, linear_model
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
raw = diabetes_X[:, None, 2]
max_raw = max(raw)
min_raw = min(raw)
scaled = (2*raw - max_raw - min_raw)/(max_raw - min_raw)
def train_raw():
linear_model.LinearRegression().fit(raw, diabetes_y)
def train_scaled():
linear_model.LinearRegression().fit(scaled, diabetes_y)
raw_time = timeit.timeit(train_raw, number=1000)
scaled_time = timeit.timeit(train_scaled, number=1000)
عندما قمنا بتشغيل هذا ، حصلنا على ما يقرب من 9٪ تحسن في هذا النموذج الذي يستخدم سمة إدخال واحدة فقط. بالنظر إلى عدد السمات في نموذج تعلم الألة النموذجي .
سبب آخر مهم للتسوية هو أن بعض خوارزميات وتقنيات تعلم الألة حساسة جدًا للأحجام النسبية للسمات المختلفة. على سبيل المثال ، خوارزمية التجميع المتوسطة كي (k-means clustering algorithm) التي تستخدم المسافة الإقليدية كمقياس للقرب سينتهي بها الأمر بالاعتماد بشكل كبير على السمات ذات الأحجام الأكبر.
يؤثر نقص القياس أيضًا على فعالية تنظيم L1 أو L2 نظرًا لأن حجم الأوزان السمة يعتمد على حجم قيم تلك السمة ، وبالتالي ستتأثر السمات المختلفة بشكل مختلف بالتنظيم. من خلال تسوية جميع السمات لتقع بين [–1 ، 1] ، نضمن عدم وجود فرق كبير في المقادير النسبية للسمات المختلفة.
تسوية خطية
يتم استخدام أربعة أشكال من التسوية بشكل شائع:
تسوية الأدنى – الأقصى (Min-max scaling)
يتم تسوية القيمة العددية خطيًا بحيث يتم تسوية الحد الأدنى للقيمة التي يمكن أن يتخذها الإدخال إلى -1 وأقصى قيمة ممكنة إلى 1:
x1_scaled = (2*x1 - max_x1 - min_x1)/(max_x1 - min_x1)
تكمن مشكلة تسوية الأدنى – الأقصى في أنه يجب تقدير القيمة القصوى والدنيا (max_x1 و min_x1) من مجموعة بيانات التدريب ، وغالبًا ما تكون قيمًا متقطعة. غالبًا ما يتم تقليص البيانات الحقيقية إلى نطاق ضيق جدًا في النطاق [–1 ، 1].
القص (بالتزامن مع التسوية الأدنى-الأقصى)
هذا يساعد في معالجة مشكلة القيم العددية المتطرفة باستخدام قيم “معقولة” بدلاً من تقدير الحد الأدنى والحد الأقصى من مجموعة بيانات التدريب. يتم تسوية القيمة العددية خطيًا بين هذين الحدين المعقولين ، ثم يتم قصها لتقع في النطاق [–1 ، 1]. هذا له تأثير معالجة القيم المتطرفة في النطاق -1 أو 1.
تسوية النتيجة-زي (Z-score normalization)
يعالج مشكلة القيم المتطرفة دون الحاجة إلى معرفة مسبقة بالنطاق المعقول من خلال التسوية الخطي للمدخلات باستخدام المتوسط والانحراف المعياري المقدّر عبر مجموعة بيانات التدريب:
x1_scaled = (x1 - mean_x1)/stddev_x1
يعكس اسم الطريقة حقيقة أن القيمة المقاسة لها متوسط صفري ويتم تسويتها بواسطة الانحراف المعياري بحيث يكون لها تباين على مجموعة بيانات التدريب.
القيمة بعد التسوية ليس لها حد ، ولكنها تقع بين [-1 ، 1] معظم الوقت (67٪ ، إذا كان التوزيع الأساسي طبيعيًا). تزداد ندرة القيم خارج هذا النطاق كلما زادت قيمتها المطلقة ، لكنها لا تزال موجودة.
