
عندما يتعلق الأمر بالصور ، فقد تم تحقيق الكثير في السنوات القليلة الماضية.يتقدم التبصير الحاسوبي بسرعة كبيرة ، ويبدو أن العديد من المشاكل المتعلقة به أصبحت الآن أسهل في الحل. مع ظهور النماذج مسبقة التدريب ورخص الحوسبة ، أصبح من السهل الآن تدريب نموذج قريب من أحدث التقنيات في المنزل لمعظم المشكلات المتعلقة بالصور.
لكن هناك أنواعًا مختلفة من مشكلات الصورمن التصنيف القياسي للصور في فئتين أو أكثر إلى القيادة الذاتية. لن نتظرق إلى القيادة الذاتيه في هذا المقال ، ولكننا سنتعامل مع بعض أكثر مشكلات الصور شيوعًا.
ما هي الأساليب المختلفة التي يمكننا تطبيقها على الصور؟ الصورة ليست سوى مصفوفة من الأرقام. الكمبيوتر لا يرى الصور كما يراها البشر. بل يبظر فقط إلى الأرقام ، وهذا ما هي الصور.
الصورة ذات التدرج الرمادي هي مصفوفة ثنائية الأبعاد بقيم تتراوح من 0 إلى 255. 0 أسود ، 255 أبيض وبينهما كل ظلال الرمادي. في السابق ، عندما لم يكن هناك تعلم عميق (أو عندما لم يكن التعلم العميق شائعًا) ، اعتاد الناس النظر إلى النقطة الضوئية (البكسل). كانت كل نقطة ضوئية عبارة عن سمة. يمكنك القيام بذلك بسهولة في بايثون. ما عليك سوى قراءة الصورة ذات التدرج الرمادي باستخدام OpenCV أو Python-PIL ، وتحويلها إلى مصفوفة عددية ورفرف (تسوية) المصفوفة. إذا كنت تتعامل مع صور RGB ، فلديك ثلاث مصفوفات بدلاً من واحدة. لكن الفكرة لا تزال كما هي.
import numpy as np import matplotlib.pyplot as plt # توليد مصفوفة نمباي عشوائية بأرقام من صفر إلى 255 # وحجمه 256×256 random_image = np.random.randint(0, 256, (256, 256)) # تهيئة الرسم plt.figure(figsize=(7,7)) plt.imshow(random_image, cmap= 'gray', vmin=0, vmax=266)
يولد الكود أعلاه مصفوفة عشوائية باستخدام numpy. تتكون هذه المصفوفة من قيم تتراوح من 0 إلى 255 (مضمنة) وحجمها 256 × 256 (المعروف أيضًا باسم النقطة الضوئية).

كما ترى النسخة المسطحة ليست سوى متجه بالحجم M ، حيث M = N * N. في هذه الحالة ، تكون هذه المتجه بحجم 256 * 256 = 65536.
الآن ، إذا قمنا بذلك من أجل جميع الصور في مجموعة البيانات لدينا ، لدينا 65536 سمة لكل عينة. يمكننا الآن بناء نموذج شجرة قرار أو نموذج غابة عشوائية أو نموذج قائم على SVM بسرعة على هذه البيانات. ستنظر النماذج في قيم النقاط الضوئية وستحاول فصل العينات الموجبة عن العينات السلبية (في حالة وجود مشكلة تصنيف ثنائي).
مجموعة البيانات
لربما قد سمعت عن مشكلة القطط مقابل الكلاب. فهي كلاسيكيه. لكن دعونا نجرب شيئًا مختلفًا. إذا كنت تتذكر ، في بداية المقال الخاص بمقاييس التقييم ، فقد قدمت لك مجموعة بيانات لصور استرواح الصدر (مجموعة البيانات). لذا ، دعونا نحاول بناء نموذج لاكتشاف ما إذا كانت صورة الأشعة السينية للرئة بها استرواح الصدر أم لا. وهذا هو ، تصنيف ثنائي بسيط (أليس كذلك).

في الصورة أعلاه ، ترى مقارنة بين الصور بدون استرواح الصدر ومع استرواح الصدر. كما لاحظت بالفعل ، من الصعب جدًا على شخص غير خبير تحديد أي من هذه الصور به استرواح الصدر.
طريقة تعلم الألة
تتعلق مجموعة البيانات الأصلية باكتشاف مكان وجود استرواح الصدر بالضبط ، ولكننا قمنا بتعديل المشكلة لمعرفة ما إذا كانت صورة الأشعة السينية المعطاة بها استرواح الصدر أم لا. لا تقلق. سوف نغطي جزء الأين في مقال أخر . تتكون مجموعة البيانات من 10675 صورة فريدة و 2379 بها استرواح الصدر (لاحظ أن هذه الأرقام تأتي بعد تنظيف بعض البيانات وبالتالي لا تتطابق مع مجموعة البيانات الأصلية).
كما يقول طبيب البيانات: هذه حالة كلاسيكية لتصنيف ثنائي منحرف. لذلك ، نختار مقياس التقييم ليكون AUC و نستخدام تحقق الطيات كي الطبقي ( stratified k-fold cross-validation) .
يمكنك تسطيح السمات وتجربة بعض الطرق الكلاسيكية مثل SVM و RF لإجراء التصنيف ، وهو أمر جيد تمامًا ، لكنه لن يجعلك قريبًا من أحدث التقنيات. أيضا الصور بحجم 1024×1024. سيستغرق تدريب نموذج على مجموعة البيانات هذه وقتًا طويلاً. ولكن دعونا نحاول إنشاء نموذج غابة عشوائي بسيط على هذه البيانات. نظرًا لأن الصور ذات تدرج رمادي ، لا نحتاج إلى إجراء أي نوع من التحويل. سنقوم بتغيير حجم الصور إلى 256 × 256 لجعلها أصغر واستخدام AUC كمقياس كما ناقشنا من قبل.
