
يعالج نمط تصميم المدخلات المتعددة الوسائط (Multimodal Input) مشكلة تمثيل أنواع مختلفة من البيانات أو البيانات التي يمكن التعبير عنها بطرق معقدة من خلال ربط جميع تمثيلات البيانات المتاحة.
المشكلة
عادةً ، يمكن تمثيل أحد المدخلات في نموذج كرقم أو كفئة أو صورة أو نص حر. يتم تعريف العديد من النماذج الجاهزة لإستخدامها في أنواع معينة من المدخلات فقط – نموذج تصنيف الصور القياسي مثل Resnet-50 ، على سبيل المثال ، لا يمتلك القدرة على التعامل مع المدخلات بخلاف الصور.
لفهم الحاجة إلى المدخلات متعددة الوسائط ، دعنا نقول أن لدينا كاميرا تلتقط لقطات عند تقاطع لتحديد مخالفات المرور. نريد أن يتعامل نموذجنا مع بيانات الصورة (لقطات الكاميرا) وبعض البيانات الوصفية حول وقت التقاط الصورة (الوقت من اليوم ، واليوم من الأسبوع ، والطقس ، وما إلى ذلك) ، كما هو موضح.
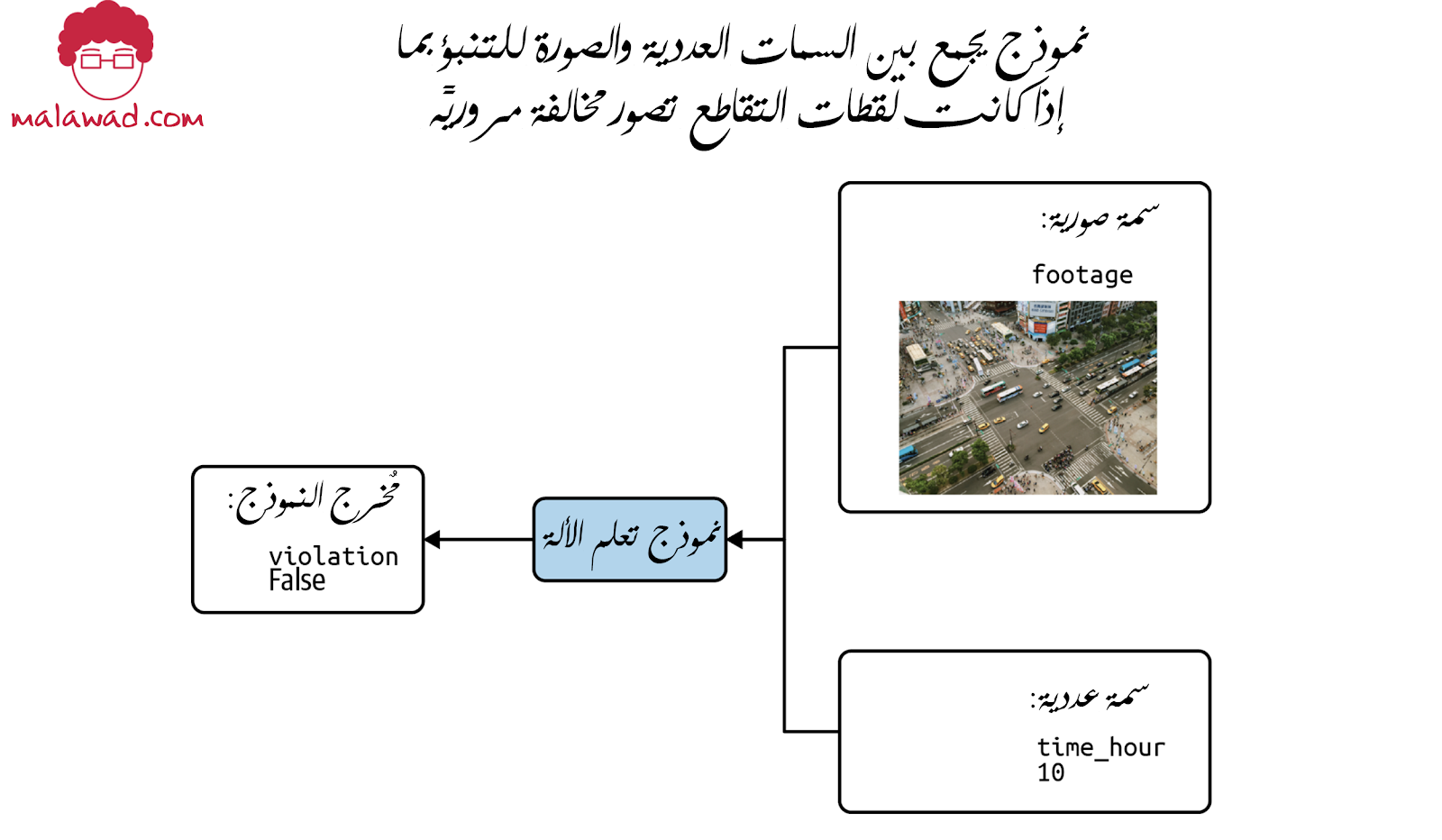
تحدث هذه المشكلة أيضًا عند تدريب نموذج بيانات منظم حيث يكون أحد المدخلات نص حر الشكل. على عكس البيانات العددية، لا يمكن تغذية الصور والنصوص مباشرة في النموذج.
