
الذكاء الاصطناعي (AI) هو فرع من علوم الكمبيوتر يهدف إلى بناء أنظمة يمكنها أداء المهام التي تتطلب ذكاءً بشريًا. يُطلق على هذا أحيانًا اسم “ذكاء الآلة”. تم وضع أسس الذكاء الاصطناعي في الخمسينيات من القرن الماضي في ورشة عمل نظمت في كلية دارتموث . تم بناء الذكاء الاصطناعي الأولي إلى حد كبير من بالاعتماد على المنطق (logic) ، والاستدلال (heuristics) ، والأنظمة المستندة إلى القواعد.
تعلم الألة (ML) هو فرع من فروع الذكاء الاصطناعي يتعامل مع تطوير الخوارزميات التي يمكنها تعلم أداء المهام تلقائيًا بناءً على عدد كبير من الأمثلة ، دون الحاجة إلى قواعد مصنوعة يدويًا.
يشير التعلم العميق (DL) إلى فرع التعلم الأله الذي يعتمد على بناء الشبكات العصبية الاصطناعية. ML و DL و NLP كلها حقول فرعية داخل الذكاء الاصطناعي .
في حين أن هناك بعض التداخل بين معالجة اللغة الطبيعية (NLP) و تعلم الألة ( ML) و التعلم العميق ( DL) ، إلا أنها أيضًا مجالات دراسة مختلفة تمامًا ، كما يوضح الشكل. تماما مثل الذكاء الاصطناعي ، استندت تطبيقات معالجة اللغة الطبيعية المبكرة أيضًا إلى القواعد والاستدلال. على الرغم من ذلك ، تأثر تطوير تطبيق معالجة اللغة الطبيعية بشكل كبير بتعلم الأله و في الآونة الأخيرة ، تم استخدام التعلم العميق بشكل متكرر أيضًا لبناء تطبيقات NLP.

الهدف من تعلم الألة هو “التعلم” لأداء المهام مبنية على أمثلة (تسمى “بيانات التدريب”) بدون تعليمات صريحة. يتم ذلك عادةً عن طريق إنشاء تمثيل رقمي (يسمى “السمات”) لبيانات التدريب واستخدام هذا التمثيل لمعرفة الأنماط في تلك الأمثلة. يمكن تجميع خوارزميات التعلم الآلي في ثلاثة نماذج أولية: التعلم تحت الإشراف والتعلم غير الخاضع للإشراف والتعلم المعزز.
في التعلم الخاضع للإشراف ، الهدف هو تعلم وظيفة تربط بين المدخلات و المخرجات مع وجود عدد كبير من الأمثلة في شكل أزواج المدخلات والمخرجات.
تُعرف أزواج المدخلات والمخرجات ببيانات التدريب ، وتُعرف المخرجات على وجه التحديد باسم التسميات (labels) أو الحقيقة الأساسية (round truth) . مثال على مشكلة التعلم الخاضع للإشراف المتعلقة باللغة هو تعلم تصنيف رسائل البريد الإلكتروني كرسائل غير مرغوب فيها.. هذا سيناريو شائع في معالجة اللغة العصبية .
يشير التعلم غير الخاضع للإشراف إلى مجموعة من أساليب تعلم الألة التي تهدف إلى العثور على أنماط مخفية في بيانات المدخلة دون وجود أي مخرجات مرجعية. يعمل التعلم غير الخاضع للإشراف مع مجموعات كبيرة من البيانات غير المصنفة. في معالجة اللغة الطبيعية ، من الأمثلة على هذه المهمة تحديد الموضوع لمجموعة كبيرة من البيانات النصية دون أي معرفة بهذه الموضوعات. يُعرف هذا باسم نمذجة الموضوع.
أخيرًا وليس آخرًا ، يتعامل التعلم المعزز مع طرق تعلم المهام عن طريق التجربة والخطأ ويتميز بغياب البيانات المصنفة أو غير المصنفة بكميات كبيرة. يتم التعلم في بيئة قائمة بذاتها ويتحسن من خلال التغذية الراجعة (المكافأة أو العقوبة) التي تسهلها البيئة.
طرق معالجة اللغة الطبيعية
تنقسم الطرق المختلفة المستخدمة لحل مشكلات معالجة اللغة الطبيعية عمومًا إلى ثلاث فئات: الاستدلال و تعلم الألة والتعلم العميق.