دعونا نرى كيف يعمل هذا.
import os
import numpy as np
import pandas as pd
from PIL import Image
from sklearn import ensemble
from sklearn import metrics
from sklearn import model_selection
from tqdm import tqdm
def create_dataset(training_df, image_dir):
"""
تأخذ هذه الوظيفة إطار بيانات التدريب
و تخرج مجموعة التدريب والتسميات
: param training_df: dataframe مع ImageId ، الأعمدة المستهدفة
: param image_dir: موقع الصور (المجلد) ، السلسلة
: return: X، y (مجموعة تدريب مع سمات وتسميات)
"""
## إنشاء قائمة فارغة لتخزين متجهات الصور
images = []
## إنشاء قائمة فارغة لتخزين الأهداف
targets = []
# إنشاء حلقة على مجموعة البيانات
for index, row in tqdm (\
training_df.iterrows(),
total = len(training_df),
desc = "processing images"
):
# الحصول على معرفات الصور
image_id = row["ImageId"]
# إنشاء مسار الصورة
image_path = os.path.join(image_dir, image_id)
# PIL فتح الصور بإستخدام
image = Image.open(image_path + ".png")
# تغيير حجم الصورة إلى 256 × 256. نستخدم إعادة التشكيل ثنائية الخطوط
image = image.resize((256,256), resample=Image.BILINEAR)
# تحويل الصورة إلى مصفوفة
image = np.array(image)
# التسطيح
image = image.ravel()
# إلحاق الصور وقوائم الأهداف
images.append(image)
# تحويل قائمة قائمة الصور إلى مصفوفة عددية
images = np.array(images)
# طباعة حجم هذه المجموعة
print(images.shape)
return images, targets
if __name__ == "__main__":
csv_path = "/home/malawad/workspace/siim_png/train.csv"
image_path = "/home/malawad/workspace/siim_png/train.png"
#CSV قراءات ملفات الـ
df = pd.read_csv(csv_path)
# و نملئه بـ -1 kfold ننشأ عامود جديد نسميه
df["kflod"] = -1
## الخطوة التالية هي ترتيب صفوف البيانات بشكل عشوائي
df = df.sample(frac=-1).reset_index(drop=True)
# الحصول على التسميات
y = df.target.values
# kfold تهيئة فئة
kf = model_selection.StratifiedKFold(n_splits=5)
# ملئ العامود الجديد
for f, (t_,v_) in enumerate(kf.split(X=df, y=y)):
df.loc[v_, 'kfold'] = f
# نمر على الطيات المنشأه
for fold_ in range(5):
# إطار بيانات موقت من أجل التدريب و الإختبار
train_df = df[df.kfold != fold_].reset_index(drop=True)
test_df = df[df.kfold == fold_].reset_index(drop=True)
# إنشاء تدريب مجموعة البيانات
# يمكنك نقل هذا إلى الخارج لتوفير بعض الوقت الحسابي
xtrain, ytrain = create_dataset(train_df, image_path)
# إنشاء إختبار مجموعة البيانات
# يمكنك نقل هذا إلى الخارج لتوفير بعض الوقت الحسابي
xtest, ytest = create_dataset(test_df, image_path)
# مناسبة نموذج الغابة العشوائية من دون أي تغيير للمعايير
clf = ensemble.RandomForestClassifier(n_jobs=-1)
clf.train(xtrain, ytrain)
# التنبو
preds = clf.predict_proba(xtest)[:,1]
# طباعة النتائج
print(f"fold : {fold_}")
print(f"AUC = {metrics.roc_auc_score(ytest, preds)}")
print("")
هذا يعطي متوسط AUC بحوالي 0.72.
هذا ليس سيئًا ولكن نأمل أن نفعل ما هو أفضل بكثير. يمكنك استخدام هذا الأسلوب للصور ، و هذا ما كان يتم القيام به أيام زمان. كان SVM مشهورًا جدًا في مجموعات بيانات الصور. لقد أثبت التعلم العميق أنه الأفضل بلا منازع لحل مثل هذه المشكلات ، وبالتالي يمكننا تجربة ذلك بعد ذلك.
طريقة التعلم العميق
لن أخوض في تاريخ التعلم العميق ومن اخترع ماذا. بدلاً من ذلك ، دعنا نلقي نظرة على أحد أشهر نماذج التعلم العميق AlexNet ونرى ما يحدث هناك.

في الوقت الحاضر ، قد تقول إنها شبكة لف رياضي عصبية عميقة بسيطه، لكنها أساس العديد من الشبكات العميقة الحديثة(الشبكات العصبية العميقة). نرى أن الشبكة في الصورة أعلاه عبارة عن شبكة عصبية تلافيفية ذات خمس طبقات لف رياضي (إلتفافية ) و طبقتين كثيفتين وطبقة ناتجة. نرى أن هناك أيضًا تجميع أقصى (max pooling) .
هناك الكثير من المفاهيم في الشبكات العصبية التلافيفية والتعلم العميق.و لفهما يرجى قراءة هذا المقال. الآن ، نحن على استعداد للبدء في بناء أول شبكة عصبية تلافيفية في PyTorch. يوفر PyTorch طريقة بديهية وسهلة لتنفيذ الشبكات العصبية العميقة ، ولا تحتاج إلى الاهتمام بالانتشار العكسي (back-propagation) .
نحدد الشبكة في python class و دالة أمامية تخبر PyTorch بكيفية ارتباط الطبقات ببعضها البعض. في PyTorch ، تدوين الصورة هو BS ، C ، H ، W ، حيث BS هو حجم الحزم ، وC قنوات الصورة ، أما H هو الارتفاع و W هو العرض. دعونا نرى كيف يتم تنفيذ AlexNet في PyTorch.
import torch
import torch.nn as nn
import torch.nn.functional as F
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet,self).__init__()
#جزيئة اللف الرياضي
self.conv1 = nn.Conv2d(
in_channels=3,
out_channels=96,
kernel_size=11,
stride=4,
padding=0
)
self.pool = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv2 = nn.Conv2d(
in_channels=96,
out_channels=256,
kernel_size=5,
stride=1,
padding=2
)
self.pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
self.conv3 = nn.Conv2d(
in_channels=256,
out_channels=384,
kernel_size=3,
stride=1,
padding=1
)
self.conv4 = nn.Conv2d(
in_channels=384,
out_channels=256,
kernel_size=3,
stride=1,
padding=1
)
self.pool3 = nn.MaxPool2d(kernel_size=3, stride=2)
# جزئية الطبقة الكثيفة
self.fc1 = nn.Linear(
in_features=9216,
out_features=4096
)
self.dropout1 = nn.Dropout(0.5)
self.fc2 = nn.Linear(
in_features=4096,
out_features=4096
)
self.dropout2 = nn.Dropout(0.5)
self.fc3 = nn.Linear(
in_features=4096,
out_features=1000
)
def forward(self, image):
# احصل على حجم الحزمة والقنوات والارتفاع والعرض
# من حزمة إدخال الصور
#(BS، 3، 227، 227) : الحجم الأصلي
bs, c, h, w, = image.size()
x = F.relu(self.conv1(image)) # (bs, 96, 55, 55) :الحجم
x = self.pool1(x) # (bs, 96, 27, 27) :الحجم
x = F.relu(self.conv2(x)) # (bs, 256, 27, 27) :الحجم
x = self.pool2(x) # (bs, 256, 13, 13) :الحجم
x = F.relu(self.conv3(x)) # (bs, 384, 13, 13) :الحجم
x = F.relu(self.conv4(x)) # (bs, 256, 13, 13) :الحجم
x = self.pool3(x) # (bs, 256, 6, 6) :الحجم
x = x.view(bs, -1) # (bs, 9216) :الحجم
x = F.relu(self.fc1(x)) # (bs, 4096) :الحجم
x = self.dropout1(x) # (bs, 4096) :الحجم
# الإسقاط لا يغير الحجم
# يتم استخدام الإسقاط للتنظيم
# 0.3 التسرب يعني أن 70٪ فقط من العقد
# من الطبقة الحالية يتم إستخدامها في الطبقة التالية
x = F.relu(self.fc2(x)) # (bs, 4096) :الحجم
x = self.dropout2(x) # (bs, 4096) :الحجم
x = F.relu(self.fc3(x)) # (bs, 1000) :الحجم
# ImageNet الحجم 1000 هو عدد الفئات في مجموعة بيانات
x = torch.softmax(x, axis=1) # (bs, 1000) :الحجم
return x
عندما يكون لديك صورة حجمها 3 × 227 × 227 ، وتقوم بتطبيق مرشح لف رياضي بحجم 11 × 11 ، فهذا يعني أنك تقوم بتطبيق مرشح بحجم 11 × 11 × 3 وتحويله إلى صورة بحجم 227 × 227 × 3.
