
في يوم الاثنين الموافق 5 ديسمبر 2016 ، الساعة 2:30 مساءً ، قدم إيان جودفيلو من Google Brain محاضرة بعنوان “شبكات الخصومة التوليدية” في مؤتمر أنظمة معالجة المعلومات العصبية (NIPS) في برشلونة .1 الأفكار التي عرضها في المحاضرة تعتبر اليوم أحد نقاط التحول الرئيسية للنمذجة التوليدية و التي أدت لظهور الكثير من الأفكار المتنوعه المبنيع على فكرته الأساسية التي دفعت المجال إلى مستويات أعلى.
في المقال الخامس من سلسلة شبكات الخصومة التوليدية سنتعلم أساسيات شبكات الخصومة التوليدية (generative adversarial networks) من هنا فصاعداً سنقوم بإستخدام اللفظ (GANs). كما سنقوم بإنشاء GANs في كيراس (Keras) … لكن في البداية قصة:
مخلوقات جي
في ظهيرة أحد الأيام ، أثناء تمشيه في الغابة ، شاهد وليد امرأة تتنقل خلال مجموعة من الصور بالأبيض والأسود ، و بدى عليها القلق . فذهب و سألها إذا ما كانت بحاجة للمساعدة.
عرفت المرأة نفسها على أنها ميز ، وهي مستكشفة ، ووضحت أنها تبحث عن المخلوق الغامض ، وهو مخلوق أسطوري يقال إنه يتجول في الغابة. بما أن المخلوق ليلي ، فهي لا تملك سوى مجموعة من الصور الليلية له و التي وجدتها ذات مرة ملقاة على أرض الغابة ، أسقطها مستكشف آخر. تجني دي أموالًا عن طريق بيع الصور لهواة جمع الصور ولكنها بدأت تقلق ، لأنها لم تر المخلوقات بنفسها وتشعر بالقلق من تعثر أعمالها إذا لم تستطع إلتقاط المزيد من الصور قريبًا.

كونه مصورًا محنك ، قرر وليد مساعدة ميز بحيث سيقوم ببالبحث عن المخلوقات بنفسه وإعطائها أي صور يلتقطها
ومع ذلك، هناك مشكلة. نظرًا لأن وليد لم ير أبدًا صورة متحركة ، فهو لا يعرف كيفية إنتاج صور جيدة للمخلوق ، وأيضًا ، نظرًا لأن ميز قد باعت الصور التي عثرت عليها فقط ، فلا يمكنها حتى معرفة الفرق بين صورة جيدة للمخلوق و صورة لا شيئ .
بدءًا من حالة الجهل هذه ، كيف يمكنهم العمل معًا للتأكد من أن وليد قادر في النهاية على إنتاج صور رائعة للمخلوق ؟
قاما بتكوين إطار العمل الآتي :
- في كل ليلة ، يلتقط وليد 64 صورة ، كل منها في موقع مختلف مع قراءات عشوائية مختلفة لضوء القمر ، ويخلطها مع 64 صورة مختلفة للمخلوق من المجموعة الأصلية.
- ثم تنظر ميز إلى هذه المجموعة من الصور وتحاول أن تخمن بين الصور التي التقطها وليد والصور في المجموعه أصلية. بناءً على أخطائها ، تحدّث فهمها لكيفية التمييز بين صور وليد والصور الأصلية.
- بعد ذلك ، يلتقط وليد 64 صورة أخرى ويطلعها عليها . تمنح ميز كل صورة درجة بين 0 و 1 ، تشير إلى مدى ثقتها أن الصورة واقعية.
- استنادًا إلى هذه التعليقات ، يقوم وليد بتحديث الإعدادات على الكاميرا الخاصة به لضمان أنه في المرة القادمة ، سيلتقط صورًا من المرجح أن تقوم ميز بمنحها تقييم أفضل.

