
حتى الآن ، اكتشفنا طرقًا مختلفة يمكننا من خلالها تدريب نموذج لتوليد عينات جديدة ، مع الأخذ في الاعتبار مجموعة التدريب فقط من البيانات التي نرغب في تقليدها. لقد طبقنا هذا على العديد من مجموعات البيانات ورأينا كيف يمكن في كل حالة أن تقوم شبكات الترميز التلقائية المتغيرة (VAEs) و شبكات الخصومة التوليدية ( GANs) تعلم الربط بين الفضاء الكامن السفلي و فضاء النقاط الضوئية (البكسل) الأصلية. من خلال أخذ عينات من التوزيع في الفضاء الكامن ، يمكننا استخدام النموذج التوليدي لربط هذه المتجه إلى صورة جديدة في فضاء النقاط الضوئية.
لاحظ أن جميع الأمثلة التي رأيناها حتى الآن تنتج ملاحظات جديدة من نقطة الصفر – أي أنه لا يوجد مدخلات باستثناء المتجه العشوائية الكامنة (Random latent vector) المأخوذ من الفضاء الكامن المستخدم لتوليد الصور.
يوجد تطبيق مختلف للنماذج التوليدية في مجال نقل النمط (style transfer) . هنا ، هدفنا هو بناء نموذج يمكنه تحويل صورة مُدخلة و التلاعب في أنماطها لإعطاء انطباع بأنها تأتي من نفس الصور في مجموعة البيانات المعطاة .

في هذا المقال سنتقوم ببناء نموذج نقل نمط يعرف بــ شبكة الخصومة متناسقة الدورة (cycle-consistent adversarial network) أو بإختصار (CycleGAN) ولكن في البداية قصة..
التفاح و البرتقال
الجدة سعاد و فرحانة يمتلكان بسطة فواكه مشتركة للتفاح و البرتقال. ، تفتخر الجدة سعاد باختيارها من التفاح ، وتقضي فرحانة ساعات في التأكد من ترتيب البرتقال بشكل مثالي.
كلاهما مقتنع تمامًا بأن طريقتهما في عرض الفواكه أفضل من الآخر ، لدرجة أنه في يوم ما قاما بعمل تحدي. و قررا أنهما لن يتشاركا الأرباح بل ستذهب كامل أرباح التفاح للجدة سعاد و كامل أرباح البرتقال لفرحانه .
لسوء الحظ ، لا تخطط الجدة سعاد ولا فرحانة لجعل هذه مسابقة عادلة. فبينما فرحانه مشغولة ، تتسلل الجدة سعاد إلى قسم البرتقال وتبدأ في تلوين البرتقال باللون الأحمر ليبدو مثل التفاح. و لكن الطيور على أشكالها تقع فلدى فرحانه نفس الخطة تمامًا ، وتحاول جعل تفاح الجدة سعاد يشبه البرتقال برشه بلون برتقالي .
عندما يجلب العملاء فواكهم إلى جهاز الدفع الألي ، فإنهم في بعض الأحيان يختارون الخيار الخاطئ على الجهاز.فعلى سبيل المثال قد يختار العميل أن يدفع ثمن البرتقال من الجهاز في حين أنه قد قام بأخذ تفاحه مزيفة تم رشها باللون البرتقالي من قبل فرحانة . و نفس الأمر يحدث مع البرنقال المزيف.
في نهاية اليوم ، يتم جمع أرباح كل فاكهة وتقسيمها وفقًا للتحدي- تخسر الجدة سعاد المال في كل مرة يتم فيها بيع أحد تفاحتها على أنها برتقالة ، وتخسر فرحانه في كل مرة يتم فيها بيع أحد برتقالتها على أنها تفاحة.
بعد إغلاق السوق ، تقوم كلا البائعتين بتنظيف مخزون فاكهتهم. و كونهما رائدتي أعمال و يبحثان عن الربح فبدلاً من محاولة التخلص من الفاكهة التي تم العبث و فيها من الطرف الأخر و خسارة أرباح فيقومان بكل بساطة بإعادة تلوينها بحيث. لمحاولة إظهارها كما كانت قبل أن يتم تخريبها. من المهم أن يقوموا بهذا بشكل مثالي لأنه إذا لم تبدوا لفاكهة بشكل صحيح ، فلن يتمكنوا من بيعها في اليوم التالي وسوف يخسرون الأرباح مرة أخرى.
لضمان الاتساق مع مرور الوقت ، يختبران تقنيات تلوينهم على الفاكهة الأصلية التي لم يتم العبث فيها ، للتأكد من أنها ستبدوا كما كانت في الأصل . إذا وجدوا أن هناك تناقضات واضحة ، فسيتعين عليهم إنفاق أرباحهم التي حصلوا عليها بشق الأنفس على تعلم تقنيات أفضل.

في البداية ، يميل العملاء إلى إجراء اختيارات عشوائية إلى حد ما في أجهزة الدفع الألي المثبتة حديثًا بسبب عدم خبرتهم مع الجهاز. ومع ذلك ، بمرور الوقت يصبحون أكثر مهارة في استخدام التكنولوجيا ، ويتعلمون كيفية تحديد الفاكهة التي تم العبث بها.