الآن ، تحتاج إلى التفكير في 3 أبعاد بدلاً من 2. عدد قنوات الإخراج هو عدد المرشحات التلافيفية المختلفة من نفس الحجم المطبقة على الصورة بشكل فردي. لذلك ، في الطبقة التلافيفية الأولى ، تكون قنوات الإدخال 3 ، وهي المدخل الأصلي ، أي قنوات R و G و B. تقدم torchvision من PyTorch العديد من النماذج المختلفة مثل AlexNet ، ويجب ملاحظة أن تطبيق AlexNet هذا يختلف عن تطبيق torchvision. تطبيق Torchvision لـ AlexNet هو AlexNet معدلة من ورقة أخرى (هنا ) .
يمكنك تصميم الشبكات العصبية التلافيفية الخاصة بك لأداء مهمة معية ، وفي كثير من الأحيان يكون من الجيد أن تبدأ شيء ما بمفردك. دعونا نبني شبكة لتصنيف الصور من مجموعة بياناتنا إلى فئتين إما مصابة باسترواح الصدر أم لا.
إنشاء ملف الطيات
لكن أولاً ، دعونا نجهز بعض الملفات . ستكون الخطوة الأولى هي إنشاء ملف الطيات ، أي train.csv لكن بعمود جديد kfold. سنبني خمسة طيات. (سبق و قمنا بهذا في مقالة التحقق المتقاطع )بالنسبة للشبكات العصبية المبنية على PyTorch ، نحتاج إلى إنشاء فئة مجموعة بيانات. الهدف من فئة مجموعة البيانات هو إرجاع عنصر أو عينة من البيانات. يجب أن تحتوي هذه العينة على كل ما تحتاجه لتدريب نموذجك أو تقييمه.
import torch
import numpy as np
from PIL import Image
from PIL import ImageFile
# في بعض الأحيان ، سيكون لديك صور بدون بت نهائي
# هذا يعتني بهذا النوع من الصور (الفاسدة)
ImageFile.LOAD_TRUNCATED_IMAGES = True
class ClassificationDataset:
"""
فئة مجموعة بيانات تصنيف عامة يمكنك استخدامها لجميع
أنواع مشاكل تصنيف الصور. فمثلا،
تصنيف ثنائي ، تصنيف متعدد الفئات ، متعدد التسميات
"""
def __init__(
self,
image_paths,
targets,
resize=None,
augmentations=None ):
"""
: param image_paths: قائمة المسار إلى الصور
: param target: مصفوفة نمباي
: param resize: tuple، على سبيل المثال (256 ، 256) ، يغير حجم الصورة إذا لم يكن لا شيء
: param augmentations: تعزيز
"""
self.image_paths = image_paths
self.targets = targets
self.resize = resize
self.augmentations = augmentations
def __len__(self):
"""
إرجاع العدد الإجمالي للعينات في مجموعة البيانات
"""
return len(self.image_paths)
def __getitem__(self, item):
"""
لفهرس "عنصر" معين ، قم بإرجاع كل ما نحتاج إليه
لتدريب نموذج معين
"""
# PIL فتح الصورة بإستخدام
image = Image.open(self.image_paths[item])
# RGB تحويل الصورة إلى
image = image.convert("RGB")
# الحصول على الأهداف الصحيحة
targets = self.targets[item]
# تغيير الحجم إذاإحتجنا
if self.resize is not None:
image= image.resize(
(self.resize[1], self.resize[0]),
resample=Image.BILINEAR
)
# تحويل الصورة إلى مصفوفة نمباي
image = np.array(image)
if self.augmentations is not None:
augmeted = self.augmentations(image=image)
image = augmeted["image"]
# pytorch expects CHW instead of HWC
image = np.transpose(image, (2,0,1)).astype(np.float32)
# إرجاع تنسور للصورة والأهداف
# الق نظرة على الأنواع!
# لمهام الانحدار ،
#torch.float سيتغير نوع الأهداف إلى
return{
"image" : torch.tensor(image, dtype=torch.float),
"target": torch.tensor(targets, dtype=torch.long)
}
الآن نحن بحاجة إلى engine.py بحيث يكون لديه وظائف التدريب والتقييم. دعونا نرى كيف يبدو engine.py.
import torch
import torch.nn as nn
from tqdm import tqdm
def train(data_leader, model, optimizer, device):
"""
"""
# نضع النموذج في وضع التدريب
model.train()
#نمر على كل حزمة في محمل البيانات
for data in data_leader:
# تذكر أن لدينا صور و أهداف في مجموعة البيانات
inputs = data["image"]
targets = data["targets"]
# ننقل المدخلات و الأهداف إلى معالج الرسومات أو المعالج المركيز
inputs = inputs.to(device, dtype=torch.float)
targets = targets.to(device, dtype=torch.float)
# zero grad المحسن
optimizer.zero_grad()
# نقوم بالخطوة الأمامية للنموذج
outputs = model(inputs)
# حساب الخسارة
loss = nn.BCEWithLogitsLoss()(outputs, targets.view(-1, 1))
#حساب خطوة الخسارة الرجعية
loss.backward()
#خطوة التحسين
optimizer.step()
def evaluate(data_loader, model, device):
"""
"""
# نضع النموذج في وضع التحقق
model.eval()
# تهيئة القوائم لحفظ المخرجات و الأهداف
final_targets = []
final_output = []
#no_grad نستخدم
with torch.no_grad():
for data in data_loader:
inputs = data["image"]
targets = data["targets"]
inputs = inputs.to(device, dtype=torch.float)
output = model(inputs)
#تحويل الأهداف و المخرجات من القوائم
targets = targets.detach().cpu().numpy().tolist()
output = output.detach().cpu().numpy().tolist()
# تمديد القائمة الأصلية
final_targets.extend(targets)
final_output.extend(output)
return final_output, final_targets
شبكة أليكس نت
بمجرد أن نحصل على engine.py ، نكون مستعدين لإنشاء ملف جديد: model.py. سيتألف الملف من نموذجنا. إنها لفكرة جيدة أن تُبقيها منفصلة لأن ذلك يتيح لنا تجربة نماذج مختلفة وبنيات مختلفة بسهولة. تحتوي مكتبة PyTorch المسماة pretrainedmodels على الكثير من المعماريات لنماذج مختلفة ، مثل AlexNet و ResNet و DenseNet وما إلى ذلك. هناك نماذج معمارية مختلفة تم تدريبها على مجموعة بيانات صور كبيرة تسمى ImageNet. يمكننا استخدامها مع أوزانها بعد التدريب على ImageNet ، ويمكننا أيضًا استخدامها بدون هذه الأوزان. إذا تدربنا بدون أوزان ImageNet ، فهذا يعني أن شبكتنا تتعلم كل شيء من البداية. هذا ما يبدو عليه model.py.