معالجة اللغة الطبيعية القائمة على الاستدلال (Heuristics-Based NLP)
على غرار أنظمة الذكاء الاصطناعي المبكرة الأخرى ، استندت المحاولات المبكرة لتصميم أنظمة معالجة اللغة الطبيعية إلى بناء قواعد للمهام التي يتم حلها. هذا يتطلب أن يكون لدى المطورين خبرة في مجال اللغة لصياغة القواعد التي يمكن دمجها في البرنامج.
تتطلب مثل هذه الأنظمة أيضًا موارد مثل القواميس وقواميس المرادفات ، التي يتم تجميعها ورقمنتها عادةً على مدار فترة زمنية. مثال على تصميم القواعد لحل مشكلة معالجة اللغة الطبيعية باستخدام مثل هذه الموارد هو تحليل المشاعر (sentiment analysis) المعتمد على المعجم. يستخدم عدد الكلمات الإيجابية والسلبية في النص لاستنباط المشاعر في النص.
إلى جانب القواميس وقواميس المرادفات ، تم بناء قواعد معرفية أكثر تفصيلاً لمساعدة معالجة اللغة الطبيعية بشكل عام ومعالجة اللغات الطبيعية القائمة على القواعد بشكل خاص. أحد الأمثلة على ذلك هو Wordnet ، وهو قاعدة بيانات للكلمات والعلاقات الدلالية بينها. يوضح الصورة أدناه مثالاً على تصوير مثل هذه العلاقات بين الكلمات باستخدام Wordnet.
في الآونة الأخيرة ، تم أيضًا دمج الحس العالم في قواعد المعرفيه مثل (Open Mind Common Sense) ، والتي تساعد أيضًا مثل هذه الأنظمة القائمة على القواعد. في حين أن ما رأيناه حتى الآن هو إلى حد كبير موارد معجمية تستند إلى معلومات على مستوى الكلمات ، فإن الأنظمة المستندة إلى القواعد تتجاوز الكلمات ويمكن أن تتضمن أشكالًا أخرى من المعلومات أيضًا.
أداة التعبيرات العادية (Regular expressions )
تعد أداة التعبيرات العادية (Regular expressions ) أو بإختصار (regex) أداة رائعة لتحليل النص وإنشاء أنظمة قائمة على القواعد. وهي مجموعة من الأحرف أو الأنمط تستخدم لمطابقة السلاسل الفرعية والبحث عنها في النص. على سبيل المثال ، تعبير عادي مثل
‘^([a-zA-Z0-9_\-\.]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$’
يُستخدم للبحث عن كافة معرّفات البريد الإلكتروني في جزء نصي. تعتبر Regexes طريقة رائعة لدمج معرفة المجال بنظام معالجة لغة طبيعية معين .
على سبيل المثال ، بالنظر لشكوى العميل التي تأتي عبر الدردشة أو البريد الإلكتروني ، نريد إنشاء نظام لتحديد المنتج الذي تتعلق به الشكوى تلقائيًا. هناك مجموعة من أكواد المنتجات التي ترتبط بأسماء تجارية معينة. يمكننا استخدام regexes لمطابقة هذه بسهولة.
Regexes هي نموذج شائع جدًا لبناء أنظمة قائمة على القواعد. يتضمن برنامج معالجة اللغة الطبيعية مثل StanfordCoreNLP TokensRegex ، وهو إطار لتعريف التعبيرات النمطية. يتم استخدامه لتحديد الأنماط في النص واستخدام النص المتطابق لإنشاء القواعد.
تُستخدم Regexes للمطابقات الحتمية (deterministic matches)- بمعنى أنها إما مطابقة أو لا. regexes الاحتمالية هي فرع فرعي يقوم بتضمين احتمال المطابقة.
القواعد بدون سياق (Context-free grammar)
القواعد بدون سياق أو بإختصار (CFG) هي نوع من القواعد الرسمية المستخدمة لنمذجة اللغات الطبيعية. تم اختراع CFG بواسطة البروفيسور نعوم تشومسكي ، عالم لغوي وعالم مشهور
يمكن استخدام CFGs لالتقاط معلومات أكثر تعقيدًا وتسلسلًا هرميًا قد لا يقدر عليها regex. يسمح محلل إيرلي (The Earley parser) بتحليل جميع أنواع CFGs.
