
تصنيف النص محل اهتمام في عدد من التطبيقات ، بدءًا من إستخدامه في القرن التاسع عشر لتحديد مؤلف نص غير معروف إلى جهود USPS في الستينيات لإجراء للتعرف على العنواين. في التسعينيات ، بدأ الباحثون في تطبيق خوارزميات تعلم الألة بنجاح لتصنيف النص لمجموعات البيانات الكبيرة.
يعد تصفية البريد الإلكتروني ، المعروف باسم “تصنيف البريد العشوائي” ، واحدة من أقدم الأمثلة على التصنيف التلقائي للنص ، والذي يؤثر على حياتنا حتى يومنا هذا. من التحليلات اليدوية للمستندات النصية إلى الأساليب الإحصائية البحتة المعتمدة على الكمبيوتر والشبكات العصبية العميقة الحديثة ، قطعنا شوطًا طويلاً في تصنيف النص. دعونا نناقش بإيجاز بعض التطبيقات الشائعة قبل الغوص في الأساليب المختلفة لأداء تصنيف النص. ستكون هذه الأمثلة مفيدة أيضًا في تحديد المشكلات التي يمكن حلها باستخدام طرق تصنيف النص.
تصنيف وتنظيم المحتوى
يشير هذا إلى مهمة تصنيف / وضع علامات على كميات كبيرة من البيانات النصية. هذا ، بدوره ، يستخدم لدعم حالات الاستخدام مثل تنظيم المحتوى ومحركات البحث وأنظمة التوصية.
تتضمن أمثلة هذه البيانات مواقع الأخبار والمدونات و المكتبات الإلكترونية ومراجعات المنتجات والتغريدات وما إلى ذلك ؛ وضع علامات على أوصاف المنتج في موقع التجارة الإلكترونية ؛ توجيه طلبات خدمة العملاء في الشركة إلى فريق الدعم المناسب ؛ وتنظيم رسائل البريد الإلكتروني في صورة شخصية واجتماعية وعروض ترويجية في Gmail كلها أمثلة على استخدام تصنيف النص لتصنيف المحتوى وتنظيمه.
دعم العملاء
غالبًا ما يستخدم العملاء وسائل التواصل الاجتماعي للتعبير عن آرائهم وتجاربهم بشأن المنتجات أو الخدمات. غالبًا ما يُستخدم تصنيف النص لتحديد التغريدات التي يجب أن تستجيب لها العلامات التجارية (أي تلك التي يمكن اتخاذ إجراء بشأنها) وتلك التي لا تتطلب استجابة (أي الضوضاء) [هنا ، هنا]. للتوضيح ، ضع في اعتبارك التغريدات الثلاث حول العلامة التجارية Macy التي تظهر في الصورة أدناه.

على الرغم من أن جميع التغريدات الثلاثة تذكر صراحةً العلامة التجارية Macy ، إلا أن أول واحدة فقط تتطلب ردًا من فريق دعم العملاء في Macy.
التجارة الإلكترونية
يترك العملاء مراجعات لمجموعة من المنتجات على مواقع التجارة الإلكترونية مثل Amazon و eBay وما إلى ذلك. ومن الأمثلة على استخدام تصنيف النص في هذا النوع من السيناريو فهم وتحليل تصور العملاء لمنتج أو خدمة بناءً على تعليقاتهم. يُعرف هذا عمومًا باسم “تحليل المشاعر”. يتم استخدامه على نطاق واسع من قبل العلامات التجارية في جميع أنحاء العالم لفهم أفضل لما إذا كانوا يقتربون من عملائهم أو يبتعدون عنهم. بدلاً من تصنيف تعليقات العملاء على أنها ببساطة إيجابية أو سلبية أو محايدة ، على مدى فترة من الزمن ، تطور تحليل المشاعر إلى نموذج أكثر تعقيدًا: تحليل المشاعر القائم على “الجوانب”. لفهم هذا ، ضع في اعتبارك تقييم العميل للمطعم الموضح في أدناه.

هل تسمي المراجعة سلبية أم إيجابية أم محايدة؟ من الصعب الإجابة على هذا السؤال – كان الطعام رائعًا ، لكن الخدمة كانت سيئة. أدرك الممارسون والعلامات التجارية الذين يعملون في مجال تحليل المشاعر أن العديد من المنتجات أو الخدمات لها جوانب متعددة. من أجل فهم المشاعر العامة ، من المهم فهم كل جانب. يلعب تصنيف النص دورًا رئيسيًا في إجراء مثل هذا التحليل الدقيق لملاحظات العملاء.
تطبيقات أخرى
بصرف النظر عن المجالات المذكورة أعلاه ، يتم استخدام تصنيف النص أيضًا في العديد من التطبيقات الأخرى في مختلف المجالات:
- يتم استخدام تصنيف النص في تحديد اللغة ، مثل تحديد لغة التغريدات أو المنشورات الجديدة. على سبيل المثال ، لدى ترجمة Google ميزة التعرف التلقائي على اللغة.