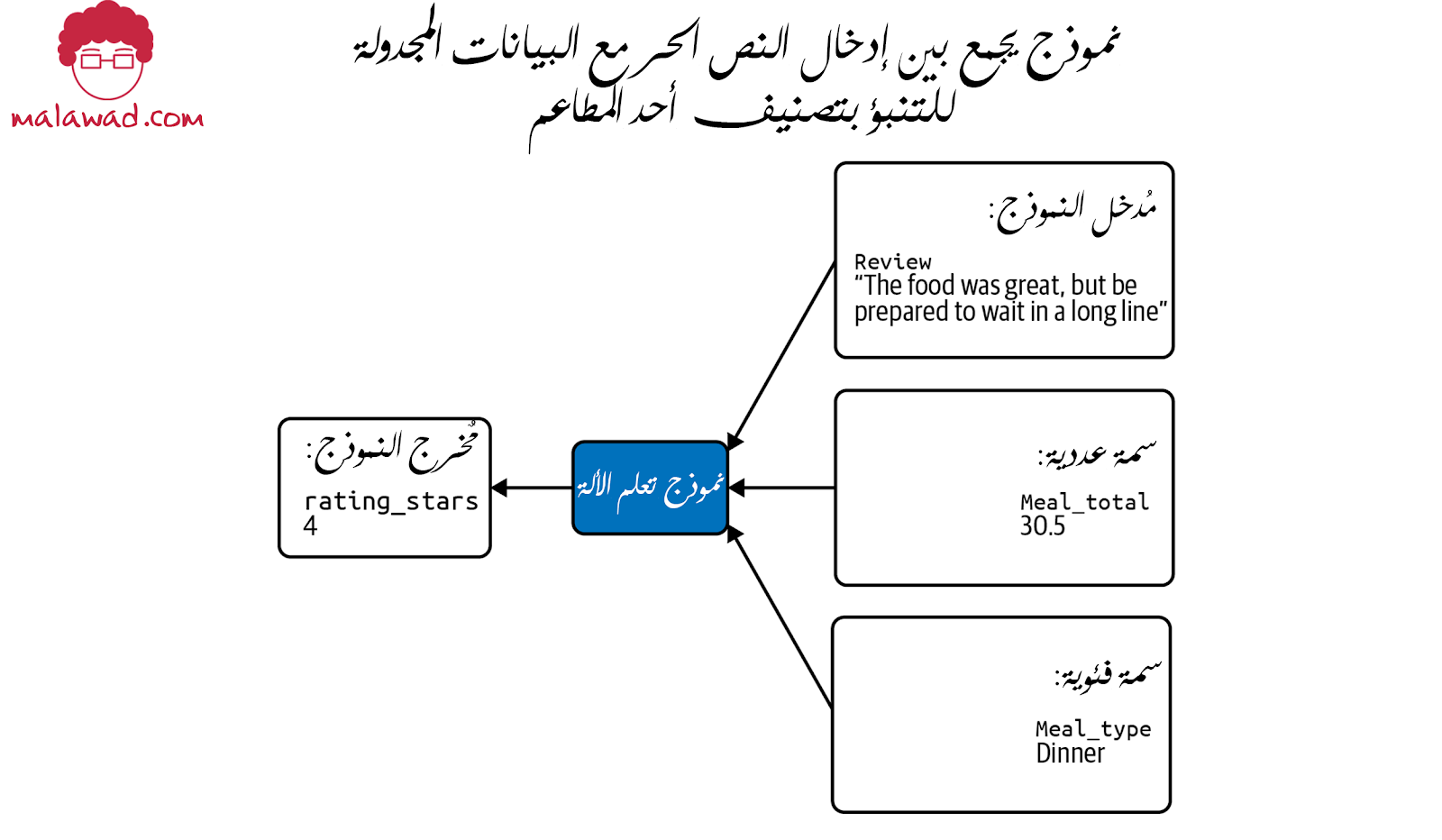
نتيجة لذلك ، سنحتاج إلى تمثيل إدخالات الصور والنص بطريقة يمكن أن يفهمها نموذجنا (عادةً باستخدام نمط تصميم التضمينات) ، ثم دمج هذه المدخلات مع سمات مجدولة أخرى. على سبيل المثال ، قد نرغب في توقع تصنيف أحد المطاعم بناءً على نص المراجعة الخاص به والسمات الأخرى مثل ما دفعه العميل وما إذا كان الغداء أو العشاء
الحل
للبدء ، دعنا نأخذ المثال أعلاه مع نص من مراجعة مطعم مقترن ببيانات وصفية مجدولة حول الوجبة المشار إليها في المراجعة. سنقوم أولًا بدمج السمات العددية والفئوية. هناك ثلاثة خيارات ممكنة لنوع الوجبة ، لذا يمكننا تحويل هذا إلى خط الترميز الأحادي وسنقدم العشاء على أنه [0 ، 0 ، 1]. مع هذه السمة الفئوية الممثلة كمصفوفة ، يمكننا الآن دمجها مع meal_total بإضافة سعر الوجبة كعنصر رابع في المصفوفة: [0 ، 0 ، 1 ، 30.5].
نمط تصميم التضمينات هو نهج شائع لترميز النص لنماذج تعلم الألة. إذا كان نموذجنا يحتوي على نص فقط ، فيمكننا تمثيله كطبقة تضمين باستخدام كود tf.keras التالي:
from tensorflow.keras import Sequential from tensorflow.keras.layers import Embedding model = Sequential() model.add(Embedding(batch_size, 64, input_length=30))
هنا ، نحتاج إلى تسطيح طبقة التضمين من أجل ربطها مع meal_type و meal_total:
model.add(Flatten()
يمكننا بعد ذلك استخدام سلسلة من الطبقات الكثيفة لتحويل تلك المصفوفة الكبيرة جدًا إلى مجموعات أصغر ، تنتهي بإخراجنا الذي يتكون من ثلاثة أرقام على سبيل المثال:
model.add(Dense(3, activation="relu"))
نحتاج الآن إلى ربط هذه الأرقام الثلاثة ، والتي تشكل تضمين الجملة للمراجعة مع المدخلات السابقة: [0 ، 0 ، 1 ، 30.5 ، 0.75 ، -0.82 ، 0.45].
للقيام بذلك ، سنستخدم Keras ونطبق نفس الخطوات. يمكن استدعاء الطبقات التي تم إنشاؤها باستخدام Keras ، مما يتيح لنا ربطها معًا بدءًا من طبقة الإدخال . للاستفادة من ذلك ، سنقوم أولاً بتعريف طبقات التضمين والجداول:
embedding_input = Input(shape=(30,)) embedding_layer = Embedding(batch_size, 64)(embedding_input) embedding_layer = Flatten()(embedding_layer) embedding_layer = Dense(3, activation='relu')(embedding_layer) tabular_input = Input(shape=(4,)) tabular_layer = Dense(32, activation='relu')(tabular_input)
لاحظ أننا قمنا بتعريف أجزاء الإدخال لكل من هاتين الطبقتين كمتغيرات خاصة بهما. هذا لأننا نحتاج إلى تمرير طبقات الإدخال عندما نبني نموذجًا بإستخدامKeras .
بعد ذلك ، سننشئ طبقة ربط ، ونغذيها في طبقة المُخرجات الخاصة بنا ، وأخيرًا ننشئ النموذج عن طريق تمرير طبقات الإدخال الأصلية التي حددناها أعلاه:
merged_input = keras.layers.concatenate([embedding_layer, tabular_layer]) merged_dense = Dense(16)(merged_input) output = Dense(1)(merged_dense) model = Model(inputs=[embedding_input, tabular_input], outputs=output) merged_dense = Dense(16, activation='relu')(merged_input) output = Dense(1)(merged_dense) model = Model(inputs=[embedding_input, tabular_input], outputs=output)
الآن لدينا نموذج واحد يقبل مُدخلات متعددة الوسائط.