تستمر هذه العملية لعدة أيام. في البداية ، لا يحصل وليد على أي تعليقات مفيدة من ميز ، لأنها تخمن بشكل عشوائي الصور الأصلية. ومع ذلك ، بعد أسابيع قليلة من التدريب ، تتحسن تدريجياً في هذا الأمر ، مما يعني أنها يمكن أن تقدم تعليقات أفضل لوليد حتى يتمكن من تعديل إعدادات الكاميرا وفقًا لذلك. وهذا يجعل مهمة ميز أصعب ، نظرًا لأن صور وليد الآن ليس من السهل تمييزها عن الصور الحقيقية ، لذلك يجب عليها تستمر في التعلم و التحسن. تستمر هذه العملية على مدار أيام وأسابيع عديدة.
بمرور الوقت ،يتحسن وليد بشكل ملحوظ في إنتاج صور المخلوق الليلي ، لدرجة ان ميز أقرت بانها لا تستطيع التفريق بين صور وليد و الصور الأصلية. بعد ذلك يعرض كل من وليد و ميز الصور في مزاد ولا يستطيع الخبراء تصديق جودة الصور الجديدة – فهم مقنعون مثل الصور الأصلية.

مقدمة في الشبكات الخصومة التوليدية (Generative Adversarial Networks)
ببساطة ، GAN هي معركة بين خصمين ، المولد (generator) والمميز (discriminator). يحاول المولد تحويل الضجيج العشوائي إلى ملاحظات تبدو كما لو كانت قد أخذت من عينات مجموعة البيانات الأصلية ويحاول المميز التنبؤ بما إذا كانت الملاحظة تأتي من مجموعة البيانات الأصلية أو أنها من تزوير المولد. ويبين الصورة أدناه أمثلة على المدخلات والمخرجات للشبكتين.

في بداية العملية ، يقوم المولد بإنتاج صور ضوضائية ويتنبأ المميز بشكل عشوائي. يكمن مفتاح شبكات الخصومة التوليدية في الطريقة التي نتبادل بها تدريب الشبكتين ، بحيث يصبح المولد أكثر مهارة في خداع المميّز ، بينما يجب على المميز التكيف من أجل الحفاظ على قدرته على تحديد الملاحظات المزيفة بشكل صحيح. هذا يدفع المولد لإيجاد طرق جديدة لخداع المميّز ، وهكذا تستمر الدورة.
لمشاهدة هذا عمليًا ، دعنا نبدأ في إنشاء أول شبكة خصومة توليدية في Keras ، لإنشاء صور المخلوقات الليلية
تدريب شبكة الخصومة التوليدية
في البداية، ستحتاج إلى تنزيل بيانات التدريب. سنستخدم مجموعة بيانات Quick, Draw من غوغل. هذه مجموعة من رسومات بالأسود و الأبيض حجمها 28 × 28 بكسل ، مرتبة حسب الموضوع . تم جمع مجموعة البيانات كجزء من لعبة على الإنترنت تتحدى اللاعبين لرسم صورة ، بينما تحاول الشبكة العصبية تخمين موضوع هذه الرسومات. إنها مجموعة بيانات مفيدة وممتعة حقًا لتعلم أساسيات التعلم العميق. في حالتنا ، ستحتاج إلى تنزيل ملف الجمل وحفظه. بالنسبة لـ GAN ، نعيد قياس البيانات إلى النطاق [–1 ، 1].
و هنا نظرة عامة في معمارية شبكة الخصومة التوليدية المستخدمة في الكود المرافق لهذه المقالة :
gan = GAN(input_dim = (28,28,1)
, discriminator_conv_filters = [64,64,128,128]
, discriminator_conv_kernel_size = [5,5,5,5]
, discriminator_conv_strides = [2,2,2,1]
, discriminator_batch_norm_momentum = None
, discriminator_activation = 'relu'
, discriminator_dropout_rate = 0.4
, discriminator_learning_rate = 0.0008
, generator_initial_dense_layer_size = (7, 7, 64)
, generator_upsample = [2,2, 1, 1]
, generator_conv_filters = [128,64, 64,1]
, generator_conv_kernel_size = [5,5,5,5]
, generator_conv_strides = [1,1, 1, 1]
, generator_batch_norm_momentum = 0.9
, generator_activation = 'relu'
, generator_dropout_rate = None
, generator_learning_rate = 0.0004
, optimiser = 'rmsprop'
, z_dim = 100
)
دعونا نلقي نظرة أولاً على كيفية بناء المميّز.