يجبر هذا الجدة سعاد و فرحانه على تطوير تقنياتهم في تخريب فاكهة الأخر ، مع ضمان دائمًا أنهما لا يزالان قادرين على استخدام نفس التقنية لتنظيف فاكهتهم بعد تغييرها. علاوة على ذلك ، يجب عليهم أيضًا التأكد من أن التقنية التي يستخدمونه لا توثر على مظهر الفاكهة الخاص بهم
بعد أيام وأسابيع عديدة من هذا التحدي السخيفة ، أدركوا أن شيئًا مذهلاً قد حدث. العملاء مرتبكون تمامًا ولا يمكنهم الآن التمييز بين التفاح الحقيقي والمزيف والبرتقال الحقيقي والمزيف.

شبكة الخصومة متناسقة الدورة (CycleGAN)
القصة السابقة تمثل أحد التطورات الرئيسيه في النمذجة التوليدية ، وعلى وجه الخصوص ، نقل النمط (style transfer) : شبكة الخصومة متناسقة الدورة (cycle-consistent adversarial network) أو بإختصار (CycleGAN) . تعتبر الورقة البحثية الأصلية خطوة مهمة إلى الأمام في مجال نقل النمط ، حيث أظهرت كيف أنه من الممكن تدريب نموذج يمكنه نسخ النمط من مجموعة مرجعية من الصور إلى صورة مختلفة ، من دون تدريب مجموعة من الأمثلة المزدوجة.
حيث تتطلب نماذج نقل النمط السابقة ، مثل pix2pix ، وجود كل صورة في مجموعة التدريب في كل من المصدر والهدف. و مثل هذا تحدي حيث كان من الممكن تصنيع هذا النوع من مجموعة البيانات لمجالات محدودة فقط (على سبيل المثال ، تلوين الصور أبيض و أسود ، أو تحويل صور الخرائط إلى صور أقمار صناعية) ، إلا أنه مستحيل بالنسبة لباقي المجالات . على سبيل المثال ، ليس لدينا صور أصلية للبركة حيث رسم مونيه سلسلة زنابق الماء الخاصة به ، ولا لدينا لوحة بيكاسو لبرج خليفة.
تم إصدار ورقة البحثية لـ CycleGAN بعد بضعة أشهر فقط من ورقة pix2pix وتوضح كيف يمكن تدريب نموذج على معالجة المشكلات حيث لا يوجد لدينا أزواج من الصور في مجالي المصدر والهدف.
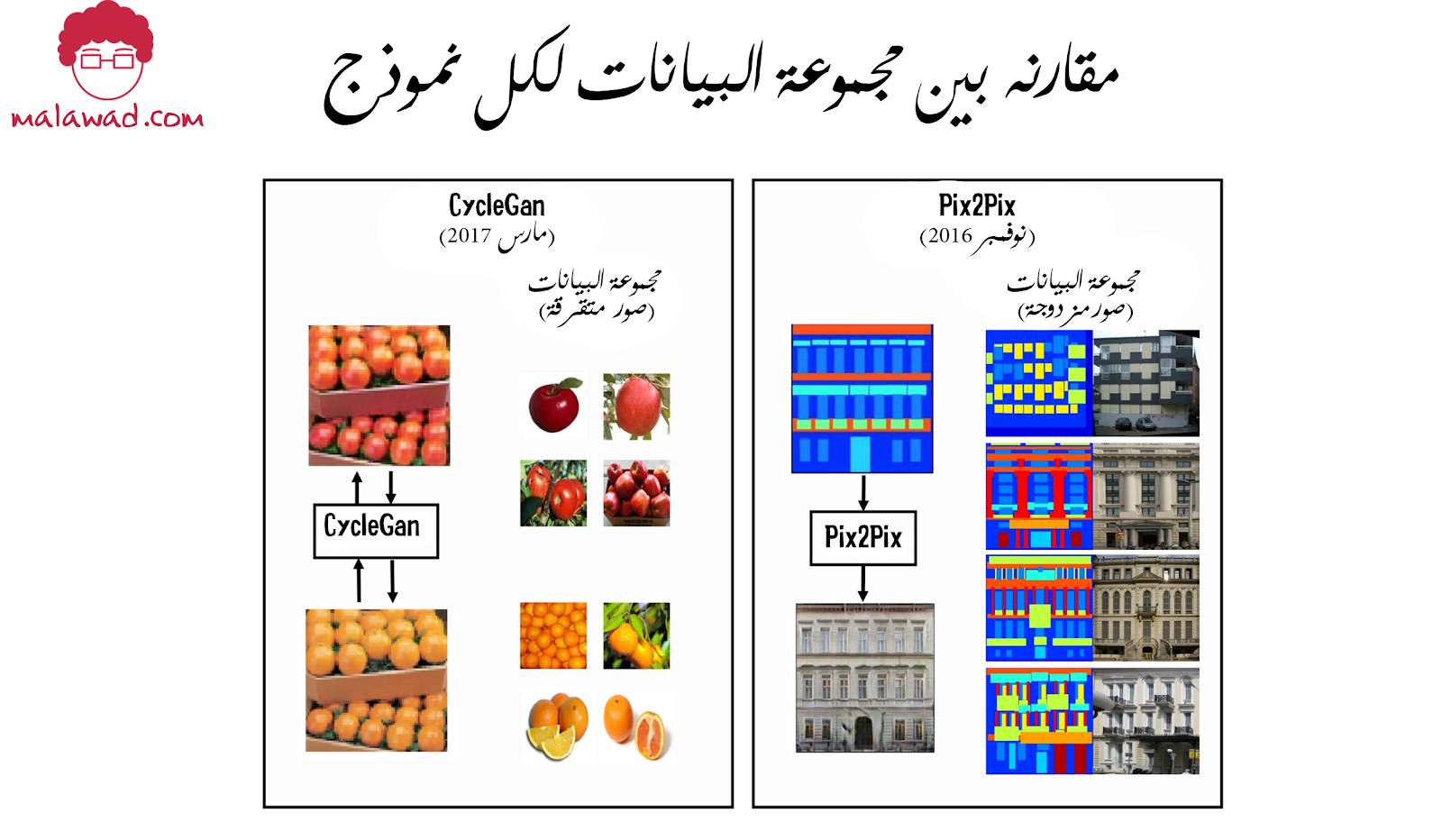
بينما يعمل pix2pix في اتجاه واحد فقط (من المصدر إلى الهدف) ، يقوم CycleGAN بتدريب النموذج في كلا الاتجاهين في وقت واحد ، بحيث يتعلم النموذج ترجمة الصور من الهدف إلى المصدر وكذلك المصدر إلى الهدف. هذا نتيجة لمعمارية النموذج ، لذلك تحصل على الاتجاه العكسي مجانًا.
دعنا الآن نرى كيف يمكننا بناء نموذج CycleGAN في Keras. سنستخدم مثال التفاح والبرتقال لبناء و تجربة معمارية CycleGAN .
معمارية CycleGAN
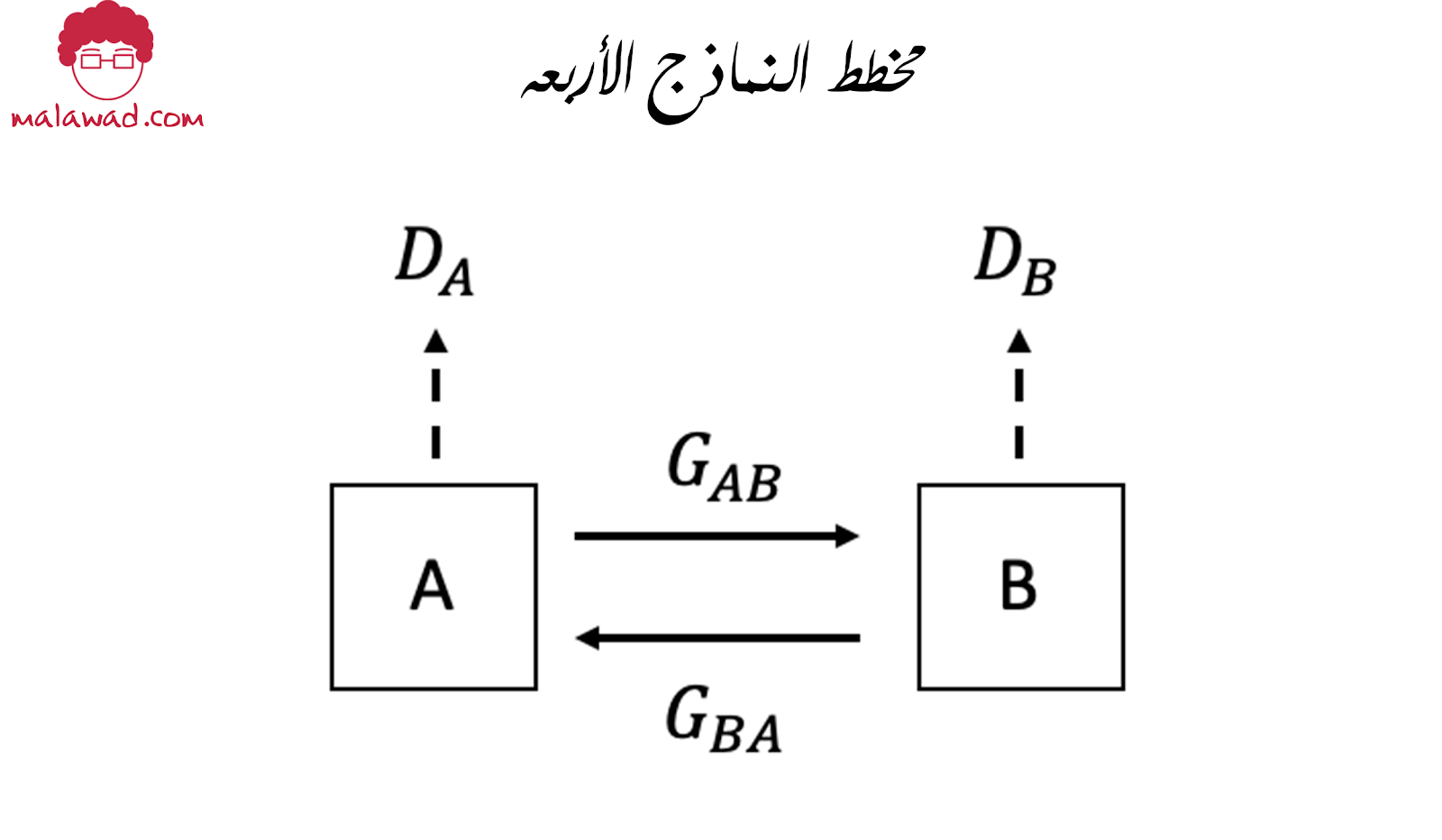
يتكون CycleGAN في الواقع من أربعة نماذج مولدين (generator) ومميزين (discriminator). يقوم المولد الأول ، G_AB ، بتحويل الصور من المجال A إلى المجال B. يقوم المولد الثاني ، G_BA ، بتحويل الصور من المجال B إلى المجال A.