المقايضات والبدائل
كما رأينا للتو ، يستكشف نمط تصميم المُدخلات متعددة الوسائط كيفية تمثيل تنسيقات الإدخال المختلفة في نفس النموذج. بالإضافة إلى مزج أنواع مختلفة من البيانات ، قد نرغب أيضًا في تمثيل نفس البيانات بطرق مختلفة لتسهيل قيام نموذجنا بتحديد الأنماط.
على سبيل المثال ، قد يكون لدينا حقل تصنيفات على مقياس ترتيبي من نجمة واحدة إلى 5 نجوم ، ونتعامل مع حقل التصنيفات هذا على أنه رقمي وفئوي. هنا ، نشير إلى المدخلات متعددة الوسائط على أنها:
- الجمع بين أنواع مختلفة من البيانات ، مثل الصور + البيانات الوصفية
- تمثيل البيانات المعقدة بطرق متعددة
سنبدأ باستكشاف كيفية تمثيل البيانات الجدولية بطرق مختلفة ، ثم سنلقي نظرة على بيانات النص والصورة.
طرق متعددة للبيانات الجدولية
لمعرفة كيف يمكننا تمثيل البيانات الجدولية بطرق مختلفة لنفس النموذج ، دعنا نعود إلى مثال مراجعة المطعم. سوف نتخيل بدلاً من ذلك أن التقييم هو أحد المدخلات في نموذجنا ونحاول التنبؤ بفائدة المراجعة (عدد الأشخاص الذين أحبوا المراجعة).
كمدخل ، يمكن تمثيل التصنيف كقيمة عدد صحيح تتراوح من 1 إلى 5 وكسمة فئوية. لتمثيل التصنيف بشكل فئوي، يمكننا جمعه في حاويات (bucket it).
الطريقة التي نجمع بها البيانات متروكة لنا وتعتمد على مجموعة البيانات وحالة الاستخدام الخاصة بنا. لتبسيط الأمور ، لنفترض أننا نريد إنشاء مجموعتين: “جيد” و “سيئ”. تتضمن المجموعة “جيدة” التصنيفات 4 و 5 ، و “سيئة” تشمل 3 أو أقل.
يمكننا بعد ذلك إنشاء قيمة منطقية لترميز حاويات التصنيف وربط كل من العدد الصحيح والمنطقي في مصفوفة واحدة (الكود الكامل موجود على GitHub).
إليك ما قد يبدو عليه هذا لمجموعة بيانات صغيرة بها ثلاث نقاط بيانات:
rating_data = [2, 3, 5]
def good_or_bad(rating):
if rating > 3:
return 1
else:
return 0
rating_processed = []
for i in rating_data:
rating_processed.append([i, good_or_bad(i)])
السمة الناتجة عبارة عن مصفوفة مكونة من عنصرين تتكون من تصنيف عدد صحيح وتمثيلها المنطقي:
[[2, 0], [3, 0], [5, 1]]
إذا قررنا بدلاً من ذلك إنشاء أكثر من حاويتين، فسنقوم بإستخدام خوارزمية خط الترميز الأحادي (one-hot encode) على كل مدخل وإلحاق هذه المصفوفة بتمثيل العدد الصحيح.
السبب في أنه من المفيد تمثيل التصنيف بطريقتين هو أن قيمة التصنيف كما تم قياسها من 1 إلى 5 نجوم لا تزيد بالضرورة بشكل خطي. التقييمات 4 و 5 متشابهة جدًا ، وتشير التصنيفات من 1 إلى 3 على الأرجح إلى أن المراجع غير راضٍ.
سواء كنت تعطي شيئًا لا يعجبك 1 أو 2 أو 3 نجوم ، فغالبًا ما يكون مرتبطًا بميول المراجع الخاصة بك بدلاً من المراجعة نفسها. على الرغم من ذلك ، لا يزال من المفيد الاحتفاظ بمعلومات أكثر دقة موجودة في التصنيف النجمي ، وهذا هو سبب ترميزها بطريقتين.
بالإضافة إلى ذلك ، ضع في اعتبارك السمات ذات النطاق الأكبر من 1 إلى 5 ، مثل المسافة بين منزل المراجع والمطعم. إذا كان شخص ما يقود سيارته لمدة ساعتين للذهاب إلى مطعم ، فقد تكون مراجعته أكثر أهمية من شخص قادم من الجانب الآخر من الشارع.
في هذه الحالة ، قد يكون لدينا قيم شاذة ، وبالتالي سيكون من المنطقي أن يتم تحديد عتبة للمسافة يتم تمثيلها رقميا كـ 50 كم بالإضافة إلى تضمين تمثيل منفصل فئوي للمسافة. يمكن تجميع السمة الفئوية في حاويات مثل “من المدينة” و “من البلد” و “من خارج البلد”.
التمثيل المتعدد الوسائط للنص
كل من النص والصور غير منظمين ويتطلبان تحويلات أكثر من البيانات الجدولية. يمكن أن يساعد تمثيلهم بتنسيقات مختلفة نماذجنا في استخراج المزيد من الأنماط. سنبني على مناقشتنا للنماذج النصية من خلال النظر في الأساليب المختلفة لتمثيل البيانات النصية.
طرق متعددة للبيانات النصية
بالنظر إلى الطبيعة المعقدة للبيانات النصية ، هناك العديد من الطرق لاستخراج المعنى منها. يتيح نمط تصميم التضمينات (Embeddings ) للنموذج تجميع الكلمات المتشابهة معًا ، وتحديد العلاقات بين الكلمات ، وفهم العناصر النحوية للنص.
بينما تمثيل النص من خلال تضمين الكلمات يعكس بشكل وثيق كيفية فهم البشر للغة بالفطرة ، هناك تمثيلات نصية إضافية يمكن أن تزيد من قدرة نموذجنا على أداء مهمة تنبؤ معينة.
سنلقي نظرة على نهج حقيبة الكلمات (bag of words) لتمثيل النص ، جنبًا إلى جنب مع استخراج السمات الجدولية من النص.
لإثبات تمثيل البيانات النصية ، سنشير إلى مجموعة بيانات تحتوي على نصوص ملايين الأسئلة والإجابات من Stack Overflow (مجموعة البيانات متوفرة في BigQuery: bigquery-public-data.stackoverflow.posts_questions) جنبًا إلى جنب مع البيانات الوصفية (metadata ) حول كل منشور.