لنمذجة قواعد أكثر تعقيدًا ، يمكن استخدام لغات قواعد اللغة مثل محرك الجافا لأنماط التعليقات التوضيحية (Java Annotation Patterns Engine) أو بإختصار JAPE .
يحتوي JAPE على ميزات من كل من regexes وكذلك CFGs ويمكن استخدامه لأنظمة معالجة اللغة الطبيعية القائمة على القواعد مثل المعمارية العامة لهندسة النص (General Architecture for Text Engineering) أو بإختصار GATE .
يستخدم GATE لبناء استخراج النص للمجالات المغلقة والمحددة جيدًا حيث تكون الدقة و اكتمال التغطية أكثر أهمية. على سبيل المثال ، تم استخدام JAPE و GATE لاستخراج المعلومات حول إجراءات زرع جهاز تنظيم ضربات القلب من التقارير السريرية (الورقة البحثية هنا) . توضح الصورة أدناه واجهة GATE جنبًا إلى جنب مع عدة أنواع من المعلومات المميزة في النص كمثال على نظام قائم على القواعد.
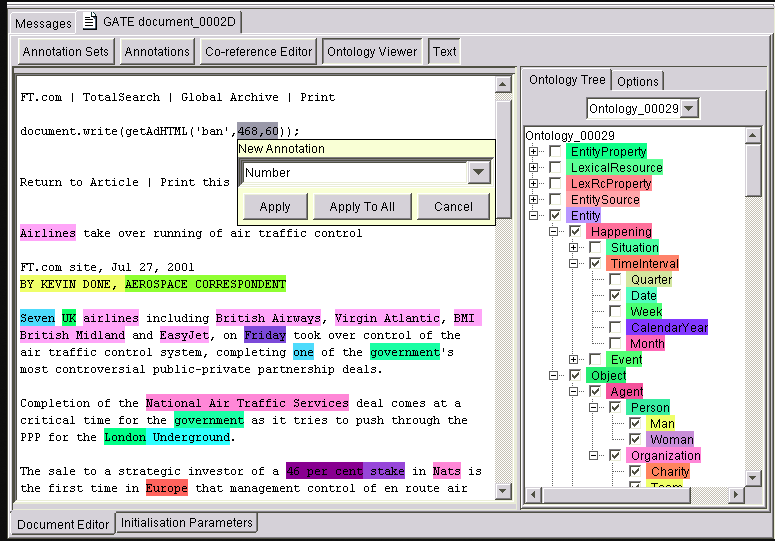
تلعب القواعد والاستدلال دورًا عبر دورة الحياة الكاملة لمشاريع معالجة اللغة الطبيعية حتى الآن.
من ناحية ، إنها طريقة رائعة لإنشاء النسخ الأولية من أنظمة معالجة اللغة الطبيعية . ببساطة ، تساعدك القواعد والاستدلال على إنشاء الإصدار الأول من النموذج بسرعة والحصول على فهم أفضل للمشكلة المطروحة. يمكن أن تكون القواعد والاستدلال مفيدة أيضًا كسمات لأنظمة معالجة اللغة الطبيعية القائمة على تعلم الألة.
لكن من ناحية أخرى من دورة حياة المشروع ، يتم استخدام القواعد والاستدلال لسد الفجوات في النظام. أي نظام NLP تم إنشاؤه باستخدام تقنيات التعلم الإحصائي أوتعلم الأله أو التعلم العميق سوف يرتكب أخطاء. قد تكون بعض الأخطاء باهظة الثمن – على سبيل المثال ، نظام الرعاية الصحية الذي ينظر في جميع السجلات الطبية للمريض ويقرر خطأ عدم تقديم النصح بإجراء اختبا. هذا الخطأ يمكن أن يكلف حياة إنسان. تعتبر القواعد والاستدلال طريقة رائعة لسد هذه الفجوات في أنظمة الإنتاج. دعنا الآن نوجه انتباهنا إلى تقنيات التعلم الآلي المستخدمة في معالجة اللغة الطبيعية .