- إسناد التأليف ، أو تحديد المؤلفين المجهولين للنصوص من مجموعة من المؤلفين ، هو حالة استخدام شائعة أخرى لتصنيف النص ، ويستخدم في مجموعة من المجالات من التحليل الجنائي إلى الدراسات الأدبية.
- تم استخدام تصنيف النص في الماضي القريب لترتيب المشاركات في منتدى الدعم عبر الإنترنت لخدمات الصحة العقلية [هنا]. في مجتمع معالجة اللغة الطبيعية ، تُجرى مسابقات سنوية (على سبيل المثال ، clpsych.org) لحل مشاكل تصنيف النص التي تنشأ من الأبحاث الطبية.
- موخراً ، تم إستخدام تصنيف النص أيضًا لفصل الأخبار الزائفة عن الأخبار الحقيقية.
خط إنتاج لبناء أنظمة تصنيف النص
في المقالات الثالث ، الرابع و الخامس من سلسة مقدمة في معالجة اللغة الطبيعية، ناقشنا بعض خطوط إنتاج معالجة اللغة الطبيعية الشائعة. يتشارك خط إنتاج تصنيف النص في بعض خطواته مع خطوط الإنتاج التي ذًكرت في هذه المقالات .
عادة ما يتبع المرء هذه الخطوات عند بناء نظام تصنيف النص:
- اجمع أو أنشئ مجموعة بيانات مصنفة مناسبة للمهمة.
- قسّم مجموعة البيانات إلى جزأين (تدريب واختبار) أو ثلاثة أجزاء: التدريب والتحقق (أي التطوير) ومجموعات الاختبار ، ثم حدد مقياس (مقاييس) التقييم.
- تحويل النص الخام إلى متجهات السمات.
- قم بتدريب المصنف باستخدام متجهات السمات والتسميات المقابلة من مجموعة التدريب.
- باستخدام مقياس (مقاييس) التقييم من الخطوة 2 ، قم بقياس أداء النموذج على مجموعة الاختبار.
- انشر النموذج لخدمة حالة الاستخدام الواقعية ومراقبة أدائه.

يتم تكرار الخطوات من 3 إلى 5 لاستكشاف المتغيرات المختلفة للسمات وخوارزميات التصنيف و معاييرها و معايرة مدخلات الضبط قبل الانتقال إلى الخطوة 6 ، ونشر النموذج الأمثل في الإنتاج.
قبل أن نبدأ في النظر في كيفية إنشاء مصنفات النص باستخدام خط الإنتاج الذي ناقشناه للتو ، دعنا نلقي نظرة على السيناريوهات التي لا يكون فيها خط الإنتاج هذا ضروريًا على الإطلاق أو حيث لا يكون من الممكن استخدامه.
مصنف بسيط بدون خط إنتاج تصنيف النص
عندما نتحدث عن خط إنتاج تصنيف النص ، فإننا نشير إلى سيناريو تعلم الألة الخاضع للإشراف. ومع ذلك ، من الممكن إنشاء مصنف بسيط بدون تعلم الآلة وبدون خط الإنتاج. ضع في اعتبارك سيناريو المشكلة التالي:
لقد حصلنا على مجموعة من التغريدات حيث يتم تصنيف كل تغريدة بالمشاعر المقابلة لها: سلبية أو إيجابية. على سبيل المثال ، تغريدة تقول ، “فيلم جيمس بوند الجديد رائع!” تعبر بوضوح عن شعور إيجابي ، في حين أن تغريدة تقول ، “لن أزور هذا المطعم مرة أخرى ، مكان فظيع !!” لديه شعور سلبي.
نريد بناء نظام تصنيف يتنبأ بمشاعر تغريدة غير مرئية باستخدام نص التغريدة فقط. يمكن أن يكون الحل البسيط هو إنشاء قوائم بالكلمات الإيجابية والسلبية باللغة الإنجليزية ، أي الكلمات التي لها مشاعر إيجابية أو سلبية.
ثم نقارن استخدام الكلمات الإيجابية مقابل الكلمات السلبية في تغريدة الإدخال ونقوم بالتنبؤ بناءً على هذه المعلومات. قد تتضمن التحسينات الإضافية لهذا النهج إنشاء قواميس أكثر تطوراً بدرجات من المشاعر الإيجابية والسلبية والحيادية للكلمات أو صياغة إرشادات محددة (على سبيل المثال ، يشير استخدام بعض الوجوه الضاحكة إلى المشاعر الإيجابية) واستخدامها لعمل تنبؤات. هذا النهج يسمى تحليل المشاعر القائم على المعجم (lexicon-based sentiment analysis) .
من الواضح أن هذا لا ينطوي على أي “تعلم” لتصنيف النص. أي أنها تستند إلى مجموعة من الأساليب التجريبية أو القواعد والموارد المصممة خصيصًا مثل قواميس الكلمات ذات المشاعر. في حين أن هذا النهج قد يبدو أبسط من أن يؤدي أداءً جيدًا بشكل معقول للعديد من سيناريوهات العالم الحقيقي ، إلا أنه قد يمكننا من نشر الحد الأدنى من المنتجات القابلة للتطبيق (minimum viable product) أو (MVP) بسرعة. الأهم من ذلك ، يمكن أن يؤدي هذا النموذج البسيط إلى فهم أفضل للمشكلة ويمنحنا خطًا أساسيًا بسيطًا لمقياس التقييم وسرعته.