import torch.nn as nn
import pretrainedmodels
def get_model(pretrained):
if pretrained:
model = pretrainedmodels.__dict__["alexnet"](
pretrained='imagenet'
)
else:
model = pretrainedmodels.__dict__["alexnet"](
pretrained=None
)
# إطبع النموذج هنا لترى ما يحدث
model.last_linear = nn.Sequential(
nn.BatchNorm1d(4096),
nn.Dropout(p=0.25),
nn.Linear(in_features=4096, out_features=2048),
nn.ReLU(),
nn.BatchNorm1d(2048, eps=1e-05, momentum=0.1),
nn.Dropout(p=0.5),
nn.Linear(in_features=2048, out_features=1)
)
return model
إذا قمت بطباعة النموذج النهائي ، فستتمكن من رؤية شكله:
AlexNet( (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (_features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (dropout0): Dropout(p=0.5, inplace=False) (linear0): Linear(in_features=9216, out_features=4096, bias=True) (relu0): ReLU(inplace=True) (dropout1): Dropout(p=0.5, inplace=False) (linear1): Linear(in_features=4096, out_features=4096, bias=True) (relu1): ReLU(inplace=True) (last_linear): Sequential( (0): BatchNorm1d(4096, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (1): Dropout(p=0.25, inplace=False) (2): Linear(in_features=4096, out_features=2048, bias=True) (3): ReLU() (4): BatchNorm1d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True) (5): Dropout(p=0.5, inplace=False) (6): Linear(in_features=2048, out_features=1, bias=True) ) )
الآن ، لدينا كل شيء ، ويمكننا البدء في التدريب. سنفعل ذلك باستخدام train.py.
from itertools import Predicate
from math import sinh
import os
from numpy.core.fromnumeric import resize
import pandas as pd
import numpy as np
import albumentations
import torch
from sklearn import metrics
from sklearn.model_selection import train_test_split
import dataset
import engine
from model import get_model
if __name__=="__main__":
# موقع ملفات البيانات
data_path = "/home/malawad/workspace/siim_png/"
device = "cuda"
# لندرب لمدة عشرة عهد
epochs = 100
#تحميل إطار البيانات
df = pd.read_csv(os.path.join(data_path, "train.csv"))
# الحصول على معرفات الصورة
images = df.ImageId.values.tolist()
# قائمة بمواقع الصور
images = [
os.path.join(data_path, "train_png", i + ".png") for i in images
]
# الأهداف الثنائية لمصفوفة نمباي
targets = df.target.values
# إحضار النموذج ، سنحاول كلاهما تم المدرب مسبقاً
# و الأوزان الغير مدربة مسبقاً
model = get_model(pretrained=True)
#Device نقل النموذج إلى
model.to(device)
# imagenet بالنسبة لمجموعة بيانات RGB لقنوات std و mean قيم
# imagenet سنستخدم القيم المحسوبة مسبقا للأوزان من
mean = (0.4585, 0.456, 0.406)
std = (0.229, 0.224, 0.225)
# هي مكتبة لتعزيز الصور albumentations
# هنا نستخدم التسوية
aug = albumentations.Compse(
[
albumentations.Normalize(
mean, std, max_pixel_value=255.0, always_apply=True
)
]
)
# train_test_split سنستخدم kfold عوضا عن إستخدام
train_images, valid_images, train_targets, valid_targets = train_test_split(
images, targets, stratify=targets, random_state=42
)
#ClassificationDataset الحصول على فئة
train_dataset = dataset.ClassificationDataset(
image_paths = train_images,
targets = train_targets,
resize=(227, 227),
augmentations=aug,
)
# محمل البيانات لتورش سيقوم بإنشاء حزم بيانات
# من فئة تصنيف حزمة البيانات
train_loader = torch.utils.data.DataLoader(
train_dataset,batch_size=16,shuffle=True, num_workers=4
)
# نقس الشئ لبيانات التحقق
valid_dataset = dataset.ClassificationDataset(
image_paths=valid_images,
targets = valid_targets,
resize=(227,227),
augmentations=aug
)
valid_loader = torch.utils.data.DataLoader(
train_dataset,batch_size=16,shuffle=False, num_workers=4
)
# نستخدم تحسين أدام
optimizer = torch.optim.Adam(model.parameters(), lr=5e-4)
# لكل الحزم Aug تدريب و طباعة نتيجة
for epoch in range(epochs):
engine.train(train_loader, model, optimizer,device=device)
predictions, valid_targets = engine.evaluate(
valid_loader, model, device=device
)
roc_auc = metrics.roc_auc_score(valid_targets, predictions)
print(
f"Epoch = {epoch}, Valid Roc Auc={roc_auc}"
)
دعونا ندربها بدون أوزان مدربة مسبقاً:
Epoch=0, Valid ROC AUC=0.5737161981475328 Epoch=1, Valid ROC AUC=0.5362868001588292 Epoch=2, Valid ROC AUC=0.6163448214387008 Epoch=3, Valid ROC AUC=0.6119219143780944 Epoch=4, Valid ROC AUC=0.6229718888519726 Epoch=5, Valid ROC AUC=0.5983014999635341 Epoch=6, Valid ROC AUC=0.5523236874306134 Epoch=7, Valid ROC AUC=0.4717721611306046 Epoch=8, Valid ROC AUC=0.6473408263980617 Epoch=9, Valid ROC AUC=0.6639862888260415
AUC هنا حوالي 0.66 وهو أقل من نموذج الغابة العشوائية لدينا. ماذا يحدث عندما نستخدم الأوزان الجاهزة؟
Epoch=0, Valid ROC AUC=0.5730387429803165 Epoch=1, Valid ROC AUC=0.5319813942934937 Epoch=2, Valid ROC AUC=0.627111577514323 Epoch=3, Valid ROC AUC=0.6819736959393209 Epoch=4, Valid ROC AUC=0.5747117168950512 Epoch=5, Valid ROC AUC=0.5994619255609669 Epoch=6, Valid ROC AUC=0.5080889443530546 Epoch=7, Valid ROC AUC=0.6323792776512727 Epoch=8, Valid ROC AUC=0.6685753182661686 Epoch=9, Valid ROC AUC=0.6861802387300147
AUC أفضل الآن. ومع ذلك ، فإنه لا يزال أقل. الشيء الجيد في النماذج الجاهزة هو أنه يمكننا تجربة العديد من النماذج المختلفة بسهولة. دعونا نحاول resnet18 بأوزان مدربة مسبقاً.