المميّز (The Discriminator)
هدف المميّز هو التنبؤ بما إذا كانت الصورة حقيقية أم مزيفة. هذه مشكلة تصنيف صور خاضعة للإشراف ، لذا يمكننا استخدام نفس معمارية شبكات اللف الرياضية : و هي عبارة عن طبقات لف رياضي مكدسة ، متبوعة بطبقة إخراج كثيفة.
في ورقة GAN الأصلية ، تم استخدام طبقات كثيفة بدلاً من طبقات اللف الرياضي ( الطبقات التلافيفية ). ومع ذلك ، فقد ثبت منذ ذلك الحين أن الطبقات التلافيفية تعطي قوة تنبؤية أكبر للمميز. , ويطلق على هذا النوع من شبكات الخصومة التوليدية مسمى شبكة الخصومة التوليفية التوليدية العميقة (deep convolutional generative adversarial network) أو بإختصار DCGAN ، ولكن تحتوي جميع معماريات GAN على طبقات اللف الرياضي ( الطبقات التلافيفية ) ، لذلك لا يتم تضمين “DC”
المعمارية الكاملة كالأتي :
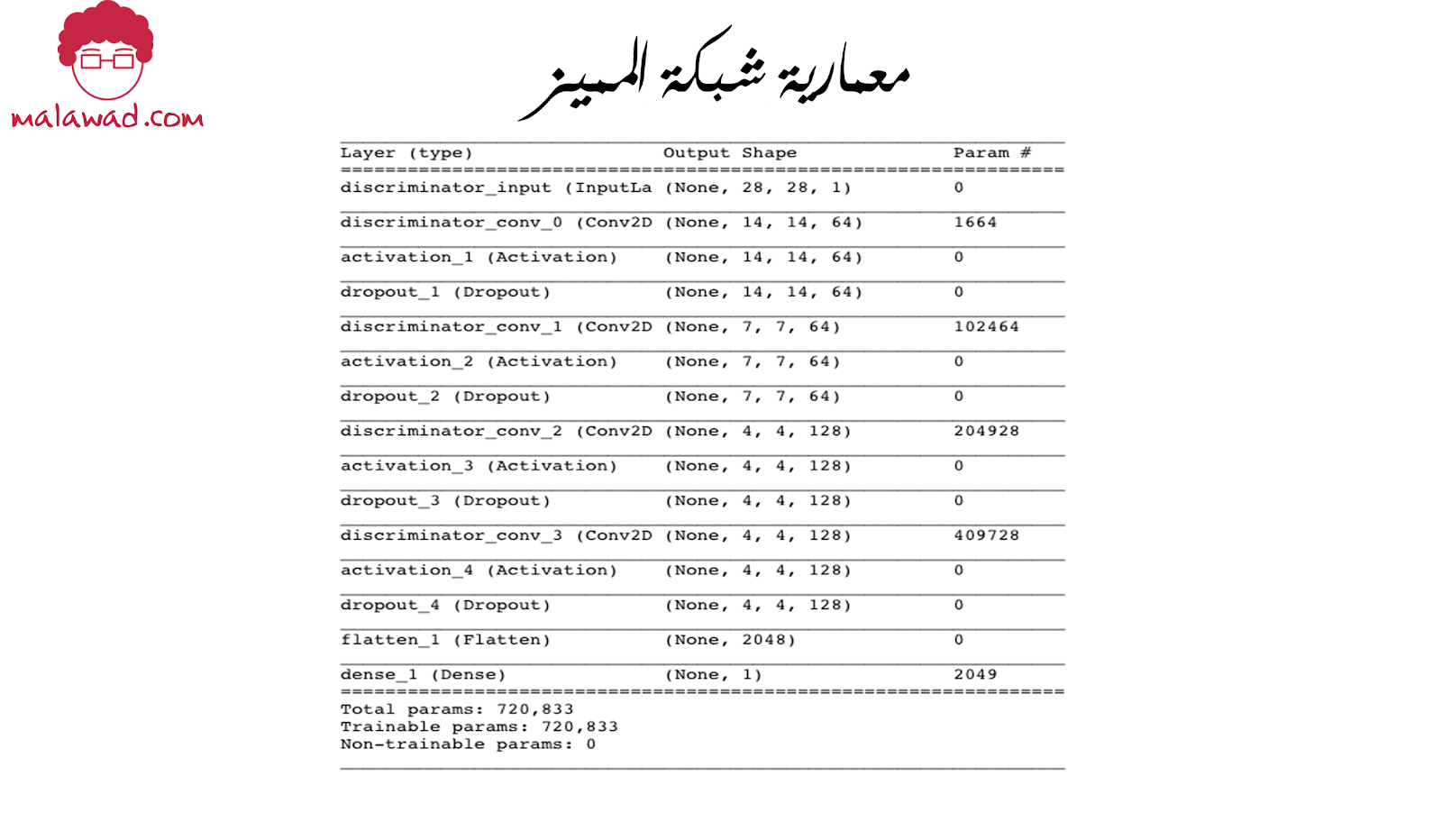
و كود بناء شبكة المميز كالأتي :
discriminator_input = Input(shape=self.input_dim, name='discriminator_input')
x = discriminator_input #1
for i in range(self.n_layers_discriminator): #2
x = Conv2D(
filters = self.discriminator_conv_filters[i]
, kernel_size = self.discriminator_conv_kernel_size[i]
, strides = self.discriminator_conv_strides[i]
, padding = 'same'
, name = 'discriminator_conv_' + str(i)
)(x)
if self.discriminator_batch_norm_momentum and i > 0:
x = BatchNormalization(momentum = self.discriminator_batch_norm_momentum)(x)
x = Activation(self.discriminator_activation)(x)
if self.discriminator_dropout_rate:
x = Dropout(rate = self.discriminator_dropout_rate)(x)
x = Flatten()(x) #3
discriminator_output= Dense(1, activation='sigmoid'