استخدام واجهات برمجة التطبيقات (APIs) لمصنفات النص المتوفرة مسبقا
السيناريو الآخر الذي قد لا نضطر فيه إلى “تعليم” المصنف أو اتباع خط الأنابيب هذا هو عندما تكون مهمتنا أكثر عمومية بطبيعتها ، مثل تحديد فئة عامة للنص (على سبيل المثال ، ما إذا كان يتعلق بالتكنولوجيا أو الموسيقى). في مثل هذه الحالات ، يمكننا استخدام واجهات برمجة التطبيقات الحالية ، مثل Google Cloud Natural Language ، التي توفر نماذج تصنيف محتوى جاهزة يمكنها تحديد ما يقرب من 700 فئة مختلفة من النصوص. مهمة التصنيف الشائعة الأخرى هي تحليل المشاعر. يقدم جميع مزودي الخدمات الرئيسيين (على سبيل المثال ، Google و Microsoft و Amazon) واجهات برمجة تطبيقات لتحليل المشاعر بأسعار متفاوته. إذا تم تكليفنا ببناء مصنف المشاعر ، فقد لا نضطر إلى بناء نظامنا الخاص إذا كان الموجود يلبي احتياجات أعمالنا.
خط إنتاج واحد ، العديد من المصنفات
دعونا نلقي نظرة الآن على بناء مصنفات النص عن طريق تغيير الخطوات من 3 إلى 5 في خط الإنتاج والحفاظ على الخطوات المتبقية ثابتة. تعد مجموعة البيانات الجيدة شرطًا أساسيًا لبدء استخدام خط الإنتاج. عندما نقول مجموعة بيانات “جيدة” ، فإننا نعني مجموعة بيانات تمثل تمثيلًا حقيقيًا للبيانات التي من المحتمل أن نراها في الإنتاج.
سنستخدم مجموعة بيانات “Economic News Article Tone and Relevance” لتوضيح تصنيف النص. و تتألف من 8000 مقالة إخبارية مشروحة بما إذا كانت ذات صلة بالاقتصاد الأمريكي أم لا (أي تصنيف ثنائي نعم / لا). مجموعة البيانات غير متوازنة أيضًا ، مع حوالي 1500 مقال ذي صلة و 6500 مقال غير ذي صلة ، مما يشكل تحديًا للحماية من التحيز تجاه فئة الأغلبية (في هذه الحالة ، المقالات غير ذات الصلة). من الواضح أن معرفة ماهية المقالة الإخبارية ذات الصلة يعد أكثر صعوبة مع مجموعة البيانات هذه من معرفة ما هو غير ذي صلة. بعد كل شيء ، مجرد التخمين بأن كل شيء غير ذي صلة يعطينا دقة 80٪!
دعنا نستكشف كيف يمكن استخدام تمثيل BoW مع مجموعة البيانات هذه باتباع خط الإنتاج الموضح سابقًا. سننشئ المصنفات باستخدام ثلاث خوارزميات معروفة: نايف بايز ، والانحدار اللوجستي ، و و ألية متجهة الدعم .
مصنف نايف بايز (Naive Bayes Classifier)
نايف بايز هو مصنف احتمالي يستخدم نظرية بايز لتصنيف النصوص بناءً على الأدلة التي تظهر في بيانات التدريب. وهي تقدر الاحتمال الشرطي لكل سمة في نص معين بناءً على وجود هذه السمة في تلك الفئة وتضاعف احتمالات جميع سمات نص معين لحساب الاحتمال النهائي للتصنيف لكل فئة. أخيرًا ، يختار الفئة ذات الاحتمال الأفضل. لمعملومات أكثر (هنا)
دعنا نتعرف على الخطوات الرئيسية لتنفيذ خط الإنتاج الموضح سابقًا لمجموعة البيانات الخاصة بنا. لهذا ، نستخدم تطبيق Naive Bayes في scikit-Learn. بمجرد تحميل مجموعة البيانات ، نقوم بتقسيم البيانات إلى بيانات التدريب والاختبار ، كما هو موضح في مقتطف الشفرة الكود أدناه:

الخطوة التالية هي معالجة النصوص مسبقًا ثم تحويلها إلى متجهات سمات . على الرغم من وجود العديد من الطرق المختلفة لإجراء المعالجة المسبقة ، فلنفترض أننا نريد القيام بما يلي: إزالة علامات الترقيم والأرقام وأي سلاسل مخصصة وكلمات التوقف. يوضح مقتطف الكود أدناه هذه المعالجة المسبقة وتحويل بيانات التدريب والاختبار إلى متجهات السمات باستخدام CountVectorizer في scikit-Learn .