على سبيل المثال ، سوف يعطينا الاستعلام التالي مجموعة فرعية من الأسئلة التي تم وضع علامة عليها كـ “keras” أو “matplotlib” أو “pandas” بالإضافة إلى عدد الإجابات التي تم تلقيها لكل سؤال:
SELECT title, answer_count, REPLACE(tags, "|", ",") as tags FROM `bigquery-public-data.stackoverflow.posts_questions` WHERE REGEXP_CONTAINS( tags, r"(?:keras|matplotlib|pandas)")
ينتج عن الاستعلام الناتج التالي:
| الصف | العنوان | عدد الإجابات | العلامات |
| 1 | Building a new column in a pandas dataframe by matching string values in a list | 6 | python,python-2.7,pandas,replace,nested-loops |
| 2 | Extracting specific selected columns to new DataFrame as a copy | 6 | python,pandas,chained-assignment |
| 3 | Where do I call the BatchNormalization function in Keras? | 7 | python,keras,neural-network,data-science,batch-normalization |
| 4 | Using Excel like solver in Python or SQL | 8 | python,sql,numpy,pandas,solver |
لا يحافظ تمثيل حقيبة الكلمات BOW على ترتيب نصنا ، لكنه يكتشف وجود أو عدم وجود كلمات معينة في كل جزء من النص نرسله إلى نموذجنا.
هذا الأسلوب هو نوع خط الترميز المتعدد (multi-hot encoding) حيث يتم تحويل كل إدخال نصي إلى مصفوفة من 1 و 0. يتوافق كل فهرس في مصفوفة BOW مع كلمة من مفرداتنا.
كيف تعمل حقيبة الكلمات
الخطوة الأولى في ترميز BOW هي اختيار حجم المفردات لدينا ، والتي ستشمل أهم N كلمات الأكثر تكرارا في مجموعة النصوص الخاصة بنا.
من الناحية النظرية ، يمكن أن يكون حجم مفرداتنا مساويًا لعدد الكلمات الفريدة في مجموعة البيانات بأكملها. ومع ذلك ، قد يؤدي هذا إلى مصفوفات إدخال كبيرة جدًا تتكون في الغالب من الأصفار ، نظرًا لأن العديد من الكلمات يمكن أن تكون فريدة لسؤال واحد.
بدلاً من ذلك ، سنرغب في اختيار حجم مفردات صغير بما يكفي لتضمين الكلمات الرئيسية المتكررة التي تنقل المعنى لمهمة التنبؤ لدينا ، ولكنها كبيرة بما يكفي بحيث لا تقتصر مفرداتنا على الكلمات الموجودة في كل سؤال تقريبًا (مثل “ال ،” “هو” و “و” وما إلى ذلك).
سيكون كل مدخل في نموذجنا بعد ذلك مصفوفة بحجم مفرداتنا. وبالتالي فإن تمثيل BOW هذا يتجاهل تمامًا الكلمات غير المدرجة في مفرداتنا. لا يوجد رقم سحري أو نسبة مئوية لاختيار حجم المفردات – من المفيد تجربة القليل منها ومعرفة أيها يحقق أفضل أداء في نموذجنا.
لفهم ترميز حقيبة الكلمات BOW ، دعنا أولاً نلقي نظرة على مثال مبسط. ، لنفترض أننا نتوقع علامة سؤال Stack Overflow من قائمة من ثلاث علامات محتملة: “pandas” و “keras” و “matplotlib”. لتبسيط الأمور ، افترض أن مفرداتنا تتكون من 10 كلمات فقط مذكورة أدناه:
dataframe layer series graph column plot color axes read_csv activation
هذه القائمة هي فهرس الكلمات الخاص بنا ، وكل إدخال نقوم بإدخاله في نموذجنا سيكون مصفوفة من 10 عناصر حيث يتوافق كل فهرس مع إحدى الكلمات المذكورة أعلاه.
على سبيل المثال ، يعني الرقم 1 في الفهرس الأول لمصفوفة الإدخال أن سؤالًا معينًا يحتوي على الكلمة dataframe.
لفهم ترميز حقيبة الكلمات BOW من منظور نموذجنا ، تخيل أننا نتعلم لغة جديدة وأن الكلمات العشر أعلاه هي الكلمات الوحيدة التي نعرفها. كل “توقع” نقوم به سيعتمد فقط على وجود أو عدم وجود هذه الكلمات العشر وسوف نتجاهل أي كلمات خارج هذه القائمة.