, kernel_initializer = self.weight_init)(x) #4
discriminator = Model(discriminator_input, discriminator_output) #5
1- حدد المدخلات للمميز (الصورة).
2- كدس طبقات تلافيفية فوق بعضها البعض.
3- قم بتسطيح آخر طبقة لف لرياضي ( طبقة تلافيفية ) إلى متجه.
4- طبقة كثيفة من وحدة واحدة ، مع دالة التنشيط سيغمويد التي تحول الناتج من الطبقة الكثيفة إلى النطاق [0 ، 1].
5- نموذج Keras الذي يحدد شبكة المميز وهو نموذج يأخذ صورة إدخال ويخرج رقمًا واحدًا بين 0 و 1.
لاحظ كيف نستخدم مقدار خطوة 2 في بعض الطبقات التلافيفية لتقليل حجم التنسور أثناء مروره عبر الشبكة ، ولكن نقوم بزيادة عدد القنوات (1 في صورة الإدخال بتدرج الرمادي ، ثم 64 ، ثم 128).
تضمن دالة التنشيط السيغمويد في الطبقة النهائية أن الناتج يتم قياسه بين 0 و 1. وسيكون هذا هو الاحتمال المتوقع أن تكون الصورة حقيقية.
المولد (The Generator)
الآن دعونا نبني المولد. المدخل إلى المولد عبارة عن متجه (Vector) ، وعادة ما يتم استخلاصه من التوزيع الطبيعي متعدد المتغيرات. أما المخرج هو صورة بنفس حجم الصورة في بيانات التدريب الأصلية.
قد يذكرك هذا الوصف بشبكة فك التشفير الموجودة في شبكة الترميز التلقائي المتغيرة. في الواقع ، تفي شبكة المولد في شبكات الخصومة التوليدية بنفس الغرض تمامًا مثل شبكة فك التشفير في شبكات الترميز التلقائي المتغيره : وهو تحويل متجه في الفضاء الكامن إلى صورة. يعد مفهوم التعيين من الفضاء الكامن إلى المجال الأصلي شائعًا جدًا في النمذجة التوليدية لأنه يمنحنا القدرة على التعامل مع المتجهات في الفضاء الكامن لتغيير السمات عالية المستوى للصور في المجال الأصلي.
المعمارية الكاملة كالأتي :

قبل وصف الكود المستخدم لبناء هذه الشبكة نحتاج إلى تقديم نوع جديد من الطبقات وهو : طبقة الاختزال.