هذا سيمنحنا متجة سمات بأكثر من 45000 سمة! لدينا الآن البيانات بالتنسيق الذي نريده: متجهات السمات. لذا ، فإن الخطوة التالية هي تدريب وتقييم المصنف. يوضح مقتطف الكود أدناه كيفية القيام بالتدريب والتقييم لمصنف نايف بايز مع السمات التي استخلصناها أعلاه:

يوضح الشكل ادناه مصفوفة الارتباك لهذا المصنف مع بيانات الاختبار.
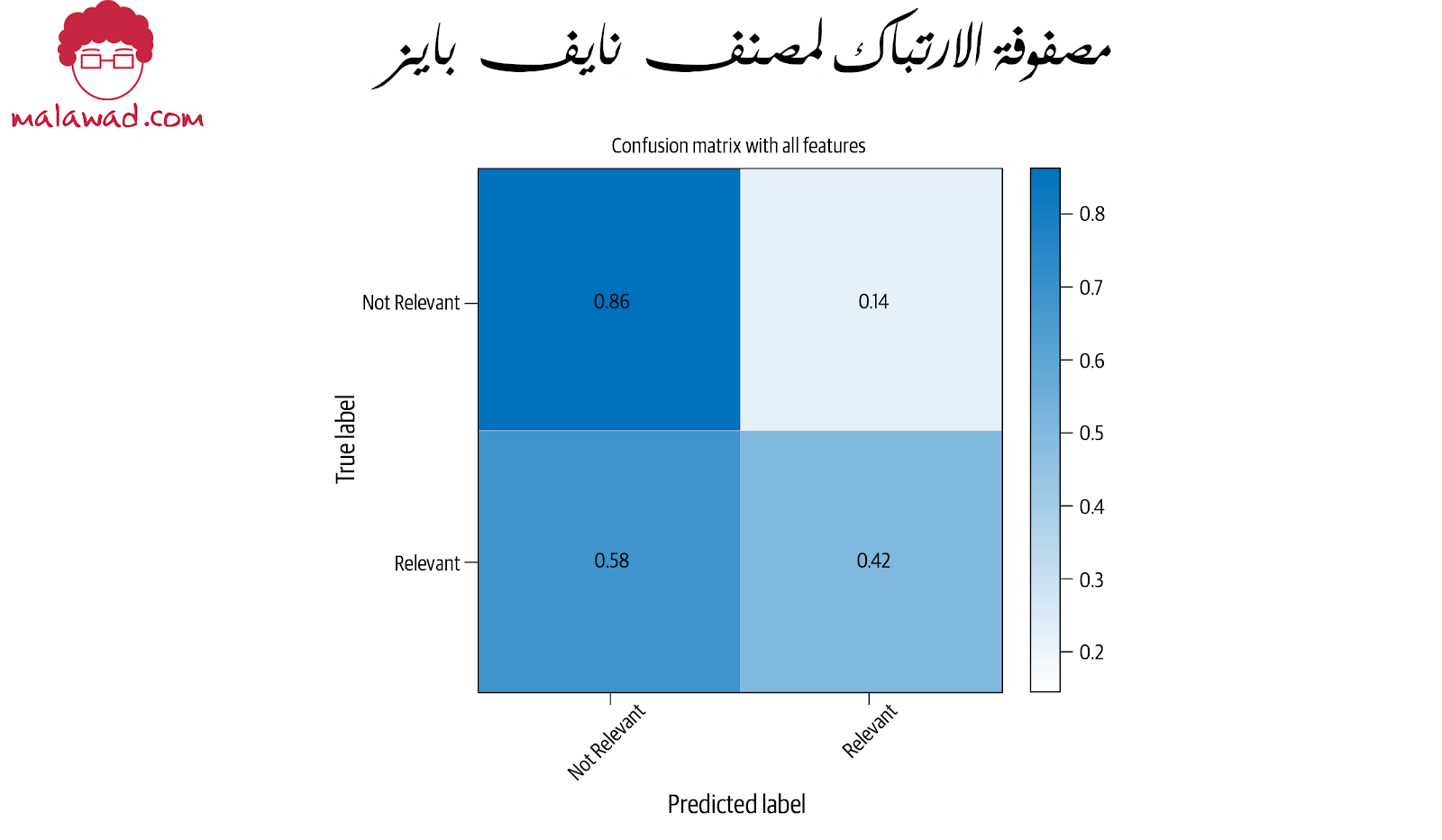
كما يتضح ، يقوم المصنف بعمل جيد إلى حد ما في تحديد المقالات غير ذات الصلة بشكل صحيح ، حيث يرتكب أخطاء بنسبة 14٪ فقط. ومع ذلك ، فإنه لا يعمل بشكل جيد مقارنة بالفئة الثانية: الملاءمة. يتم تحديد الفئة بشكل صحيح بنسبة 42٪ فقط.