نظرًا لعدم وجود صور مقترنة لتدريب مولداتنا عليها ، نحتاج أيضًا إلى تدريب اثنين من المميزات التي ستحدد ما إذا كانت الصور التي تنتجها المولدات مقنعة. تم تدريب المُميِّز الأول ، d_A ، ليكون قادرًا على تحديد الفرق بين الصور الحقيقية من المجال A والصور المزيفة التي تم إنتاجها بواسطة المولد G_BA. على العكس من ذلك ، تم تدريب المميز d_B ليكون قادرًا على تحديد الفرق بين الصور الحقيقية من المجال B والصور المزيفة التي تم إنتاجها بواسطة المولد G_AB.
المعايير التي تصف CycleGAN
gan = CycleGAN(
input_dim = (128,128,3)
, learning_rate = 0.0002
, lambda_validation = 1
, lambda_reconstr = 10
, lambda_id = 2
, generator_type = 'u-net'
, gen_n_filters = 32
, disc_n_filters = 32
)
دعونا أولاً نلقي نظرة على معمارية المولدات . عادةً ما تأخذ مولدات CycleGAN إحدى المعماريتين: U-Net أو ResNet . في ورقة pix2pix السابقة ، استخدم المؤلفون معمارية U-Net ، لكنهم إنتقلوا إلى معمارية ResNet لـ CycleGAN. سنقوم ببناء كلا المعماريتين في في هذا المقال ، بدءًا من U-Net.
المولدات (U-Net)

بطريقة مشابهة لشبكات الترميز التلقائي المتغيره ، تتكون U-Net من نصفين: نصف تقليل الأبعاد ، حيث يتم ضغط أبعاد الصور المدخلة و لكن زيادة عدد قنواتها ، ونصف زيادة أبعاد ، حيث يتم توسيع الأبعاد و تخفيض عدد القنوات .
ولكن ، على عكس شبكات الترميز التلقائي المتغيرة ، هناك أيضًا وصلات تخطي بين الطبقات المتكافئة في جزء تقليل الأبعاد و جزء زيادة الأبعاد من الشبكة
بمعنى . شبكات الترميز التلقائي المتغيرة خطيه ؛ تتدفق البيانات عبر الشبكة من المدخلات إلى المخرجات ، طبقة تلو الأخرى. أما U-Net ، فتحتوي على وصلات تخطي تسمح للمعلومات باختصار أجزاء من الشبكة وتتدفق عبر طبقات لاحقة.
الفكرة هنا هو أنه مع كل طبقة لاحقة في جزء التقليل من الشبكة ، يفهم النموذج مضمون الصورة ولكن يفقد معلومات عن مواضع ما يكون الصورة.
في قمة U ، ستكون خرائط السمات قد تعلمت فهمًا سياقيًا لما هو موجود في الصورة ، مع القليل من الفهم لمواضعها . بالنسبة لنماذج التصنيف التنبؤية ، هذا كل ما نطلبه ، لذلك يمكننا ربط هذا بطبقة كثيفة نهائية لإخراج احتمالية وجود فئة معينة في الصورة. ومع ذلك ، بالنسبة لتطبيق U-Net الأصلي (تجزئة الصورة) وأيضًا لنقل النمط ، فمن المهم أنه عندما نعود إلى حجم الصورة الأصلي ، نعيد إلى كل طبقة المعلومات المكانية التي فُقدت أثناء تقليل الأبعاد. هذا هو بالضبط سبب حاجتنا لوصلات التخطي. لبناء وصلات التخطي ، سنحتاج إلى تقديم نوعين جديدين من الطبقات.