تفتيت (Winsorizing)
يستخدم التوزيع التجريبي في مجموعة بيانات التدريب لقص مجموعة البيانات إلى الحدود المعطاة بواسطة القيم 10% و 90% من قيم البيانات (أو 5% و 95% ، وهكذا). القيمة المُكتسبة هي الحد الأدنى-الأقصى للتسوية.
جميع الطرق التي تمت مناقشتها حتى الآن تعمل على تسوية البيانات خطيًا.
تميل الطريقتين الأدنى – الأقصى (Min-max) و القص (clipping) إلى العمل بشكل أفضل مع البيانات الموزعة بشكل موحد ، وتميل النتيجة-زي للعمل بشكل أفضل مع البيانات الموزعة بشكل طبيعي.
مهم : لا ترمي “القيم المتطرفة”
لاحظ أننا عرّفنا الفص على أنه أخذ القيم بعد التسوية الأقل من -1 ومعاملتها على أنها -1 ، والقيم أكبر من 1 ومعاملتها على أنها 1. نحن لا نتجاهل مثل هذه “القيم المتطرفة” لأننا نتوقع أن نموذج تعلم الألة سوف يواجه القيم المتطرفة مثل هذا في الإنتاج.
خذ ، على سبيل المثال ، الأطفال المولودين لأمهات يبلغن من العمر 50 عامًا. نظرًا لعدم وجود عدد كافٍ من الأمهات الأكبر سناً في مجموعة البيانات الخاصة بنا ، ينتهي الأمر بالقص إلى معالجة جميع الأمهات الأكبر من 45 عامًا (على سبيل المثال) بعمر 45.
سيتم تطبيق هذا العلاج نفسه في الإنتاج ، وبالتالي ، سيكون نموذجنا قادرًا على التعامل مع الأمهات الأكبر سنًا . لن يتعلم النموذج أن يعكس القيم المتطرفة إذا تخلصنا ببساطة من جميع الأمثلة التدريبية للأطفال المولودين لأمهات تزيد أعمارهن عن 50 عامًا!
هناك طريقة أخرى للتفكير في ذلك وهي أنه في حين أنه من المقبول التخلص من المدخلات غير الصالحة ، فإنه من غير المقبول التخلص من البيانات الصحيحة.
وبالتالي ، سيكون لدينا ما يبرر التخلص من الصفوف التي تكون فيها mother_age سالبة لأنها على الأرجح خطأ في إدخال البيانات.
أثناء الإنتاج ، سيضمن التحقق من صحة نموذج الإدخال أن كاتب المدخل يجب أن يعيد إدخال سن الأم. ومع ذلك ، ليس لدينا ما يبرر التخلص من الصفوف التي تكون فيها mother_age هي 50 لأن الرقم 50 هو إدخال صالح تمامًا ونتوقع أن نلتقي بأمهات يبلغن من العمر 50 عامًا بمجرد نشر النموذج في الإنتاج.
في الشكل أدناه، لاحظ أن minmax_scaled يحصل على قيم x في النطاق المرغوب من [–1 ، 1] لكنه يستمر في الاحتفاظ بالقيم في الأطراف القصوى للتوزيع حيث لا توجد أمثلة كافية.