شبكة ريزنت
import torch.nn as nn
import pretrainedmodels
def get_model(pretrained):
if pretrained:
model = pretrainedmodels.__dict__["resnet18"](
pretrained='imagenet'
)
else:
model = pretrainedmodels.__dict__["resnet18"](
pretrained=None
)
# إطبع النموذج هنا لترى ما يحدث
model.last_linear = nn.Sequential(
nn.BatchNorm1d(512),
nn.Dropout(p=0.25),
nn.Linear(in_features=512, out_features=2048),
nn.ReLU(),
nn.BatchNorm1d(2048, eps=1e-05, momentum=0.1),
nn.Dropout(p=0.5),
nn.Linear(in_features=2048, out_features=1)
)
return model
عند تجربة هذا النموذج ، قمت أيضًا بتغيير حجم الصورة إلى 512 × 512 وأضفت جدولة معدل تعلم خطوة والذي يضاعف معدل التعلم بمقدار 0.5 بعد كل 3 حقب.
Epoch=0, Valid ROC AUC=0.5988225569880796 Epoch=1, Valid ROC AUC=0.730349343208836 Epoch=2, Valid ROC AUC=0.5870943169939142 Epoch=3, Valid ROC AUC=0.5775864444138311 Epoch=4, Valid ROC AUC=0.7330502499939224 Epoch=5, Valid ROC AUC=0.7500336296524395 Epoch=6, Valid ROC AUC=0.7563722113724951 Epoch=7, Valid ROC AUC=0.7987463837994215 Epoch=8, Valid ROC AUC=0.798505708937384 Epoch=9, Valid ROC AUC=0.8025477500546988
يبدو أن هذا النموذج يعمل بشكل أفضل. ومع ذلك ، قد تتمكن من ضبط المعايير المختلفة وحجم الصورة في AlexNet للحصول على درجة أفضل. سيؤدي استخدام التعزيز إلى تحسين النتيجة بشكل أكبر.
يعد تحسين الشبكات العصبية العميقة أمرًا صعبًا ولكنه ليس مستحيلًا. اختر مُحسِّن آدم ، واستخدم معدل تعلم منخفضًا ، وقلل معدل التعلم كلما تصل خسارة التحقق لدرجة لا يقل فيها ، وجرب بعض التعزيزات ، وجرب المعالجة المسبقة للصور (على سبيل المثال ، القص إذا لزم الأمر ، يمكن اعتبار ذلك أيضًا معالجة مسبقة) ، وتغيير حجم الدفعة ، وما إلى ذلك الكثير مما يمكنك فعله لتحسين شبكتك العصبية العميقة.
ResNet هي بنية أكثر تعقيدًا مقارنةً بـ AlexNet. تشير ResNet إلى الشبكة العصبية المتبقية (Residual Neural Network) و تم تقديمها في هذه الورقة البحثية عام 2015.
تتكون شبكة ResNet من الكتل المتبقية (residual blocks) التي تنقل المعرفة من طبقة واحدة للمزيد من الطبقات عن طريق تخطي بعض الطبقات بينهما. تُعرف هذه الأنواع من اتصالات بين الطبقات باسم وصلات التخطي (skip-connections) نظرًا لأننا نتخطى طبقة واحدة أو أكثر.
تساعد وصلات التخطي في مشكلة تلاشي الإشتقاقات عن طريق نقل الإشتقاقات إلى طبقات أخرى. هذا يسمح لنا بتدريب شبكات اللف الرياضي العصبية الكبيرة جدًا دون فقدان الأداء. عادة ، تزداد خسارة التدريب في نقطة معينة إذا كنا نستخدم شبكة عصبية كبيرة ، ولكن يمكننا منع ذلك باستخدام وصلات التخطي.
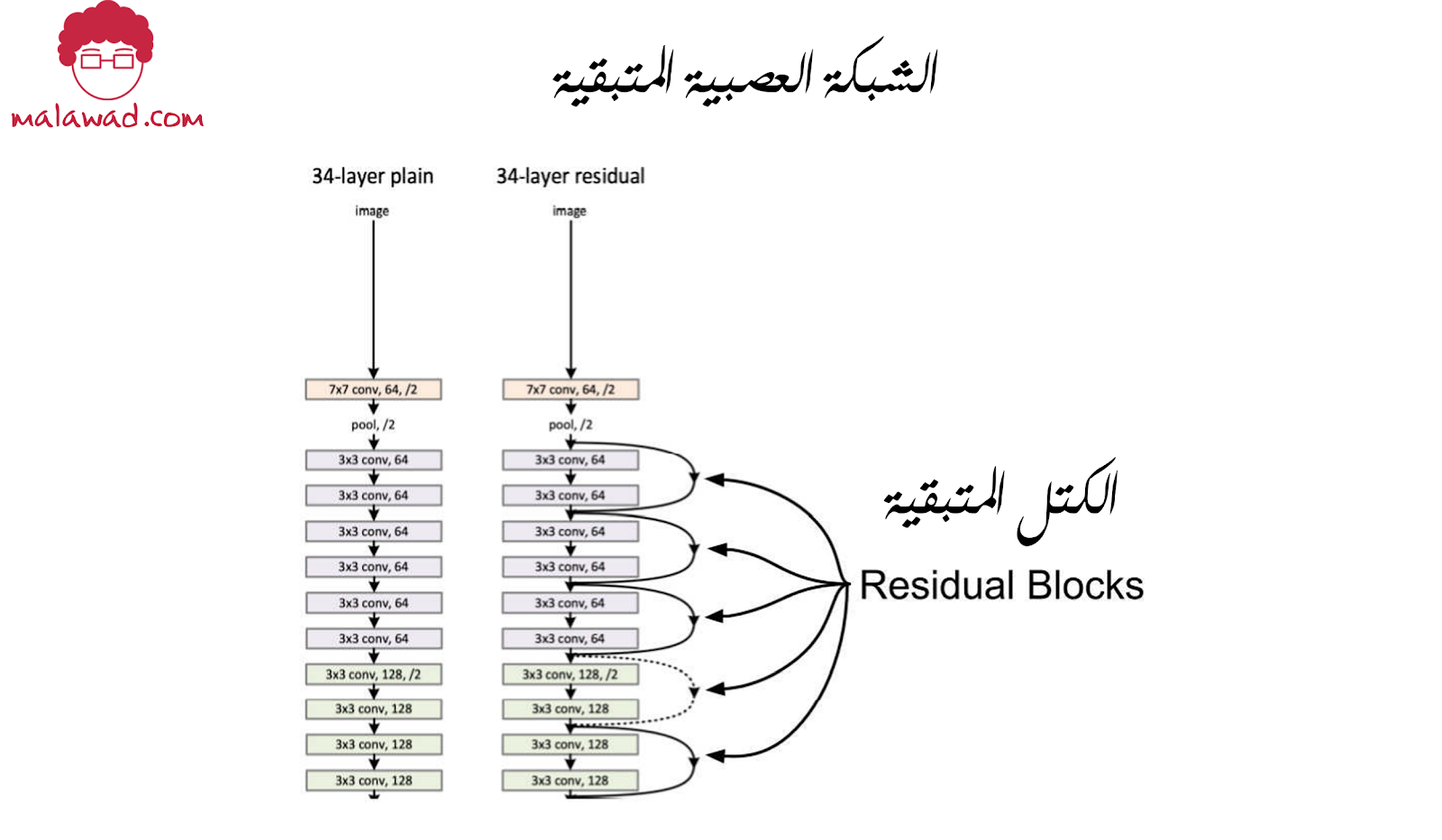
الكتلة المتبقية سهلة الفهم. تأخذ الإخراج من طبقة ، وتتخطى بعض الطبقات وتضيف هذا الإخراج إلى طبقة أخرى في الشبكة. تعني الخطوط المنقطة أن شكل الإدخال يحتاج إلى تعديل حيث يتم استخدام التجميع الأقصى (max-pooling) واستخدام التجميع الأقصى يغير حجم الإخراج.