أولاً : طبقة وصل (Concatenate Layer)
تقوم طبقة الوصل ببساطة بربط مجموعة من الطبقات معًا على طول محور معين (افتراضيًا ، المحور الأخير). على سبيل المثال ، في Keras ، يمكننا ضم طبقتين سابقتين ، x و y معًا على النحو التالي:
Concatenate()([x,y])
في U-Net ، نستخدم طبقات الوصل لربط طبقات زيادة الأبعاد بطبقة ذات حجم مكافئ في جزء تقليل الأبعاد من الشبكة. يتم ربط الطبقات ببعضها البعض على طول بعد القنوات وبالتالي يزيد عدد القنوات من ألف إلى ألفين كمثال، بينما يظل عدد الأبعاد المكانية كما هو. لاحظ أنه لا توجد أوزان لتعلمها في طبقة الوصل ؛لأنه يتم استخدامها فقط في “لصق” الطبقات السابقة معًا.
ثانياً: طبقة تسوية الحالة
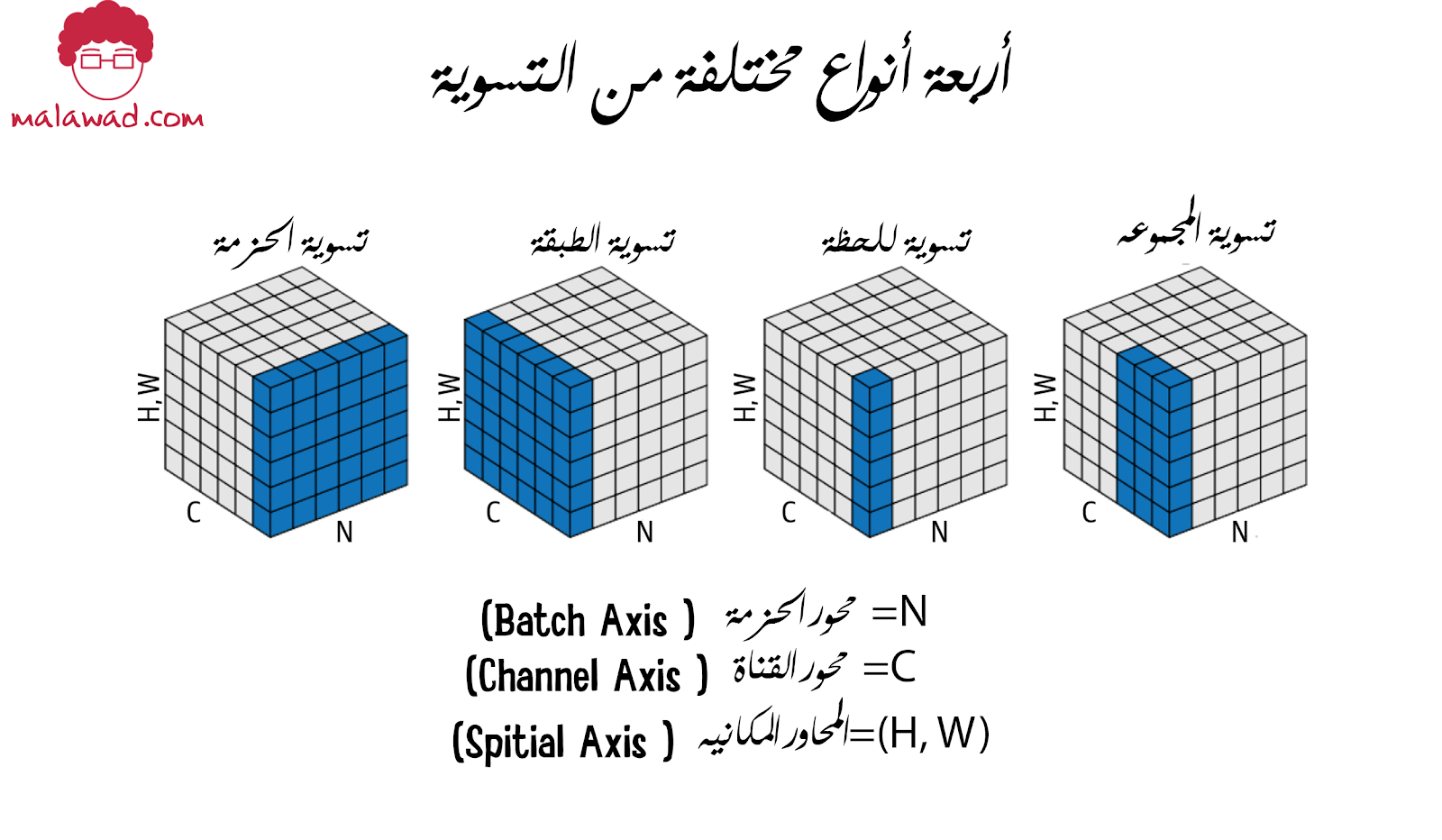
يستخدم مولد CycleGAN طبقات تسوية الحالة ( Instance Normalization ) بدلاً من طبقات تسوية الحزم، والتي تعطي نتائج أكثر إرضاء .