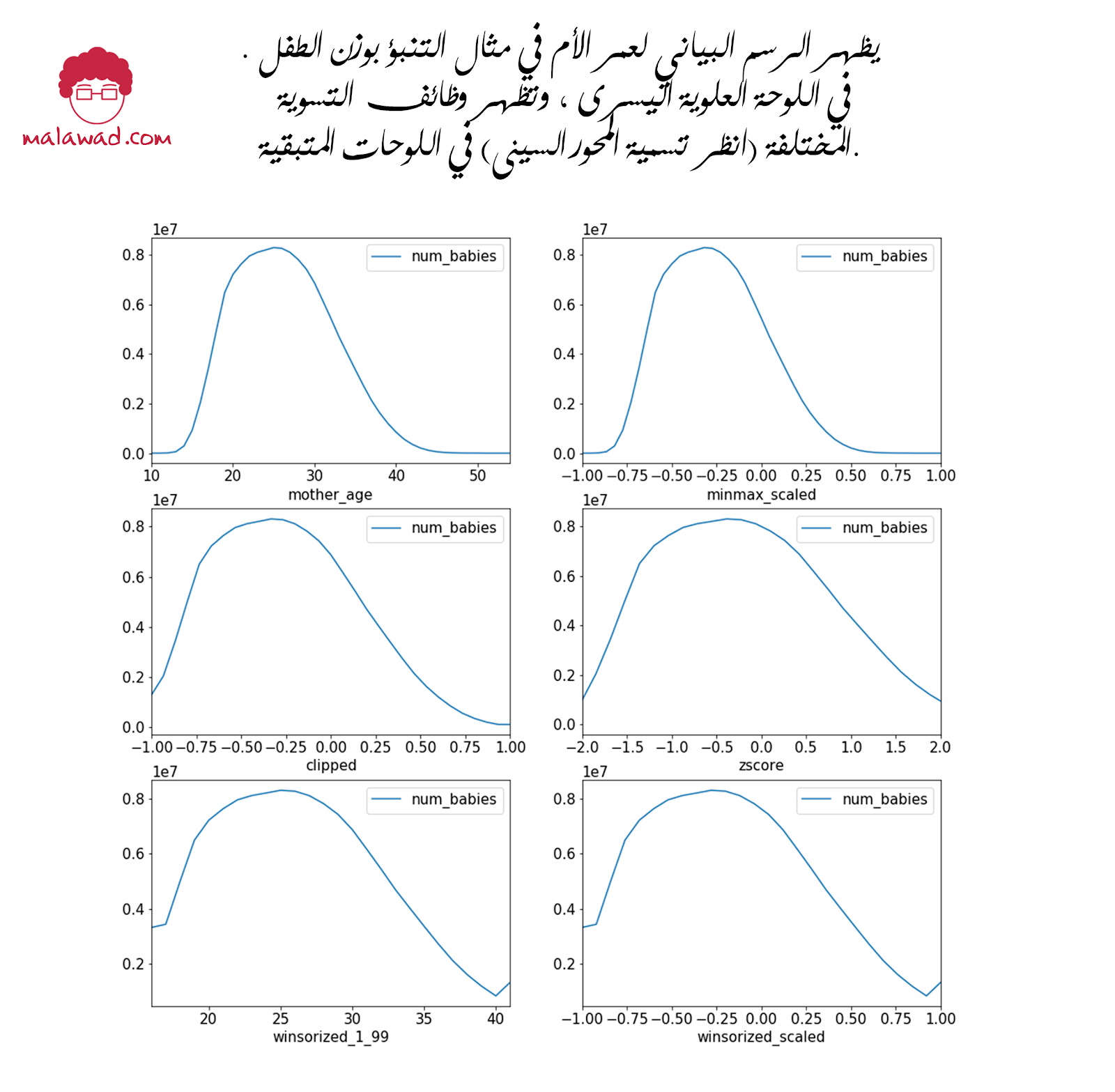
يتعامل القص مع العديد من القيم المسببه للمشاكل ، ولكنه يتطلب الحصول على عتبات قص صحيحة تمامًا – هنا ، هنا الانخفاض البطيء في عدد الأطفال الذين تزيد أعمارهم أمهاتهم عن 40 عامًا تطرح مشاكل في تحديد عتبة قصوى يدوياً .
يتطلب التفتيت، على غرار القص، الحصول على عتبات النسبة المئوية بشكل صحيح تمامًا.
يعمل تسوية النتيجة-زي على تحسين النطاق (لكنه لا يقيد القيم لتكون بين [–1 ، 1]) ويدفع القيم المسبب للمشاكل إلى أبعد من ذلك. من بين هذه الطرق الثلاث ، تعمل التسوية الصفرية (zero-norming ) بشكل أفضل مع عمر الأم لأن قيم العمر الخام كانت إلى حد ما تمثل منحنى الجرس.