تأتي شبكة ResNet بالعديد من الأشكال المختلفة: 18 و 34 و 50 و 101 و 152 طبقة وكلها متوفرة بأوزان مدربة مسبقًا على مجموعة بيانات ImageNet. تعمل النماذج التي تم تدريبها مسبقًا في هذه الأيام على كل شيء (تقريبًا) ولكن تأكد من البدء بنماذج أصغر ، على سبيل المثال ، ابدأ بـ resnet-18 بدلاً من resnet-50. تتضمن بعض نماذج ImageNet الأخرى المدربة مسبقًا ما يلي:
– Inception
– DenseNet (اختلافات مختلفة)
– NASNet
– PNASNet
– VGG
– Xception
– ResNeXt
– EfficientNet ، إلخ.
يمكن العثور على غالبية النماذج المدربة مسبقًا على غيتهاب هنا . فلنرى كيف يمكن استخدام نموذج تم تدريبه مسبقًا مثل هذا لمهمة التجزئة (segmentation task).
مهام التجزئة (segmentation task)
التجزئة مهمة شائعة جدًا في التبصير الحاسوبي. في مهمة تجزئة ، نحاول إزالة / عزل الأجسام من الخلفية. يمكننا أن نقول إنها مهمة تصنيف حسب البكسل حيث تتمثل مهمتك في تعيين فئة لكل بكسل في صورة معينة. مجموعة بيانات استرواح الصدر التي نعمل عليها هي في الواقع مهمة تجزئة. في هذه المهمة ، بالنظر إلى صور الأشعة السينية، نحن مطالبون بتقسيم استرواح الصدر. النموذج الأكثر شيوعًا المستخدم في مهام التجزئة هو U-Net.
شبكة يونت

تتكون المعمارية من جزأين: مشفر و مفكك. المشفر هو نفسه مثل أي شبكة لف رياضي رأيته حتى الآن. أما المفكك مختلف بعض الشيء. يتكون المفكك من طبقات اللف الرياضي التناقلية و التي تستخدم المرشحات التي عند تطبيقها على صورة صغيرة ، تخلق صورة أكبر.
في PyTorch ، يمكنك استخدام ConvTranspose2d لهذه العملية. دعونا نرى كيف يتم تنفيذ U-Net
import torch
import torch.nn as nn
from torch.nn import functional as F
def double_conv(in_channels, out_channels):
"""
هذه الوظيفة تقوم بتطبيق شبكتي لف رياضي
كل واحدة متبوعه بطبقة ريلو
:param in_channels: عدد الطبقات المدخلة
:param out_channels: عدد الطبقات المخرجة
:return: إخراج طبقة لف رياضي
"""
conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels,kernel_size=3),
nn.ReLU(inplace=True)
)
return conv
def crop_tensor(tensor, target_tensor):
"""
تقوم هذه الوظيفة بقص حجم التنسور لحجم معطأة
(bs , c, h, w) حجم التنسور هو
:param tensor: تنسور يحتاح لقص
:param target_tensor: الحجم المراد
:return:التنسور المقصصوص
"""
target_size = target_tensor.size()[2]
tensor_size = tensor.size()[2]
delta = tensor_size - target_size
delta = delta // 2
return tensor[
:,
:,
delta:tensor_size - delta ,
delta:tensor_size - delta
]
class UNet(nn.Module):
def __init__(self):
super(UNet, self).__init__()
self.max_pool_2x2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.down_conv_1 = double_conv(1, 64)
self.down_conv_2 = double_conv(64, 128)
self.down_conv_3 = double_conv(128, 256)
self.down_conv_4 = double_conv(256, 512)
self.down_conv_5 = double_conv(512, 1024)
self.up_trans_1 = nn.ConvTranspose2d(
in_channels=1024,out_channels=512,kernel_size=2,stride=2
)
self.up_conv_1 = double_conv(1024,512)
self.up_trans_2 = nn.ConvTranspose2d(
in_channels=512,out_channels=256,kernel_size=2,stride=2
)
self.up_conv_2 = double_conv(512, 256)
self.up_trans_3 = nn.ConvTranspose2d(
in_channels= 256,out_channels=128,kernel_size=2,stride=2
)
self.up_conv_3 = double_conv(256, 128)
self.up_trans_4 = nn.ConvTranspose2d(
in_channels= 128,out_channels=64,kernel_size=2,stride=2
)
self.up_conv_4 = double_conv(128, 64)
self.out = nn.Conv2d(
in_channels= 64,out_channels=2,kernel_size=1
)
def forward(self, image):
# المشفر
x1 = self.down_conv_1(image)
x2 = self.max_pool_2x2(x1)
x3 = self.down_conv_2(x2)
x4 = self.max_pool_2x2(x3)
x5 = self.down_conv_3(x4)
x6 = self.max_pool_2x2(x5)
x7 = self.down_conv_4(x6)
x8 = self.max_pool_2x2(x7)
x9 = self.down_conv_5(x8)
# المفكك
x = self.up_trans_1(x9)
y = crop_tensor(x7, x)
x = self.up_conv_1(torch.cat([x, y], axis=1))
x = self.up_trans_2(x)
y = crop_tensor(x5, x)
x = self.up_conv_2(torch.cat([x, y], axis=1))
x = self.up_trans_3(x)
y = crop_tensor(x3, x)
x = self.up_conv_3(torch.cat([x, y], axis=1))
x = self.up_trans_4(x)
y = crop_tensor(x1, x)
x = self.up_conv_4(torch.cat([x, y], axis=1))
out = self.out(x)
return out
if __name__== "__main__":
image = torch.rand((1, 1, 572, 572))
model = UNet()
print(model(image))
يرجى ملاحظة أن تنفيذ U-Net الذي عرضته أعلاه هو التنفيذ الأصلي لورقة U-Net. هناك العديد من الاختلافات التي يمكن العثور عليها على الإنترنت. يفضل البعض استخدام أخذ العينات الخطي الثنائي (bilinear sampling) بدلاً من طبقات اللف الرياضي التناقلية في جزئية التكبير ، ولكن هذا ليس التنفيذ الحقيقي للورقة. ومع ذلك ، قد ينتج عنه أداء أفضل.