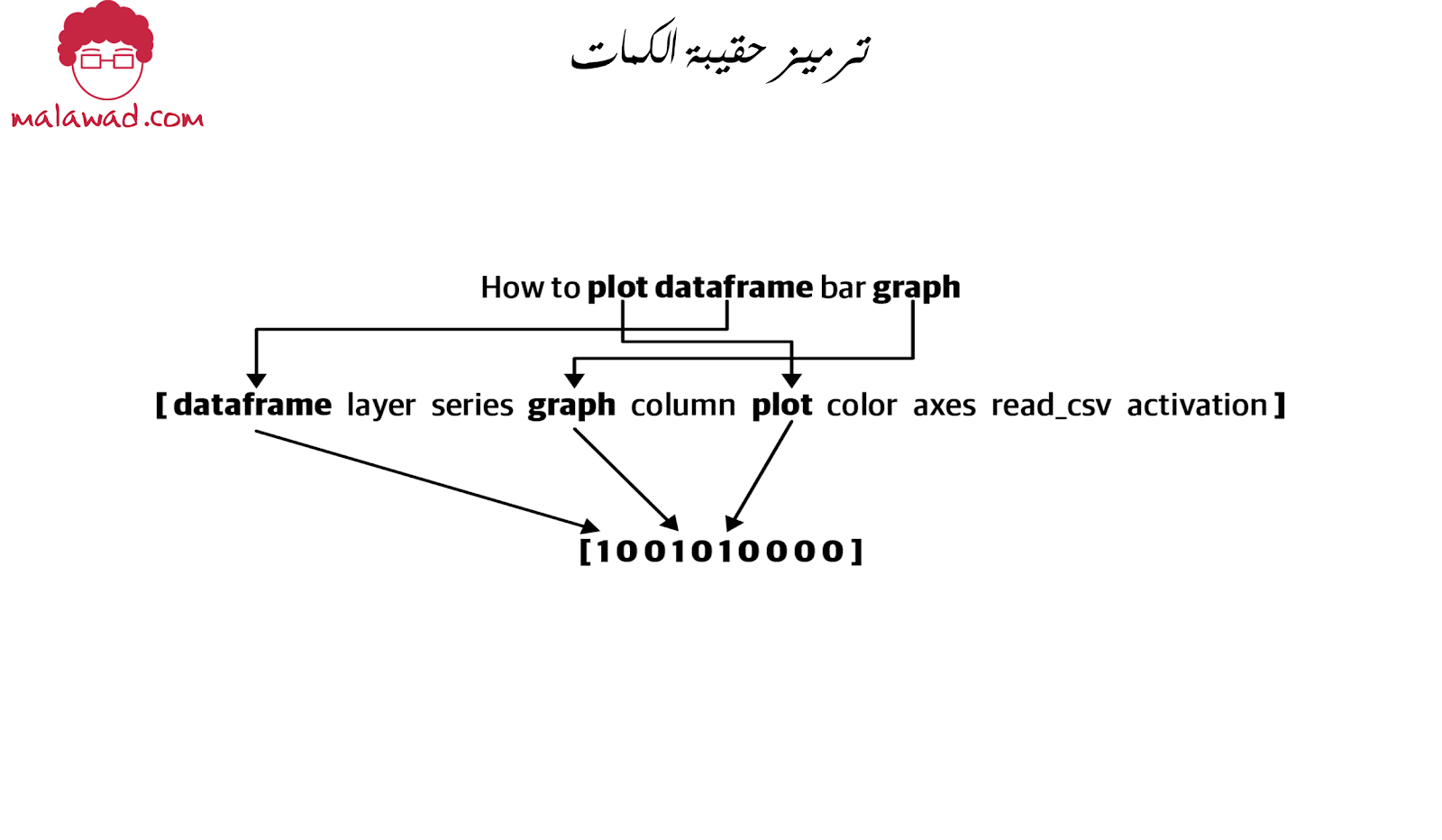
لذلك ، بالنظر إلى عنوان السؤال ، “How to plot dataframe bar graph” ، كيف سنحوله إلى تمثيل BOW؟
أولاً ، دعنا نلاحظ الكلمات الواردة في هذه الجملة والتي تظهر في مفرداتنا: plot وdataframe وgraph. سيتم تجاهل الكلمات الأخرى في هذه الجملة من خلال نهج حقيبة الكلمات. باستخدام فهرس الكلمات أعلاه ، تصبح هذه الجملة:
[1 0 0 1 0 1 0 0 0 0]لاحظ أن الأحاد في هذه المصفوفة تتوافق مع فهرسة dataframe ووgraph و plot على التوالي. للتلخيص ، يوضح الشكل أدناه كيف قمنا بتحويل مدخلاتنا من نص خام إلى مصفوفة مشفرة باستخدام نهج حقيبة الكلمات بناءً على مفرداتنا.
لدى Keras بعض الوظائف المفيدة لترميز النص كحقيبة من الكلمات ، لذلك لا نحتاج إلى كتابة الكود لتحديد أفضل الكلمات من مجموعة النصوص الخاصة بنا وترميز النص الخام إلى مصفوفات متعددة المهام من البداية.
أيهما نختار
نظرًا لوجود طريقتين مختلفتين لتمثيل النص (التضمينات و حقيبة الكلمات) ، ما النهج الذي يجب أن نختاره لمهمة معينة؟ كما هو الحال مع العديد من جوانب تعلم الألة ، يعتمد هذا على مجموعة البيانات الخاصة بنا وطبيعة مهمة التنبؤ الخاصة بنا ونوع النموذج الذي نخطط لاستخدامه.
تضيف التضمينات (Embeddings ) طبقة إضافية إلى نموذجنا وتوفر معلومات إضافية حول معنى الكلمة الغير متوفر في ترميز حقيبة الكلمات.
ومع ذلك ، تتطلب التضمينات تدريبًا (ما لم نتمكن من استخدام التضمينات المُدرَّبة مسبقًا لمشكلتنا). بينما قد يحقق نموذج التعلم العميق دقة أعلى ، يمكننا أيضًا محاولة استخدام ترميز حقيبة الكلمات في الانحدار الخطي أو نموذج شجرة القرار باستخدام إطارات عمل مثل scikit-Learn أو XGBoost.
استخدام ترميز حقيبة الكلمات مع نموذج بسيط قد يكون مفيدًا للنماذج الأولية السريعة أو للتحقق من أن مهمة التنبؤ التي اخترناها ستعمل على مجموعة البيانات الخاصة بنا.
على عكس التضمينات ، لا تأخذ حقيبة الكلمات في الاعتبار ترتيب أو معنى الكلمات في مستند نصي. إذا كان أي من هذين الأمرين مهمًا لمهمة التنبؤ لدينا ، فقد تكون التضمينات هي أفضل طريقة.
قد تكون هناك أيضًا فوائد لبناء نموذج عميق يجمع بين حقيبة الكلمات وتمثيلات تضمين النص لاستخراج المزيد من الأنماط من بياناتنا.
للقيام بذلك ، يمكننا استخدام نهج الإدخال متعدد الوسائط ، باستثناء أنه بدلاً من تسلسل النص والسمات الجدولية ، نستخدم تسلسل تمثيلات التضمين و حقيبة الكلمات . هنا ، سيكون شكل طبقة الإدخال الخاصة بنا هو حجم المفردات لتمثيل BOW. تتضمن بعض فوائد تمثيل النص بطرق متعددة ما يلي:
- يوفر ترميز حقيبة الكلمات (BoW) إشارات قوية لأهم الكلمات الموجودة في مفرداتنا ، بينما يمكن للتضمينات تحديد العلاقات بين الكلمات في مفردات أكبر بكثير.
- إذا كان لدينا نص يقوم بالتبديل بين اللغات ، فيمكننا بناء التضمينات (أو ترميزات حقيبة الكلمات (BoW) ) لكل واحدة وتسلسلها.
- يمكن أن تقوم عمليات التضمين بترميز تكرار الكلمات في النص ، حيث يتعامل حقيبة الكلمات (BoW) مع وجود كل كلمة كقيمة منطقية. لكل التمثيلات ذات قيمة.
- يمكن لترميز حقيبة الكلمات (BoW) تحديد الأنماط بين المراجعات التي تحتوي جميعها على كلمة “مذهلة” ، بينما يمكن أن يتعلم التضمين ربط عبارة “غير مدهش” بمراجعة أقل من المتوسط. مرة أخرى ، كل من هذه التمثيلات ذات قيمة.