طبقة الاختزال (Upsampling)
في شبكات الترميز التلقائي المتغيره الذي قمنا ببنائه في مقال السابق ، ضاعفنا عرض وارتفاع التنسور في كل طبقة باستخدام طبقات اللف الرياضية التناقليه مع مقدار خطوة 2. وهذا سمح لنا بإدخل قيم صفرية بين وحدات البكسل قبل إجراء عمليات الالتفاف.
في GAN هذا ، نستخدم طبقة الإختزال في كيراس تسمى Upsampling2D بدلاً من ذلك لمضاعفة عرض وارتفاع التسنور. هذا ببساطة يكرر كل صف وعمود من المدخلات من أجل مضاعفة الحجم. ثم نتبع ذلك بطبقة تلافيفية عادية بخطوة 1 لإجراء عملية الالتفاف. إنها فكرة مشابهة ، ولكن بدلاً من ملء الفجوات بين البيكسلات بالأصفار ، فإن الاختزال يكرر فقط قيم البكسل الموجودة.
كلتا الطريقتين – Upsampling + Conv2D و Conv2DTranspose – هما طريقتان مقبولتان للعودة إلى مجال الصورة الأصلي. و يبقى لنا التجريب لتحديد أيهما سيعطي أفضل نتائج في المسائل الخاصة بنا. لقد ثبت أن طريقة Conv2DTranspose يمكن أن تؤدي إلى وجود شوائب في الصورة الناتجة و التي تفسد جودتها . ومع ذلك ، لا تزال تُستخدم في العديد من أكثر شبكات GAN إثارة للإعجاب وأثبتت أنها أداة قوية في صندوق أدوات ممارس التعلم العميق.

generator_input = Input(shape=(self.z_dim,), name='generator_input') #1
x = generator_input
x = Dense(np.prod(self.generator_initial_dense_layer_size))(x) #2
if self.generator_batch_norm_momentum:
x = BatchNormalization(momentum = self.generator_batch_norm_momentum)(x)
x = Activation(self.generator_activation)(x)
x = Reshape(self.generator_initial_dense_layer_size)(x) #3
if self.generator_dropout_rate:
x = Dropout(rate = self.generator_dropout_rate)(x)
for i in range(self.n_layers_generator): #4
x = UpSampling2D()(x)
x = Conv2D(
filters = self.generator_conv_filters[i]
, kernel_size = self.generator_conv_kernel_size[i]
, padding = 'same'
, name = 'generator_conv_' + str(i)
)(x)
if i < n_layers_generator - 1: #5
if self.generator_batch_norm_momentum:
x = BatchNormalization(momentum = self.generator_batch_norm_momentum))(x)
x = Activation('relu')(x)
else:
x = Activation('tanh')(x)
generator_output = x
generator = Model(generator_input, generator_output) #6
1- تحديد المدخلات للمولد – متجه طوله 100.
2- نتبع ذلك بطبقة كثيفة تتكون من 3136 وحدة
3- التي ، بعد تطبيق تسوية الحزم و دالة تنشيط ReLU ، يتم إعادة تشكيلها إلى موتر 7 × 7 × 64.
4- نقوم بتمرير هذا من خلال أربع طبقات Conv2D ، أول طبقتين مسبوقتين بطبقات Upsampling2D ، لإعادة تشكيل التنسور إلى 14 × 14 ، ثم 28 × 28 (حجم الصورة الأصلي). في الكل ما عدا الطبقة الأخيرة ، نستخدم تسوية الحزم و دالة تنشيط ReLU (يمكن أيضًا استخدام LeakyReLU).
5- بعد طبقة Conv2D النهائية ، نستخدم دالة تنشيط tanh لتحويل الإخراج إلى النطاق [–1 ، 1] ، لمطابقة مجال الصورة الأصلي.
6- نموذج Keras الذي يحدد المولد – نموذج يقبل متجهًا بطول 100 ويخرج موترًا للشكل [28 ، 28 ، 1].
تدريب شبكة الخصومة التوليدية
كما رأينا ، فإن معمارية المولد والمميز في شبكة الخصومة التوليدية بسيطة للغاية ولا تختلف كثيرًا عن النماذج التي نظرنا إليها في المقالات السابقة . مفتاح فهم شبكات GAN هو فهم عملية التدريب.