بالنسبة للمشكلات الأخرى ، فقد يعمل تسوية الأدنى- الأقصى أو القص أو التفتيت بشكل أفضل.
التحولات غير الخطية
ماذا لو كانت بياناتنا منحرفة وغير موزعة بشكل موحد أو موزعة مثل منحنى الجرس؟ في هذه الحالة ، من الأفضل تطبيق تحويل غير خطي على الإدخال قبل تسويةه. إحدى الحيل الشائعة هي أخذ لوغاريتم قيمة الإدخال قبل تسويتها. تتضمن التحولات الشائعة الأخرى توسعات دالة السيغمويد و الدوال متعددة الحدود (التربيعي والجذر التربيعي والمكعب والجذر التكعيبي وما إلى ذلك). سنعرف أن لدينا دالة تحويل جيدة إذا أصبح توزيع القيمة المحولة منتظمًا أو موزعًا بشكل طبيعي.
افترض أننا نبني نموذجًا للتنبؤ بمبيعات كتاب واقعي. أحد مدخلات النموذج هو شعبية صفحة ويكيبيديا المقابلة للموضوع. ومع ذلك ، فإن عدد مشاهدات الصفحات في ويكيبيديا منحرف للغاية ويحتل نطاقًا ديناميكيًا كبيرًا (انظر اللوحة اليمنى من الشكل أدناه: التوزيع منحرف للغاية نحو الصفحات التي نادرًا ما يتم عرضها ، ولكن الصفحات الأكثر شيوعًا يتم عرضها عشرات من ملايين المرات). من خلال أخذ لوغاريتم وجهات النظر ، ثم أخذ الجذر الرابع لهذه القيمة اللوغاريتمية وقياس النتيجة خطيًا ، نحصل على شيء في النطاق المرغوب فيه إلى حد ما على شكل جرس.

قد يكون من الصعب ابتكار دالة خطية تجعل التوزيع يبدو وكأنه منحنى الجرس. تتمثل الطريقة الأسهل في تجميع عدد المشاهدات ، واختيار حدود الحاوية لتناسب توزيع الإخراج المطلوب.
تتمثل الطريقة المبدئية في اختيار هذه المجموعات في إجراء معادلة المدرج التكراري (histogram equalization) ، حيث يتم اختيار صناديق المدرج التكراري بناءً على مقادير التوزيع الخام ، (اللوحة الثالثة من الشكل أعلاه). في الحالة المثالية ، ينتج عن معادلة المدرج التكراري توزيع منتظم (وإن لم يكن في هذه الحالة ، بسبب القيم المتكررة في الكميات).
لتنفيذ معادلة المدرج التكراري في BigQuery ، يمكننا تنفيذ ما يلي:
ML.BUCKETIZE(num_views, bins) AS bin
بحيث يتم الحصول على الصناديق من
APPROX_QUANTILES(num_views, 100) AS bins
هناك طريقة أخرى للتعامل مع التوزيعات المنحرفة وهي استخدام تقنية تحويل حدودي مثل تحويل Box-Cox.