هناك عدة أسباب لسوء عمل المصنف :
- نظرًا لأننا استخرجنا جميع السمات الممكنة ، فقد انتهى بنا المطاف في متجه سمات كبير ومتناثر ، حيث تكون معظم السمات نادرة جدًا وينتهي بنا الأمر إلى التشويش. مجموعة السمات المتناثرة تجعل التدريب صعبًا أيضًا.
- هناك عدد قليل جدًا من الأمثلة على المقالات ذات الصلة (حوالي 20٪) مقارنة بالمقالات غير ذات الصلة (حوالي 80٪) في مجموعة البيانات. يؤدي عدم التوازن في التصانيف هذا إلى انحراف عملية التعلم نحو فئة المقالات غير ذات الصلة ، حيث يوجد عدد قليل جدًا من الأمثلة على المقالات “ذات الصلة”.
- ربما نحتاج إلى خوارزمية تعلم أفضل.
- ربما نحتاج إلى آلية أفضل للمعالجة المسبقة واستخراج السمات.
- ربما ينبغي علينا النظر في ضبط معلمات المصنف والمعلمات الفائقة.
دعونا نرى كيفية تحسين أداء التصنيف لدينا من خلال معالجة بعض الأسباب المحتملة لذلك. تتمثل إحدى طرق التعامل مع السبب 1 في تقليل الضوضاء في متجهات السمات. النهج في مثال الكود السابق كان يحتوي على ما يقرب من 40.000 سمة مما يقدم عدد كبير من السمات المتناثرة ؛
على سبيل المثال ، معظم السمات في متجه السمة صفرية ، وقيم قليلة فقط غير صفرية. وهذا بدوره يؤثر على قدرة خوارزمية تصنيف النص على التعلم. دعونا نرى ما سيحدث إذا قصرنا هذا على 5000 وأعدنا عملية التدريب والتقييم. يتطلب ذلك منا تغيير CountVectorizer في العملية ، كما هو موضح في مقتطف الشفرة أدناه ، وتكرار جميع الخطوات:

مصفوفة الارتباك الجديدة مع هذا الإعداد.
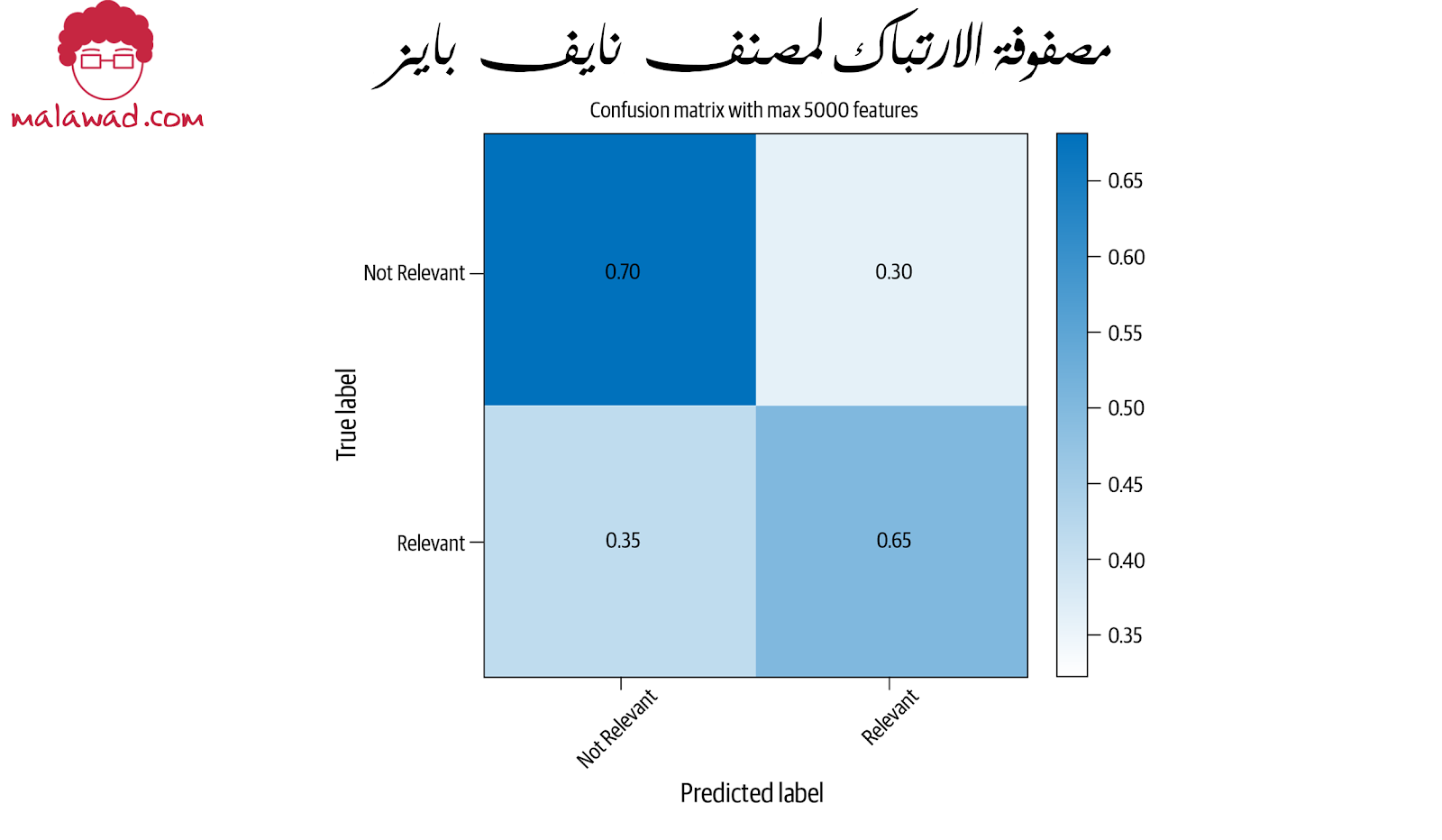
الآن ، بينما يبدو متوسط الأداء أقل من ذي قبل ، زاد التحديد الصحيح للمقالات ذات الصلة بنسبة تزيد عن 20٪. في هذه المرحلة ، قد يتساءل المرء عما إذا كان هذا هو ما نريده. تعتمد الإجابة على هذا السؤال على المشكلة التي نحاول حلها.