يمكننا تدريب المميز من خلال إنشاء مجموعة تدريب حيث يتم اختيار بعض الصور بشكل عشوائي من الملاحظات الحقيقية من مجموعة التدريب وبعضها عبارة عن مخرجات من المولد. ستكون الاستجابة 1 للصور الحقيقية و 0 للصور التي تم إنشاؤها. إذا تعاملنا مع هذا على أنها مسألة تعلم خاضعة للإشراف ، فيمكننا تدريب المميز على معرفة كيفية التمييز بين الصور الأصلية والمولدة ، وإخراج القيم بالقرب من 1 للصور الحقيقية والقيم بالقرب من 0 للصور المزيفة.
يعد تدريب المولد أكثر صعوبة حيث لا توجد مجموعة تدريب تخبرنا بالصورة الحقيقية التي يجب تعيين نقطة معينة في الفضاء الكامن إليها. بدلاً من ذلك ، نريد فقط الصورة التي تم إنشاؤها لخداع المميز – أي عندما يتم تغذية الصورة كمدخل إلى المميز، نريد أن يكون الناتج قريبًا من 1.
لذلك ، لتدريب المولد ، يجب علينا أولاً توصيله بالمميز لإنشاء نموذج Keras يمكننا تدريبه. على وجه التحديد ، نقوم بتغذية المخرج من المولد (صورة 28 × 28 × 1) في المميز بحيث يكون الناتج من هذا النموذج المشترك هو احتمال أن تكون الصورة المولدة حقيقية ، وفقًا للمميز. يمكننا تدريب هذا النموذج المركب عن طريق إنشاء مجموعات تدريب تتكون من متجهات كامنة لها 100بُعد تم إنشاؤها عشوائيًا كمدخلات واستجابة مضبوطة على 1 ، لأننا نريد تدريب المولد لإنتاج الصور التي يعتقد المميّز أنها حقيقية.
عندئذٍ تكون دالة الخسارة عبارة عن إنتروبيا متقاطعه ثنائية (binary cross-entropy) بين الناتج من المُميِّز ومتجه الاستجابة 1.
أهم أمر ، يجب علينا تجميد أوزان المميز أثناء تدريب النموذج المدمج ، بحيث يتم تحديث أوزان المولد فقط. إذا لم نقم بتجميد أوزان المميز، فسيتم ضبط المميز بحيث تزداد احتمالية توقع الصور المُنشأة على أنها حقيقية ، وهي ليست النتيجة المرجوة.
نريد أن يتم توقع الصور التي تم إنشاؤها بالقرب من 1 (حقيقي) لأن المولد قوي ، وليس لأن المميز ضعيفة.

دعونا نرى كيف يبدو هذا في الكود. نحتاج أولاً إلى تجميع نموذج المُميِّز والنموذج الذي يقوم بتدريب المولد
self.discriminator.compile(
optimizer= RMSprop(lr=0.0008)
, loss = 'binary_crossentropy'
, metrics = ['accuracy']
) #1
### COMPILE MODEL THAT TRAINS THE GENERATOR
self.discriminator.trainable = False #2
model_input = Input(shape=(self.z_dim,), name='model_input')
model_output = discriminator(self.generator(model_input))
self.model = Model(model_input, model_output) #3
self.model.compile(
optimizer=RMSprop(lr=0.0004)
, loss='binary_crossentropy'
, metrics=['accuracy']
) #4
1- يتم تجميع المميّز مع خسارة الانتروبيا المتقاطعة الثنائية ، حيث أن الاستجابة ثنائية ولدينا مخرج واحد مع دالة تنشيط سيغمويد .
2- بعد ذلك ، نقوم بتجميد أوزان المميز – وهذا لا يؤثر على نموذج المميز الحالي الذي قمنا بتجميعه مسبقاً.
3- نحدد نموذجًا جديدًا يكون مدخله عبارة عن متجه كامنه لديها 100 بعد ؛ يتم تمريرها من خلال المولد والمميز الذي تم تجميده لإنتاج المخرج كإحتمال.