يختار Box-Cox معامله الوحيد ، lambda ، للتحكم في “التباين غير المتماثل” بحيث لا يعتمد التباين على المقدار. هنا ، سيكون التباين بين صفحات ويكيبيديا التي نادرًا ما يتم عرضها أصغر بكثير من التباين بين الصفحات التي يتم عرضها بشكل متكرر ،
ويحاول Box-Cox معادلة التباين عبر جميع نطاقات عدد المشاهدات. يمكن القيام بذلك باستخدام حزمة Python SciPy:
traindf['boxcox'], est_lambda = (
scipy.stats.boxcox(traindf['num_views']))
يتم بعد ذلك استخدام المعييار الذي تم تقديرة عبر مجموعة بيانات التدريب (est_lambda) لتحويل القيم الأخرى:
evaldf['boxcox'] = scipy.stats.boxcox(evaldf['num_views'], est_lambda)
مجموعة من الأرقام
في بعض الأحيان ، تكون بيانات الإدخال عبارة عن مجموعة من الأرقام. إذا كانت المصفوفة ذات طول ثابت ، يمكن أن يكون تمثيل البيانات بسيطًا إلى حد ما: قم بتسطيح المصفوفة وتعامل مع كل موضع كسمة منفصلة. لكن في كثير من الأحيان ، ستكون المصفوفة متغيرة الطول. على سبيل المثال ، قد يكون أحد مدخلات النموذج للتنبؤ بمبيعات كتاب واقعي هو مبيعات جميع الكتب السابقة حول هذا الموضوع. قد يكون أحد الأمثلة على الإدخال:
[2100 ، 15200 ، 230000 ، 1200 ، 300 ، 532100]من الواضح أن طول هذه المجموعة سيختلف في كل صف لأن هناك أعدادًا مختلفة من الكتب المنشورة حول مواضيع مختلفة.
تتضمن المصطلحات الشائعة للتعامل مع مصفوفات الأرقام ما يلي:
- تمثيل مصفوفة الإدخال من حيث الإحصائيات المجمعة. على سبيل المثال ، قد نستخدم الطول (أي عدد الكتب السابقة حول الموضوع) ، والمتوسط ، و التوسط ، والحد الأدنى ، والحد الأقصى ، وما إلى ذلك.
- تمثيل مصفوفة الإدخال من حيث توزيعها التجريبي – أي حسب النسبة المئوية10% ، 20% ، وهكذا.
- إذا تم ترتيب المصفوفة بطريقة معينة (على سبيل المثال ، بالترتيب الزمني أو حسب الحجم) ، يتم تمثيل مصفوفة الإدخال حسب آخر ثلاثة عناصر أو عدد ثابت آخر من العناصر. بالنسبة إلى المصفوفات التي يقل طولها عن ثلاثة ، يتم حشو السمة ليصبح طولها ثلاثة.
كل هذا في نهاية المطاف يمثل مجموعة متغيرة الطول من البيانات كسمة ثابتة الطول. كان بإمكاننا أيضًا صياغة هذه المشكلة كمشكلة توقع السلاسل الزمنية ، مثل مشكلة التنبؤ بمبيعات الكتاب التالي حول الموضوع بناءً على التاريخ الزمني لمبيعات الكتب السابقة. من خلال التعامل مع مبيعات الكتب السابقة كمدخلات مصفوفة ، نفترض أن أهم العوامل في التنبؤ بمبيعات الكتاب هي خصائص الكتاب نفسه (المؤلف والناشر والمراجعات وما إلى ذلك) وليس الاستمرارية الزمنية للمبيعات ككميات.
المدخلات الفئوية
نظرًا لأن معظم نماذج تعلم الألة الحديثة والواسعة النطاق (الغابات العشوائية ،و أليات متجهة الدعم ، والشبكات العصبية) تعمل على القيم العددية ، يجب تمثيل المدخلات الفئوية كأرقام.
ببساطة تعداد القيم المحتملة وتعيينها إلى مقياس ترتيبي سيعمل بشكل سيء. لنفترض أن أحد مدخلات النموذج الذي يتنبأ بمبيعات كتاب واقعي هي اللغة التي تمت كتابة الكتاب بها. لا يمكننا ببساطة إنشاء جدول رسم خرائط مثل هذا:
| إدخال فئوي | سمة رقمية |
| الإنجليزية | 1.0 |
| الصينية | 2.0 |
| الألمانية | 3.0 |
وذلك لأن نموذج تعلم الألة سيحاول بعد ذلك إستخدام شعبية الكتب الألمانية والإنجليزية للحصول على شعبية الكتاب باللغة الصينية! نظرًا لعدم وجود علاقة ترتيبية بين اللغات ، نحتاج إلى استخدام ربط فئوي إلى عددي يسمح للنموذج بتعلم سوق الكتب المكتوبة بهذه اللغات بشكل مستقل.