تقوم طبقة تسوية الحالة بتسوية كل ملاحظة على حدة ، وليس كحزمة. على عكس طبقة تسوية الحزم، فإنها لا تتطلب حساب المعييارين mu و sigma كمتوسط تشغيل أثناء التدريب ، وذلك لأنه في وقت الاختبار تقوم الطبيقة بتسوية كل حالة تماماً كما تفعل أثناء التدريب . قيم المتوسط (means) والانحراف المعياري (standard deviations ) المستخدمة لتسوية كل طبقة يتم حسابها لكل قناة ولكل ملاحظة.
أيضًا ، بالنسبة لطبقات تسوية الحالة في هذه الشبكة ، لا توجد أوزان للتعلم نظرًا لأننا لا نستخدم معييار التحجيم (جاما) أو معيار التحول (بيتا).
لدينا الآن كل ما نحتاجه لبناء مولد U-Net في Keras
def build_generator_unet(self):
def downsample(layer_input, filters, f_size=4):
d = Conv2D(filters, kernel_size=f_size
, strides=2, padding='same')(layer_input)
d = InstanceNormalization(axis = -1, center = False, scale = False)(d)
d = Activation('relu')(d)
return d
def upsample(layer_input, skip_input, filters, f_size=4, dropout_rate=0):
u = UpSampling2D(size=2)(layer_input)
u = Conv2D(filters, kernel_size=f_size, strides=1, padding='same')(u)
u = InstanceNormalization(axis = -1, center = False, scale = False)(u)
u = Activation('relu')(u)
if dropout_rate:
u = Dropout(dropout_rate)(u)
u = Concatenate()([u, skip_input])
return u
# Image input
img = Input(shape=self.img_shape)
# Downsampling #1
d1 = downsample(img, self.gen_n_filters)
d2 = downsample(d1, self.gen_n_filters*2)
d3 = downsample(d2, self.gen_n_filters*4)
d4 = downsample(d3, self.gen_n_filters*8)
# Upsampling #2
u1 = upsample(d4, d3, self.gen_n_filters*4)
u2 = upsample(u1, d2, self.gen_n_filters*2)
u3 = upsample(u2, d1, self.gen_n_filters)
u4 = UpSampling2D(size=2)(u3)
output = Conv2D(self.channels, kernel_size=4, strides=1
, padding='same', activation='tanh')(u4)
return Model(img, output)
1- يتكون المولد من نصفين. أولاً ، نقوم بتقليل أبعاد الصورة باستخدام طبقات Conv2D مع مقدار الخطوة= 2.
2- نقوم يزيادة الأبعاد ، لإعادة التنسور إلى نفس حجم الصورة الأصلية. تحتوي كتل زيادة الأبعاد على طبقات وصل، والتي تمنح الشبكة معمارية U-Net.
المميز (discriminator)
كل شبكات المميز التي تعرفنا عليها في هذه السلسة حتى الأن مخرجها هو رقم واحد ، و هو الاحتمال المتوقع أن تكون الصورة المدخلة “حقيقية”. أما شبكة المميز التي سنبنيها في CycleGAN مخرجها عبارة عن تنسور حجم 8 × 8 أحادي القناة بدلاً من رقم واحد.
والسبب في ذلك هو أن CycleGAN ترث معمارية المميز الخاصة بها من نموذج يعرف باسم PatchGAN ، حيث يقسم الصورة الصورة إلى “رقع” مربعة متداخلة . ثم يخمن ما إذا كانت كل رقعة حقيقية أو مزيفة ، بدلاً من التنبؤ بالصورة ككل . لذلك فإن ناتج المميز عبارة عن تنسور يحتوي على الاحتمال المتوقع لكل رقعة ، وليس مجرد رقم واحد.
لاحظ أن الرقع يتم توقعها كلها في وقت واحد أثناء قيامنا بتمرير صورة عبر الشبكة ، و ليس فردياً . ينشأ تقسيم الصورة إلى بقع بشكل طبيعي كنتيجة لمعمارية اللف الرياضي الخاصة بالمميز.
تتمثل فائدة استخدام مميِّز PatchGAN في أن دالة الخسارة يمكنها بعد ذلك قياس مدى جودة المميز في تمييز الصور بناءً على أنماطها (style) بدلاً من محتواها. نظرًا لأن كل عنصر في توقع المميز يعتمد فقط على رقعه صغير من الصورة ، فبالتالي يجب أن يستخدم نمط الرقعه ، بدلاً من محتواهها ، لاتخاذ القرار . هذا هو بالضبط ما نطلبه ؛ نفضل أن يكون المميز لدينا جيد في تحديد متى تختلف صورتان في النمط عن المحتوى.
هنا برمجة المميز في keras
def build_discriminator(self):
def conv4(layer_input,filters, stride = 2, norm=True):
y = Conv2D(filters, kernel_size=4, strides=stride
, padding='same')(layer_input)
if norm:
y = InstanceNormalization(axis = -1, center = False, scale = False)(y)
y = LeakyReLU(0.2)(y)
return y
img = Input(shape=self.img_shape)
y = conv4(img, self.disc_n_filters, stride = 2, norm = False) #1
y = conv4(y, self.disc_n_filters*2, stride = 2)
y = conv4(y, self.disc_n_filters*4, stride = 2)
y = conv4(y, self.disc_n_filters*8, stride = 1)
output = Conv2D(1, kernel_size=4, strides=1, padding='same')(y) #2
return Model(img, output)
1- مميِّز CycleGAN عبارة عن سلسلة من الطبقات التلافيفية ، وكلها تحتوي تسوية حالة (باستثناء الطبقة الأولى).