تعلم الآلة في معالجة اللغة الطبيعية
يتم تطبيق تقنيات تعلم الألة على البيانات النصية تمامًا كما يتم استخدامها في أشكال أخرى من البيانات ، مثل الصور. تُستخدم تقنيات تعلم الأله الخاضعة للإشراف مثل التصنيف (classification) والانحدار (regression) بكثافة في مختلف مهام معالجة اللغة الطبيعية .
على سبيل المثال ، قد تتمثل مهمة تصنيف معالجة اللغة الطبيعية في تصنيف المقالات الإخبارية في مجموعة من الموضوعات الإخبارية مثل الرياضة أو السياسة.
من ناحية أخرى ، يمكن استخدام تقنيات الانحدار ، التي تعطي تنبؤًا رقميًا ، لتقدير سعر السهم بناءً على معالجة مناقشة وسائل التواصل الاجتماعي حول هذا السهم. وبالمثل ، يمكن استخدام خوارزميات التجميع غير الخاضعة للرقابة لتجميع المستندات النصية معًا.
يمكن وصف أي نهج لتعلم الأله لـ NLP ، تحت الإشراف أو غير خاضع للإشراف ، على أنه يتكون من ثلاث خطوات شائعة:
1- استخراج السمات من النص .
2- استخدام تمثيل السمات لتعليم نموذج.
3- تقييم النموذج وتحسينه.
سنتحدث الآن بإيجاز عن بعض أساليب تعلم الألة تحت الإشراف شائعة الاستخدام في في الخطوة الثانية (استخدام تمثيل السمات لتعليم نموذج) .
نايف بايز (Naive Bayes)
نايف بايز هي خوارزمية كلاسيكية لمهام التصنيف (الورقة البحثية) التي تعتمد بشكل أساسي على نظرية بايز.
باستخدام النظرية فإنه يتم حساب احتمالية ملاحظة تصنيف فئة معينه بالنظر إلى مجموعة السمات لبيانات الإدخال. من سمات هذه الخوارزمية أنها تفترض أن كل ميزة مستقلة عن جميع الميزات الأخرى.
بالنسبة لمثال تصنيف الأخبار المذكور سابقًا تتمثل إحدى طرق تمثيل النص رقميًا في استخدام عدد الكلمات الخاصة بالمجال ، مثل الكلمات الخاصة بالرياضة أو الخاصة بالسياسة ، الموجودة في النص.
نحن نفترض أن هذه الكلمات لا ترتبط ببعضها البعض. إذا كان الافتراض صحيحًا ، فيمكننا استخدام نايف باي لتصنيف المقالات الإخبارية. يتم استخدام نايف باي بشكل شائع كخوارزمية أوليه لتصنيف النص.و ذلك لأنها سهلة الفهم وسريعة للغاية في التدريب والتشغيل.
ألية مُتجه الدعم (Support vector machine)
آلة متجه الدعم (SVM) هي خوارزمية تصنيف شائع أخرى (الورقة البحثية) . الهدف في أي نهج تصنيف هو معرفة الحد الفاصل الذي يفصل بين فئات مختلفة من النص (على سبيل المثال ، السياسة مقابل الرياضة في مثال تصنيف الأخبار لدينا).
يمكن أن يكون الحد الفاصل خطي أو غير خطي (على سبيل المثال ، دائرة). يمكن أن يتعلم SVM كلاً من الحدود الخطية أو غير الخطية لفصل نقاط البيانات التي تنتمي إلى فئات مختلفة.
يتعلم الحد الفاصل الخطي تمثيل البيانات بطريقة تجعل الفروق بين التصانيف واضحة. بالنسبة لتمثيلات السمات ثنائية الأبعاد ، الصورة أدناه تعطي مثال لهذا.

حيث تنتمي النقاط بالأبيض والأسود إلى فئات مختلفة (على سبيل المثال ، مجموعات الأخبار الرياضية والسياسة). يتعلم SVM الحد الفاصل الأمثل بحيث تكون المسافة بين النقاط عبر التصانيف في أقصى حد لها.