السبب الثاني في قائمتنا هو مشكلة الانحراف في البيانات تجاه فئة الأغلبية. هناك عدة طرق لمعالجة هذا. هناك نهجان نموذجيان هما الإفراط في أخذ العينات التي تنتمي إلى فئات الأقليات أو تقليل عينات فئة الأغلبية لإنشاء مجموعة بيانات متوازنة. التعلم غير المتوازن (imbalanced-learn) عبارة عن مكتبة بايثون تضم بعض طرق أخذ العينات لمعالجة هذه المشكلة. على الرغم من أننا لن نتعمق في تفاصيل هذه المكتبة هنا ، فإن المصنفات لديها أيضًا آلية مضمنة لمعالجة مجموعات البيانات غير المتوازنة هذه. سنرى كيفية استخدام ذلك من خلال أخذ مصنف آخر ، الانحدار اللوجستي
الانحدار اللوجستي
عندما وصفنا مصنف نايف بايز ، ذكرنا أنه يتعرف على احتمالية وجود نص لكل فئة ويختار النص ذي الاحتمال الأقصى. يسمى هذا المصنف المصنف التوليدي. في المقابل ، هناك مصنف تمييزي يهدف إلى معرفة توزيع الاحتمالات على جميع الفئات. الانحدار اللوجستي هو مثال على المصنف التمييزي ويستخدم بشكل شائع في تصنيف النص ، كخط أساس في البحث.
على عكس نايف بايز ، التي تقدر الاحتمالات بناءً على ظهور السمة في الفئات ، فإن الانحدار اللوجستي “يتعلم” أوزان السمات الفردية بناءً على مدى أهمية اتخاذ قرار التصنيف. الهدف من الانحدار اللوجستي هو تعلم فاصل خطي بين الفئات في بيانات التدريب بهدف تعظيم احتمالية البيانات. يتم هذا “التعلم” لأوزان السمات وتوزيع الاحتمالات على جميع الفئات من خلال وظيفة تسمى الوظيفة “اللوجيستية” ، و (ومن هنا الاسم) الانحدار اللوجستي .
لنأخذ متجه السمات ذات 5000 بعد من الخطوة الأخيرة لمثال نايف بايز و نقوم بتدريب مصنف الانحدار اللوجستي. يوضح مقتطف الشفرة أدناه كيفية استخدام الانحدار اللوجستي لهذه المهمة:

ينتج عن هذا مصنف بدقة 73.7٪. و هنا مصفوفة الارتباك مع هذا النهج.