خط ترميز الأحادي (One hot Encoding)
إن أبسط طريقة لتعيين المتغيرات الفئوية مع ضمان استقلالية المتغيرات هي خط الترميز الأحادي . في مثالنا ، سيتم تحويل متغير الإدخال الفئوي إلى متجه سمة ثلاثية العناصر باستخدام التعيين التالي:
| إدخال فئوي | سمة رقمية |
| الإنجليزية | [1.0 ، 0.0 ، 0.0] |
| الصينية | [0.0، 1.0، 0.0] |
| الألمانية | [0.0 ، 0.0 ، 1.0 |
يتطلب خط الترميز الأحادي منا معرفة مفردات المدخلات الفئوية مسبقًا. هنا ، تتكون المفردات من ثلاثة عملات (الإنجليزية والصينية والألمانية) ، وطول السمة الناتجة هو حجم هذه المفردات.
في بعض الحالات ، قد يكون من المفيد التعامل مع إدخال عددي على أنه فئوي وتعيينه إلى عمود خط الترميز الأحادي :
- عندما يكون الإدخال العددي عبارة عن فهرس
على سبيل المثال ، إذا كنا نحاول التنبؤ بمستويات حركة المرور وكان أحد إدخالاتنا هو يوم الأسبوع ، فيمكننا التعامل مع يوم الأسبوع على أنه رقم (1 ، 2 ، 3 ، … ، 7) ، ولكن من المفيد أدراك أن يوم الأسبوع هنا ليس مقياسًا مستمرًا ولكنه في الحقيقة مجرد مؤشر.
من الأفضل التعامل معه على أنه فنة (الأحد ، الاثنين ، … ، السبت) لأن الفهرسة عشوائية. هل يجب أن يبدأ الأسبوع يوم الأحد (كما في الولايات المتحدة) أم الاثنين (كما في فرنسا) أم السبت (كما في مصر)؟
- عندما تكون العلاقة بين المدخلات والتسمية غير مستمرة
ما يجب أن يقلب الميزان نحو التعامل مع يوم من أيام الأسبوع كسمة فئوية هو أن مستويات حركة المرور يوم الجمعة لا تتأثر بمستويات يومي الخميس والسبت.
- عندما يكون من المفيد تجميع المتغير الرقمي
في معظم المدن ، تعتمد مستويات حركة المرور على ما إذا كانت عطلة نهاية الأسبوع ، ويمكن أن يختلف ذلك حسب الموقع . سيكون من المفيد بعد ذلك التعامل مع يوم من أيام الأسبوع كسمة منطقية (عطلة نهاية الأسبوع أو أيام الأسبوع).
مثل هذا التعيين حيث يكون عدد المدخلات المسماة (هنا ، سبعة) أكبر من عدد قيم السمات المسماة (هنا ، اثنان) يسمى تجميع (bucketing ).
بشكل عام ، يتم إجراء التجميع من حيث النطاقات – على سبيل المثال ، قد نقوم بتجميع عمر الأم في نطاقات عند 20 ، 25 ، 30 ، وما إلى ذلك ، ونعامل كل من هذه الحاويات على أنها فئوية ، ولكن يجب إدراك أن هذا يفقد الطبيعة الترتيبية من عمر الأم.
- عندما نريد أن نتعامل مع القيم المختلفة للإدخال العددي على أنها مستقلة عندما يتعلق الأمر بتأثيرها على المسمى
على سبيل المثال ، يعتمد وزن الطفل على التعددية للولادة لأن التوائم والثلاثة توائم يميلون إلى أن يكون وزنهم أقل من الولادات الفردية.
لذا ، فإن الطفل الأقل وزنًا ، إذا كان جزءًا من ثلاثة توائم ، قد يكون أكثر صحة من طفل توأم له نفس الوزن. في هذه الحالة ، قد نقوم بتعيين التعددية إلى متغير فئوي ، نظرًا لأن المتغير الفئوي يسمح للنموذج بتعلم معايير قابلة للضبط مستقلة للقيم المختلفة للتعددية.