4- مرة أخرى ، نستخدم خسارة الانتروبيا المتقاطعة الثنائية ا للنموذج المشترك – معدل التعلم أبطأ من المميز حيث نود عمومًا أن يكون المميز أقوى من المولد. معدل التعلم هو معييار يجب ضبط بعناية.
ثم نقوم بتدريب شبكة الخصومة التوليدية بالتناوب بين تدريب المييز والمولد .
def train_discriminator(x_train, batch_size):
valid = np.ones((batch_size,1))
fake = np.zeros((batch_size,1))
# TRAIN ON REAL IMAGES
idx = np.random.randint(0, x_train.shape[0], batch_size)
true_imgs = x_train[idx]
self.discriminator.train_on_batch(true_imgs, valid) #1
# TRAIN ON GENERATED IMAGES
noise = np.random.normal(0, 1, (batch_size, z_dim))
gen_imgs = generator.predict(noise)
self.discriminator.train_on_batch(gen_imgs, fake) #2
def train_generator(batch_size):
valid = np.ones((batch_size,1))
noise = np.random.normal(0, 1, (batch_size, z_dim))
self.model.train_on_batch(noise, valid) #3
epochs = 2000
batch_size = 64
for epoch in range(epochs):
train_discriminator(x_train, batch_size)
train_generator(batch_size)
1- لتحديث حزمة واحدة للمميز علينا أولاً التدرب على حزمة من الصور الحقيقية مع الاستجابة 1 .
2- ثم على حزمة من الصور التي تم توليدها مع الاستجابة 0.
3- يتضمن تحديث حزمة واحدة للمولد التدريب على حزمة من الصور التي تم إنشاؤها مع الاستجابة 1. نظرًا لأن المميز مجمد ، فلن تتأثر أوزانها ؛ بدلاً من ذلك ، ستتحرك أوزان المولد في الاتجاه الذي يسمح لها بإنشاء صور أفضل من المرجح أن تخدع المميز (أي جعل المميز تتنبأ بقيم قريبة من 1).
بعد عدد مناسب من الحقب (epoch) ، سيجد المميّز والمولد توازنًا يسمح للمولد بتعلم معلومات مفيدة من المميز وستبدأ جودة الصور في التحسن .