استخراج السمات الجدولية من النص
بالإضافة إلى ترميز بيانات النص الخام ، غالبًا ما توجد خصائص أخرى للنص يمكن تمثيلها كسمات جدولية. لنفترض أننا نبني نموذجًا للتنبؤ بما إذا كان سؤال Stack Overflow سيحصل على إجابة أم لا.
قد تكون العوامل المختلفة المتعلقة بالنص والتي لا علاقة لها بالكلمات نفسها ذات صلة بتدريب نموذج على هذه المهمة. على سبيل المثال ، ربما يؤثر طول السؤال أو وجود علامة استفهام على احتمالية الإجابة.
ومع ذلك ، عندما نقوم بإنشاء التضمين ، فإننا عادةً ما نقوم باقتطاع الكلمات إلى طول معين. يتم فقدان الطول الفعلي للسؤال في تمثيل البيانات هذا.
وبالمثل ، غالبًا ما يتم إزالة علامات الترقيم. يمكننا استخدام نمط تصميم المدخلات متعددة الوسائط لإعادة هذه المعلومات المفقودة إلى النموذج.
في الاستعلام التالي ، سنستخرج بعض السمات الجدولية من حقل العنوان لمجموعة بيانات Stack Overflow للتنبؤ بما إذا كان السؤال سيحصل على إجابة أم لا:
SELECT
LENGTH(title) AS title_len,
ARRAY_LENGTH(SPLIT(title, " ")) AS word_count,
ENDS_WITH(title, "?") AS ends_with_q_mark,
IF
(answer_count > 0,
1,
0) AS is_answered,
FROM
`bigquery-public-data.stackoverflow.posts_questions`
| الصف | title_len | word_count | ends_with_q_mark | is_answered |
| 1 | 84 | 14 | true | 0 |
| 2 | 104 | 16 | false | 0 |
| 3 | 85 | 19 | true | 1 |
| 4 | 88 | 14 | false | 1 |
| 5 | 17 | 3 | false | 1 |
بالإضافة إلى هذه السمات المستخرجة مباشرةً من عنوان السؤال ، يمكننا أيضًا تمثيل البيانات الوصفية حول السؤال كسمات.
على سبيل المثال ، يمكننا إضافة سمات تمثل عدد العلامات التي يحتوي عليها السؤال ويوم الأسبوع الذي تم نشره فيه. يمكننا بعد ذلك دمج هذه السمات الجدولية مع نصنا المُرمز وإدخال كلا التمثيلين في نموذجنا باستخدام طبقة الربط من Keras لدمج مصفوفة النص مع ترميز حقيبة الكلمات (BoW) مع البيانات الوصفية المجدولة التي تصف نصنا.
التمثيل متعدد الوسائط للصور
هناك العديد من الطرق لتمثيل بيانات الصورة عند تحضيرها لنموذج تعلم الألة . مثل النص الخام ، لا يمكن تغذية الصور مباشرة في نموذج ونحتاج إلى تحويلها إلى تنسيق رقمي يمكن للنموذج فهمه.
سنبدأ بمناقشة بعض الأساليب الشائعة لتمثيل بيانات الصورة: كقيم بكسل ، وكمجموعات من المربعات ، وكمجموعات من التسلسلات ذات الإطارات. يوفر نمط تصميم المدخلات متعددة الوسائط طريقة لاستخدام أكثر من تمثيل للصورة في نموذجنا.
الصور كقيم نقاط ضوئية
الصور في جوهرها عبارة عن صفوف من قيم البكسل. تحتوي الصورة بالأبيض والأسود ، على سبيل المثال ، على قيم بكسل تتراوح من 0 إلى 255. لذلك يمكننا تمثيل صورة 28 × 28 بكسل بالأبيض والأسود في نموذج كمصفوفة 28 × 28 بقيم صحيحة تتراوح من 0 إلى 255.
في هذا القسم ، سنشير إلى مجموعة بيانات MNIST ، وهي مجموعة بيانات شائعة تتضمن صورًا لأرقام مكتوبة بخط اليد.
يمكننا تمثيل صور MNIST الخاصة بنا لقيم البكسل باستخدام طبقة Flatten ، والتي تعمل على تسطيح الصورة في مصفوفة عناصرها 784 (28 * 28) أحادية البعد:
layers.Flatten(input_shape=(28, 28))
بالنسبة للصور الملونة ، يصبح هذا الأمر أكثر تعقيدًا. لكل نقطة ضوئية في الصورة الملونه ثلاث قيم — واحدة للأحمر والأخضر والأزرق. إذا كانت صورنا في المثال أعلاه ملونة بدلاً من ذلك ، فسنضيف بُعدًا ثالثًا إلى شكل إدخال النموذج بحيث يكون:
layers.Flatten(input_shape=(28, 28, 3))
بينما تمثيل الصور كمصفوفات من قيم النقاط الضوئية يعمل جيدًا للصور البسيطة مثل الصور ذات التدرج الرمادي في مجموعة بيانات MNIST ، فإنها تبدأ في الانهيار عندما نقدم صورًا ذات حواف وأشكال أكثر في كل مكان.
عندما يتم تغذية شبكة بجميع وحدات النقاط الضوئية الموجودة في صورة ما في وقت واحد ، يصعب عليها التركيز على مناطق أصغر من وحدات النقاط الضوئية المجاورة التي تحتوي على معلومات مهمة.
الصور كهياكل مبلطة
نحن بحاجة إلى طريقة لتمثيل صور أكثر تعقيدًا في العالم الحقيقي ليمكن نموذجنا من استخراج تفاصيل ذات مغزى وفهم الأنماط. إذا قمنا بتغذية الشبكة بأجزاء صغيرة فقط من الصورة في كل مرة ، فمن المرجح أن تحدد أشياء مثل التدرجات والحواف المكانية الموجودة في وحدات البكسل المجاورة. الهندسة النموذجية الشائعة لإنجاز ذلك هي الشبكة العصبية التلافيفية (convolutional neural network) أو (CNN).
يوفر Keras طبقات اللف الرياضي لبناء نماذج تقسم الصور إلى أجزاء أصغر ذات إطارات. لنفترض أننا نبني نموذجًا لتصنيف الصور الملونة 28 × 28 على أنها إما “كلب” أو “قطة”.