2- الطبقة النهائية هي طبقة تلافيفية مع مرشح واحد فقط وبدون تنشيط.
تجميع CycleGAN
للتلخيص ، نهدف إلى بناء مجموعة من النماذج التي يمكنها تحويل الصور الموجودة في المجال A (مثل صور التفاح) إلى المجال B (مثل صور البرتقال) والعكس صحيح. لذلك نحتاج إلى تجميع أربعة نماذج متميزة ، مولدين ومميزين ، على النحو التالي:
g_AB
يتعلم كيفية تحويل صورة من المجال A إلى المجال B.
g_BA
يتعلم كيفية تحويل صورة من المجال B إلى المجال A.
d_A
يتعلم الفرق بين الصور الحقيقية من المجال A والصور المزيفة التي تم إنشاؤها بواسطة g_BA.
d_B
يتعلم الفرق بين الصور الحقيقية من المجال B والصور المزيفة التي تم إنشاؤها بواسطة g_AB.
يمكننا تجميع المُميزين مباشرة ، حيث لدينا المدخلات (الصور من كل مجال) والمخرجات ( 1 إذا كانت الصورة من المجال أو 0 إذا كانت مزيفة أنشئها المولد).
self.d_A = self.build_discriminator()
self.d_B = self.build_discriminator()
self.d_A.compile(loss='mse',
optimizer=Adam(self.learning_rate, 0.5),
metrics=['accuracy'])
self.d_B.compile(loss='mse',
optimizer=Adam(self.learning_rate, 0.5),
metrics=['accuracy'])
و لكن ، لا يمكننا تجميع المولدات بشكل مباشر ، حيث لا توجد لدينا أزواج صور في مجموعة البيانات الخاصة بنا. بدلاً من ذلك ، نحكم على المولدات في وقت واحد بناءً على ثلاثة معايير :
الأول : الصلاحية . هل الصور التي ينتجها كل مولد تخدع المميز ذات الصلة؟ (على سبيل المثال ، هل المخرج من g_BA يخدع d_A وهل المخرج من g_AB يخدع d_B؟)
الثاني : إعادة البناء . إذا قمنا بتطبيق المولدين واحدًا تلو الآخر (في كلا الاتجاهين) ، فهل نعود إلى الصورة الأصلية؟ هذا المعييار هو سبب حصول CycleGAN على أسمه
الثالث : الهوية. إذا طبقنا كل مولد على صور من المجال المستهدف الخاص به ، فهل تظل الصورة بدون تغيير؟
هنا طريقة برمجة هذه المعايير في النموذج المركب لتدريب المولدات .
self.g_AB = self.build_generator_unet()
self.g_BA = self.build_generator_unet()
self.d_A.trainable = False
self.d_B.trainable = False
img_A = Input(shape=self.img_shape)
img_B = Input(shape=self.img_shape)
fake_A = self.g_BA(img_B)
fake_B = self.g_AB(img_A)
valid_A = self.d_A(fake_A)
valid_B = self.d_B(fake_B)
reconstr_A = self.g_BA(fake_B)
reconstr_B = self.g_AB(fake_A)
img_A_id = self.g_BA(img_A)
img_B_id = self.g_AB(img_B)
self.combined = Model(inputs=[img_A, img_B],
outputs=[ valid_A, valid_B,
reconstr_A, reconstr_B,
img_A_id, img_B_id ])
self.combined.compile(loss=['mse', 'mse',
'mae', 'mae',
'mae', 'mae'],
loss_weights=[
self.lambda_validation
, self.lambda_validation
, self.lambda_reconstr
, self.lambda_reconstr
, self.lambda_id
, self.lambda_id
],
optimizer=optimizer)
1- الصلاحية
2- إعادة البناء
3- الهوية
يقبل النموذج المدمج مجموعة من الصور من كل مجال كمدخلات ويوفر ثلاثة مخرجات (لمطابقة المعايير الثلاثة) لكل مجال – أي ستة مخرجات في المجموع. لاحظ كيف نقوم بتجميد الأوزان في المميز ، كما هو معتاد مع شبكات GAN ، بحيث يقوم النموذج المدمج فقط بتدريب أوزان المولد ، على الرغم من أن المميز متضمنة في النموذج.
الخسارة الإجمالية هي المجموع الموزون للخسارة لكل معيار. يتم استخدام متوسط الخطأ التربيعي (Mean squared error) لمعيار الصلاحية حيث يتحقق ناتج المميز مقابل الاستجابة الحقيقية (1) أو الاستجابة المزيفة (0) . و يستخم خطا الخسارة المطلقة (mean absolute error ) للمعايير القائمة على الصورة (إعادة البناء والهوية) .