في التطبيق الأصلي الموضح أعلاه ، توجد صورة بقناة واحدة بها قناتان في الإخراج: واحدة للمقدمة (foreground) والأخرى للخلفية(background). كما ترى ، يمكن تخصيص هذا لأي عدد من الفئات وأي عدد من قنوات الإدخال بسهولة بالغة. يختلف حجم صورة الإدخال عن حجم صورة الإخراج في هذا التنفيذ لأننا نستخدم طبقات لف رياضي بدون حشو. نرى أن جزء المشفر من U-Net ليس سوى شبكة تلافيفية بسيطة.
يمكننا ، بالتالي ، استبدال هذا بأي شبكة مثل ResNet. يمكن أيضًا إجراء الاستبدال بأوزان المدربة مسبقا. وبالتالي ، يمكننا استخدام مشفر قائم على ResNet والذي تم تدريبه مسبقًا على ImageNet و مفكك عام. بدلاً من ResNet ، يمكن استخدام العديد من معماريات الشبكات المختلفة.
نماذج التجزئة Pytorch بواسطة Pavel Yakubovskiy هو تنفيذ للعديد من هذه الاختلافات حيث يمكن استبدال المشفر بنموذج تم اختباره مسبقًا.( من هنا )
U-Net مبنية على ResNet
دعنا نطبق U-Net مبنية على ResNet لمشكلة اكتشاف استرواح الصدر.
يجب أن يكون لمعظم المشاكل مثل هذا مدخلين: الصورة الأصلية والقناع. في حالة وجود أجسام متعددة ، سيكون هناك أقنعة متعددة. في مجموعة بيانات استرواح الصدر لدينا ، يتم تزويدنا بـ RLE بدلاً من ذلك. RLE تعني ترميز طول التشغيل (Run length encoding) وهي طريقة لتمثيل الأقنعة الثنائية لتوفير المساحة.
لنفترض أن لدينا صورة إدخال وقناع مطابق. لنقم أولاً بتصميم فئة مجموعة بيانات تُخرج صورًا وصورة قناع. يرجى ملاحظة أننا سننشئ هذه البرامج النصية بطريقة يمكن تطبيقها على أي مشكلة تجزئة تقريبًا. مجموعة بيانات التدريب عبارة عن ملف CSV يتكون فقط من معرفات للصور وهي أيضًا أسماء ملفات.
import os
import glob
import torch
import numpy as np
import pandas as pd
from PIL import Image, ImageFile
from tqdm import tqdm
from collections import defaultdict
from torchvision import transforms
from albumentations import (
Compose,
OneOf,
RandomBrightness,
RandomGamma,
ShiftScaleRotate
)
ImageFile.LOAD_TRUNCATED_IMAGES = True
class SIIMDataset(torch.utils.data.Dataset):
def __init__(
self,
image_ids,
transform=True,
preprocessing_fn =None
):
"""
"""
# سننشى قاموس فارغ لحفظ الصور
self.data =defaultdict(dict)
# التعزيز
self.transform = transform
# وظيفة مسبقة المعالجة لتسوية الصور
self.preprocessing_fn = preprocessing_fn
# تعزيز الصور
# لدينا التحول و التكبير والتدوير
# مطبق باحتمال 80٪
# ثم لدينا جاما والسطوع / التباين
# يتم تطبيقه على الصورة
# الذي يعتني بالزيادة albumentation
# يتم تطبيقه على الصورة والقناع
self.aug = Compose(
[
ShiftScaleRotate(
shift_limit=0.0625,
scale_limit=0.1,
rotate_limit=10,
p=0.8
),
OneOf(
[
RandomGamma(
Gamma_limit=(90,110)
),
RandomBrightness(
Brightness_limit=0.1,
contrast_limit=0.1
),
],
),
]
)
# نمر على كل معرفات الصور
# لنخزن مسار الصور و القناع
for imgid in image_ids:
files = glob.glob(os.path.join(TRAIN_PATH, imgid, "*.png"))
self.data[counter] = {
"img_path" : os.path.join(
TRAIN_PATH, imgid + ".png"
),
"mask_path" : os.path.join(
TRAIN_PATH, imgid + "_mask.png"
),
}
def __len__(self):
return len(self.data)
def __getitem__(self, item):
# لفهرس عنصر معين ،
# نخرج الصورة وقناع الموترات
# قراءة مسارات الصور والقناع
img_path = self.data[item]["img_path"]
mask_path = self.data[item]["mask_path"]
#RGB قراءة الصورة و نحولها إلى
img = Image.open(img_path)
img = img.convert("RGB")
# تحويل الصورة إلى مصفوفة نمباي
img = np.array(img)
#قراءة قناع الصورة
mask = Image.open(mask_path)
mask = (mask >= 1).astype("float32")
#لو كان هذه بيانات التدريب فطبق التحويلات
if self.transform is True:
augmented = self.aug(image=img, mask=mask)
img = augmented["image"]
mask = augmented["mask"]
# معالجة مسبقة للصورة
# من أجل تسويتها
img = self.preprocessing_fn(img)
# إخراج الصور
return{
"image" : transforms.ToTensor()(img),
"mask" : transforms.ToTensor()(mask).float()
}
بما أن لدينا الفئة لمجموعة البيانات ؛ يمكننا إنشاء وظيفة تدريب .
import os
import sys
import torch
import numpy as np
import pandas as pd
import segmentation_models_pytorch as smp
import torch.nn as nn
import torch.optim as optim
from apex import amp
from collections import OrderedDict
from sklearn import model_selection
from tqdm import tqdm
from torch.optim import lr_scheduler
from dataset import SIIMDataset
# مسار ملف التدريب
TRAINING_CSV = "../input/train_pneumothorax.csv"
# حجم حزمة الإختبار و التدريب
TRAINING_BATCH_SIZE = 16
TEST_BATCH_SIZE = 4
# عدد الحقب
EPOCHS = 10
# تحديد المشفر ليونت
# لمعرفة كل المشفرات المتاحة من الرابط
# https://github.com/qubvel/segmentation_models.pytorch
ENCODER = "resnet18"
# سنستخدم الأوزان المدربة مسبقا لأجل أيماجنت
ENCODER_WEIGHTS = "imagenet"
# gpu التدريب على
DEVICE = "cuda"
def train(dataset, data_loader, model, criterion, optimizer):
"""
وظيفة التدريب لحقب واحد
:param dataset:(SIIMDataset) فئة مجموعة البيانات
:param data_loader: محمل حزم البيانات لتورش
:param model: النموذج
:param criterion: دالة الخسارة
:param optimizer: adam, sgd, etc.