تتمثل قوة خوارزمية SVM في قدرتها العالية على معالجة التباين والضوضاء في البيانات. تتمثل إحدى نقاط الضعف الرئيسية في الوقت المستغرق في التدريب وعدم القدرة على التوسع عندما تكون هناك كميات كبيرة من بيانات التدريب
نموذج ماركوف المخفي (HIDDEN MARKOV MODEL)
نموذج ماركوف المخفي (HMM) هو نموذج إحصائي (الورقة البحثية) يفترض أن هناك عملية أساسية غير قابلة للرصد مع حالات مخفية تولد البيانات – أي يمكننا فقط مراقبة البيانات بمجرد إنشائها.
ثم يحاول HMM نمذجة الحالات المخفية من هذه البيانات. على سبيل المثال ، ضع في اعتبارك مهمة معالجة اللغة الطبيعية المتمثلة في وضع علامات على جزء من الكلام (part-of-speech ) أو (POS) ، والتي تتعامل مع تعيين علامات جزء من الكلام للجمل.
يتم استخدام HMMs لوضع علامات POS على البيانات النصية. هنا ، نفترض أن النص تم إنشاؤه وفقًا لقواعد أساسية مخفية داخل النص. الحالات المخفية هي أجزاء من الكلام تحدد بطبيعتها بنية الجملة التي تتبع قواعد اللغة ، لكننا نلاحظ فقط الكلمات التي تحكمها هذه الحالات المخفية.
إلى جانب ذلك ، تقوم HMMs أيضًا بعمل افتراض ماركوف ، مما يعني أن كل حالة مخفية تعتمد على الحالة (الحالات) السابقة. لغة الإنسان متسلسلة بطبيعتها ، وتعتمد الكلمة الحالية في الجملة على ما حدث قبلها.
وبالتالي ، فإن HMMs مع هذين الافتراضين هي أداة قوية لنمذجة البيانات النصية. في الصورة أدناه ، يمكننا أن نرى مثالاً على HMM يتعلم أجزاء من الكلام من جملة معينة. أجزاء الكلام مثل JJ (صفة) و NN (اسم) هي حالات مخفية ، بينما تتم ملاحظة الجملة “natural language processing ( nlp )…” مباشرة..

الحقول الشرطية العشوائية (Conditional random fields)
الحقول الشرطية العشوائية (CRF) هي خوارزمية أخرى تُستخدم للبيانات المتسلسلة. حيث تستخدم بشكل أساسي في مهمة تصنيف كا عنصر في التسلسل (الورقة البحثية) .
تخيل نفس المثال على علامات POS ، حيث يمكن لـ CRF تمييز كلمة كلمة عن طريق تصنيفها إلى أحد أجزاء الكلام من مجموعة جميع علامات POS.
نظرًا لأنها تأخذ في الاعتبار الإدخال المتسلسل وسياق العلامات ، فإنها تعتبر أكثر تعبيراً من طرق التصنيف المعتادة وتعمل بشكل أفضل بشكل عام.
تتفوق الحقول الشرطية العشوائية (CRF) على نموذج ماركوف المخفي (HMM) في مهام مثل علامات POS ، والتي تعتمد على الطبيعة المتسلسلة للغة.
هذه كانت نظرة عامة على بعض خوارزميات تعلم الآلة الشائعة المستخدمة بكثرة في مهام معالجة اللغة الطبيعية . دعونا الآن نلقي نظرة على مناهج التعلم العميق في معالجة اللغة الطبيعية.
التعلم العميق في معالجة اللغة الطبيعية
في السنوات القليلة الماضية ، شهدنا طفرة هائلة في استخدام الشبكات العصبية للتعامل مع البيانات المعقدة وغير المنظمة. اللغة معقدة بطبيعتها وغير منظمة. لذلك ، نحتاج إلى نماذج ذات تمثيل أفضل وقدرة على التعلم لفهم وحل المهام اللغوية. في ما يلي بعض معماريات الشبكات العصبية العميقة الشائعة في معالجة اللغة الطبيعية.
الشبكات العصبية المتكررة (RECURRENT NEURAL NETWORKS)
كما ذكرنا سابقًا ، اللغة متسلسلة بطبيعتها. تتدفق الجملة في أي لغة من اتجاه إلى آخر (على سبيل المثال ، تقرأ اللغة الإنجليزية من اليسار إلى اليمين). وبالتالي ، فإن النموذج الذي يمكنه قراءة نص مُدخل تدريجيًا من طرف إلى آخر يمكن أن يكون مفيدًا جدًا لفهم اللغة.