تدريب CycleGAN
بعد بناء النموذج المزدوج يمكننا الآن تدريبه. و عملية التدريب هي نفسها المتبعة في تدريب شبكات الخصومة التوليدية حيث يتم التناوب بين تدريب المميز مع تدريب المولد (من خلال النموذج المشترك).
batch_size = 1
patch = int(self.img_rows / 2**4)
self.disc_patch = (patch, patch, 1)
valid = np.ones((batch_size,) + self.disc_patch) #1
fake = np.zeros((batch_size,) + self.disc_patch)
for epoch in range(self.epoch, epochs):
for batch_i, (imgs_A, imgs_B) in enumerate(data_loader.load_batch(batch_size)):
fake_B = self.g_AB.predict(imgs_A) #2
fake_A = self.g_BA.predict(imgs_B)
dA_loss_real = self.d_A.train_on_batch(imgs_A, valid)
dA_loss_fake = self.d_A.train_on_batch(fake_A, fake)
dA_loss = 0.5 * np.add(dA_loss_real, dA_loss_fake)
dB_loss_real = self.d_B.train_on_batch(imgs_B, valid)
dB_loss_fake = self.d_B.train_on_batch(fake_B, fake)
dB_loss = 0.5 * np.add(dB_loss_real, dB_loss_fake)
d_loss = 0.5 * np.add(dA_loss, dB_loss)
g_loss = self.combined.train_on_batch([imgs_A, imgs_B],
[valid, valid,
imgs_A, imgs_B,
imgs_A, imgs_B]) #3
1- نستخدم 1 للصور الحقيقية و 0 للصور التي تم إنشاؤها. لاحظ كيف توجد استجابة واحدة لكل رقعة ، لأننا نستخدم المميز PatchGAN.
2- لتدريب المميز ، نستخدم أولاً المولد المعني لإنشاء مجموعة من الصور المزيفة ، ثم نقوم بتدريب كل مميز على هذه المجموعة المزيفة ومجموعة من الصور الحقيقية. عادةً ما يكون حجم الحزمة لـ CycleGAN هو 1 (صورة واحدة).
3- يتم تدريب المولدين معًا في خطوة واحدة ، من خلال النموذج المركب الذي تم تجميعه مسبقًا. لاحظ كيف تتطابق المخرجات الستة مع وظائف الخسارة الست المحددة مسبقًا أثناء التجميع.
تحليل CycleGAN
دعونا نرى كيف يعمل CycleGAN على مجموعة البيانات البسيطة الخاصة بنا من التفاح والبرتقال ونلاحظ كيف أن تغيير معيار الوزن في دالة الخسارة يمكن أن يكون له تأثيرات كبيرة على النتائج.
لقد رأينا بالفعل مثالاً لمخرج نموذج CycleGAN في بداية المقالة و الآن بعد أن تعرفنا على معمارية CycleGAN ، قد تدرك أن هذه الصورة تمثل المعايير الثلاثة التي يتم من خلالها الحكم على النموذج المدمج: الصلاحية ، وإعادة البناء ، والهوية.
يمكننا أن نتأكد أن تدريب الشبكة كان ناجحًا بعدة أمور :
أولاً : لأن كل مولد يقوم بتغيير صورة الإدخال بشكل مرئي لتبدو أشبه بصورة صالحة من المجال المقابل.
ثانياً : عندما يتم تطبيق المولدات واحدة تلو الأخرى ، يكون الفرق بين صورة الإدخال والصورة المعاد بناؤها ضئيلًا.
أخيرًا: عندما يتم تطبيق كل مولد على صورة من مجال الإدخال الخاص به ، لا تتغير الصورة بشكل ملحوظ.

في ورقة CycleGAN الأصلية ، تم تضمين خسارة الهوية كإضافة اختيارية لكل من خسارتي إعادة البناء و الصلاحية. لإثبات أهمية مصطلح الهوية في دالة الخسارة ، دعنا نرى ما يحدث إذا أزلناه ، عن طريق تعيين معييار وزن دالة الهوية بصفر في دالة الخسارة

لا يزال CycleGAN قادرًا على ترجمة البرتقال إلى تفاح ولكن لون الحاوية الذي يحمل البرتقال انقلب من الأسود إلى الأبيض ، حيث لا يوجد الآن مصطلح فقدان الهوية لمنع هذا التحول في ألوان الخلفية. يساعد مصطلح الهوية في تنظيم المولد للتأكد من أنه يضبط فقط أجزاء الصورة الضرورية لإكمال التحويل وليس أكثر.
وهذا يسلط الضوء على أهمية ضمان أن تكون أوزان وظائف الخسارة الثلاث متوازنة بشكل جيد – فلو كانت خسارة الهوية قليلة ستظهر مشكلة تغير اللون ؛ اأما لو كانت كبيرة فلن يتم تحفيز CycleGAN بشكل كافٍ لتغيير المدخلات لتبدو وكأنها صورة من المجال الآخر.
رابط الدفتر على الغيتهاب













إضافة تعليق