نظرًا لأن هذه الصور ملونة ، فسيتم تمثيل كل صورة كمصفوفة 28 × 28 × 3 أبعاد ، لأن كل بكسل له ثلاث قنوات لونية. إليك كيفية تحديد مدخلات هذا النموذج باستخدام طبقة التفاف و API التسلسلي:
Conv2D(filters=16, kernel_size=3, activation='relu', input_shape=(28,28,3))
في هذا المثال ، نقسم الصور المدخلة إلى أجزاء 3 × 3 قبل تمريرها عبر طبقة تجميع قصوى. يسمح بناء بنية نموذجية تقسم الصور إلى أجزاء من النوافذ المنزلقة لنموذجنا بالتعرف على تفاصيل أكثر دقة في صورة مثل الحواف والأشكال.
الجمع بين تمثيلات الصور المختلفة
بالإضافة إلى ذلك ، كما هو الحال مع حقيبة الكلمات وتضمين النص ، قد يكون من المفيد تمثيل نفس بيانات الصورة بطرق متعددة. مرة أخرى ، يمكننا تحقيق ذلك باستخدام واجهة برمجة تطبيقات Keras الوظيفية.
إليك كيفية دمج قيم النقاط الضوئية لدينا مع تمثيل النافذة المنزلقة باستخدام طبقة الربط في Keras:
# Define image input layer (same shape for both pixel and tiled
# representation)
image_input = Input(shape=(28,28,3))
# Define pixel representation
pixel_layer = Flatten()(image_input)
# Define tiled representation
tiled_layer = Conv2D(filters=16, kernel_size=3,
activation='relu')(image_input)
tiled_layer = MaxPooling2D()(tiled_layer)
tiled_layer = tf.keras.layers.Flatten()(tiled_layer)
# Concatenate into a single layer
merged_image_layers = keras.layers.concatenate([pixel_layer, tiled_layer])
لتحديد نموذج يقبل تمثيل المدخلات متعدد الوسائط ، يمكننا بعد ذلك تغذية الطبقة المتسلسلة في طبقة الإخراج لدينا:
merged_dense = Dense(16, activation='relu')(merged_image_layers) merged_output = Dense(1)(merged_dense) model = Model(inputs=image_input, outputs=merged_output)
يعتمد اختيار تمثيل الصور المراد استخدامه أو ما إذا كان سيتم استخدام التمثيلات متعددة الوسائط إلى حد كبير على نوع بيانات الصورة التي نعمل معها.
بشكل عام ، كلما كانت صورنا أكثر تفصيلاً ، زادت احتمالية رغبتنا في تمثيلها في نوافذ منزلقة لتقسيمها. بالنسبة لمجموعة بيانات MNIST ، قد يكفي تمثيل الصور كقيم بكسل وحدها.
من ناحية أخرى ، مع الصور الطبية المعقدة ، قد نرى دقة متزايدة من خلال الجمع بين تمثيلات متعددة. لماذا الجمع بين تمثيلات الصور المتعددة؟ يتيح تمثيل الصور كقيم نقاط ضوئية للنموذج تحديد نقاط التركيز ذات المستوى الأعلى في صورة مثل الكائنات السائدة عالية التباين. من ناحية أخرى ، تساعد التمثيلات المتجانبة النماذج على تحديد حواف وأشكال أكثر دقة وأقل تباينًا.
استخدام الصور مع البيانات الوصفية
ناقشنا سابقًا أنواعًا مختلفة من البيانات الوصفية التي قد تكون مرتبطة بالنص ، وكيفية استخراج هذه البيانات الوصفية وتمثيلها كسمات جدولية لنموذجنا. يمكننا أيضًا تطبيق هذا المفهوم على الصور.
للقيام بذلك ، دعنا نعود إلى المثال النموذج الذي يستخدم لقطات لتقاطع للتنبؤ بما إذا كان يحتوي على مخالفة مرورية أم لا.

يمكن لنموذجنا استخراج العديد من الأنماط من صور حركة المرور بمفردها ، ولكن قد تكون هناك بيانات أخرى متاحة يمكنها تحسين دقة نموذجنا.
على سبيل المثال ، ربما لا يُسمح بسلوك معين (على سبيل المثال ، انعطاف يمين بينما الإشارة حمراء) أثناء ساعة الذروة ولكنه لا بأس به في أوقات أخرى من اليوم. أو ربما يكون السائقون أكثر عرضة لانتهاك قوانين المرور في الأحوال الجوية السيئة. إذا كنا نجمع بيانات الصورة من تقاطعات متعددة ،