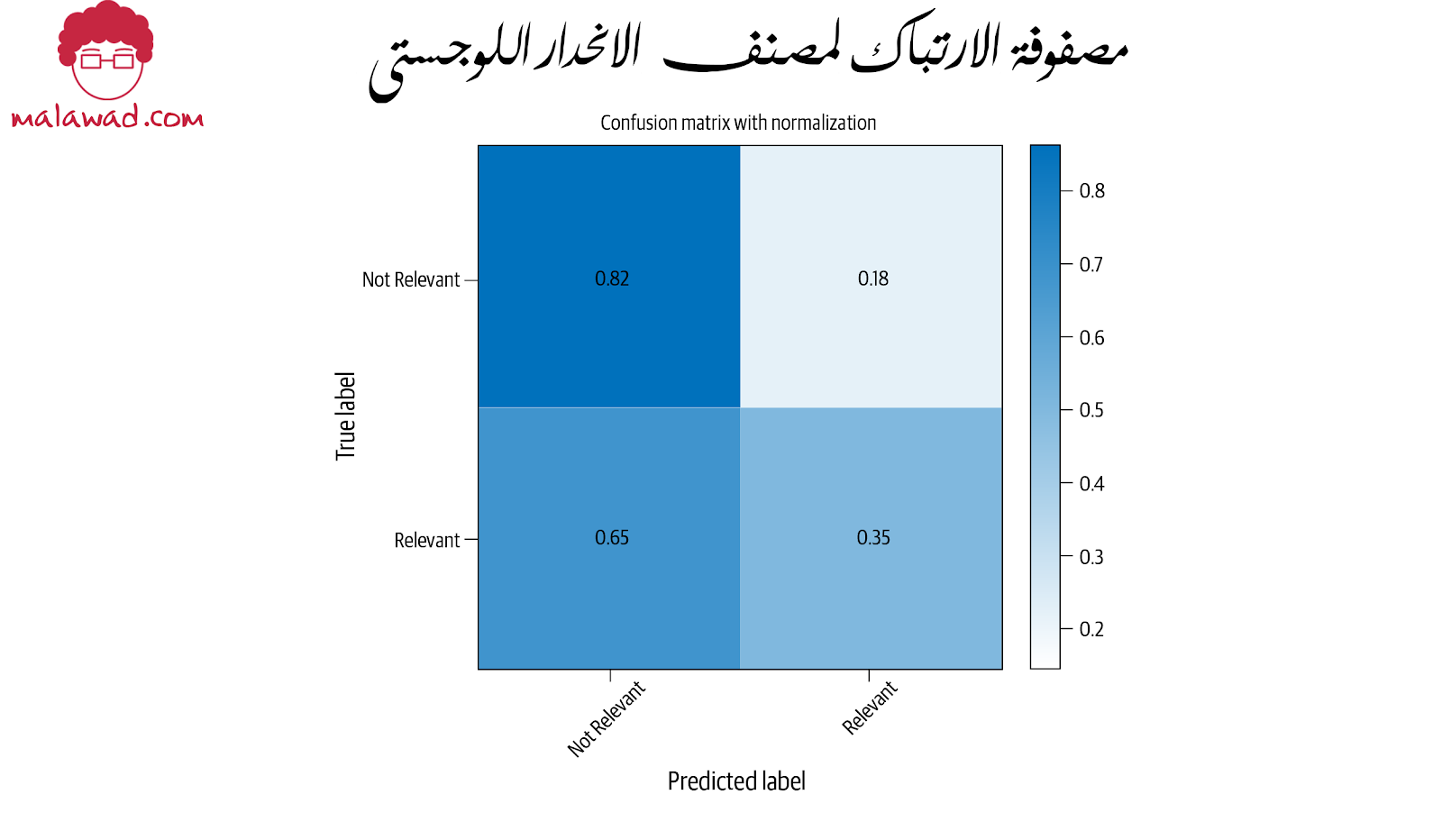
يحتوي مصنف الانحدار اللوجستي على class_weight ، والتي تُعطى قيمة “balanced”. هذا يخبر المصنف بزيادة أوزان الفئات بالتناسب العكسي مع عدد العينات لتلك الفئة. لذلك ، نتوقع رؤية أداء أفضل للفئات الأقل تمثيلًا. يمكننا تجربة هذا الكود عن طريق إزالة هذا وإعادة تدريب المصنف ، سنشهد هبوطًا (بنسبة 5٪ تقريبًا) في الخلية اليمنى السفلية من مصفوفة الارتباك. ومع ذلك ، من الواضح أن الانحدار اللوجستي يؤدي أداء أسوأ من نايف بايز لمجموعة البيانات هذه.
كان السبب 3 في قائمتنا هو: “ربما نحتاج إلى خوارزمية تعلم أفضل.” هذا يثير السؤال: “ما هي خوارزمية التعلم الأفضل؟” القاعدة العامة عند العمل مع أساليب تعلم الآلة هي أنه لا توجد خوارزمية واحدة تتعلم جيدًا في جميع مجموعات البيانات. النهج الشائع هو تجربة خوارزميات مختلفة ومقارنتها.
دعنا نرى ما إذا كانت هذه الفكرة تساعدنا من خلال استبدال الانحدار اللوجستي بخوارزمية تصنيف أخرى معروفة والتي ثبت أنها مفيدة للعديد من مهام تصنيف النص ، تسمى “آلة متجه الدعم”.
ألية متجهات الدعم (Support Vector Machine)
وصفنا الانحدار اللوجستي بأنه مصنف تمييزي يتعلم أوزان السمات الفردية ويتنبأ بتوزيع الاحتمالات على الفئات. ألية متجهات الدعم (SVM) ، التي تم اختراعها لأول مرة في أوائل الستينيات ، هي مصنف تمييزي مثل الانحدار اللوجستي. ومع ذلك ، على عكس الانحدار اللوجستي ، فإنه يهدف إلى البحث عن المستوى الفائق (hyperplane ) الأمثل في الفضاء ذو الأبعاد الأعلى ، والتي يمكن أن تفصل الفئات في البيانات بأقصى هامش ممكن. علاوة على ذلك ، فإن SVMs قادرة على تعلم حتى الفواصل غير الخطية بين الفئات ، على عكس الانحدار اللوجستي. ومع ذلك ، قد يستغرقون أيضًا وقتًا أطول للتدريب.