من خلال مراقبة الصور التي ينتجها المولد في فترات محددة أثناء التدريب ، من الواضح أن المولد أصبح بارعًا بشكل متزايد في إنتاج الصور التي كان يمكن استخلاصها من مجموعة التدريب.
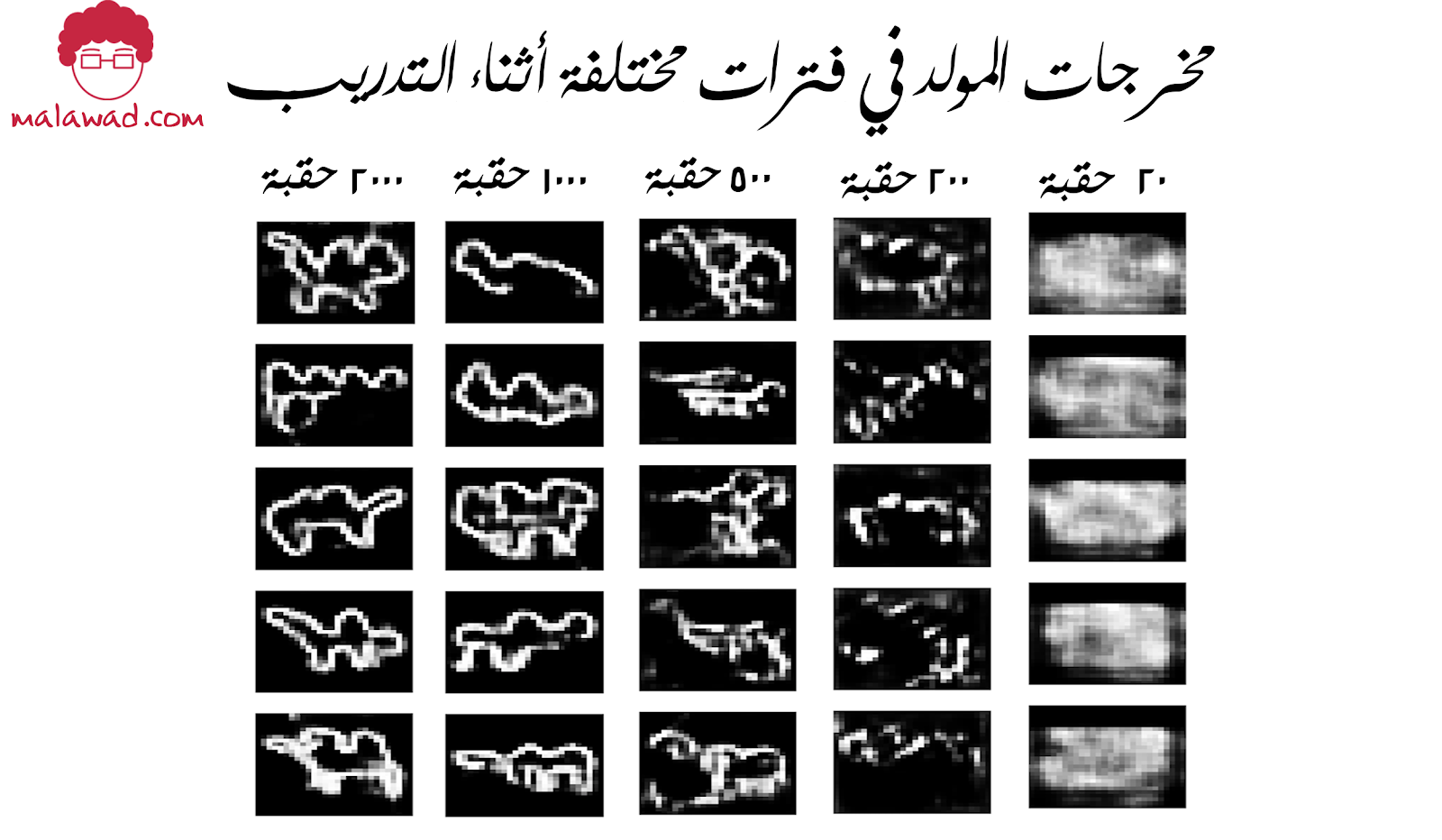
أن تكون الشبكة العصبية قادرة على تحويل الضوضاء العشوائية إلى شيء ذي معنى. هو أمر مدهش. تجدر الإشارة إلى أننا لم نوفر للنموذج أي ميزات إضافية بخلاف وحدات النقاط الضوئية الأولية ، لذلك يتعين عليه وضع مفاهيم عالية المستوى مثل كيفية رسم سنام أو أرجل أو رأس بمفرده. لن تتمكن نماذج نايف بايز التي رأيناها في المقال الثاني من هذه السلسة من تحقيق هذا المستوى من التعقيد نظرًا لأنها لا تستطيع نمذجة الترابطات بين وحدات النقاط الضوئية التي تعتبر ضرورية لتشكيل هذه الميزات عالية المستوى.
من المتطلبات الأخرى للنموذج التوليدي الناجح أنه لا يقوم فقط بإعادة إنتاج الصور من مجموعة التدريب. لاختبار ذلك ، يمكننا العثور على الصورة من مجموعة التدريب الأقرب إلى مثال معين تم إنشاؤه. مقياس جيد للمسافة هو المسافة L1 ، المعرفة على النحو التالي:
def l1_compare_images(img1, img2):
return np.mean(np.abs(img1 - img2))
توضح الصورة أدناه أقرب الملاحظات في مجموعة التدريب لمجموعة مختارة من الصور التي تم إنشاؤها. يمكننا أن نرى أنه على الرغم من وجود درجة معينة من التشابه بين الصور التي تم إنشاؤها ومجموعة التدريب ، إلا أنها ليست متطابقة ، كما أن GAN قادرة أيضًا على إكمال بعض الرسومات غير المكتملة عن طريق ، على سبيل المثال ، إضافة أرجل أو رأس. يوضح هذا أن المولد قد فهم هذه الميزات عالية المستوى ويمكنه إنشاء أمثلة مختلفة عن تلك التي شاهدها بالفعل.

في الختام يمكنكم تجريب الكود المستخدم المصاحب لهذه المقالة على الغيتهاب













إضافة تعليق