تم تصميم الشبكات العصبية المتكررة (RNNs) خصيصًا للحفاظ على هذه المعالجة المتسلسلة والتعلم في الاعتبار. تحتوي RNNs على وحدات عصبية قادرة على تذكر ما قاموا بمعالجته حتى الآن. تسمى الذاكرة مؤقتة ، ويتم تخزين المعلومات وتحديثها مع كل خطوة زمنية حيث يقرأ RNN الكلمة التالية في الإدخال.

تعد RNNs قوية وتعمل بشكل جيد جدًا لحل مجموعة متنوعة من مهام معالجة اللغة الطبيعية ، مثل تصنيف النص والترجمة الآلية ، وما إلى ذلك.
يمكن أيضًا استخدام RNNs لإنشاء نص حيث يكون الهدف هو قراءة النص السابق والتنبؤ بالكلمة التالية أو الحرف التالي.(مقالة تتحدث عن هذا)
شبكة الذاكرة طويلة قصيرة المدى (LONG SHORT-TERM MEMORY)
على الرغم من قدرتها وتعدد استخداماتها ، تعاني شبكات RNN من مشكلة النسيان – فهي لا تستطيع تذكر السياقات الطويلة وبالتالي لا تؤدي أداءً جيدًا عندما يكون نص الإدخال طويلًا ، وهو ما يحدث عادةً مع مدخلات النص.
تم اختراع شبكات الذاكرة طويلة المدى (LSTMs) ، وهي نوع من RNN ، للتخفيف من هذا النقص في شبكات RNN. تتحايل LSTMs على هذه المشكلة من خلال التخلي عن السياق غير ذي الصلة وتذكر فقط الجزء من السياق المطلوب لحل المهمة المطروحة.
هذا يخفف من عبء تذكر سياق طويل جدًا في تمثيل متجه واحد. لقد استبدلت LSTMs شبكات RNNs في معظم التطبيقات بسبب هذا الحل البديل.

الشبكات اللف الرياضي العصبية (Convolutional neural networks)
تحظى شبكات اللف الرياضي العصبية (CNN) بشعبية كبيرة وتستخدم بكثرة في مهام التبصير الحاسوبي مثل تصنيف الصور والتعرف على الفيديو وما إلى ذلك.
كما شهدت شبكات CNN نجاحًا في معالجة اللغات الطبيعية ، خاصة في مهام تصنيف النص. يمكن للمرء أن يستبدل كل كلمة في جملة بمتجه الكلمة المقابل لها ، وجميع المتجهات لها نفس الحجم (d) .
وبالتالي ، يمكن تكديسها على بعضها البعض لتشكيل مصفوفة أو مصفوفة ثنائية الأبعاد من البعد n ✕ d ، حيث n هو عدد الكلمات في الجملة و d هو حجم متجهات الكلمة.
يمكن الآن معالجة هذه المصفوفة بشكل مشابه لصورة ويمكن نمذجتها بواسطة CNN. الميزة الرئيسية لشبكات CNN هي قدرتها على النظر إلى مجموعة من الكلمات معًا باستخدام نافذة سياق (context window).
على سبيل المثال ، نقوم بتصنيف المشاعر ، ونحصل على جملة مثل ، “I like this movie very much!” من أجل فهم هذه الجملة ، من الأفضل النظر إلى الكلمات ومجموعات مختلفة من الكلمات المتجاورة.

كما هو موضح في الصورة ، تستخدم CNN مجموعة من طبقات اللف الرياضي والتجميع لتحقيق هذا التمثيل المكثف للنص ، والذي يتم تغذيته كمدخل إلى طبقة متصلة بالكامل لتعلم بعض مهام معالجة اللغة الطبيعية مثل تصنيف النص.