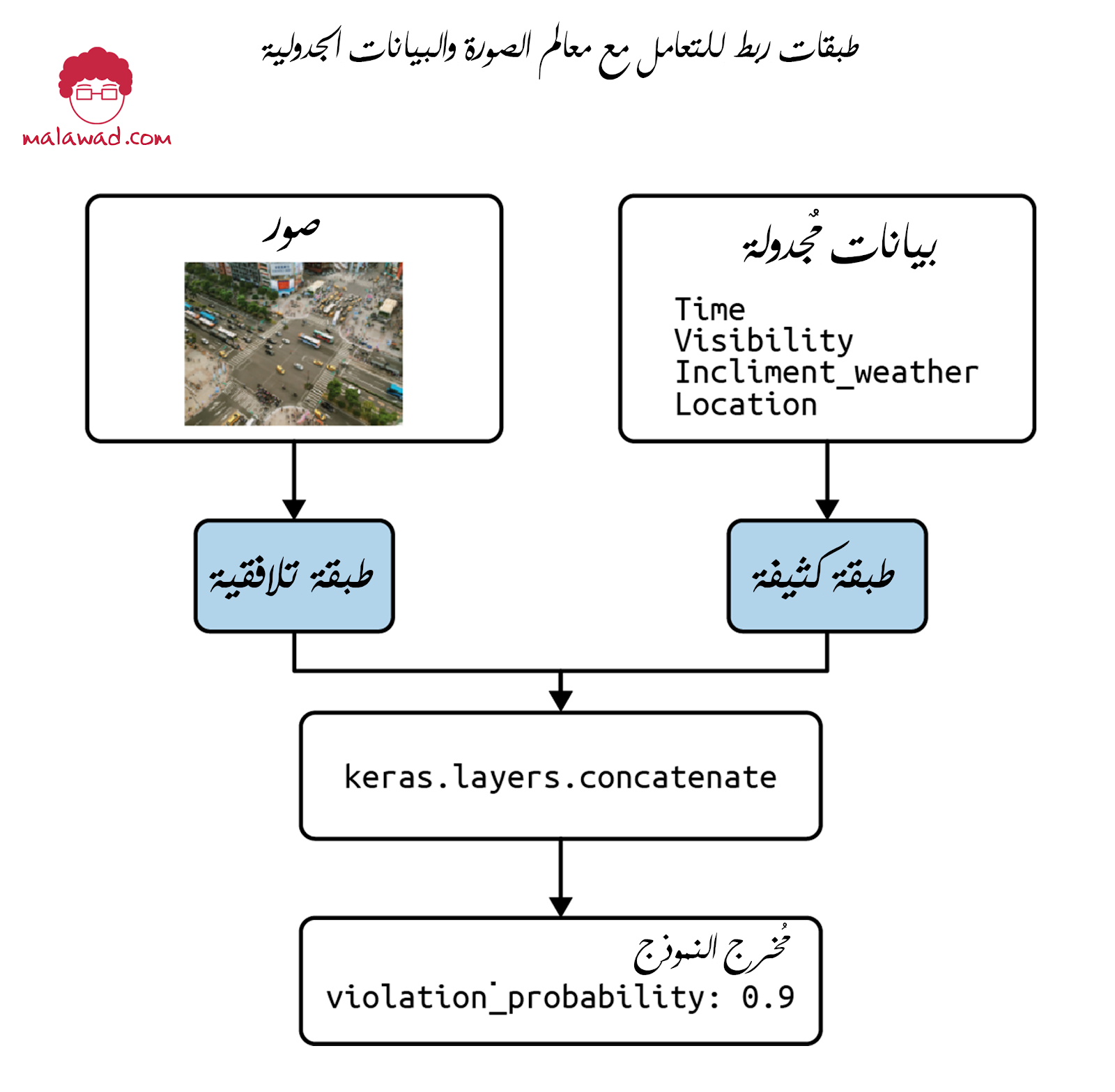
لقد حددنا الآن ثلاث سمات جدولة إضافية يمكن أن تعزز نموذج الصورة لدينا:
- وقت اليوم
- الجو
- الموقع
بعد ذلك ، دعنا نفكر في التمثيلات الممكنة لكل من هذه السمات. يمكننا تمثيل الوقت كرقم صحيح يشير إلى ساعة اليوم. قد يساعدنا ذلك في تحديد الأنماط المرتبطة بأوقات الازدحام الشديد مثل ساعة الذروة. في سياق هذا النموذج ، قد يكون من المفيد معرفة ما إذا كان هناك ظلام عند التقاط الصورة أم لا. في هذه الحالة ، يمكننا تمثيل الوقت كسمة منطقية.
يمكن أيضًا تمثيل الطقس بطرق مختلفة ، كقيم عددية وفئوية. يمكننا تضمين درجة الحرارة كسمة ، ولكن في هذه الحالة ، قد تكون الرؤية أكثر فائدة. هناك خيار آخر لتمثيل الطقس وهو من خلال متغير فئوي يشير إلى وجود المطر أو الثلج.
إذا كنا نجمع البيانات من العديد من المواقع ، فسنرغب على الأرجح في ترميزها كسمة أيضًا. قد يكون هذا أكثر منطقية كسمة فئوية ، وقد يكون حتى سمات متعددة (مدينة ، دولة ، ولاية ، إلخ) اعتمادًا على عدد المواقع التي نجمع لقطات منها.
في هذا المثال ، لنفترض أننا نرغب في استخدام السمات الجدولية التالية:
- الوقت كساعة من اليوم (عدد صحيح)
- الرؤية (رقم عائم)
- طقس عاصف (فئوي: مطر ، ثلج ، لا شيء)
- معرف الموقع (فئوي مع خمسة مواقع محتملة)
إليك ما قد تبدو عليه مجموعة فرعية من مجموعة البيانات هذه للأمثلة الثلاثة:
data = {
'time': [9,10,2],
'visibility': [0.2, 0.5, 0.1],
'inclement_weather': [[0,0,1], [0,0,1], [1,0,0]],
'location': [[0,1,0,0,0], [0,0,0,1,0], [1,0,0,0,0]]
}
يمكننا بعد ذلك دمج هذه السمات المجدولة في مصفوفة واحدة لكل مثال ، بحيث يكون شكل إدخال نموذجنا هو 10. تبدو مصفوفة الإدخال للمثال الأول كما يلي:
[9 ، 0.2 ، 0 ، 0 ، 1 ، 0 ، 1 ، 0 ، 0 ، 0]يمكننا تغذية هذا الإدخال في طبقة كثيفة متصلة بالكامل ، وسيكون ناتج نموذجنا قيمة واحدة بين 0 و 1 تشير إلى ما إذا كان المثيل يحتوي على انتهاك لحركة المرور أم لا.
لدمج هذا مع بيانات الصور الخاصة بنا ، سنستخدم نهجًا مشابهًا لما ناقشناه للنماذج النصية. أولاً ، سنقوم بتعريف طبقة التفاف للتعامل مع بيانات الصورة الخاصة بنا ، ثم طبقة كثيفة للتعامل مع بياناتنا المجدولة ، وأخيرًا بحمعهما كلاهما في إخراج واحد.
تمثيلات السمات متعددة الوسائط و شرح النموذج
من الصعب بطبيعتها شرح نماذج التعلم العميق. إذا قمنا ببناء نموذج يحقق دقة 99٪ ، فإننا ما زلنا لا نعرف بالضبط كيف يقوم نموذجنا بعمل تنبؤات ، وبالتالي ، سواءً كانت الطريقة التي يتخذ بها تلك التنبؤات صحيحة.
على سبيل المثال ، لنفترض أننا قمنا بتدريب نموذج على صور لأطباق بتريه مأخوذة في معمل وتم تحقيق درجة دقة عالية. تحتوي هذه الصور أيضًا على تعليقات توضيحية من العالم الذي التقط الصور. ما لا نعرفه هو أن النموذج يستخدم التعليقات التوضيحية بشكل غير صحيح لعمل تنبؤاته ، بدلاً من محتويات أطباق البتري.
هناك العديد من الأساليب لشرح نماذج الصور التي يمكنها تمييز النقاط الضوئية التي تشير إلى تنبؤ النموذج. عندما نقوم بدمج تمثيلات بيانات متعددة في نموذج واحد ، فإن هذه السمات تصبح معتمدة على بعضها البعض. نتيجة لذلك ، قد يكون من الصعب شرح كيفية قيام النموذج بالتنبؤات..













إضافة تعليق