"""
# نضع النموذج في وضع التدريب
model.train()
# حساب عدد الحزم
num_batches = int(len(dataset) / data_loader.batch_size)
# لتتبغ التقدم tqdm تهيئة
tk0 = tqdm(data_loader, total=num_batches)
# إنشاء حلقة على كل الحزم
for d in tk0:
# الحصول على الصور و الأقنعة
inputs = inputs.to(DEVICE, dtype=torch.float)
targets = targets.to(DEVICE, dtype=torch.float)
optimizer.zero_grad()
# الخطوة الأمامية للنموذج
outputs = model(inputs)
# حساب الخسارة
loss = criterion(outputs, targets)
# scaled loss context الخسارة الرجعية محسوبة على
# mixed precision بما أننا نستخدم تدريب
# لكن إذا لم نكن نستخدم ذلك فيقدورنا حذف السطرين القادمين
# loss.backward() و إستخدام
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
# خطوة المحسن
optimizer.step()
# tqdm إغلاق
tk0.close()
def evaluate(dataset, data_loader, model):
"""
وظيقة تقييم لحساب الخسارة على مجموعة التحقق
لحزمة واحدة
:param dataset:(SIIMDataset) فئة مجموعة البيانات
:param data_loader: محمل حزم البيانات لتورش
:param model: النموذج
"""
# نضع النموذج في وضع التحقق
model.eval()
# تهيئة الخسارة النهائية بصفر
final_loss = 0
#tqdm نحسب أرقام الحزم و نهيئ
num_batches = int(len(dataset) / data_loader.batch_size)
tk0 = tqdm(data_loader, total=num_batches)
# لتوفير الذاكرة نقوم بالتالي
with torch.no_grad():
for d in tk0:
inputs = d["image"]
targets = d["mask"]
inputs = inputs.to(DEVICE, dtype=torch.float)
targets = targets.to(DEVICE, dtype=torch.float)
output = model(inputs)
loss = criterion(output, targets)
# أضيف الخسارة إلى الخسارة النهائية
final_loss += loss
tk0.close()
# نخرج الخسارة المتوسطة لكل الحزم
return final_loss / num_batches
if __name__=="__main__":
#تحميل إطار البيانات
df = pd.read_csv(TRAINING_CSV)
# تقسيم البيانات إلى تدريب و تحقق
df_train, df_valid = model_selection.train_test_split(
df , random_state=42, test_size=0.1
)
#قائمة و مصفوفات التدريب و التحقق
training_images = df_train.image_id.values
validation_images = df_valid.image_id.values
# سنحصل على نموذج يونت من نماذج التجزئة
model = smp.Unet(
encoder_name = ENCODER,
encoder_weights = ENCODER_WEIGHTS,
classes = 1,
activation = None
)
# توفر نماذج التجزئة دالة معالجة مسبقة
# نقوم بتسوية الصور و ليس الأقنعة
prep_fn = smp.encoders.get_preprocessing_fn(
ENCODER,
ENCODER_WEIGHTS
)
#GPU نرسل النماذج
model.to(DEVICE)
# تهيئة بيانات التدريب
train_dataset = SIIMDataset(
training_images,
transform=True,
preprocessing_fn=prep_fn,
)
train_loader = torch.utils.data.DataLoader(
train_dataset,batch_size=TRAINING_BATCH_SIZE,shuffle=True,num_workers=12
)
# تهيئة بيانات التحقق
valid_dataset = SIIMDataset(
validation_images,
transform=False,
preprocessing_fn=prep_fn,
)
valid_loader = torch.utils.data.DataLoader(
valid_dataset,batch_size=TEST_BATCH_SIZE,shuffle=True,num_workers=4
)
criterion = nn.CrossEntropyLoss()
#سنستخدم محسن أدام
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
# نقلل مفدار التعلم عندما تتوقف الخسارة عن النقصان
Schaeduler = lr_scheduler.ReduceLROnPlateau(
optimizer, mode="min", patience=3, verbose=True
)
# wrap model and optimizer with NVIDIA's apex
# this is used for mixed precision training
model, optimizer = amp.initializer(
model, optimizer, opt_level="01", verbosity=0
)
#Gpu لو كان لدينا أكثر من
#يمكننا إستخدام الإثنين
if torch.cuda.device_count() > 1:
print(f"Let's use {torch.cuda.device_count()} GPUs!")
model = nn.DataParallel(model)
# بعض السجلات
print(f"Training batch size: {TRAINING_BATCH_SIZE}")
print(f"Test batch size: {TEST_BATCH_SIZE}")
print(f"Epochs: {EPOCHS}")
print(f"Image size: {IMAGE_SIZE}")
print(f"Number of training images: {len(train_dataset)}")
print(f"Number of validation images: {len(valid_dataset)}")
print(f"Encoder: {ENCODER}")
# إنشاء حلقة على كل الحقب
for epoch in range(EPOCHS):
print(f"Training Epoch: {epoch}")
# ألتدريب لحزمة واحدة
train(
train_dataset,
train_loader,
model,
criterion,
optimizer
)
print(f"Validation Epoch: {epoch}")
# حساب خسارة التحقق
val_log = evaluate(
valid_dataset,
valid_loader,
model
)
# خطوة المجدول
Schaeduler.step(val_log["log"])
print("\n")
في مشاكل التجزئة ، يمكنك استخدام مجموعة متنوعة من دوال الخسارة ، على سبيل المثال ، إنتروبيا متقاطعة ثنائية لكل البكسل (pixel-wise binary cross-entropy) ، وخسارة بؤرية (focal loss) وما إلى ذلك .
عندما تقوم بتدريب نموذج كهذا ، ستقوم بإنشاء نموذج يحاول التنبؤ بموقع استرواح الصدر ، كما هو موضح في الشكل أدناه. في الكود أعلاه ، استخدمنا تدريبًا مختلطًا بدقة باستخدام NVIDIA apex.














إضافة تعليق