المحولات (Transformers)
المحولات (الورقة البحثية) هي أحدث التطورات في نماذج التعلم العميق فيما يخص معالجة اللغة الطبيعية. حققت نماذج المحولات أحدث التقنيات في جميع مهام معالجة اللغة الطبيعية تقريبًا في العامين الماضيين
إنهم يصوغون السياق النصي ولكن ليس بطريقة متسلسلة. بالنظر إلى كلمة في الإدخال ، فإنه يفضل النظر إلى جميع الكلمات من حوله (المعروفة باسم الاهتمام الذاتي) وتمثيل كل كلمة فيما يتعلق بسياقها. على سبيل المثال ، يمكن أن يكون لكلمة “بنك” معاني مختلفة اعتمادًا على السياق الذي تظهر فيه. إذا كان السياق يتحدث عن التمويل ، فربما تشير كلمة “بنك” إلى مؤسسة مالية. من ناحية أخرى ، إذا ذكر السياق نهرًا ، فمن المحتمل أنه يشير إلى ضفة النهر. يمكن للمحولات نمذجة مثل هذا السياق ، ومن ثم تم استخدامها بكثافة في مهام معالجة اللغة الطبيعية بسبب قدرة التمثيل العالية هذه مقارنة بالشبكات العميقة الأخرى.
نقل التعلم هو أسلوب في الذكاء الاصطناعي حيث يتم تطبيق المعرفة المكتسبة أثناء حل مشكلة واحدة على مشكلة مختلفة ولكنها ذات صلة.
مع المحولات ، تكمن الفكرة في تدريب وضع محول كبير جدًا بطريقة غير خاضعة للإشراف (يُعرف بالتدريب المسبق) للتنبؤ بجزء من الجملة بالنظر إلى باقي المحتوى بحيث يمكنه ترميز الفروق الدقيقة للغة فيه. يتم تدريب هذه النماذج على أكثر من 40 جيجابايت من البيانات النصية ، المأخوذة من الإنترنت بالكامل.
مثال على محول كبير هو تمثيلات التشفير ثنائية الاتجاه من المحولات (Bidirectional Encoder Representations from Transformers) أو بإختصار BERT (الورقة البحثية)

يظهر النموذج المدرَّب مسبقًا على الجانب الأيمن. يتم بعد ذلك ضبط هذا النموذج بدقة في مهام معالجة اللغات الطبيعية ، مثل تصنيف النص ، واستخراج الكيان ، والإجابة على الأسئلة ، وما إلى ذلك ، كما هو موضح على اليسار.
نظرًا للكم الهائل من المعرفة المدربة مسبقًا ، تعمل BERT بكفاءة في نقل المعرفة وتحقق أحدث ما توصلت إليه التقنية للعديد من هذه المهام. الصورة أدناه توضح طريقة عمل آلية الانتباه الذاتي ، والتي تعد مكونًا رئيسيًا للمحول.

شبكات الترميز التلقائي
تعد شبكات الترميز التلقائي نوعًا مختلفًا من الشبكات تستخدم بشكل أساسي لتعلم تمثيل المتجه المضغوط للإدخال.
على سبيل المثال ، إذا أردنا تمثيل نص بواسطة متجه ، فما أفضل طريقة للقيام بذلك؟ يمكننا أن نتعلم وظيفة ربط من إدخال النص إلى المتجه.
لجعل وظيفة الربط هذه مفيدة ، نقوم “بإعادة بناء” المدخلات من تمثيل المتجه. هذا شكل من أشكال التعلم غير الخاضع للإشراف.
بعد التدريب ، نقوم بجمع تمثيل المتجه ، والذي يعمل بمثابة ترميز لنص الإدخال كمتجه كثيف (dense vector) . تُستخدم شبكات الترميز التلقائي عادةً لإنشاء تمثيلات السمات المطلوبة لأية مهام في المراحل النهائية. ا

في هذا المخطط ، تعطي الطبقة المخفية تمثيلًا مضغوطًا لبيانات الإدخال ، وتلتقط الجوهر ، وتقوم طبقة الإخراج (شبكة فك التشفير) بإعادة بناء تمثيل الإدخال من التمثيل المضغوط.
في حين أن معمارية شبكات الترميز التلقائي لا يمكنها التعامل مع خصائص محددة للبيانات المتسلسلة مثل النص ، فإن التعديلات في شبكات الترميز التلقائي ، مثل شبكات الترميز التلقائي طويلة قصيرة الذاكرة ( LSTM autoencoders )، تعالج هذه الخصائص جيدًا.
قدمنا هنا بإيجاز بالتحدث عن بعض معماريات التعلم العميق المشهورة في تطبيقات معالجة اللغة الطبيعية .













إضافة تعليق