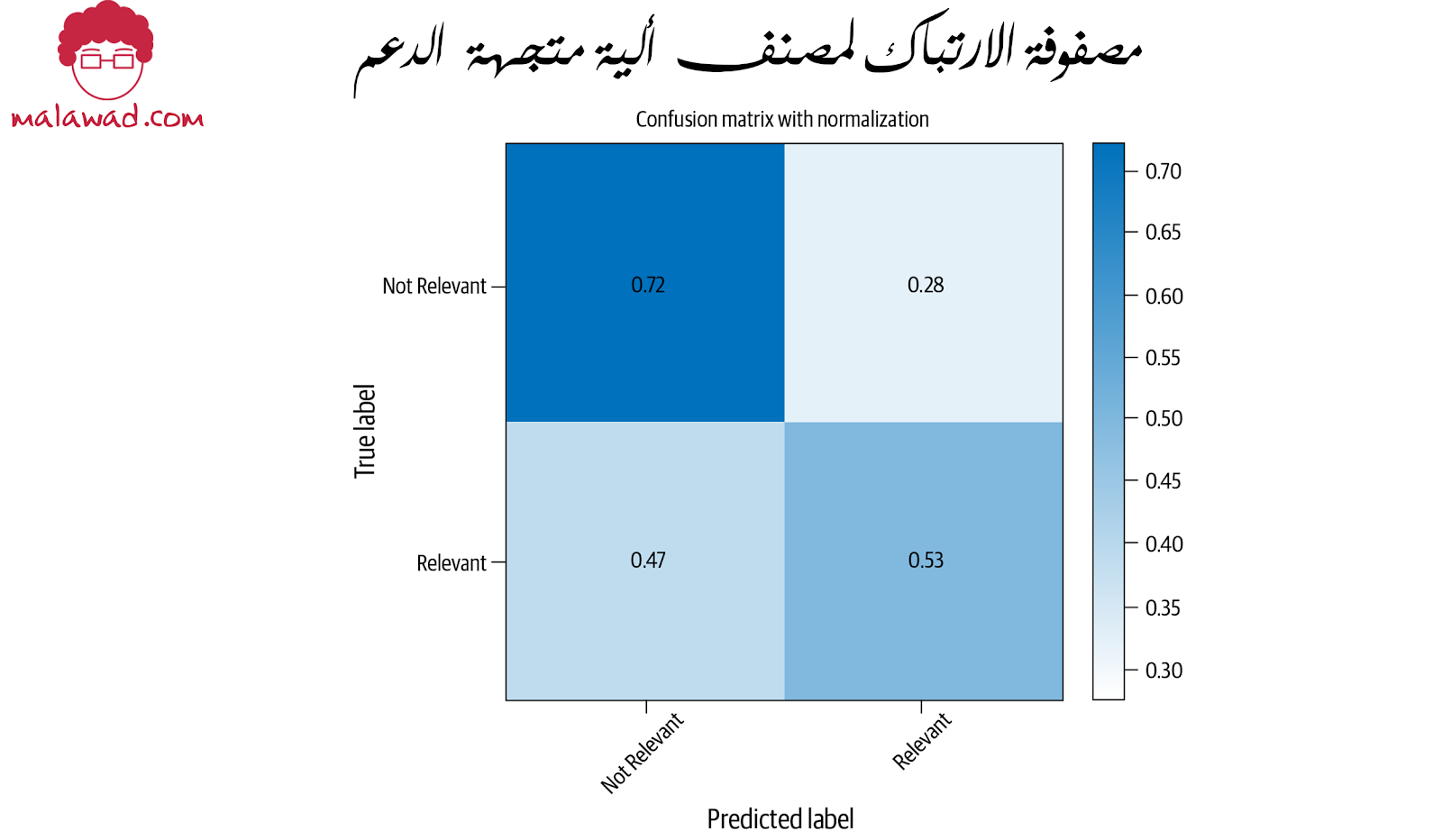
تأتي SVMs بأنواع مختلفة في sklearn. دعونا نرى كيف يتم استخدام أحدهما عن طريق الاحتفاظ بكل شيء آخر كما هو وتعديل الحد الأقصى للسمات إلى 1000 بدلاً من المثال السابق 5000. نحن نقتصر على 1000 سمة ، مع الأخذ في الاعتبار الوقت الذي تستغرقه خوارزمية SVM في التدريب. يوضح مقتطف الشفرة أدناه كيفية القيام بذلك ،

و هنا مصفوفة الارتباك مع هذا النهج.
ختاماً
يتضمن مشروع تصنيف النص في العالم الحقيقي استكشاف خيارات متعددة مثل هذه ، بدءًا من أبسط نهج من حيث النمذجة والنشر والقياس ، وزيادة التعقيد تدريجيًا. هدفنا النهائي هو بناء المصنف الذي يلبي احتياجات أعمالنا على أفضل وجه بالنظر إلى جميع القيود الأخرى.













إضافة تعليق