بالطبع ، لا يمكننا القيام بذلك إلا إذا كان لدينا أمثلة كافية من التوائم و الثلاثة توائم في مجموعة البيانات الخاصة بنا.
مجموعة المتغيرات التصنيفية
في بعض الأحيان ، تكون بيانات الإدخال عبارة عن مجموعة من الفئات. إذا كانت المصفوفة ذات طول ثابت ، فيمكننا التعامل مع كل موضع مصفوفة كسمة منفصلة. لكن في كثير من الأحيان ، ستكون المصفوفة متغيرة الطول. على سبيل المثال ، قد يكون أحد مدخلات نموذج الولادة هو نوع الولادات السابقة لهذه الأم:
[تحفيزي ، تحفيزي، طبيعي ، قيصري]من الواضح أن طول هذه المجموعة سيختلف في كل صف لأن هناك أعدادًا مختلفة من الأشقاء الأكبر سنًا لكل طفل.
تتضمن المصطلحات الشائعة للتعامل مع مصفوفات المتغيرات الفئوية ما يلي:
- حساب عدد تكرارات كل بند من المفردات. لذلك ، سيكون التمثيل في مثالنا هو [2 ، 1 ، 1] بافتراض أن المفردات تحفيزي وطبيعي وقيصري (بهذا الترتيب). هذه الآن مصفوفة ذات طول ثابت من الأرقام التي يمكن تسويتها واستخدامها بترتيب موضعي. إذا كان لدينا مصفوفة حيث يمكن أن يحدث العنصر مرة واحدة فقط (على سبيل المثال ، اللغات التي يتحدثها الشخص) ، أو إذا كانت السمة تشير فقط إلى الوجود وليس العد (مثل ما إذا كانت الأم قد خضعت لعملية قيصرية من قبل) ، فسيتم حساب الترقيم في كل موضع أما 0 أو 1 ، وهذا ما يسمى خط الترميز المتعدد (multi-hot encoding).
- لتجنب الأعداد الكبيرة ، يمكن استخدام التردد النسبي بدلاً من العد. سيكون التمثيل لمثالنا [0.5 ، 0.25 ، 0.25] بدلاً من [2 ، 1 ، 1]. المصفوفات الفارغة (الأطفال المولودون لأول مرة بدون أشقاء سابقين) يتم تمثيلها كـ [0 ، 0 ، 0]. في معالجة اللغة الطبيعية ، يتم تسوية التردد النسبي للكلمة بشكل عام عن طريق التكرار النسبي للوثائق التي تحتوي على الكلمة لإنتاج TF-IDF . يعكس TF-IDF مدى تميز الكلمة في المستند.
- إذا تم ترتيب المصفوفة بطريقة معينة (على سبيل المثال ، بالترتيب الزمني) ، فتمثل مصفوفة الإدخال حسب العناصر الثلاثة الأخيرة. المصفوفات الأقصر من ثلاثة يتم حشوها.
- تمثيل المصفوفة بإحصاءات مجمعة ، على سبيل المثال ، طول المصفوفة ، الوضع (الإدخال الأكثر شيوعًا) ، الوسيط ، النسبة المئوية 10/20 / … إلخ.
من بين هؤلاء ، فإن مصطلح التعداد/ التردد النسبي (counting/relative-frequency) هو الأكثر شيوعًا. لاحظ أن كلا الأمرين عبارة عن تعميم لترميز الخط الأحادي (one-hot encoding) – إذا لم يكن للطفل أشقاء أكبر سنًا ، فسيكون التمثيل [0 ، 0 ، 0] ، وإذا كان لدى الطفل شقيق واحد أكبر منه ولد في ولادة طبيعية ، سيكون التمثيل [0 ، 1 ، 0].













إضافة تعليق